TORC表格式对应的小文件合并方法
友情链接:
- Inceptor compact 性能优化方法
- TORC Compact 常见故障诊断方法
- ArgoDB Holodesk表格式对应的小文件合并方法 (Compact Service)
- ArgoDB归档分区功能介绍及使用方法
- Text/ORC非事务表合并最佳方式
- 【小文件详解】不同阶段下的小文件治理最佳解决手段
前情提要
在实际业务中,小文件现象出现频率并不低,当小文件过多时,将会导致内存占用高、集群不稳定,增加计算资源的开支等一系列问题,因此解决小文件问题迫在眉睫!!
由于篇幅限制,欲了解小文件出现背景,原因分析,为什么要治理小文件,小文件过多的危害等方面的内容,可参考:【小文件详解】不同阶段下的小文件治理最佳解决手段
在前面介绍小文件治理相关的文章中有提到,小文件治理无外乎三个阶段,存储端、计算端以及SQL端。其中存储端合并指的是说当表中有小文件或者小文件过多时,可以通过合并已经写入到存储的文件来治理,主要适用于以下原因导致的小文件问题:
- 频繁的写入数据;
- torc表compact多次合并失败后进入黑名单,导致小文件不再继续合并;
- 历史数据流程导致小文件问题,这些数据一般是从别的数据库迁移过来,后续没有进行治理;
- 但是,不同的表格式的合并方式不同。本篇文章主要为读者介绍如何针对TORC(ORC Transaction)事务表做合并。
背景
Orc transaction表是一种inceptor中可以支持CRUD操作的的ORC表,其基本原理是对于每个crud操作(insert,update,delete,merge into),都会生成一个对应版本,同时系统中存在compact机制对每个orc transaction进行compact,将多个版本合并成一个版本。
执行方式
TORC表中的Compact类型主要为Major Compact,禁止使用Minor Compact哦。
A. 同步compact(自动)
命令:alter table tblName compact 'major' and wait;
在beeline执行该命令后,会一直等待,直到通过该命令成功提交compaction任务,并成功执行compact,该命令才显示执行成功。否则会基于下方两个场景抛出异常:
① 如果compaction队列中已经有了该表或者分区(可能是后台服务添加,也可能是其他用户通过命令行添加),则抛出异常;
② 如果compact期间失败,则抛出异常;
可以通过配置一些参数来触发major compact,比如:
//当系统中没有base版本,则当delta版本大于10时;
//当系统中有base版本,则当所有delta版本的数据量达到base版本数据量的10%或者delta版本个数大于50时;
分别对应于参数:
//hive.compactor.delta.num.threshold.without.base default value 10
//hive.compactor.delta.pct.threshold default value 0.1
//hive.compactor.delta.num.threshold default value 50
B. 异步compact
命令:alter table tblName compact 'major';
执行该命名,相当于在后台提交了compact请求,beeline会立刻返回并显示执行成功。至于compact是否真正成功执行,需要查看log。
查看任务队列
可以通过下方命令查看合并任务的队列情况,包括合并完成的,合并中的,等待合并的任务。
命令:show compactions;
Compaction Blacklist黑名单机制
如果一个表或者分区在多次尝试compact并且失败,compaction 服务会认为后续再对这个表或分区compact同样会失败。为了避免浪费资源,comapction服务会将这个表或分区加入compaction blacklist。
目前失败次数由参数orc.compact.blacklist.threshold控制,默认值是3。
表或分区一旦加入黑名单,无论自动或手动触发compaction,都不会执行compact操作。
目前还没有从compaction blacklist中自动移除的机制。
查看黑名单
可以在beeline通过以下命令查看:
命令:show compact blacklist;
从黑名单中移除
对于进入黑名单的表或分区,需要及时将其从黑名单中移除,便于其进行小文件合并,可以通过:
alter table table_name enable compact; // 表
alter table table_name partition (pt='xxx') enable compact; // 单值分区
alter table table_name partition range_name enable compact; // 范围分区
用户也可以在mysql中,直接删除COMPACTION_BLACKLIST中的记录。
手动加入黑名单
可以使用下方命令手动将某个表或分区加入黑名单,不让其做compaction:
alter table table_name disable compact; // 表
alter table table_name partition (pt='xxx') disable compact; // 单值分区
alter table table_name partition range_name disable compact; // 范围分区
注意事项
① 分桶表:跨分桶不能进行合并
② 分区表:跨分区不能进行合并
常见报错与解决方案
1. 表进入黑名单怎么办
通过show compact blacklist命令,发现表在黑名单里,说明之前已经compact失败多次。如果能找到之前失败的日志可做进一步分析报错,如果无法找到,则可以先将该表或分区从blacklist中移除(alter table table_name enable compact;),然后手动触发compaction(alter table table_name compact ‘major’;),再根据如下情况做分析。
2. 报错NPE或者 dir is null, the table or partition is invalid for compaction at present
日志中出现NPE(Java.lang.NullPointerException)或者 dir is null, the table or partition is invalid for compaction at present,基本是高并发情况下,如果系统中某些表或分区长时间处于open状态(未提交也未rollback),使得系统中的表都无法满足compact条件,此时需等系统并发降低或者对orc事务表操作空闲的时候,触发compact。
3. 数据倾斜
在yarn页面中,也可以看到大部分任务快速完成,少量任务执行时间特别长,点开耗时很长的任务,可以看到有重试情况,并且重试都失败。这是因为mapreduce的推断执行机制,重试的任务失败,整个task会被kill掉。可以配置yarn的参数mapreduce.map.speculative=false并重启yarn和inceptor则可以解决。
更多有关TORC Compact 的常见故障诊断方法可参考: https://community.transwarp.cn/article/272
操作实践
社区版核心组件为Inceptor,因此下面将以具体例子来演示TORC表中Compact的过程:
1. 创建一张orc transaction表
create table orc_transaction_table(id int, value1 int, value2 int, value3 int) clustered by (id) into 2 buckets stored as orc tblproperties('transactional'='true');
建好表之后用desc formatted orc_transaction_table命令来获取该表在hdfs上的位置
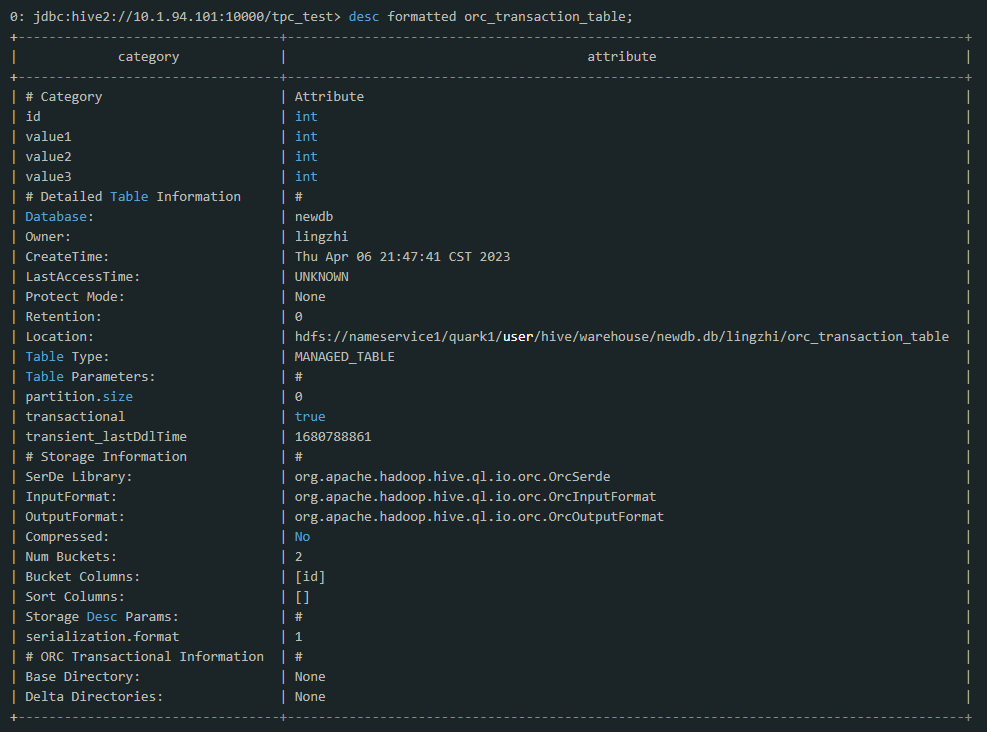
通过hdfs命令来看当前表所在目录下的内容

可以看到表创建好时,目录是空的。
2. 插入数据
用insert语句向该表插入一条数据:
insert into orc_transaction_table values(1,2,3,4); 1 rows affected. Time taken: 1.747 seconds
这时候重新查看hdfs再看表目录:

可以看到多了一个delta开始的目录,这种delta目录就对应了表的一个版本,delta中的数字代表该crud操作的transaction号。
3. 更新数据
用update命令更新该表并观察hdfs上的内容:
update orc_transaction_table set value3 = 10 where id = 1;
重新查看

可见update操作为表添加了一个新的版本。
4. Compact机制
对于orc表的多个版本,inceptor系统中专门有compact机制来负责在合适的时候对多版本进行合并。目前compact由metastore的compact thread在后台自动检测并合并。同时也可以通过命令alter table tablename compact compactType来手动触发compact,例如:
alter table orc_transaction_table compact 'major';
注意:alter table compact命令是异步的,该命令本身只是发出一个compact请求,其本身并不做compact操作,所以很快会结束。
目前,compact任务根据配置可以是一个mapreduce任务,也可以是spark任务(下面的示例我们将以mapreduce的方式进行compact)。
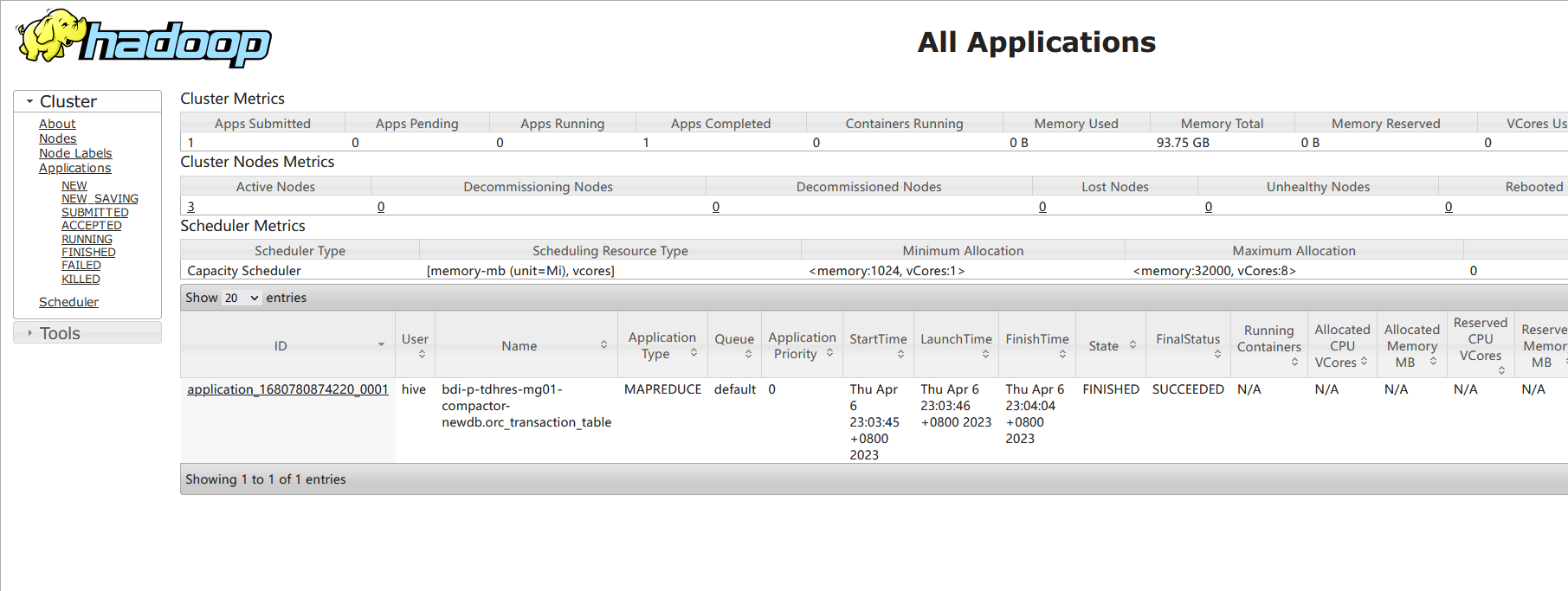
- 当设置orc.compact.service.provider=metastore 时,compact threads内嵌在metastore中,compact任务是一个mapreduce任务;我们可以在yarn的8088页面上看到(compact任务的名称类似与test-02-23-compactor-crud001.orc_transaction_table);
- 当设置orc.compact.service.provider=server时,compact threads内嵌在server中,compact任务是一个spark任务,我们可以在spark的4040页面上看到(compact任务的sql类似于compact xxx ‘major’);
查看compact由metastore还是compactservice执行:show compact location;
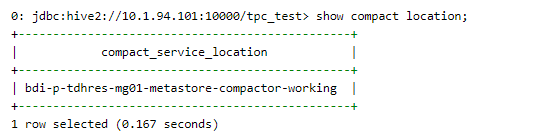
注:设置orc.compact.service.provider=metastore或者orc.compact.service.provider=server时要设置在hive-site里面, 不能直接beeline中set;或者也可以在manager里面加配置, 然后重启;
我们可以在yarn的8088页面上看到(compact任务的名称类似与test-02-23-compactor-crud001.orc_transaction_table);
在compact任务成功结束之后,再观察hdfs上的内容:
可见major compact后,系统会产生一个base开始的目录,记录了到transaction号0000081为止,该表的全部内容。

如果在往该表插入新的记录,则会生产新的delta版本:

一段时间之后在查看hdfs目录可以发现这两个版本被自动合并成了一个新版本:

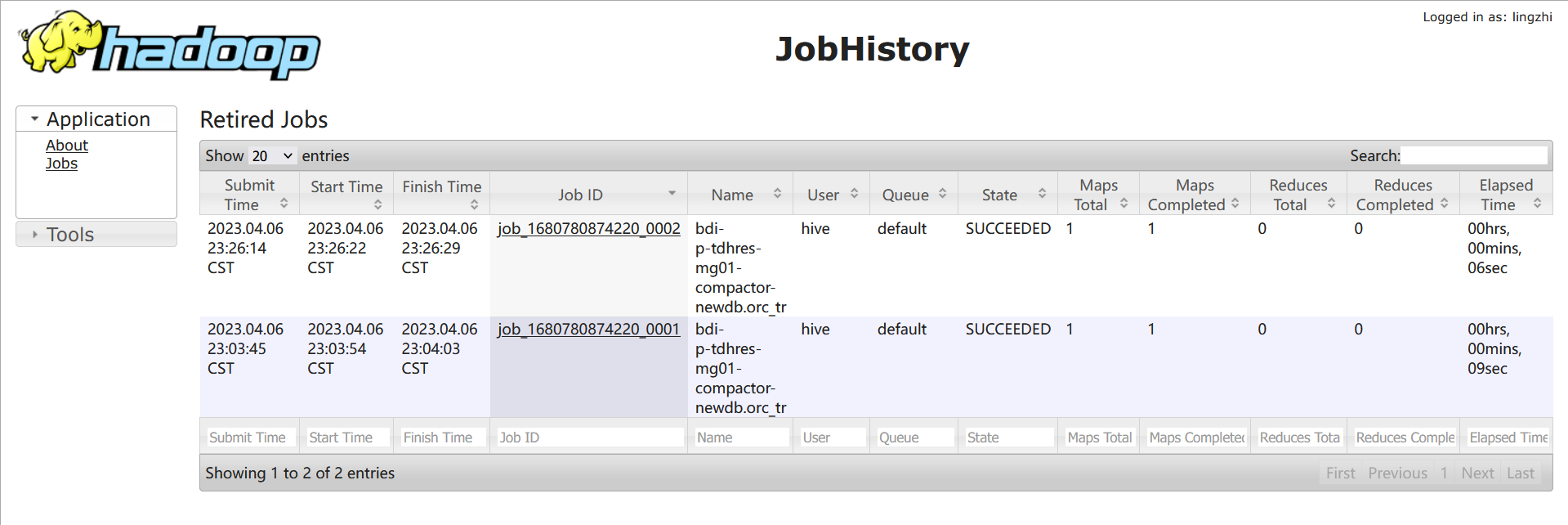
这是compact thread在后台自动做的compact,目前后台的compact触发条件是:
- 当系统中没有base版本,则当delta版本大于10时触发major compact;
- 当系统中有base版本,则当所有delta版本的数据量达到base版本数据量的10%或者delta版本个数大于50时,自动触发major compact;
这些触发条件都是可以配置的,分别对应于参数:
- hive.compactor.delta.num.threshold.without.base default value 10
- hive.compactor.delta.num.threshold default value 50
- hive.compactor.delta.pct.threshold default value 0.1
Compact结果校验方式
torc普通表
1) 通过desc formatted pre_torc1_2查看delta文件是否合并成了base文件
2) 表compaction_queue_v中的compaction_state的值
3) show compactions;
4) hdfs路径
torc分区表
1) 表compaction_queue_v中compaction_state的值
2) show compactions;
3) hdfs路径
写在最后
以上就是当前TORC表如何合并小文件的全部内容,如需了解更多其他表格式的合并方式可参考:
友情链接:
- Inceptor compact 性能优化方法
- TORC Compact 常见故障诊断方法
- ArgoDB Holodesk表格式对应的小文件合并方法 (Compact Service)
- ArgoDB归档分区功能介绍及使用方法
- Text/ORC非事务表合并最佳方式
- 【小文件详解】不同阶段下的小文件治理最佳解决手段
前情提要
在实际业务中,小文件现象出现频率并不低,当小文件过多时,将会导致内存占用高、集群不稳定,增加计算资源的开支等一系列问题,因此解决小文件问题迫在眉睫!!
由于篇幅限制,欲了解小文件出现背景,原因分析,为什么要治理小文件,小文件过多的危害等方面的内容,可参考:【小文件详解】不同阶段下的小文件治理最佳解决手段
在前面介绍小文件治理相关的文章中有提到,小文件治理无外乎三个阶段,存储端、计算端以及SQL端。其中存储端合并指的是说当表中有小文件或者小文件过多时,可以通过合并已经写入到存储的文件来治理,主要适用于以下原因导致的小文件问题:
- 频繁的写入数据;
- torc表compact多次合并失败后进入黑名单,导致小文件不再继续合并;
- 历史数据流程导致小文件问题,这些数据一般是从别的数据库迁移过来,后续没有进行治理;
- 但是,不同的表格式的合并方式不同。本篇文章主要为读者介绍如何针对TORC(ORC Transaction)事务表做合并。
背景
Orc transaction表是一种inceptor中可以支持CRUD操作的的ORC表,其基本原理是对于每个crud操作(insert,update,delete,merge into),都会生成一个对应版本,同时系统中存在compact机制对每个orc transaction进行compact,将多个版本合并成一个版本。
执行方式
TORC表中的Compact类型主要为Major Compact,禁止使用Minor Compact哦。
A. 同步compact(自动)
命令:alter table tblName compact 'major' and wait;
在beeline执行该命令后,会一直等待,直到通过该命令成功提交compaction任务,并成功执行compact,该命令才显示执行成功。否则会基于下方两个场景抛出异常:
① 如果compaction队列中已经有了该表或者分区(可能是后台服务添加,也可能是其他用户通过命令行添加),则抛出异常;
② 如果compact期间失败,则抛出异常;
可以通过配置一些参数来触发major compact,比如:
//当系统中没有base版本,则当delta版本大于10时;
//当系统中有base版本,则当所有delta版本的数据量达到base版本数据量的10%或者delta版本个数大于50时;
分别对应于参数:
//hive.compactor.delta.num.threshold.without.base default value 10
//hive.compactor.delta.pct.threshold default value 0.1
//hive.compactor.delta.num.threshold default value 50
B. 异步compact
命令:alter table tblName compact 'major';
执行该命名,相当于在后台提交了compact请求,beeline会立刻返回并显示执行成功。至于compact是否真正成功执行,需要查看log。
查看任务队列
可以通过下方命令查看合并任务的队列情况,包括合并完成的,合并中的,等待合并的任务。
命令:show compactions;
Compaction Blacklist黑名单机制
如果一个表或者分区在多次尝试compact并且失败,compaction 服务会认为后续再对这个表或分区compact同样会失败。为了避免浪费资源,comapction服务会将这个表或分区加入compaction blacklist。
目前失败次数由参数orc.compact.blacklist.threshold控制,默认值是3。
表或分区一旦加入黑名单,无论自动或手动触发compaction,都不会执行compact操作。
目前还没有从compaction blacklist中自动移除的机制。
查看黑名单
可以在beeline通过以下命令查看:
命令:show compact blacklist;
从黑名单中移除
对于进入黑名单的表或分区,需要及时将其从黑名单中移除,便于其进行小文件合并,可以通过:
alter table table_name enable compact; // 表
alter table table_name partition (pt='xxx') enable compact; // 单值分区
alter table table_name partition range_name enable compact; // 范围分区
用户也可以在mysql中,直接删除COMPACTION_BLACKLIST中的记录。
手动加入黑名单
可以使用下方命令手动将某个表或分区加入黑名单,不让其做compaction:
alter table table_name disable compact; // 表
alter table table_name partition (pt='xxx') disable compact; // 单值分区
alter table table_name partition range_name disable compact; // 范围分区
注意事项
① 分桶表:跨分桶不能进行合并
② 分区表:跨分区不能进行合并
常见报错与解决方案
1. 表进入黑名单怎么办
通过show compact blacklist命令,发现表在黑名单里,说明之前已经compact失败多次。如果能找到之前失败的日志可做进一步分析报错,如果无法找到,则可以先将该表或分区从blacklist中移除(alter table table_name enable compact;),然后手动触发compaction(alter table table_name compact ‘major’;),再根据如下情况做分析。
2. 报错NPE或者 dir is null, the table or partition is invalid for compaction at present
日志中出现NPE(Java.lang.NullPointerException)或者 dir is null, the table or partition is invalid for compaction at present,基本是高并发情况下,如果系统中某些表或分区长时间处于open状态(未提交也未rollback),使得系统中的表都无法满足compact条件,此时需等系统并发降低或者对orc事务表操作空闲的时候,触发compact。
3. 数据倾斜
在yarn页面中,也可以看到大部分任务快速完成,少量任务执行时间特别长,点开耗时很长的任务,可以看到有重试情况,并且重试都失败。这是因为mapreduce的推断执行机制,重试的任务失败,整个task会被kill掉。可以配置yarn的参数mapreduce.map.speculative=false并重启yarn和inceptor则可以解决。
更多有关TORC Compact 的常见故障诊断方法可参考: https://community.transwarp.cn/article/272
操作实践
社区版核心组件为Inceptor,因此下面将以具体例子来演示TORC表中Compact的过程:
1. 创建一张orc transaction表
create table orc_transaction_table(id int, value1 int, value2 int, value3 int) clustered by (id) into 2 buckets stored as orc tblproperties('transactional'='true');
建好表之后用desc formatted orc_transaction_table命令来获取该表在hdfs上的位置
通过hdfs命令来看当前表所在目录下的内容
可以看到表创建好时,目录是空的。
2. 插入数据
用insert语句向该表插入一条数据:
insert into orc_transaction_table values(1,2,3,4); 1 rows affected. Time taken: 1.747 seconds
这时候重新查看hdfs再看表目录:
可以看到多了一个delta开始的目录,这种delta目录就对应了表的一个版本,delta中的数字代表该crud操作的transaction号。
3. 更新数据
用update命令更新该表并观察hdfs上的内容:
update orc_transaction_table set value3 = 10 where id = 1;
重新查看
可见update操作为表添加了一个新的版本。
4. Compact机制
对于orc表的多个版本,inceptor系统中专门有compact机制来负责在合适的时候对多版本进行合并。目前compact由metastore的compact thread在后台自动检测并合并。同时也可以通过命令alter table tablename compact compactType来手动触发compact,例如:
alter table orc_transaction_table compact 'major';
注意:alter table compact命令是异步的,该命令本身只是发出一个compact请求,其本身并不做compact操作,所以很快会结束。
目前,compact任务根据配置可以是一个mapreduce任务,也可以是spark任务(下面的示例我们将以mapreduce的方式进行compact)。
- 当设置orc.compact.service.provider=metastore 时,compact threads内嵌在metastore中,compact任务是一个mapreduce任务;我们可以在yarn的8088页面上看到(compact任务的名称类似与test-02-23-compactor-crud001.orc_transaction_table);
- 当设置orc.compact.service.provider=server时,compact threads内嵌在server中,compact任务是一个spark任务,我们可以在spark的4040页面上看到(compact任务的sql类似于compact xxx ‘major’);
查看compact由metastore还是compactservice执行:show compact location;
注:设置orc.compact.service.provider=metastore或者orc.compact.service.provider=server时要设置在hive-site里面, 不能直接beeline中set;或者也可以在manager里面加配置, 然后重启;
我们可以在yarn的8088页面上看到(compact任务的名称类似与test-02-23-compactor-crud001.orc_transaction_table);
在compact任务成功结束之后,再观察hdfs上的内容:
可见major compact后,系统会产生一个base开始的目录,记录了到transaction号0000081为止,该表的全部内容。
如果在往该表插入新的记录,则会生产新的delta版本:
一段时间之后在查看hdfs目录可以发现这两个版本被自动合并成了一个新版本:
这是compact thread在后台自动做的compact,目前后台的compact触发条件是:
- 当系统中没有base版本,则当delta版本大于10时触发major compact;
- 当系统中有base版本,则当所有delta版本的数据量达到base版本数据量的10%或者delta版本个数大于50时,自动触发major compact;
这些触发条件都是可以配置的,分别对应于参数:
- hive.compactor.delta.num.threshold.without.base default value 10
- hive.compactor.delta.num.threshold default value 50
- hive.compactor.delta.pct.threshold default value 0.1
Compact结果校验方式
torc普通表
1) 通过desc formatted pre_torc1_2查看delta文件是否合并成了base文件
2) 表compaction_queue_v中的compaction_state的值
3) show compactions;
4) hdfs路径
torc分区表
1) 表compaction_queue_v中compaction_state的值
2) show compactions;
3) hdfs路径
写在最后
以上就是当前TORC表如何合并小文件的全部内容,如需了解更多其他表格式的合并方式可参考:
 登录后可评论
登录后可评论








.jpg)



