分布式计算框架系列文章(四)当出现数据倾斜时如何应对--倾斜key单独处理/MapJoin/星环SkewJoin的原理及使用方法
友情链接
- 分布式计算框架系列文章(一)MR框架工作流程详解以及框架限制
- 分布式计算框架系列文章(二)数据倾斜现象诱因、原理、影响,以及星环对此的应对策略
- 分布式计算框架系列文章(三)星环科技计算引擎针对数据倾斜现象的引擎保护机制
- 分布式计算框架系列文章(四)当出现数据倾斜时如何应对--倾斜key单独处理/MapJoin/星环SkewJoin的原理及使用方法
常见的3类处理方式
① Key分布不均匀 --- 倾斜的key单独处理
② 大表与小表进行关联 --- Map Join
③ 大表与大表进行关联 --- Skew Join
方法一 倾斜的key单独处理
当存在大量倾斜key的时候,可以通过手动拆分,将倾斜与未倾斜的部分分别做处理,再将结果合并。
用法示例:不包括倾斜key的查询union all包括倾斜key的查询
select
*
from
FACT f
left join DIMENSION d
on f.CODE_ID = d.CODE_ID
where
f.CODE_ID <> 250
union all
select
*
from
FACT f
left join DIMENSION d
on f.CODE_ID = d.CODE_ID
where
f.CODE_ID = 250
and d.CODE_ID = 250还有一种情况比较简单,如果业务上不需要一些key的参与(比如空字符串等无效或无价值的key),可以考虑将倾斜的key直接过滤掉。
用法示例
select a.col1,null as col2 from test1 a
where a.id is null
union all
select a.col1,b.col2 from test1 a
left join test2 b on a.id=b.id
where a.id is not null但是这种方法适用的场景是导致倾斜的key只有少数几个,并且不影响最终结果。所以如果倾斜的key比较重要,不适合进行过滤的操作,也可以采用下面的方式进一步解决。
Null倾斜
功能开关
- quark.join.null.optimize - hive-site.xml
- 设为true(默认false)
方法二 改用MapJoin的形式,广播小表出去,避免shuffle
CommonJoin劣势
CommonJoin(也被称为Shuffle Join/Reduce side Join/Sort Merge Join..)主要是在 Shuffle 阶段(Reduce 端)执行。
Common Join 的一个主要问题是在数据整理排序的过程上耗费了大量的资源,它会启动一个Task,Mapper会去读取两张表中的数据,然后处理数据后会对对他们进行排序、合并等操作,然后相同key的所有行数据都会分发到同一个节点上。比如key是age=20,task会读取该行剩下的所有数据,id=1,name=张三,地址=xxx。然后在reduce阶段,reducer获取排序后的数据执行join操作。不可避免地会涉及到shuffle,而shuffle通常是IO重灾区,大量的 IO 都会集中在shuffle过程中。但是。一旦触发Shuffle,所有相同key的值就会被拉到一个或几个Reducer节点上,容易发生单点计算问题,非常消耗资源。
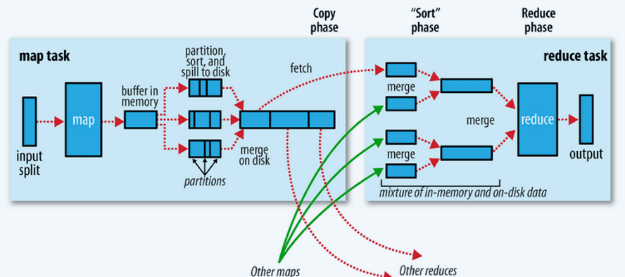
MapJoin介绍
为了优化作业缩短大量数据传输时间,提升系统资源利用率,我们可以改用mapjoin的方式在Map阶段执行表连接,而非等到shuffle以及reduce阶段才执行,避免shuffle。下面我们来看一下MapJoin的运行方式进一步了解。
使用MapJoin时需区分大小表,MapJoin的核心是将小表的数据广播给每个executor,executor读取大表的数据probe小表,逐行按序扫描做关联。
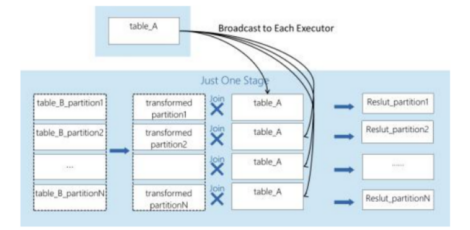
MapJoin原理
Map Join 的方式是先提前把小表的数据写入HDFS,在大表做计算的时候会先把小表从HDFS读出来复制到每个计算节点上,然后构建小表的哈希表。接下来Executor会读取大表的数据块,根据join key和小表的hashtable做关联,生成结果输出,给到下一个计算阶段(比如groupby)。
由于较小的表已经被提前写入HDFS中,整个计算过程仅涉及Map 阶段,减少了shuffle中排序和合并过程以及网络传输所需的时间。同时,该方式不需要reducer并且跳过了reduce阶段,由executor直接输出结果文件进入下一阶段,所以他与CommonJoin方式相比查询性能更好,任务的执行效率更高。
MapJoin使用方式&限制
但是MapJoin只适用于大表小表Join的情况,因为MapJoin会将指定表的数据全部加载在内存,表在被加载到内存后,数据大小会急剧膨胀,因此指定的表只能是小表。
我们推荐小表被加载到内存后占用的总内存不超过5M(压缩后),如果超过可以根据业务以及集群的情况适当调整。
MapJoin中针对Join操作的限制
- left outer join的左表必须是大表。
- right outer join的右表必须是大表。
- 不支持full outer join。
- inner join的左表或右表均可以是大表。
启用MapJoin的方式
当大小表关联时星环计算引擎默认自动开启MapJoin,但是如果存在如某些query 或者表,过滤后比较小的情况,这个情况引擎无法自动判断大小,所以需要手动指定,手动指定的方式如下:
通过 HINT 实现
HINT是写在语句中用于指示计算底层实现某个操作的执行方式的一条说明,按照优化目的与一定的格式书写。MapJoin的HINT形式为“/*+ mapjoin(<table_name>) */”,其中table_name指明被广播的表,可以为多个,一般都是小表或过滤率高的表。HINT的实现语法如下:
SELECT /*+MAPJOIN(table_B)*/
...
FROM table_A JOIN table_B
ON a.key = b.key;其中 table_B 为小表。
比如对于store_sales(大表)和date_dim(小表)两表的JOIN操作语法示例:
SELECT /*+MAPJOIN(date_dim)*/
COUNT(*)
FROM store_sales JOIN date_dim
ON ss_sold_date_sk = d_date_sk;方法三 skew join
MapJoin主要适用于大小表关联的情况,那如果是大表与大表之间进行关联可以考虑TDH新版本发布的skew join功能,可以一定程度缓解大表关联场景下的数据倾斜问题。
该功能已上线最新版本社区版,感兴趣的小伙伴可以点击该链接获取相关资源:社区版相关资源指路
Skew Join的核心是针对倾斜key(MapJoin)以及常规key(CommonJoin)分别采用不同的Join方式,然后合并他们的结果产生输出。
SKEWJOIN原理
SKEWJOIN在运行时,对于倾斜数据较少的CommonTable,会先将它的倾斜key对应的数据写入HDFS中等待后续的MapJoin操作。接下来运行一组计算节点读取倾斜表的数据,执行下述步骤:
① 将HDFS中存储的数据复制到计算节点上,然后构建哈希表。倾斜表中的倾斜数据与哈希表文件关联执行MapJoin操作;
② 其他的常规数据执行CommonJoin的操作;
③ 最后合并MapJoin与CommonJoin的结果进行输出;
SKEWJOIN使用限制
- 只支持连接中单张表存在数据倾斜的情况;
- 只支持等值连接的情况。等值连接指的是SQL语句中join的on 条件中join key为keyA=keyB或类似条件,此时 keyA、keyB 就是 join key;
- 支持Windrunner和Linac引擎;
- 对于子查询倾斜的场景,目前只能通过设置hint来解决;
注意:不要随意添加该 hint,该 hint 会在 reduce 和 join 阶段增加行级的判断,在不存在显著数据倾斜的场景中添加该 hint 会影响性能。
当对JOIN语句使用 SKEWJOIN时的限制:
- INNER JOIN:可以在INNER JOIN语句中为左表或右表指定SKEWJOIN HINT;
- LEFT JOIN:只能为左表指定 SKEWJOIN HINT;
- RIGHT JOIN:只能为右表指定 SKEWJOIN HINT;(实质与 left join 左表倾斜等价)
- FULL JOIN:不支持 SKEWJOIN HINT;
SKEWJOIN语法
您需要在select语句中使用Hint提示
"/*+SKEWJOIN(table_alias (column_name) [(skew_value)],table_alias (column_name) [(skew_value)]...)*/"才会执行skewjoin,整体 hint 语法大体上分为:
- table_alias:存在倾斜的表别名;
- column_name:倾斜表中连接用的一个或多个列名,要求必须包含所有用作 join 条件的列,即 SQL 中 join 语句的 on 条件中匹配的列名;多个列名用逗号 ',' 分开,整体用括号 '( )' 包裹,如 (col1, col2);
- skew_value:倾斜表中的连接用列的一个或多个倾斜值,每个倾斜值用括号 '()' 包裹;倾斜值内部不同列的值用逗号 ',' 分割,多个倾斜值整体用方括号 '[ ]' 包裹,如 [('name1', 100), ('name2', 200)];
- 每个倾斜值,即括号内的多个列值,其必须与 column_name 中倾斜列按顺序对应,skew_value不允许出现null;
语法示例
SET quark.join.null.optimize=TRUE;
SET quark.skewjoin.hint.enable=TRUE;
SET ngmr.windrunner.session.orc=TRUE;
SET ngmr.windrunner.nonquery.enabled=TRUE;
select /*+ SKEWJOIN(a(id, name)[(1,'qwh'),(2,'ly')]) */
jt_1.id, jt_1.name, des, data
from jt_1 a inner join jt_3 b
on a.id = b.id
and a.name = b.name;
如上述样例,计算引擎会对表 jt_1 中,所有 id=1,name='qwh' 以及 id=2,name='ly' 的所有列做均匀处理,避免倾斜。
本系列文章分享结束,如果对您有帮助多多留言点赞吧~如果您有想要进一步了解的内容,也欢迎您多多留言反馈~
我们下期见~
友情链接
- 分布式计算框架系列文章(一)MR框架工作流程详解以及框架限制
- 分布式计算框架系列文章(二)数据倾斜现象诱因、原理、影响,以及星环对此的应对策略
- 分布式计算框架系列文章(三)星环科技计算引擎针对数据倾斜现象的引擎保护机制
- 分布式计算框架系列文章(四)当出现数据倾斜时如何应对--倾斜key单独处理/MapJoin/星环SkewJoin的原理及使用方法
常见的3类处理方式
① Key分布不均匀 --- 倾斜的key单独处理
② 大表与小表进行关联 --- Map Join
③ 大表与大表进行关联 --- Skew Join
方法一 倾斜的key单独处理
当存在大量倾斜key的时候,可以通过手动拆分,将倾斜与未倾斜的部分分别做处理,再将结果合并。
用法示例:不包括倾斜key的查询union all包括倾斜key的查询
select
*
from
FACT f
left join DIMENSION d
on f.CODE_ID = d.CODE_ID
where
f.CODE_ID <> 250
union all
select
*
from
FACT f
left join DIMENSION d
on f.CODE_ID = d.CODE_ID
where
f.CODE_ID = 250
and d.CODE_ID = 250还有一种情况比较简单,如果业务上不需要一些key的参与(比如空字符串等无效或无价值的key),可以考虑将倾斜的key直接过滤掉。
用法示例
select a.col1,null as col2 from test1 a
where a.id is null
union all
select a.col1,b.col2 from test1 a
left join test2 b on a.id=b.id
where a.id is not null但是这种方法适用的场景是导致倾斜的key只有少数几个,并且不影响最终结果。所以如果倾斜的key比较重要,不适合进行过滤的操作,也可以采用下面的方式进一步解决。
Null倾斜
功能开关
- quark.join.null.optimize - hive-site.xml
- 设为true(默认false)
方法二 改用MapJoin的形式,广播小表出去,避免shuffle
CommonJoin劣势
CommonJoin(也被称为Shuffle Join/Reduce side Join/Sort Merge Join..)主要是在 Shuffle 阶段(Reduce 端)执行。
Common Join 的一个主要问题是在数据整理排序的过程上耗费了大量的资源,它会启动一个Task,Mapper会去读取两张表中的数据,然后处理数据后会对对他们进行排序、合并等操作,然后相同key的所有行数据都会分发到同一个节点上。比如key是age=20,task会读取该行剩下的所有数据,id=1,name=张三,地址=xxx。然后在reduce阶段,reducer获取排序后的数据执行join操作。不可避免地会涉及到shuffle,而shuffle通常是IO重灾区,大量的 IO 都会集中在shuffle过程中。但是。一旦触发Shuffle,所有相同key的值就会被拉到一个或几个Reducer节点上,容易发生单点计算问题,非常消耗资源。
MapJoin介绍
为了优化作业缩短大量数据传输时间,提升系统资源利用率,我们可以改用mapjoin的方式在Map阶段执行表连接,而非等到shuffle以及reduce阶段才执行,避免shuffle。下面我们来看一下MapJoin的运行方式进一步了解。
使用MapJoin时需区分大小表,MapJoin的核心是将小表的数据广播给每个executor,executor读取大表的数据probe小表,逐行按序扫描做关联。
MapJoin原理
Map Join 的方式是先提前把小表的数据写入HDFS,在大表做计算的时候会先把小表从HDFS读出来复制到每个计算节点上,然后构建小表的哈希表。接下来Executor会读取大表的数据块,根据join key和小表的hashtable做关联,生成结果输出,给到下一个计算阶段(比如groupby)。
由于较小的表已经被提前写入HDFS中,整个计算过程仅涉及Map 阶段,减少了shuffle中排序和合并过程以及网络传输所需的时间。同时,该方式不需要reducer并且跳过了reduce阶段,由executor直接输出结果文件进入下一阶段,所以他与CommonJoin方式相比查询性能更好,任务的执行效率更高。
MapJoin使用方式&限制
但是MapJoin只适用于大表小表Join的情况,因为MapJoin会将指定表的数据全部加载在内存,表在被加载到内存后,数据大小会急剧膨胀,因此指定的表只能是小表。
我们推荐小表被加载到内存后占用的总内存不超过5M(压缩后),如果超过可以根据业务以及集群的情况适当调整。
MapJoin中针对Join操作的限制
- left outer join的左表必须是大表。
- right outer join的右表必须是大表。
- 不支持full outer join。
- inner join的左表或右表均可以是大表。
启用MapJoin的方式
当大小表关联时星环计算引擎默认自动开启MapJoin,但是如果存在如某些query 或者表,过滤后比较小的情况,这个情况引擎无法自动判断大小,所以需要手动指定,手动指定的方式如下:
通过 HINT 实现
HINT是写在语句中用于指示计算底层实现某个操作的执行方式的一条说明,按照优化目的与一定的格式书写。MapJoin的HINT形式为“/*+ mapjoin(<table_name>) */”,其中table_name指明被广播的表,可以为多个,一般都是小表或过滤率高的表。HINT的实现语法如下:
SELECT /*+MAPJOIN(table_B)*/
...
FROM table_A JOIN table_B
ON a.key = b.key;其中 table_B 为小表。
比如对于store_sales(大表)和date_dim(小表)两表的JOIN操作语法示例:
SELECT /*+MAPJOIN(date_dim)*/
COUNT(*)
FROM store_sales JOIN date_dim
ON ss_sold_date_sk = d_date_sk;方法三 skew join
MapJoin主要适用于大小表关联的情况,那如果是大表与大表之间进行关联可以考虑TDH新版本发布的skew join功能,可以一定程度缓解大表关联场景下的数据倾斜问题。
该功能已上线最新版本社区版,感兴趣的小伙伴可以点击该链接获取相关资源:社区版相关资源指路
Skew Join的核心是针对倾斜key(MapJoin)以及常规key(CommonJoin)分别采用不同的Join方式,然后合并他们的结果产生输出。
SKEWJOIN原理
SKEWJOIN在运行时,对于倾斜数据较少的CommonTable,会先将它的倾斜key对应的数据写入HDFS中等待后续的MapJoin操作。接下来运行一组计算节点读取倾斜表的数据,执行下述步骤:
① 将HDFS中存储的数据复制到计算节点上,然后构建哈希表。倾斜表中的倾斜数据与哈希表文件关联执行MapJoin操作;
② 其他的常规数据执行CommonJoin的操作;
③ 最后合并MapJoin与CommonJoin的结果进行输出;
SKEWJOIN使用限制
- 只支持连接中单张表存在数据倾斜的情况;
- 只支持等值连接的情况。等值连接指的是SQL语句中join的on 条件中join key为keyA=keyB或类似条件,此时 keyA、keyB 就是 join key;
- 支持Windrunner和Linac引擎;
- 对于子查询倾斜的场景,目前只能通过设置hint来解决;
注意:不要随意添加该 hint,该 hint 会在 reduce 和 join 阶段增加行级的判断,在不存在显著数据倾斜的场景中添加该 hint 会影响性能。
当对JOIN语句使用 SKEWJOIN时的限制:
- INNER JOIN:可以在INNER JOIN语句中为左表或右表指定SKEWJOIN HINT;
- LEFT JOIN:只能为左表指定 SKEWJOIN HINT;
- RIGHT JOIN:只能为右表指定 SKEWJOIN HINT;(实质与 left join 左表倾斜等价)
- FULL JOIN:不支持 SKEWJOIN HINT;
SKEWJOIN语法
您需要在select语句中使用Hint提示
"/*+SKEWJOIN(table_alias (column_name) [(skew_value)],table_alias (column_name) [(skew_value)]...)*/"才会执行skewjoin,整体 hint 语法大体上分为:
- table_alias:存在倾斜的表别名;
- column_name:倾斜表中连接用的一个或多个列名,要求必须包含所有用作 join 条件的列,即 SQL 中 join 语句的 on 条件中匹配的列名;多个列名用逗号 ',' 分开,整体用括号 '( )' 包裹,如 (col1, col2);
- skew_value:倾斜表中的连接用列的一个或多个倾斜值,每个倾斜值用括号 '()' 包裹;倾斜值内部不同列的值用逗号 ',' 分割,多个倾斜值整体用方括号 '[ ]' 包裹,如 [('name1', 100), ('name2', 200)];
- 每个倾斜值,即括号内的多个列值,其必须与 column_name 中倾斜列按顺序对应,skew_value不允许出现null;
语法示例
SET quark.join.null.optimize=TRUE;
SET quark.skewjoin.hint.enable=TRUE;
SET ngmr.windrunner.session.orc=TRUE;
SET ngmr.windrunner.nonquery.enabled=TRUE;
select /*+ SKEWJOIN(a(id, name)[(1,'qwh'),(2,'ly')]) */
jt_1.id, jt_1.name, des, data
from jt_1 a inner join jt_3 b
on a.id = b.id
and a.name = b.name;
如上述样例,计算引擎会对表 jt_1 中,所有 id=1,name='qwh' 以及 id=2,name='ly' 的所有列做均匀处理,避免倾斜。
本系列文章分享结束,如果对您有帮助多多留言点赞吧~如果您有想要进一步了解的内容,也欢迎您多多留言反馈~
我们下期见~
 登录后可评论
登录后可评论








.jpg)



