小文件救星来了!!Text/ORC非事务表合并最佳方式
友情链接:
- 【小文件那些事(一)】为什么会出现小文件?小文件出现背景、原因及危害
- 【小文件那些事(二)】针对不同阶段下的小文件过多问题如何处理,最佳治理手段(星环Compact机制)
- TORC表格式对应的小文件合并方法
- ArgoDB Holodesk表格式对应的小文件合并方法 (Compact Service)
- ArgoDB归档分区功能介绍及使用方法
- 小文件相关问题的处理思路
- Inceptor compact 性能优化方法
- Automerge及优化后的AutomergeV2用法及注意事项
前情提要
在实际业务中,小文件现象出现频率并不低,当小文件过多时,将会导致内存占用高、集群不稳定,增加计算资源的开支等一系列问题,因此解决小文件问题迫在眉睫!!
由于篇幅限制,欲了解小文件出现背景,原因分析,为什么要治理小文件,小文件过多的危害等方面的内容,可参考:【小文件详解】不同阶段下的小文件治理最佳解决手段
在前面介绍小文件治理相关的文章中有提到,小文件治理无外乎三个阶段,存储端、计算端以及SQL端。其中存储端合并指的是说当表中有小文件或者小文件过多时,可以通过合并已经写入到存储的文件来治理,主要适用于以下原因导致的小文件问题:
- 频繁的写入数据;
- torc表compact多次合并失败后进入黑名单,导致小文件不再继续合并;
- 历史数据流程导致小文件问题,这些数据一般是从别的数据库迁移过来,后续没有进行治理;
但是,不同的表格式的合并方式不同。本篇文章主要为读者介绍如何针对Orc表/Text非事务表做合并。
Orc表/Text表
对于holodesk及torc表用户可以采用自动或手动的形式进行合并,或者使用最新的Compact Service,但是针对text及orc非事务表来说,一直以来没有一个很完美的合并方法。这是因为非事务表不像事务表有文件合并的逻辑。
非事务表与事务表的合并逻辑差异
事务表需要严格遵循ACID(原子性、一致性、隔离性、持久性)特性,确保在并发操作和错误恢复情况下数据的完整性和一致性。因此,为了维护这些特性,事务表需要复杂的机制来管理数据操作,比如锁机制和日志记录,其中也包括对文件进行合并以确保数据一致性和性能。
但是非事务表由于并不需要严格遵循ACID特性,适用于需要快速写入和读取的大数据应用以及分析和数据仓库的场景下,因此并不需要涉及复杂的事务管理机制。
不同的应用场景和需求决定了非事务表跟事务表在文件合并逻辑上的差异。
但是!!在Inceptor跑批场景中,经常会涉及ORC等非事务表,随着每日增量数据的插入以及可能的数据重复插入,HDFS上的文件数与日俱增,达到千万甚至上亿的级别!!在部分现场发现其中有上千万个大小仅有KB~MB之间的小文件。这些小文件数量严重的制约了集群的稳定运行,对HDFS以及Inceptor组件的稳定性影响也很大,比如出现长GC,OOM等。
因此,非事务表的合并机制也至关重要。
为什么星环要专门做一个合并功能,而非采用开源方案?
开源方案的弊端:
- 合并小文件需要根据每一张表的数据量和分布情况,手动编写任务进行重写来实现小文件合并的效果,在这个过程中,表只能读不能写;
- 由于小文件合并是一个资源密集型的操作,可能会影响到正在运行的任务的性能和资源利用率,所以开源方案的合并作业通常会放置于数据处理流程的末端,也就是数据存储到 HDFS 后的后处理阶段执行,无法及时清理;
前面的章节有提到,任务的各个流程跟步骤中都有可能会产生大量的小文件。所以开源方案在任务运行结束后再去扫描进行合并并不能从根本上预防以及根治小文件过多的问题,而且在这个过程中表相关的业务会受影响。
除了这个原因之外,开源方案的小文件合并机制在保障数据一致性与原子性方面也存在一些局限性。
原子性问题
- 小文件合并通常会涉及多个阶段,包括读取原始文件、将其内容写入新的大文件、删除原文件等等。但是,如果这些步骤不能在一个原子操作中完成(即要么全部成功,要么全部失败),就可能在合并过程中出现中间状态。比如,某些小文件已经被读取和写入新文件,但尚未删除旧文件,或者新文件还未完全写入完成。这种中间状态可能会导致数据的不一致性。
- 而且,如果在合并过程中发生故障(节点崩溃或网络中断),合并操作可能会中断,留下不完整的文件或重复的数据,最终导致原子性无法保障。
一致性问题
- 在分布式环境中,经常会出现多个进程同时尝试访问和操作相同的小文件的情况,可能会有新的数据写入或修改操作。但是非事务表本身在设计上没有像事务表一样有那么严格的锁机制或事务管理,所以这些并发操作极大可能会导致数据冲突和不一致。例如,一个进程正在读取和合并某些小文件,而另一个进程可能同时写入这些文件,最终会导致合并后的文件与原始数据不一致。
- 合并小文件不仅涉及数据文件本身,还涉及元数据。像HDFS是使用NameNode来管理文件系统的元数据的,其中包括文件的目录结构和文件块的位置。小文件合并通常会涉及对元数据的多次修改(比如更新文件块信息、删除旧文件记录等)。如果这些修改不能保证在所有NameNode副本之间的一致性,可能就会导致NameNode视图与实际数据不一致。
所以综上所述,目前开源方案针对小文件合并机制还面临着诸多挑战,这些挑战主要源于非事务表原生不支持事务操作,这使得很难在多个文件操作间保持严格的一致性和原子性。
因此如果想要实现在确保小文件合并效率的同时充分保障文件操作间的一致性与原子性,还需要额外设计一些机制以及逻辑控制。
这就是为什么星环要设计一个新的合并方案来解决开源方案中的不足。
星环Galactus应运而生!!Galactus可以自动检测到小文件自动合并掉,用户无需担心因为处理不及时或有疏漏影响到业务系统,更加贴合生产上的需求。
星环是怎么做的?为什么不采用TORC Compact的逻辑?
TORC Compact是靠事务锁和事务ID来保证原子性以及读数的正确性的。所以事务表在合并一开始便会获取读锁,其他会造成影响的如truncate需要获取排他锁,所以truncate必须等到整个合并完成,这样才能保证合并过程的原子性;同时在读数的时候根据base的事务ID去过滤掉事务ID比它小的base和delta,保证了不会多读数。
但是对于非事务表来说,是没有这两个属性的,需要强行加上类似的锁机制和类事务ID来保证原子性以及确保不会多读数。
所以,星环的非事务表小文件合并设计方案设计了一些算法以及采用editlog reply机制实现了在没有事务控制下保证合并过程中的原子性以及不会多读数的目标。
对于实际业务来说,星环方案有哪些独特的优势?
- 在Compaction过程中,计算引擎端(quark)的业务,表的读,写,删除等操作能够不被长时间阻塞,并成功执行不报错;
- 即使客户通过HDFS CLIENT操作数据目录,合并也不会造成数据的丢失或增加;
- 开源产品如Hive/Spark也能用该方案解决小文件问题;
- 完善的回退机制,保证了数据的正确性以及editlog能被原HDFS正常重放,恢复到合并前;
- 该方案针对多次访问文件产生的大量开销做了优化,并且针对多个异常现象,如NN重启或者主从切换、合并前/中/后发生了目录或文件的mv,cp,truncate等操作,该方案都做了完备的处理机制,以保障系统整体的一致性、原子性以及正确性。
客户案例
星环某一从CDH迁移过来的客户,业务系统中共有72个库,近万张表,其中Quark 数据目录下共约3600万个文件,除此之外,每天平均入库40~50万个文件。
在开启Galactus一周后,系统文件数量减少了13%,每天合并80万个小文件,充分覆盖了增量文件。整体的绩效业务跑批性能提升了一倍以上。
截至目前,该功能共计为客户合并了9000w+个小文件,文件对象从8600w+降低至6900w+。
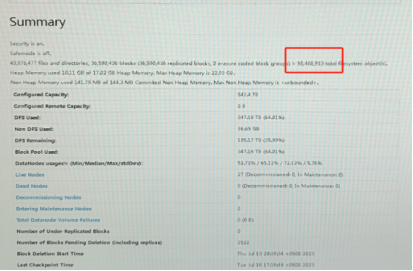
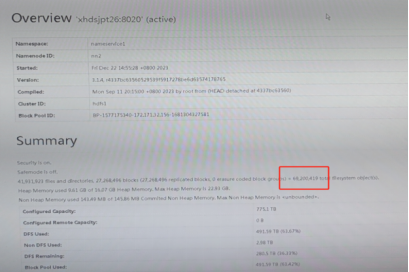
使用Demo/最佳实践
前期准备
版本检查
在使用前,用户需要检查当前环境版本是否满足下方要求:
a. 商业版:TDH 6.2.2或9.3.2及以上版本,HDFS及Inceptor打最新Patch
b. 社区版:TDH-CE-24-5版本
HDFS状态检查
检查HDFS角色状态和pod状态,保证hdfs的状态是正常可以使用的;
① 角色状态检查
② Pod检查
执行:kubectl get pod -owide | grep hdfs
FSImage检查
① 首先找到dfs.namenode.name.dir的路径
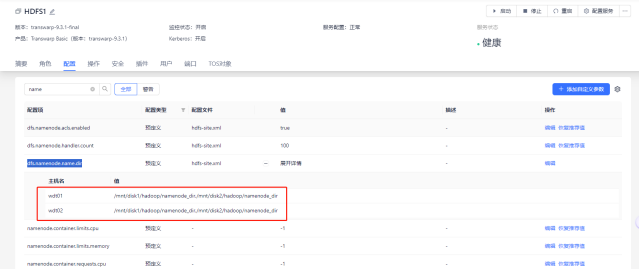
② 找到namenode的active和stand by节点
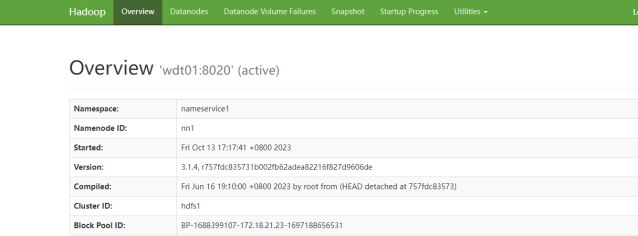
③ 依次检查active节点dfs.namenode.name.dir路径的fsimage,确保数据日期和实际的日期相差在1h之内。
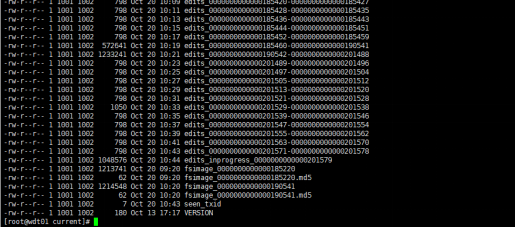
④ 依次检查stand by节点dfs.namenode.name.dir路径的fsimage,确保和active的一致。

HDFS summary检查
检查hdfs的元数据个数,文件及文件数的个数,以及文件总大小。
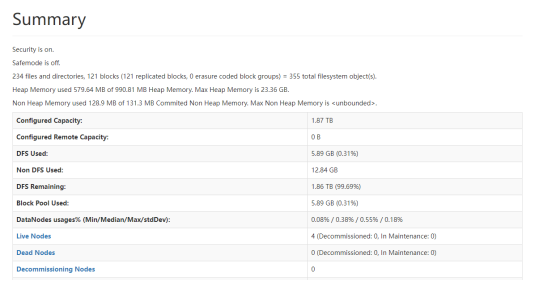
HDFS count检查
命令:hdfs dfs -count /quark(n)

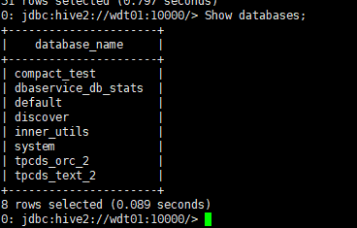
Database个数检查
命令:Show databases;
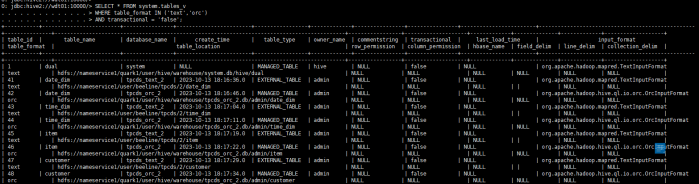
非事务表个数检查
查询命令:
SELECT * FROM system.tables_v
WHERE table_format IN ('text','orc')
AND transactional = 'false';
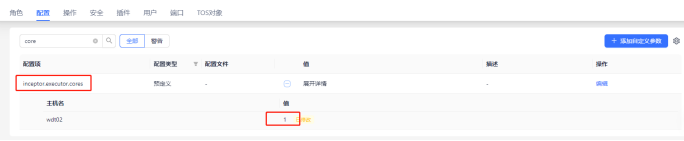
Quark部署
Galactus禁止部署在批处理quark和重要业务查询的quark上。因此,用户在使用前需要新建一个quark,专门用于galactus小文件合并作业,每个节点均需安装executor,资源要求配置为单核,内存3GB。


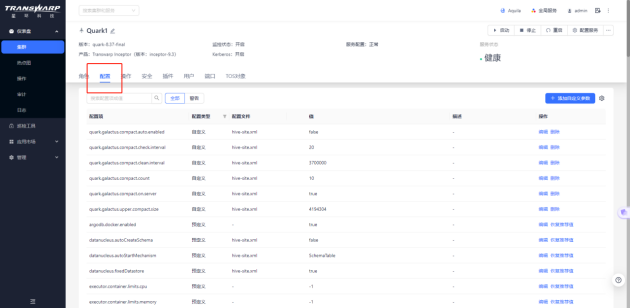
配置所需参数
参数配置方法
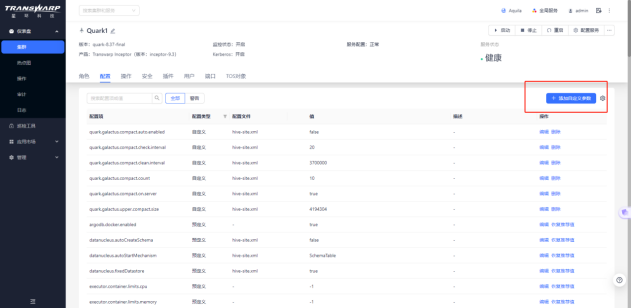
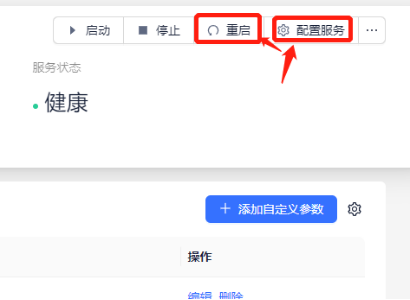
① 登录到manager页面,点击Transwarp inceptor的quark服务进入服务详情页面

② 点击配置模块的“添加自定义参数”按钮,进入添加页面,配置文件选择hive-site.xml,配置项参考下一小节;
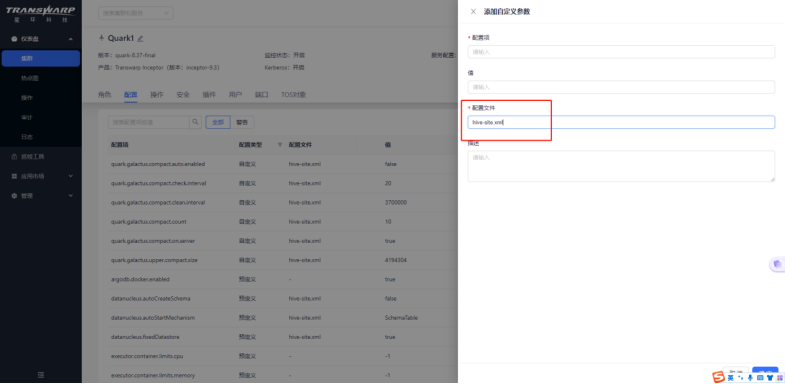
③ 注意:在添加完参数后可以参考后续章节选择对不同的配置项赋予不同的值。比如点击右侧的编辑,将自动合并的参数quark.galactus.compact.auto.enabled设置为true;
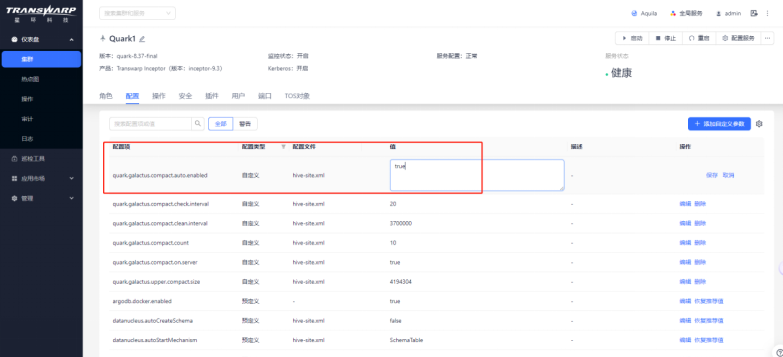
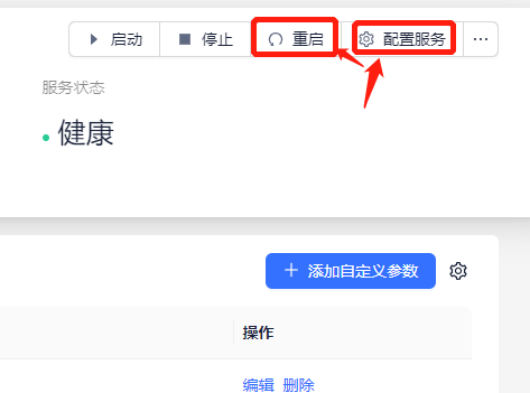
④ 参数配置完成后,均需先重新配置服务,再重启quark;
涉及的参数配置项
以下参数均是全局参数,需要基于上一小节的方法在manager页面添加自定义参数及对应的参数值进行配置。全局参数列表如下:
| 参数 | 值 | 功能描述 |
| quark.galactus.compact.on.server | true | 在Quark Server上开启compaction功能 |
| quark.galactus.compact.auto.enabled | false/true | 开启/关闭自动compact功能 |
| quark.galactus.compact.check.interval | 3600000 | X小时检测一遍是否可合并(建议根据合并性能要求调整,比如1小时) |
| quark.galactus.compact.clean.interval | 4200000 | X小时后清理已经被合并的小文件;而由这些小文件合并生成的大文件在这些小文件被清理之前不会参与下一次的合并 |
| quark.galactus.compact.count | 10 | 目录下小于4M的小文件参与合并,超过10个小于4M的小文件才会触发合并;合并时10个小文件为一组合并为一个文件,最后如果还有剩余不足10个的小文件,则这些小文件合并为一个文件 |
| quark.galactus.upper.compact.size | 4194304 | |
| quark.galactus.compact.db.blacklist | aa,bb,cc | DB合并黑名单 |
| quark.galactus.compact.db.whitelist | dd,ee,ff | DB合并白名单 |
| quark.galactus.compact.file.fetch.size | 1000 | 自动合并时,默认值为1000/false,即一张表一次取1000个小文件参与合并,合并完成后,以同样的规则合并下一张表;若为true,则该表的全部小文件参与合并,完成后再去合并下一张表,手动合并时第二个参数默认为true,即每次取1000小文件参与合并,直至全表合并结束 |
| quark.galactus.compact.continue.to.finished | false/true |
合并操作
手动合并
手动合并涉及以下参数:
| 参数 | 值 | 功能描述 |
| quark.galactus.compact.on.server | true | 在Quark Server上开启compaction功能 |
| quark.galactus.compact.auto.enabled | false | 关闭自动compact功能 |
使用beeline或waterdrop连接需要合并小文件的表所在的数据库,可以对指定的表手动进行小文件合并,具体命令如下:
alter table table_name compact 'full'
合并过程中可以使用下方命令来查看表文件是否正在在合并(合并后的新文件格式为*_cpt_*):
dfs -ls hdfs路径
dfs -count hdfs路径
自动合并
自动合并涉及以下参数:
| 参数 | 值 | 功能描述 |
| quark.galactus.compact.on.server | true | 在Quark Server上开启compaction功能 |
| quark.galactus.compact.auto.enabled | true | 开启自动compact功能 |
| quark.galactus.compact.check.interval | 3600000 | X小时检测一遍是否可合并(建议根据合并性能要求调整,比如1小时) |
| quark.galactus.compact.clean.interval | 4200000 | X小时后清理已经被合并的小文件;而由这些小文件合并生成的大文件在这些小文件被清理之前不会参与下一次的合并 |
| holodesk.compact.init.interval(社区版不支持) | 60(s) | 设置 Init 线程 SLEEP 的时间 |
| holodesk.compact.table.interval(社区版不支持) | 300(s) | 设置同一张表同一分区执行 Compact 的最低间隔 |
| holodesk.compact.thread.max(社区版不支持) | 10 | 限制执行 COMPACT 的最大并发数 |
| holodesk.compact.worker.interval(社区版不支持) | 20(s) | 设置 worker 线程运行周期中 SLEEP 的时间 |
| holodesk.fullcompaction.single.task.filenum.threshold(社区版不支持) | 50(个) | 控制 fullcompact 单个 task 处理的小文件数量上限 |
- 开启自动合并开关,需要将quark.galactus.compact.auto.enabled设置为true;
- quark.galactus.compact.check.interval参数是合并时间间隔,推荐配置大于1小时,用户可以根据具体的业务情况来设置大小;
- quark.galactus.compact.clean.interval是清理小文件时间间隔,合并生成的大文件在小文件被清理之前不会参与下一次的合并,超过合并清理时间间隔后,合并后的文件如果符合规则,会参与下一次合并;
- 再次提醒:如果重新配置了参数值,需要重新配置服务和重启quark。
黑白名单
黑白名单涉及以下参数:
| 参数 | 值 | 功能描述 |
| quark.galactus.compact.db.blacklist | aa,bb,cc | DB合并黑名单 |
| quark.galactus.compact.db.whitelist | dd,ee,ff | DB合并白名单 |
黑白名单作用范围规则如下:
| 黑名单设置 | 白名单设置 | 合并范围 |
| 不设置 | 不设置 | 所有database均参与合并 |
| 不设置 | 设置 | 合并白名单内的database |
| 设置 | 不设置 | 合并不在黑名单内的database |
| 设置 | 设置 | 合并不在黑名单内但在白名单内的database即:not in 黑名单 and in 白名单 |
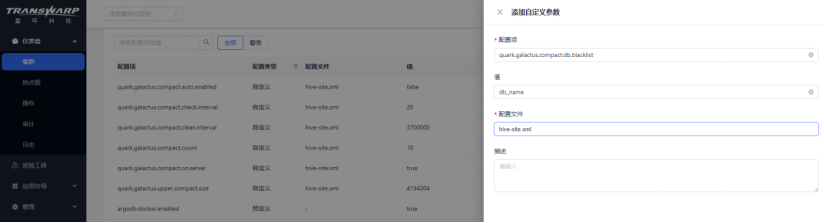
设置黑名单
设置后可以把黑名单内的database过滤掉,不参与小文件合并,多个DB之间用‘,’分割。设置后无论是手动合并还是自动合并,黑名单均生效。
比如想要设置仅session级别生效,则可以在查询的时候动态执行set quark.galactus.compact.db.blacklist=db_name1,db_name2;
如果需要全局生效,则可以在配置页面按照下方图片进行配置,配置后重新配置服务和重启quark即可。
![]()
设置白名单
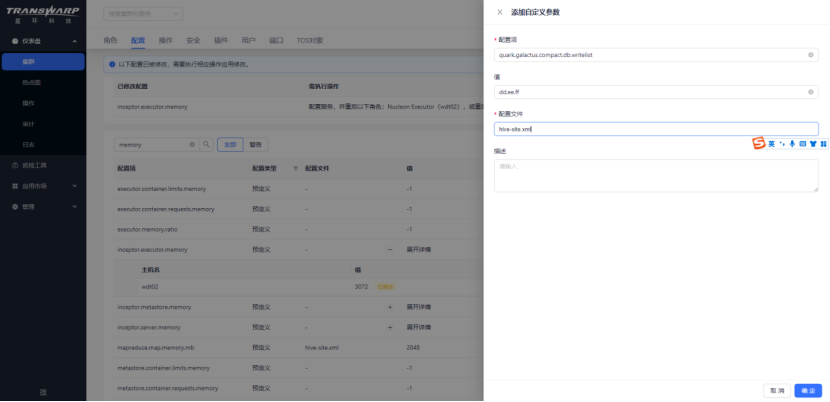
设置后可以只合并白名单内的database,多个DB之间用‘,’分割。设置后无论是手动合并还是自动合并,白名单均生效。
比如想要设置仅session级别生效,则可以在查询的时候动态执行set quark.galactus.compact.db.writelist=db_name3,db_name4;
如果需要全局生效,则可以在配置页面按照下方图片进行配置,配置后重新配置服务和重启quark即可。
多线程
设置小文件合并的多线程并发数,参数为quark.galactus.compact.concurrency,默认为10。
回滚合并
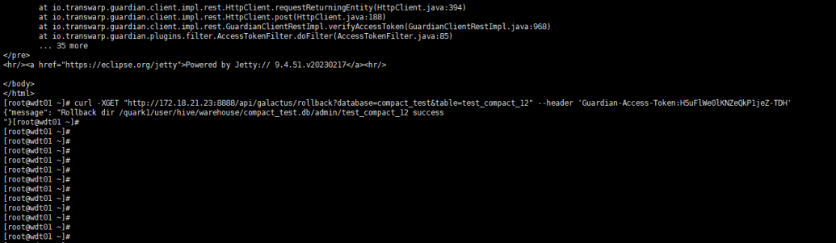
小文件合并后,支持回滚到合并前的小文件,命令行输入以下命令,database和table输入需要回滚表的相关信息即可。
- 非安全模式下命令如下:
curl -XGET "http://host:8888/api/galactus/rollback?database=db_name&table=table_name"
- 安全模式下需要特别注意,命令后要加上Guardian-Access-Token,其中token的获取请参考Guardian产品手册 3.3.2. 小节-【使用Guardian Access Token访问服务】
curl -XGET "http://host:8888/api/galactus/rollback?database=db_name&table=table_name" --header 'Guardian-Access-Token:H5uFlWe0lKNZeQkP1jeZ-TDH'
注意:合并完成后,在quark.galactus.compact.clean.interval 时间内执行上述命令可以进行回滚。但如果超过quark.galactus.compact.clean.interval时间后再执行回滚的话,此时数据已被清理,则没有办法回滚。
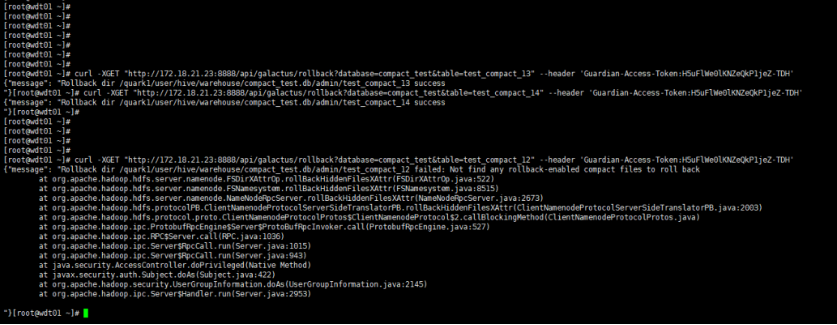
检查合并效果
如果需要检查Galactus小文件合并效果可以通过以下几种方式查看监控:
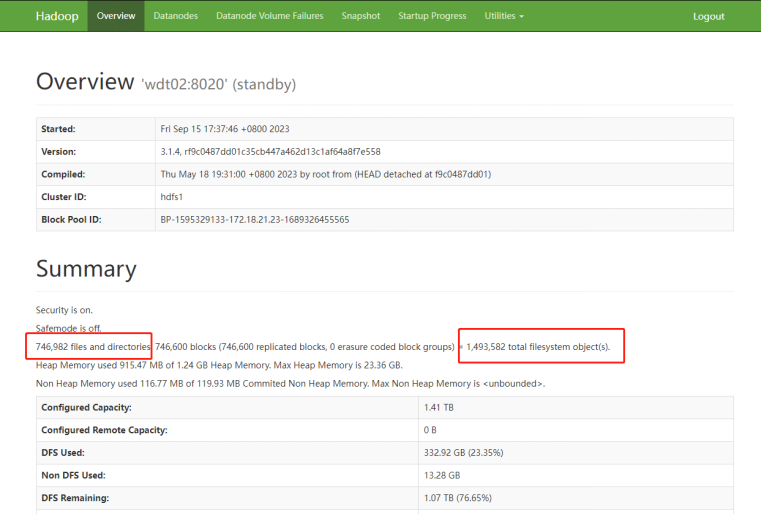
1) HDFS Summary
通过对HDFS的summary上的文件数据和元数据数据的连续监控,计算出小文件合并的效率。
2) HDFS count
通过使用命令hdfs dfs -count /quarkn查看文件数量,并连续监控,计算出小文件合并的效率。

3) Aquila统计
将josn文件:非事务表小文件合并统计指标(GALACTUS).json和HDFS小文件监控.json导入即可。
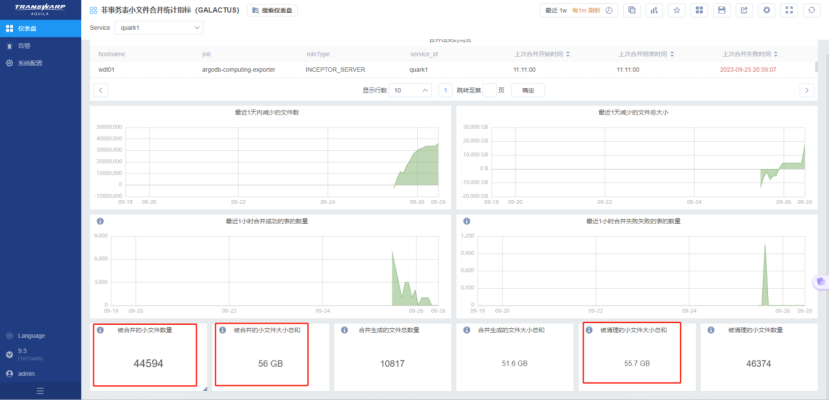
通过Aquila上监控被合并的小文件数量和被清理的小文件数量,进而计算出小文件合并的效率。
友情链接:
- 【小文件那些事(一)】为什么会出现小文件?小文件出现背景、原因及危害
- 【小文件那些事(二)】针对不同阶段下的小文件过多问题如何处理,最佳治理手段(星环Compact机制)
- TORC表格式对应的小文件合并方法
- ArgoDB Holodesk表格式对应的小文件合并方法 (Compact Service)
- ArgoDB归档分区功能介绍及使用方法
- 小文件相关问题的处理思路
- Inceptor compact 性能优化方法
- Automerge及优化后的AutomergeV2用法及注意事项
前情提要
在实际业务中,小文件现象出现频率并不低,当小文件过多时,将会导致内存占用高、集群不稳定,增加计算资源的开支等一系列问题,因此解决小文件问题迫在眉睫!!
由于篇幅限制,欲了解小文件出现背景,原因分析,为什么要治理小文件,小文件过多的危害等方面的内容,可参考:【小文件详解】不同阶段下的小文件治理最佳解决手段
在前面介绍小文件治理相关的文章中有提到,小文件治理无外乎三个阶段,存储端、计算端以及SQL端。其中存储端合并指的是说当表中有小文件或者小文件过多时,可以通过合并已经写入到存储的文件来治理,主要适用于以下原因导致的小文件问题:
- 频繁的写入数据;
- torc表compact多次合并失败后进入黑名单,导致小文件不再继续合并;
- 历史数据流程导致小文件问题,这些数据一般是从别的数据库迁移过来,后续没有进行治理;
但是,不同的表格式的合并方式不同。本篇文章主要为读者介绍如何针对Orc表/Text非事务表做合并。
Orc表/Text表
对于holodesk及torc表用户可以采用自动或手动的形式进行合并,或者使用最新的Compact Service,但是针对text及orc非事务表来说,一直以来没有一个很完美的合并方法。这是因为非事务表不像事务表有文件合并的逻辑。
非事务表与事务表的合并逻辑差异
事务表需要严格遵循ACID(原子性、一致性、隔离性、持久性)特性,确保在并发操作和错误恢复情况下数据的完整性和一致性。因此,为了维护这些特性,事务表需要复杂的机制来管理数据操作,比如锁机制和日志记录,其中也包括对文件进行合并以确保数据一致性和性能。
但是非事务表由于并不需要严格遵循ACID特性,适用于需要快速写入和读取的大数据应用以及分析和数据仓库的场景下,因此并不需要涉及复杂的事务管理机制。
不同的应用场景和需求决定了非事务表跟事务表在文件合并逻辑上的差异。
但是!!在Inceptor跑批场景中,经常会涉及ORC等非事务表,随着每日增量数据的插入以及可能的数据重复插入,HDFS上的文件数与日俱增,达到千万甚至上亿的级别!!在部分现场发现其中有上千万个大小仅有KB~MB之间的小文件。这些小文件数量严重的制约了集群的稳定运行,对HDFS以及Inceptor组件的稳定性影响也很大,比如出现长GC,OOM等。
因此,非事务表的合并机制也至关重要。
为什么星环要专门做一个合并功能,而非采用开源方案?
开源方案的弊端:
- 合并小文件需要根据每一张表的数据量和分布情况,手动编写任务进行重写来实现小文件合并的效果,在这个过程中,表只能读不能写;
- 由于小文件合并是一个资源密集型的操作,可能会影响到正在运行的任务的性能和资源利用率,所以开源方案的合并作业通常会放置于数据处理流程的末端,也就是数据存储到 HDFS 后的后处理阶段执行,无法及时清理;
前面的章节有提到,任务的各个流程跟步骤中都有可能会产生大量的小文件。所以开源方案在任务运行结束后再去扫描进行合并并不能从根本上预防以及根治小文件过多的问题,而且在这个过程中表相关的业务会受影响。
除了这个原因之外,开源方案的小文件合并机制在保障数据一致性与原子性方面也存在一些局限性。
原子性问题
- 小文件合并通常会涉及多个阶段,包括读取原始文件、将其内容写入新的大文件、删除原文件等等。但是,如果这些步骤不能在一个原子操作中完成(即要么全部成功,要么全部失败),就可能在合并过程中出现中间状态。比如,某些小文件已经被读取和写入新文件,但尚未删除旧文件,或者新文件还未完全写入完成。这种中间状态可能会导致数据的不一致性。
- 而且,如果在合并过程中发生故障(节点崩溃或网络中断),合并操作可能会中断,留下不完整的文件或重复的数据,最终导致原子性无法保障。
一致性问题
- 在分布式环境中,经常会出现多个进程同时尝试访问和操作相同的小文件的情况,可能会有新的数据写入或修改操作。但是非事务表本身在设计上没有像事务表一样有那么严格的锁机制或事务管理,所以这些并发操作极大可能会导致数据冲突和不一致。例如,一个进程正在读取和合并某些小文件,而另一个进程可能同时写入这些文件,最终会导致合并后的文件与原始数据不一致。
- 合并小文件不仅涉及数据文件本身,还涉及元数据。像HDFS是使用NameNode来管理文件系统的元数据的,其中包括文件的目录结构和文件块的位置。小文件合并通常会涉及对元数据的多次修改(比如更新文件块信息、删除旧文件记录等)。如果这些修改不能保证在所有NameNode副本之间的一致性,可能就会导致NameNode视图与实际数据不一致。
所以综上所述,目前开源方案针对小文件合并机制还面临着诸多挑战,这些挑战主要源于非事务表原生不支持事务操作,这使得很难在多个文件操作间保持严格的一致性和原子性。
因此如果想要实现在确保小文件合并效率的同时充分保障文件操作间的一致性与原子性,还需要额外设计一些机制以及逻辑控制。
这就是为什么星环要设计一个新的合并方案来解决开源方案中的不足。
星环Galactus应运而生!!Galactus可以自动检测到小文件自动合并掉,用户无需担心因为处理不及时或有疏漏影响到业务系统,更加贴合生产上的需求。
星环是怎么做的?为什么不采用TORC Compact的逻辑?
TORC Compact是靠事务锁和事务ID来保证原子性以及读数的正确性的。所以事务表在合并一开始便会获取读锁,其他会造成影响的如truncate需要获取排他锁,所以truncate必须等到整个合并完成,这样才能保证合并过程的原子性;同时在读数的时候根据base的事务ID去过滤掉事务ID比它小的base和delta,保证了不会多读数。
但是对于非事务表来说,是没有这两个属性的,需要强行加上类似的锁机制和类事务ID来保证原子性以及确保不会多读数。
所以,星环的非事务表小文件合并设计方案设计了一些算法以及采用editlog reply机制实现了在没有事务控制下保证合并过程中的原子性以及不会多读数的目标。
对于实际业务来说,星环方案有哪些独特的优势?
- 在Compaction过程中,计算引擎端(quark)的业务,表的读,写,删除等操作能够不被长时间阻塞,并成功执行不报错;
- 即使客户通过HDFS CLIENT操作数据目录,合并也不会造成数据的丢失或增加;
- 开源产品如Hive/Spark也能用该方案解决小文件问题;
- 完善的回退机制,保证了数据的正确性以及editlog能被原HDFS正常重放,恢复到合并前;
- 该方案针对多次访问文件产生的大量开销做了优化,并且针对多个异常现象,如NN重启或者主从切换、合并前/中/后发生了目录或文件的mv,cp,truncate等操作,该方案都做了完备的处理机制,以保障系统整体的一致性、原子性以及正确性。
客户案例
星环某一从CDH迁移过来的客户,业务系统中共有72个库,近万张表,其中Quark 数据目录下共约3600万个文件,除此之外,每天平均入库40~50万个文件。
在开启Galactus一周后,系统文件数量减少了13%,每天合并80万个小文件,充分覆盖了增量文件。整体的绩效业务跑批性能提升了一倍以上。
截至目前,该功能共计为客户合并了9000w+个小文件,文件对象从8600w+降低至6900w+。
使用Demo/最佳实践
前期准备
版本检查
在使用前,用户需要检查当前环境版本是否满足下方要求:
a. 商业版:TDH 6.2.2或9.3.2及以上版本,HDFS及Inceptor打最新Patch
b. 社区版:TDH-CE-24-5版本
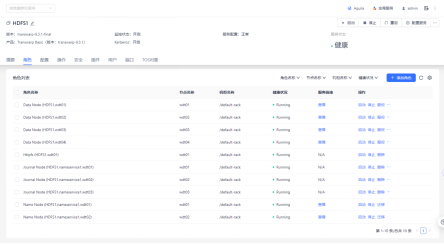
HDFS状态检查
检查HDFS角色状态和pod状态,保证hdfs的状态是正常可以使用的;
① 角色状态检查
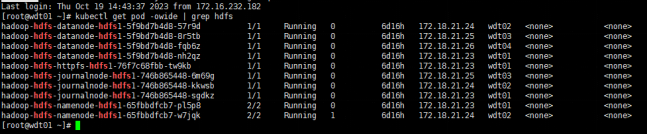
② Pod检查
执行:kubectl get pod -owide | grep hdfs
FSImage检查
① 首先找到dfs.namenode.name.dir的路径
② 找到namenode的active和stand by节点
③ 依次检查active节点dfs.namenode.name.dir路径的fsimage,确保数据日期和实际的日期相差在1h之内。
④ 依次检查stand by节点dfs.namenode.name.dir路径的fsimage,确保和active的一致。
HDFS summary检查
检查hdfs的元数据个数,文件及文件数的个数,以及文件总大小。
HDFS count检查
命令:hdfs dfs -count /quark(n)
Database个数检查
命令:Show databases;
非事务表个数检查
查询命令:
SELECT * FROM system.tables_v
WHERE table_format IN ('text','orc')
AND transactional = 'false';
Quark部署
Galactus禁止部署在批处理quark和重要业务查询的quark上。因此,用户在使用前需要新建一个quark,专门用于galactus小文件合并作业,每个节点均需安装executor,资源要求配置为单核,内存3GB。
配置所需参数
参数配置方法
① 登录到manager页面,点击Transwarp inceptor的quark服务进入服务详情页面
② 点击配置模块的“添加自定义参数”按钮,进入添加页面,配置文件选择hive-site.xml,配置项参考下一小节;
③ 注意:在添加完参数后可以参考后续章节选择对不同的配置项赋予不同的值。比如点击右侧的编辑,将自动合并的参数quark.galactus.compact.auto.enabled设置为true;
④ 参数配置完成后,均需先重新配置服务,再重启quark;
涉及的参数配置项
以下参数均是全局参数,需要基于上一小节的方法在manager页面添加自定义参数及对应的参数值进行配置。全局参数列表如下:
| 参数 | 值 | 功能描述 |
| quark.galactus.compact.on.server | true | 在Quark Server上开启compaction功能 |
| quark.galactus.compact.auto.enabled | false/true | 开启/关闭自动compact功能 |
| quark.galactus.compact.check.interval | 3600000 | X小时检测一遍是否可合并(建议根据合并性能要求调整,比如1小时) |
| quark.galactus.compact.clean.interval | 4200000 | X小时后清理已经被合并的小文件;而由这些小文件合并生成的大文件在这些小文件被清理之前不会参与下一次的合并 |
| quark.galactus.compact.count | 10 | 目录下小于4M的小文件参与合并,超过10个小于4M的小文件才会触发合并;合并时10个小文件为一组合并为一个文件,最后如果还有剩余不足10个的小文件,则这些小文件合并为一个文件 |
| quark.galactus.upper.compact.size | 4194304 | |
| quark.galactus.compact.db.blacklist | aa,bb,cc | DB合并黑名单 |
| quark.galactus.compact.db.whitelist | dd,ee,ff | DB合并白名单 |
| quark.galactus.compact.file.fetch.size | 1000 | 自动合并时,默认值为1000/false,即一张表一次取1000个小文件参与合并,合并完成后,以同样的规则合并下一张表;若为true,则该表的全部小文件参与合并,完成后再去合并下一张表,手动合并时第二个参数默认为true,即每次取1000小文件参与合并,直至全表合并结束 |
| quark.galactus.compact.continue.to.finished | false/true |
合并操作
手动合并
手动合并涉及以下参数:
| 参数 | 值 | 功能描述 |
| quark.galactus.compact.on.server | true | 在Quark Server上开启compaction功能 |
| quark.galactus.compact.auto.enabled | false | 关闭自动compact功能 |
使用beeline或waterdrop连接需要合并小文件的表所在的数据库,可以对指定的表手动进行小文件合并,具体命令如下:
alter table table_name compact 'full'
合并过程中可以使用下方命令来查看表文件是否正在在合并(合并后的新文件格式为*_cpt_*):
dfs -ls hdfs路径
dfs -count hdfs路径
自动合并
自动合并涉及以下参数:
| 参数 | 值 | 功能描述 |
| quark.galactus.compact.on.server | true | 在Quark Server上开启compaction功能 |
| quark.galactus.compact.auto.enabled | true | 开启自动compact功能 |
| quark.galactus.compact.check.interval | 3600000 | X小时检测一遍是否可合并(建议根据合并性能要求调整,比如1小时) |
| quark.galactus.compact.clean.interval | 4200000 | X小时后清理已经被合并的小文件;而由这些小文件合并生成的大文件在这些小文件被清理之前不会参与下一次的合并 |
| holodesk.compact.init.interval(社区版不支持) | 60(s) | 设置 Init 线程 SLEEP 的时间 |
| holodesk.compact.table.interval(社区版不支持) | 300(s) | 设置同一张表同一分区执行 Compact 的最低间隔 |
| holodesk.compact.thread.max(社区版不支持) | 10 | 限制执行 COMPACT 的最大并发数 |
| holodesk.compact.worker.interval(社区版不支持) | 20(s) | 设置 worker 线程运行周期中 SLEEP 的时间 |
| holodesk.fullcompaction.single.task.filenum.threshold(社区版不支持) | 50(个) | 控制 fullcompact 单个 task 处理的小文件数量上限 |
- 开启自动合并开关,需要将quark.galactus.compact.auto.enabled设置为true;
- quark.galactus.compact.check.interval参数是合并时间间隔,推荐配置大于1小时,用户可以根据具体的业务情况来设置大小;
- quark.galactus.compact.clean.interval是清理小文件时间间隔,合并生成的大文件在小文件被清理之前不会参与下一次的合并,超过合并清理时间间隔后,合并后的文件如果符合规则,会参与下一次合并;
- 再次提醒:如果重新配置了参数值,需要重新配置服务和重启quark。
黑白名单
黑白名单涉及以下参数:
| 参数 | 值 | 功能描述 |
| quark.galactus.compact.db.blacklist | aa,bb,cc | DB合并黑名单 |
| quark.galactus.compact.db.whitelist | dd,ee,ff | DB合并白名单 |
黑白名单作用范围规则如下:
| 黑名单设置 | 白名单设置 | 合并范围 |
| 不设置 | 不设置 | 所有database均参与合并 |
| 不设置 | 设置 | 合并白名单内的database |
| 设置 | 不设置 | 合并不在黑名单内的database |
| 设置 | 设置 | 合并不在黑名单内但在白名单内的database即:not in 黑名单 and in 白名单 |
设置黑名单
设置后可以把黑名单内的database过滤掉,不参与小文件合并,多个DB之间用‘,’分割。设置后无论是手动合并还是自动合并,黑名单均生效。
比如想要设置仅session级别生效,则可以在查询的时候动态执行set quark.galactus.compact.db.blacklist=db_name1,db_name2;
如果需要全局生效,则可以在配置页面按照下方图片进行配置,配置后重新配置服务和重启quark即可。
![]()
设置白名单
设置后可以只合并白名单内的database,多个DB之间用‘,’分割。设置后无论是手动合并还是自动合并,白名单均生效。
比如想要设置仅session级别生效,则可以在查询的时候动态执行set quark.galactus.compact.db.writelist=db_name3,db_name4;
如果需要全局生效,则可以在配置页面按照下方图片进行配置,配置后重新配置服务和重启quark即可。
多线程
设置小文件合并的多线程并发数,参数为quark.galactus.compact.concurrency,默认为10。
回滚合并
小文件合并后,支持回滚到合并前的小文件,命令行输入以下命令,database和table输入需要回滚表的相关信息即可。
- 非安全模式下命令如下:
curl -XGET "http://host:8888/api/galactus/rollback?database=db_name&table=table_name"
- 安全模式下需要特别注意,命令后要加上Guardian-Access-Token,其中token的获取请参考Guardian产品手册 3.3.2. 小节-【使用Guardian Access Token访问服务】
curl -XGET "http://host:8888/api/galactus/rollback?database=db_name&table=table_name" --header 'Guardian-Access-Token:H5uFlWe0lKNZeQkP1jeZ-TDH'
注意:合并完成后,在quark.galactus.compact.clean.interval 时间内执行上述命令可以进行回滚。但如果超过quark.galactus.compact.clean.interval时间后再执行回滚的话,此时数据已被清理,则没有办法回滚。
检查合并效果
如果需要检查Galactus小文件合并效果可以通过以下几种方式查看监控:
1) HDFS Summary
通过对HDFS的summary上的文件数据和元数据数据的连续监控,计算出小文件合并的效率。
2) HDFS count
通过使用命令hdfs dfs -count /quarkn查看文件数量,并连续监控,计算出小文件合并的效率。
3) Aquila统计
将josn文件:非事务表小文件合并统计指标(GALACTUS).json和HDFS小文件监控.json导入即可。
通过Aquila上监控被合并的小文件数量和被清理的小文件数量,进而计算出小文件合并的效率。
 登录后可评论
登录后可评论








.jpg)



