分布式计算框架系列文章(二)数据倾斜现象诱因、原理、影响,以及星环对此的应对策略
友情链接
- 分布式计算框架系列文章(一)MR框架工作流程详解以及框架限制
- 分布式计算框架系列文章(二)数据倾斜现象诱因、原理、影响,以及星环对此的应对策略
- 分布式计算框架系列文章(三)星环科技计算引擎针对数据倾斜现象的引擎保护机制
- 分布式计算框架系列文章(四)当出现数据倾斜时如何应对--倾斜key单独处理/MapJoin/星环SkewJoin的原理及使用方法
数据倾斜是什么
从本质上来看,数据倾斜指的是说在并行处理海量数据的时候,某个或者某些分区的数据分布不均匀导致引起性能瓶颈的情况。那么为什么会出现数据分布不均匀的情况?
原理其实很简单,主要是因为key分布不均匀,重复的key很多,个别节点出现过载和拥塞。
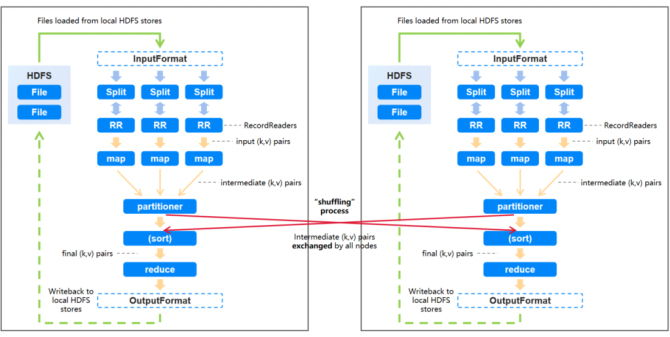
我们先来简单回顾下上一篇长提到的MapReduce的流程图,可以看到,输入的数据集被拆分成多个独立的部分(InputSplit)后会被分散到不同的节点上进行处理,生成多个Map tasks。
RecordReader会将数据转换为适合mapper读取的键值对后会发送到mapper进行进一步处理。Mapper针对每条输入记录(来自RecordReader)进行处理并生成新的键值对,对这些数据通过hash等方式散列到不同的reducer,然后开始spill(溢写)写入磁盘。
如果不同key的数据量分布不均,个别key对应的数据量特别大的话,就会发生数据倾斜。
比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了,个别task可能分配到了100万数据,要运行一两个小时,最终等待时间可能会超出可接受范围,也可能会导致负载不均衡超出节点的计算能力,个别节点成为性能瓶颈。
下面我们举个例子来进一步理解,假设有这么两组数据:
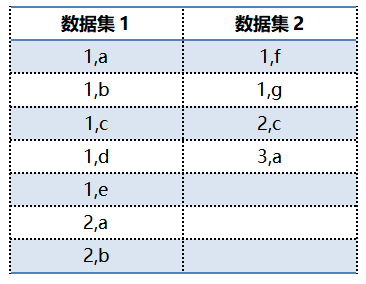
在MR程序启动后,Mappers从两个数据集中读取输入数据,partitioner获取中间输出后,基于key进行分区。
在进行shuffle的时候,通常会将同样的key对应的数据拉取到同一个task中进行处理,这个时候我们可以看到下方对应的task1就存在着数据倾斜的问题。
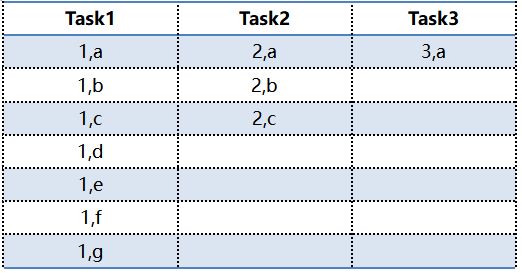
在这种情况下,Task2/Task3将比Task1更快的完成任务,因为Task1需要处理的数据更多。那可想而知,如果业务上存在大量key=1的倾斜数据,那么Task1对应的节点就会出现过载和拥塞,导致计算系统效率低下,最终由于读取过多数据引起task不稳定甚至故障。
如何判断是否出现数据倾斜
出现数据倾斜会存在以下现象:
- 在并行处理海量数据的时候,某个或者某些分区的数据更多,导致引起性能瓶颈。比如有1000个task,有999个1ms搞定了,但是有一个要1min才能结束就是发生数据倾斜了;
- 大部分 task 都执行迅速,但是有的 task 在运行过程中会突然报出 OOM,反复执行几次都在某一个 task 报出 OOM 错误,此时可能出现了数据倾斜,作业无法正常运行;
- 运行过程中出现Data skew for single key found等报错提醒(具体详见下方<保护机制>的部分);
Task数量是如何决定的
Inceptor的后台执行引擎是Spark,Spark的基本执行单位是Task,Task的数目是由RDD的分区数决定的。Inceptor中把一个SQL的执行划分为map阶段和reduce阶段,这两个阶段的task数目受到很多因素影响。具体内容请查看: Task的数量是如何决定的
引起数据倾斜的诱因
引发数据倾斜的因素可能有很多,比如某些SQL语句设置不当、建表时考虑不周等等,可能是业务特性导致,也有可能是数据加工过程导致。通常数据倾斜的现象主要出现在两大阶段,shuffle写、shuffle读。
Shuffle运行流程
什么是shuffle?
在大数据处理的分布式计算环境中,Shuffle阶段扮演着数据处理流程中的重要角色,具有将不同计算阶段相连、优化数据访问、提升整体处理性能的关键作用。Shuffle 的核心原理在于有效地管理和调整分布在多个计算节点(node)上的数据,以优化后续复杂操作的执行效率。在这个阶段,数据从初始的分散状态被重新组织和重新分配,以便使具有某种共同特征(相同键key或条件)的一类数据可以被最终聚合到同一个计算节点上进行计算,为接下来的计算操作提供理想的数据访问方式。这些数据分布在各个不同的存储节点上,并且要被不同的节点的计算单元处理。根据特定的分片规则进行重新分片然后聚合到不同的节点的过程就是Shuffle。
Shuffle 的重要性在于,它可以极大地提升大数据处理的效率。通过将相同键的数据集中在一起,Shuffle 操作可以减少多次数据扫描和处理的开销。同时,通过优化数据分配以及通信策略,Shuffle 可以减少不必要的数据移动,从而降低整体处理时间。
Shuffle的过程主要分为两个部分,shuffle write和shuffle read。
Shuffle Write
ShuffleWriter有很多,常见的两种开源的writer是Hash Shuffle Write以及Sort Shuffle Write,但是均存在一些缺点,如下所述:
① Hash Shuffle Write
Hash Shuffle Write主要是在过程中按照Hash的方式重组Partition的数据,不进行排序(比sort要快)。这种方式可以减少内存存储空间压力,也有一定容错性可以避免重算。具体是每个ShuffleMapTask根据key的哈希值计算出每个key需要写入的partition,然后将数据单独写入一个文件。下游的Task通过网络或者本地的硬盘读写,读取这个文件并进行计算。
但是存在一些弊端,比如每个map端的任务为每个reduce端的Task生成一个文件,通常会产生大量的文件(即对应为M*R个中间文件,其中M表示map端的Task个数,R表示reduce端的Task个数),伴随大量的随机磁盘IO操作与大量的内存开销。如果文件数量特别巨大,对文件读写的性能会带来比较大的影响,此外由于同时打开的文件句柄数量众多,序列化,以及压缩等操作需要分配的临时内存空间也可能会迅速膨胀到无法接受的地步,对内存的使用和GC带来很大的压力,在Executor内存比较小的情况下尤为突出,例如Spark on Yarn模式。
② Sort shuffle write
Sort shuffle write则是单map单文件,map端的任务会按照key对应的PartitionID进行排序,容量可能会超过内存阈值溢写到硬盘,然后会通过mergeSort合并所有的溢写文件和内存中的数据,写到一个大的输出文件中,同时生成一个index文件记录每个partition的数据量。reduce端的Task可以通过该索引文件获取相关的数据。
这种方式在写入分区数据的时候,首先会根据实际情况对数据采用不同的方式进行排序操作,底线是至少按照Reduce分区Partition进行排序,这样来自于同一个Map任务Shuffle到不同的Reduce分区中去的所有数据都可以写入到同一个外部磁盘文件中去,用简单的Offset标志不同Reduce分区的数据在这个文件中的偏移量。所以Index文件中会记录不同的Partition的range信息(offset+length),各个reducer根据offset和length来fetch自己的信息。
采用Sort shuffle write的方式的话,一个Map任务就只需要生成一个shuffle文件,从而避免了上述HashShuffleManager可能遇到的文件数量巨大的问题。但是如果mapper数量大,依旧会产生很多小文件,reduce需要同时打开大量的记录来进行反序列化,同样会导致大量的内存消耗和GC负担。
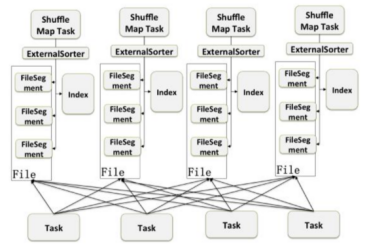
星环的技术方案
综上,无论是哪一种shuffle写的方式都会存在一定的内存消耗和GC负担,为了避免上述的情况,星环的计算引擎采用的方式是Data sequence base shuffle。
这种方式继承了HashShuffle的优势,不单单只是针对原始数据进行排序。这里的排序指的是说比如在SortShuffle中会根据partitionID排序,排序不可避免的会带来cpu压力以及内存压力。
Data sequence base shuffle的方式是根据数据到达的时间加了一个单调递增的key(生成ShuffleID),然后后续Shuffle下游就可以请求MapOutputTrackerMaster,然后根据shuffleID拿到shuffle信息来做shuffle了。
Shuffle Read
在开源的框架中,不同的shuffle方式有各自对应的ShuffleWriter,但是通常共用一个ShuffleReader,即org.apache.spark.shuffle.hash.HashShuffleReader,会在parentstage的所有ShuffleMapTasks结束后再进行读取。处理过程如下:
- ① Shuffle Write阶段所涉及的数据通过排序或其他形式完成写入后,mapper端会将数据通过RPC发送给各个storage;
- ② ReduceTask在拉取storage数据的时候会先用BlockStoreShuffleFetcher来从MapOutputTrackerMaster中请求status的结果(shuffleId,reduceId)获取shuffle块的位置以及想要的数据的信息,请求后将返回Seq[(BlockManagerId,Seq[(BlockId,Long)])];
- ③ 然后接下来对刚刚拉取的数据进行一些数据结构上的转换操作,封装转型成Iterator,ShuffleBlockFetcherIterator构造以后,根据BlockManagerId判断读取策略(本地/远程),本地的话可以根据blockId进行本地数据块的读取,也可以去远程ShuffleMapTask所在的节点的BlockManager去拉取需要聚合的数据;
- ④ 最后,将拉取到的数据,执行一些转换和封装,返回。
星环的技术方案
但是,上述方式可能会存在一定风险,比如inceptor server的内存达到上限爆掉。因此在新版本TDH中针对Shuffle reader做了优化,数据将放在不同的executor中,不再使用集中管理的status,尽管维护复杂度会有增高,但是保护了inceptor server的内存。
ShuffleWrite阶段存在的数据倾斜问题
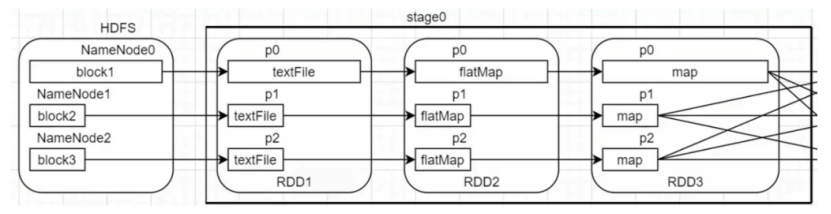
这种情况引起数据倾斜的主要地方是在shuffle writer的过程,但是算子我们是没有办法干涉处理过程中的数据倾斜。从上面的流程也可以看出,是mapper在读取数据本身的时候,数据本身就不正常才会导致这个问题。
需要注意的是,星环科技的计算框架在运行的时候是有做倾斜检查的,所以如果在生产过程中出现了倾斜大多数情况下可能是因为业务特性导致,比如说业务数据本身的特性:
在实际生产中,大部分数据都是有偏差的,比如维度表中的数据一般比较固定,数据有限,但是事实表可能会随着业务实时增长。这种情况下如果没有处理好业务逻辑(事实表关联事实表导致数据膨胀),可能就会导致数据倾斜的风险。
所以当发生数据倾斜的情况时,需要最先判断是否是业务逻辑不合理导致,是否有优化空间,再考虑进行技术方案的优化。
ShuffleRead阶段导致的数据倾斜问题
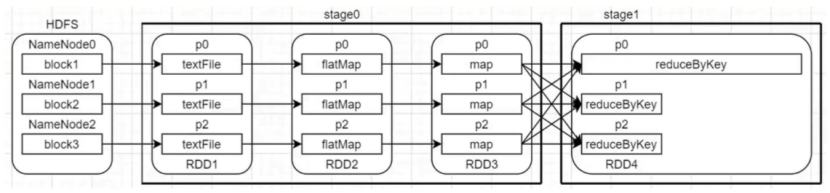
这种情况起因是聚合数据的算子产生的问题,这时候也要从数据本身去找问题,造成聚合数据异常的原因是在shuffle的过程中key hash之后对reducer partitionNum取余后比较集中导致的。
出现这个问题的常见诱因有:大量的空值,处理耗时导致倾斜。
在实际业务中可能会有大量的null值或者一些无意义的数据参与到计算作业中,比如null值。Null值可能在下述两个阶段产生:
1)原始阶段--表中本身就存在大量的null值(例. text表导入的文件有些没有值就会变成null),所有的null值都会被分配到一个reducer中进行处理,除了耗时之外可能也会产生数据倾斜,对于这种情况产生的倾斜问题就需要从业务侧进行修改。
2)数据加工阶段(计算过程中)--进行join操作的时候由于数据匹配不上出现null值;
当涉及到多个数据表时,JOIN是SQL中最常用的操作之一。JOIN的作用是将多个数据表中的数据组合在一起,从而使用户可以根据不同的条件组合过滤和查询多个表中的数据,最终提取记录形成一个新的结果集,实现数据关联和查询分析。
数据倾斜会有什么影响
1)浪费计算资源,资源利用率下降
在分阶段执行任务的场景下,stage与stage之间通常存在数据上的依赖关系,前一个stage完成之前,后续的stage则无法开始。
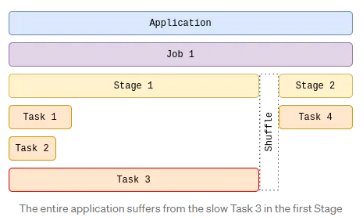
比如下图中stage2依赖stage1产生的数据结果,那么stage2必须等待stage1执行完成后才能开始。尽管stage1中其他两个task已经提前完成了,但是task3因为执行的数据量过大还在执行中,所以stage2将一直处于等待状态。
此时资源被长时间占用但是只有极少数task在执行,大多数的资源都在等待第一阶段的所有任务都完成后,才能继续提供给其他任务,比如Task4。
2)stage执行时间超出预期,导致后续依赖数据结果的作业出错
有时stage与stage之间,并没有构建强依赖关系,而是通过执行时间的前后时间差来调度,当前置stage未在预期时间范围内完成执行,那么当后续stage启动时便无法读取到其所需要的最新数据,从而导致连续出错。
3)引发内存溢出,导致集群崩坏
数据发生倾斜时,可能导致大量数据集中在少数几个节点上,在计算执行中由于要处理的数据超出了单个executor的能力范围,最终导致内存被撑爆,集群崩坏。
由于篇幅原因,下一篇将为您讲述星环针对上述问题以及出现数据倾斜情况下的引擎保护机制,如何避免出现上述问题。
下一篇:分布式计算框架系列文章(三)星环科技计算引擎针对数据倾斜现象的保护机制
友情链接
- 分布式计算框架系列文章(一)MR框架工作流程详解以及框架限制
- 分布式计算框架系列文章(二)数据倾斜现象诱因、原理、影响,以及星环对此的应对策略
- 分布式计算框架系列文章(三)星环科技计算引擎针对数据倾斜现象的引擎保护机制
- 分布式计算框架系列文章(四)当出现数据倾斜时如何应对--倾斜key单独处理/MapJoin/星环SkewJoin的原理及使用方法
数据倾斜是什么
从本质上来看,数据倾斜指的是说在并行处理海量数据的时候,某个或者某些分区的数据分布不均匀导致引起性能瓶颈的情况。那么为什么会出现数据分布不均匀的情况?
原理其实很简单,主要是因为key分布不均匀,重复的key很多,个别节点出现过载和拥塞。
我们先来简单回顾下上一篇长提到的MapReduce的流程图,可以看到,输入的数据集被拆分成多个独立的部分(InputSplit)后会被分散到不同的节点上进行处理,生成多个Map tasks。
RecordReader会将数据转换为适合mapper读取的键值对后会发送到mapper进行进一步处理。Mapper针对每条输入记录(来自RecordReader)进行处理并生成新的键值对,对这些数据通过hash等方式散列到不同的reducer,然后开始spill(溢写)写入磁盘。
如果不同key的数据量分布不均,个别key对应的数据量特别大的话,就会发生数据倾斜。
比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了,个别task可能分配到了100万数据,要运行一两个小时,最终等待时间可能会超出可接受范围,也可能会导致负载不均衡超出节点的计算能力,个别节点成为性能瓶颈。
下面我们举个例子来进一步理解,假设有这么两组数据:
在MR程序启动后,Mappers从两个数据集中读取输入数据,partitioner获取中间输出后,基于key进行分区。
在进行shuffle的时候,通常会将同样的key对应的数据拉取到同一个task中进行处理,这个时候我们可以看到下方对应的task1就存在着数据倾斜的问题。
在这种情况下,Task2/Task3将比Task1更快的完成任务,因为Task1需要处理的数据更多。那可想而知,如果业务上存在大量key=1的倾斜数据,那么Task1对应的节点就会出现过载和拥塞,导致计算系统效率低下,最终由于读取过多数据引起task不稳定甚至故障。
如何判断是否出现数据倾斜
出现数据倾斜会存在以下现象:
- 在并行处理海量数据的时候,某个或者某些分区的数据更多,导致引起性能瓶颈。比如有1000个task,有999个1ms搞定了,但是有一个要1min才能结束就是发生数据倾斜了;
- 大部分 task 都执行迅速,但是有的 task 在运行过程中会突然报出 OOM,反复执行几次都在某一个 task 报出 OOM 错误,此时可能出现了数据倾斜,作业无法正常运行;
- 运行过程中出现Data skew for single key found等报错提醒(具体详见下方<保护机制>的部分);
Task数量是如何决定的
Inceptor的后台执行引擎是Spark,Spark的基本执行单位是Task,Task的数目是由RDD的分区数决定的。Inceptor中把一个SQL的执行划分为map阶段和reduce阶段,这两个阶段的task数目受到很多因素影响。具体内容请查看: Task的数量是如何决定的
引起数据倾斜的诱因
引发数据倾斜的因素可能有很多,比如某些SQL语句设置不当、建表时考虑不周等等,可能是业务特性导致,也有可能是数据加工过程导致。通常数据倾斜的现象主要出现在两大阶段,shuffle写、shuffle读。
Shuffle运行流程
什么是shuffle?
在大数据处理的分布式计算环境中,Shuffle阶段扮演着数据处理流程中的重要角色,具有将不同计算阶段相连、优化数据访问、提升整体处理性能的关键作用。Shuffle 的核心原理在于有效地管理和调整分布在多个计算节点(node)上的数据,以优化后续复杂操作的执行效率。在这个阶段,数据从初始的分散状态被重新组织和重新分配,以便使具有某种共同特征(相同键key或条件)的一类数据可以被最终聚合到同一个计算节点上进行计算,为接下来的计算操作提供理想的数据访问方式。这些数据分布在各个不同的存储节点上,并且要被不同的节点的计算单元处理。根据特定的分片规则进行重新分片然后聚合到不同的节点的过程就是Shuffle。
Shuffle 的重要性在于,它可以极大地提升大数据处理的效率。通过将相同键的数据集中在一起,Shuffle 操作可以减少多次数据扫描和处理的开销。同时,通过优化数据分配以及通信策略,Shuffle 可以减少不必要的数据移动,从而降低整体处理时间。
Shuffle的过程主要分为两个部分,shuffle write和shuffle read。
Shuffle Write
ShuffleWriter有很多,常见的两种开源的writer是Hash Shuffle Write以及Sort Shuffle Write,但是均存在一些缺点,如下所述:
① Hash Shuffle Write
Hash Shuffle Write主要是在过程中按照Hash的方式重组Partition的数据,不进行排序(比sort要快)。这种方式可以减少内存存储空间压力,也有一定容错性可以避免重算。具体是每个ShuffleMapTask根据key的哈希值计算出每个key需要写入的partition,然后将数据单独写入一个文件。下游的Task通过网络或者本地的硬盘读写,读取这个文件并进行计算。
但是存在一些弊端,比如每个map端的任务为每个reduce端的Task生成一个文件,通常会产生大量的文件(即对应为M*R个中间文件,其中M表示map端的Task个数,R表示reduce端的Task个数),伴随大量的随机磁盘IO操作与大量的内存开销。如果文件数量特别巨大,对文件读写的性能会带来比较大的影响,此外由于同时打开的文件句柄数量众多,序列化,以及压缩等操作需要分配的临时内存空间也可能会迅速膨胀到无法接受的地步,对内存的使用和GC带来很大的压力,在Executor内存比较小的情况下尤为突出,例如Spark on Yarn模式。
② Sort shuffle write
Sort shuffle write则是单map单文件,map端的任务会按照key对应的PartitionID进行排序,容量可能会超过内存阈值溢写到硬盘,然后会通过mergeSort合并所有的溢写文件和内存中的数据,写到一个大的输出文件中,同时生成一个index文件记录每个partition的数据量。reduce端的Task可以通过该索引文件获取相关的数据。
这种方式在写入分区数据的时候,首先会根据实际情况对数据采用不同的方式进行排序操作,底线是至少按照Reduce分区Partition进行排序,这样来自于同一个Map任务Shuffle到不同的Reduce分区中去的所有数据都可以写入到同一个外部磁盘文件中去,用简单的Offset标志不同Reduce分区的数据在这个文件中的偏移量。所以Index文件中会记录不同的Partition的range信息(offset+length),各个reducer根据offset和length来fetch自己的信息。
采用Sort shuffle write的方式的话,一个Map任务就只需要生成一个shuffle文件,从而避免了上述HashShuffleManager可能遇到的文件数量巨大的问题。但是如果mapper数量大,依旧会产生很多小文件,reduce需要同时打开大量的记录来进行反序列化,同样会导致大量的内存消耗和GC负担。
星环的技术方案
综上,无论是哪一种shuffle写的方式都会存在一定的内存消耗和GC负担,为了避免上述的情况,星环的计算引擎采用的方式是Data sequence base shuffle。
这种方式继承了HashShuffle的优势,不单单只是针对原始数据进行排序。这里的排序指的是说比如在SortShuffle中会根据partitionID排序,排序不可避免的会带来cpu压力以及内存压力。
Data sequence base shuffle的方式是根据数据到达的时间加了一个单调递增的key(生成ShuffleID),然后后续Shuffle下游就可以请求MapOutputTrackerMaster,然后根据shuffleID拿到shuffle信息来做shuffle了。
Shuffle Read
在开源的框架中,不同的shuffle方式有各自对应的ShuffleWriter,但是通常共用一个ShuffleReader,即org.apache.spark.shuffle.hash.HashShuffleReader,会在parentstage的所有ShuffleMapTasks结束后再进行读取。处理过程如下:
- ① Shuffle Write阶段所涉及的数据通过排序或其他形式完成写入后,mapper端会将数据通过RPC发送给各个storage;
- ② ReduceTask在拉取storage数据的时候会先用BlockStoreShuffleFetcher来从MapOutputTrackerMaster中请求status的结果(shuffleId,reduceId)获取shuffle块的位置以及想要的数据的信息,请求后将返回Seq[(BlockManagerId,Seq[(BlockId,Long)])];
- ③ 然后接下来对刚刚拉取的数据进行一些数据结构上的转换操作,封装转型成Iterator,ShuffleBlockFetcherIterator构造以后,根据BlockManagerId判断读取策略(本地/远程),本地的话可以根据blockId进行本地数据块的读取,也可以去远程ShuffleMapTask所在的节点的BlockManager去拉取需要聚合的数据;
- ④ 最后,将拉取到的数据,执行一些转换和封装,返回。
星环的技术方案
但是,上述方式可能会存在一定风险,比如inceptor server的内存达到上限爆掉。因此在新版本TDH中针对Shuffle reader做了优化,数据将放在不同的executor中,不再使用集中管理的status,尽管维护复杂度会有增高,但是保护了inceptor server的内存。
ShuffleWrite阶段存在的数据倾斜问题
这种情况引起数据倾斜的主要地方是在shuffle writer的过程,但是算子我们是没有办法干涉处理过程中的数据倾斜。从上面的流程也可以看出,是mapper在读取数据本身的时候,数据本身就不正常才会导致这个问题。
需要注意的是,星环科技的计算框架在运行的时候是有做倾斜检查的,所以如果在生产过程中出现了倾斜大多数情况下可能是因为业务特性导致,比如说业务数据本身的特性:
在实际生产中,大部分数据都是有偏差的,比如维度表中的数据一般比较固定,数据有限,但是事实表可能会随着业务实时增长。这种情况下如果没有处理好业务逻辑(事实表关联事实表导致数据膨胀),可能就会导致数据倾斜的风险。
所以当发生数据倾斜的情况时,需要最先判断是否是业务逻辑不合理导致,是否有优化空间,再考虑进行技术方案的优化。
ShuffleRead阶段导致的数据倾斜问题
这种情况起因是聚合数据的算子产生的问题,这时候也要从数据本身去找问题,造成聚合数据异常的原因是在shuffle的过程中key hash之后对reducer partitionNum取余后比较集中导致的。
出现这个问题的常见诱因有:大量的空值,处理耗时导致倾斜。
在实际业务中可能会有大量的null值或者一些无意义的数据参与到计算作业中,比如null值。Null值可能在下述两个阶段产生:
1)原始阶段--表中本身就存在大量的null值(例. text表导入的文件有些没有值就会变成null),所有的null值都会被分配到一个reducer中进行处理,除了耗时之外可能也会产生数据倾斜,对于这种情况产生的倾斜问题就需要从业务侧进行修改。
2)数据加工阶段(计算过程中)--进行join操作的时候由于数据匹配不上出现null值;
当涉及到多个数据表时,JOIN是SQL中最常用的操作之一。JOIN的作用是将多个数据表中的数据组合在一起,从而使用户可以根据不同的条件组合过滤和查询多个表中的数据,最终提取记录形成一个新的结果集,实现数据关联和查询分析。
数据倾斜会有什么影响
1)浪费计算资源,资源利用率下降
在分阶段执行任务的场景下,stage与stage之间通常存在数据上的依赖关系,前一个stage完成之前,后续的stage则无法开始。
比如下图中stage2依赖stage1产生的数据结果,那么stage2必须等待stage1执行完成后才能开始。尽管stage1中其他两个task已经提前完成了,但是task3因为执行的数据量过大还在执行中,所以stage2将一直处于等待状态。
此时资源被长时间占用但是只有极少数task在执行,大多数的资源都在等待第一阶段的所有任务都完成后,才能继续提供给其他任务,比如Task4。
2)stage执行时间超出预期,导致后续依赖数据结果的作业出错
有时stage与stage之间,并没有构建强依赖关系,而是通过执行时间的前后时间差来调度,当前置stage未在预期时间范围内完成执行,那么当后续stage启动时便无法读取到其所需要的最新数据,从而导致连续出错。
3)引发内存溢出,导致集群崩坏
数据发生倾斜时,可能导致大量数据集中在少数几个节点上,在计算执行中由于要处理的数据超出了单个executor的能力范围,最终导致内存被撑爆,集群崩坏。
由于篇幅原因,下一篇将为您讲述星环针对上述问题以及出现数据倾斜情况下的引擎保护机制,如何避免出现上述问题。
下一篇:分布式计算框架系列文章(三)星环科技计算引擎针对数据倾斜现象的保护机制
 登录后可评论
登录后可评论








.jpg)



