【小文件那些事(一)】为什么会出现小文件?小文件出现背景、原因及危害
友情链接
- 【小文件那些事(一)】为什么会出现小文件?小文件出现背景、原因及危害
- 【小文件那些事(二)】针对不同阶段下的小文件过多问题如何处理,最佳治理手段(星环Compact机制)
- TORC表格式对应的小文件合并方法
- TORC Compact 常见故障诊断方法
- Inceptor Plus及ArgoDB Holodesk表格式对应的小文件合并方法 (Compact Service)
- TDH及ArgoDB归档分区功能介绍及使用方法
- Text/ORC非事务表合并最佳方式
- 小文件相关问题的处理思路
- Inceptor compact 性能优化方法
- Automerge及优化后的AutomergeV2用法及注意事项
背景
大数据场景下会产生海量文件,其中,小文件会对系统造成一系列影响。在实际业务中,小文件现象出现频率并不低,客户现场开发环境和或生产环境多或少都会遇到小文件问题,这些问题或来自上游系统,亦可能是因为表的分区分桶不合理,也可能是来自于不规范的sql等等。
当小文件过多时,将会导致内存占用高、集群不稳定,增加计算资源的开支等一系列问题。
因此小文件治理是必要的也是迫切的。因此,本篇文章将从源头为您介绍什么是小文件合并,为什么会出现小文件增多的情况,不同阶段下治理小文件的最佳手段,以及不同的表格式中的合并机制是什么,如何使用。感兴趣的小伙伴一起看下去吧~
为了更清楚的理解我们为什么要治理小文件,Compact机制是什么,我们需要溯源,了解小文件出现的原因是什么,有什么弊端。
小文件出现背景
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目之一,旨在通过计算机集群在分布式环境中有效地存储和处理大批量文件,有效地解决大规模、海量数据的存储以及读写性能的问题,并为海量数据提供了不怕故障的存储,为超大数据集的应用处理带来了很多便利。
HDFS常常用于在Hadoop生态体系内提供分布式文件读写服务,目前大数据平台很多都在使用HDFS应对海量数据的存储。
HDFS有以下的设计目标:
- 高可靠性,可以防止服务器出现故障宕机所导致的数据丢失等问题;
- 相比较磁盘阵列构建成本低,可构建在廉价x86服务器上;
- 将大文件切成Block,支持GB-TB级别海量数据存储;
- 支持大规模离线批处理,利用数据本地性提速计算过程;
虽然HDFS有效解决了用户大文件存储等问题,但其本身设计存在一些缺陷。我们先来看一下HDFS的简易架构图:
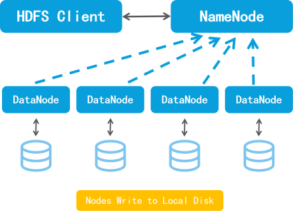
从整个系统架构上看,NameNode扮演着十分重要的角色,其一大功能是负责进行元数据的存储与管理。其中元数据信息包括文件名、文件所在路径、文件所有者、副本数等信息。此外,还有多个 DataNode 节点,这些节点就是文件存储位置。客户端收到服务器允许上传文件的响应之后,会将该文件分为一个个块(block),并将这些块存储在集群中的不同节点上,然后将每个块依次发送到 DataNode 中,由 NameNode 记录块的存储位置等信息存储在元数据中。
同时,为了保证数据有足够多的副本来确保数据可靠性和容错性,这时服务器会进行一个异步的操作,将这个块再进行复制操作,存储到其他 DataNode 中。
因此,HDFS基于block块存储、3副本机制等设计的特点在面对低延时、数据量小且文件多的场景下小文件问题会变得格外突出。
题外话:
如果超出2亿文件规模,HDFS需要分federation隔离,大幅增加运维管理成本。
星环TDFS可以高效管理还聊小文件存储,支持10亿+文件,相较于开源提升5倍,服务启动时间降低93%,元数据QPS性能提升70%,兼容Hadoop接口,可支持S3接口,感兴趣可查看: TDFS产品页
小文件的出现
小文件通常是指文件size远小于HDFS上block块大小的文件。小文件数量过多,会给hadoop的扩展性和性能带来严重问题。
任何block块、文件或者目录在内存中均以对象的形式存储,如果小文件的数据量非常多,则NameNode需要更多存储元数据的空间,将逐渐出现内存受限的问题,并且很多存储小文件时被隐藏的问题被暴露出来,比如启动时间变长(NameNode的启动过程通常分为几个阶段,包括fsimage本地数据加载、读取JournalNode上比fsimage新的editlog、在本地进行editlog replay、DataNode的BlockReport)。这样NameNode内存容量严重制约了集群的扩展。
并且,有关元数据的管理处理等操作基本都是基于NameNode来进行,那么当内存被大量占用时,对于元数据的增删改查的操作性能会出现下降的趋势,相对于更复杂的操作处理,比如RPC (Remote Procedure Call) 请求的性能下降趋势将会更加明显。
HDFS最初是为流式访问大文件开发的,访问大量小文件,block块在不同的节点上,则需要不断的从一个DataNode跳到另一个DataNode,严重影响性能。
即使NameNode能够存储大量的小文件信息,对于hive,spark计算时,小文件同时也意味着需要更多的task和资源,处理大量小文件的速度远远大于处理同等大小的大文件的速度。这是因为每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上,同样也会导致节点异常。
原因分析及危害
因此,总的来说,导致出现小文件的原因主要有以下几类:
① 用户在进行小批量、频繁的数据写入和更新操作的时候,会产生大量的小文件;
② torc表compact多次合并失败后进入黑名单,导致小文件不再继续合并;
③ 采用不规范的sql语句,导致单次事务产生的都是小文件;
④ 往动态分区插入数据可能会产生大量的小文件,从而导致Map数量剧增。这是因为假设动态分区有n个分区,数据插入动态分区阶段产生了m个Map任务,则会产生n*m个文件,从而带来很多小文件。对于多级动态分区,n值往往会变得很大;对于大的数据量,m值往往会变得很大;
⑤ 表设计不合理:
- 范围分区表,分区跨度小,导致单分区内的数据量小,小文件过多,单值分区设置不合理也会导致这个情况;
- 使用动态分区表来做数据的存储入库时,在设计分区分桶的时候不合理导致底层有大量的小文件;
- 再或者说非分区表的分桶设置过大,数据平均分布,导致底层文件利用率低,每个桶文件大小几KB,从而产生小文件,或者分桶字段设置不合理,导致数据倾斜,从而产生小文件;
- 不同的表类型,如:textfile表,csvfile表,orc/TORC表,hyperbase表,search表,holodesk表等等,不同表类型适用与不同业务场景,使用不当也极有可能会造成小文件问题产生。
⑥ HDFS的设计建立在更多的响应"一次写入、多次读写"任务的基础上。这意味着一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。比如我们使用 Spark Streaming 从外部数据源接收数据,然后经过 ETL 处理之后存储到 HDFS 中。这种情况下在每个 Job 中都会产生大量的小文件。
⑦ 数据源自身存在问题:比如历史数据流程导致小文件问题,这些数据一般是从别的数据库迁移过来,后续没有进行治理;也可能数据源本身就是大量的小文件或落盘参数不合理。例如需要接入的数据文件即是大量文件,如照片,文档等非结构化数据的接入(原始数据就是大量小文件,所以存储到HDFS上必定也是小文件);
综上所述,出现小文件问题的可能性有很多,从上游到下游的各个步骤都有可能产生小文件,但无论是什么原因,都有可能会导致下述影响:
- 写入和查询性能衰减,批处理性能下降;
- HDFS的Namenode内存增大,内存占用高;
- Map/Reduce tasks数增多,Mapper和Reducer数量增加,占据调度时间,寻址时间更高;
- 长尾效应:大文件处理时间长,小文件处理时间短,浪费资源;
- 增加计算资源的开销,增加集群的负载压力,影响性能;
- Namenode崩溃;
综上,小文件治理迫在眉睫!!
下一篇:小文件过多如何处理,不同阶段下的最佳治理手段(星环Compact机制)
友情链接
- 【小文件那些事(一)】为什么会出现小文件?小文件出现背景、原因及危害
- 【小文件那些事(二)】针对不同阶段下的小文件过多问题如何处理,最佳治理手段(星环Compact机制)
- TORC表格式对应的小文件合并方法
- TORC Compact 常见故障诊断方法
- Inceptor Plus及ArgoDB Holodesk表格式对应的小文件合并方法 (Compact Service)
- TDH及ArgoDB归档分区功能介绍及使用方法
- Text/ORC非事务表合并最佳方式
- 小文件相关问题的处理思路
- Inceptor compact 性能优化方法
- Automerge及优化后的AutomergeV2用法及注意事项
背景
大数据场景下会产生海量文件,其中,小文件会对系统造成一系列影响。在实际业务中,小文件现象出现频率并不低,客户现场开发环境和或生产环境多或少都会遇到小文件问题,这些问题或来自上游系统,亦可能是因为表的分区分桶不合理,也可能是来自于不规范的sql等等。
当小文件过多时,将会导致内存占用高、集群不稳定,增加计算资源的开支等一系列问题。
因此小文件治理是必要的也是迫切的。因此,本篇文章将从源头为您介绍什么是小文件合并,为什么会出现小文件增多的情况,不同阶段下治理小文件的最佳手段,以及不同的表格式中的合并机制是什么,如何使用。感兴趣的小伙伴一起看下去吧~
为了更清楚的理解我们为什么要治理小文件,Compact机制是什么,我们需要溯源,了解小文件出现的原因是什么,有什么弊端。
小文件出现背景
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目之一,旨在通过计算机集群在分布式环境中有效地存储和处理大批量文件,有效地解决大规模、海量数据的存储以及读写性能的问题,并为海量数据提供了不怕故障的存储,为超大数据集的应用处理带来了很多便利。
HDFS常常用于在Hadoop生态体系内提供分布式文件读写服务,目前大数据平台很多都在使用HDFS应对海量数据的存储。
HDFS有以下的设计目标:
- 高可靠性,可以防止服务器出现故障宕机所导致的数据丢失等问题;
- 相比较磁盘阵列构建成本低,可构建在廉价x86服务器上;
- 将大文件切成Block,支持GB-TB级别海量数据存储;
- 支持大规模离线批处理,利用数据本地性提速计算过程;
虽然HDFS有效解决了用户大文件存储等问题,但其本身设计存在一些缺陷。我们先来看一下HDFS的简易架构图:
从整个系统架构上看,NameNode扮演着十分重要的角色,其一大功能是负责进行元数据的存储与管理。其中元数据信息包括文件名、文件所在路径、文件所有者、副本数等信息。此外,还有多个 DataNode 节点,这些节点就是文件存储位置。客户端收到服务器允许上传文件的响应之后,会将该文件分为一个个块(block),并将这些块存储在集群中的不同节点上,然后将每个块依次发送到 DataNode 中,由 NameNode 记录块的存储位置等信息存储在元数据中。
同时,为了保证数据有足够多的副本来确保数据可靠性和容错性,这时服务器会进行一个异步的操作,将这个块再进行复制操作,存储到其他 DataNode 中。
因此,HDFS基于block块存储、3副本机制等设计的特点在面对低延时、数据量小且文件多的场景下小文件问题会变得格外突出。
题外话:
如果超出2亿文件规模,HDFS需要分federation隔离,大幅增加运维管理成本。
星环TDFS可以高效管理还聊小文件存储,支持10亿+文件,相较于开源提升5倍,服务启动时间降低93%,元数据QPS性能提升70%,兼容Hadoop接口,可支持S3接口,感兴趣可查看: TDFS产品页
小文件的出现
小文件通常是指文件size远小于HDFS上block块大小的文件。小文件数量过多,会给hadoop的扩展性和性能带来严重问题。
任何block块、文件或者目录在内存中均以对象的形式存储,如果小文件的数据量非常多,则NameNode需要更多存储元数据的空间,将逐渐出现内存受限的问题,并且很多存储小文件时被隐藏的问题被暴露出来,比如启动时间变长(NameNode的启动过程通常分为几个阶段,包括fsimage本地数据加载、读取JournalNode上比fsimage新的editlog、在本地进行editlog replay、DataNode的BlockReport)。这样NameNode内存容量严重制约了集群的扩展。
并且,有关元数据的管理处理等操作基本都是基于NameNode来进行,那么当内存被大量占用时,对于元数据的增删改查的操作性能会出现下降的趋势,相对于更复杂的操作处理,比如RPC (Remote Procedure Call) 请求的性能下降趋势将会更加明显。
HDFS最初是为流式访问大文件开发的,访问大量小文件,block块在不同的节点上,则需要不断的从一个DataNode跳到另一个DataNode,严重影响性能。
即使NameNode能够存储大量的小文件信息,对于hive,spark计算时,小文件同时也意味着需要更多的task和资源,处理大量小文件的速度远远大于处理同等大小的大文件的速度。这是因为每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上,同样也会导致节点异常。
原因分析及危害
因此,总的来说,导致出现小文件的原因主要有以下几类:
① 用户在进行小批量、频繁的数据写入和更新操作的时候,会产生大量的小文件;
② torc表compact多次合并失败后进入黑名单,导致小文件不再继续合并;
③ 采用不规范的sql语句,导致单次事务产生的都是小文件;
④ 往动态分区插入数据可能会产生大量的小文件,从而导致Map数量剧增。这是因为假设动态分区有n个分区,数据插入动态分区阶段产生了m个Map任务,则会产生n*m个文件,从而带来很多小文件。对于多级动态分区,n值往往会变得很大;对于大的数据量,m值往往会变得很大;
⑤ 表设计不合理:
- 范围分区表,分区跨度小,导致单分区内的数据量小,小文件过多,单值分区设置不合理也会导致这个情况;
- 使用动态分区表来做数据的存储入库时,在设计分区分桶的时候不合理导致底层有大量的小文件;
- 再或者说非分区表的分桶设置过大,数据平均分布,导致底层文件利用率低,每个桶文件大小几KB,从而产生小文件,或者分桶字段设置不合理,导致数据倾斜,从而产生小文件;
- 不同的表类型,如:textfile表,csvfile表,orc/TORC表,hyperbase表,search表,holodesk表等等,不同表类型适用与不同业务场景,使用不当也极有可能会造成小文件问题产生。
⑥ HDFS的设计建立在更多的响应"一次写入、多次读写"任务的基础上。这意味着一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。比如我们使用 Spark Streaming 从外部数据源接收数据,然后经过 ETL 处理之后存储到 HDFS 中。这种情况下在每个 Job 中都会产生大量的小文件。
⑦ 数据源自身存在问题:比如历史数据流程导致小文件问题,这些数据一般是从别的数据库迁移过来,后续没有进行治理;也可能数据源本身就是大量的小文件或落盘参数不合理。例如需要接入的数据文件即是大量文件,如照片,文档等非结构化数据的接入(原始数据就是大量小文件,所以存储到HDFS上必定也是小文件);
综上所述,出现小文件问题的可能性有很多,从上游到下游的各个步骤都有可能产生小文件,但无论是什么原因,都有可能会导致下述影响:
- 写入和查询性能衰减,批处理性能下降;
- HDFS的Namenode内存增大,内存占用高;
- Map/Reduce tasks数增多,Mapper和Reducer数量增加,占据调度时间,寻址时间更高;
- 长尾效应:大文件处理时间长,小文件处理时间短,浪费资源;
- 增加计算资源的开销,增加集群的负载压力,影响性能;
- Namenode崩溃;
综上,小文件治理迫在眉睫!!
下一篇:小文件过多如何处理,不同阶段下的最佳治理手段(星环Compact机制)
 登录后可评论
登录后可评论








.jpg)



