Task的数量是如何决定的
前言
在分布式计算系统中,计算任务(Task)的数量对于整个系统的性能和效率至关重要。比如:
- 资源利用率:合理的任务数量可以帮助系统更有效地利用集群中的资源,避免某些节点过载而其他节点空闲,从而实现负载均衡,避免出现数据倾斜等弊端(数据倾斜原理及处理方法系列文章);
- 计算效率:任务数量直接影响计算的并行度。如果任务太少,可能会导致资源浪费和计算效率低下;如果任务太多,可能会导致资源争用和调度开销增加;
- 数据处理和传输:在MapReduce、Spark等计算框架中,任务数量通常与数据的分割方式有关。合理的任务划分可以减少数据传输和存储的开销,提高数据处理速度;
- 任务调度和执行任务调度器需要根据任务数量和资源状况来优化任务的分配和执行顺序。合理的任务数量有助于提高调度效率和执行速度;
- 性能瓶颈:任务数量的不合理配置可能导致性能瓶颈。例如,如果某些任务因为数据倾斜而处理的数据量远大于其他任务,这将导致这些任务执行时间过长,成为性能瓶颈;
- ...
综上所述,计算任务数量的合理配置对于分布式计算系统的性能、效率、稳定性和扩展性都有着直接的影响。
在Inceptor/ArgoDB中task数量如何计算
Inceptor的后台执行引擎是Spark,Spark的基本执行单位是Task,Task的数目是由RDD的分区数决定的。Inceptor中把一个SQL的执行划分为map阶段和reduce阶段,这两个阶段的task数目受到很多因素影响。
其次ArgoDB的任务分配是以Task为粒度执行的,每一个Task同时只会执行在一个Executor上,是用一个vCore资源,因此如果要充分利用上CPU,就必须要干预Task数量。
Map阶段
数据集主要是存储在磁盘中,在启动一个MR程序后,数据会被拆分成一个或多个InputSplits并分配给单独的Mapper生成对应数量的map tasks,数据的拆分方式取决于不同的数据源,受很多因素影响。
如果是开源的格式,例如text,orc等,那么InputFormat则定义了如何拆分和读取Input Files以及RecordReader。举个例子:
Text表
如果数据源是text格式,那么数据在输入时会基于设定的块大小(比如128MB)进行切分。然后TextInputFormat会把输入文件的每一行作为单独的一个记录,按行读取每条记录,此格式对应的key是行的字节偏移量,value则是行的内容。然后后续将键值对发送到mapper进行进一步处理,一个block则对应一个task。
也就是说处理text表的task数目是由HDFS文件的文件数数和split决定的,一个split对应一个task。一个大文件,HDFS 默认根据block size (TDH默认128MB)来分split。
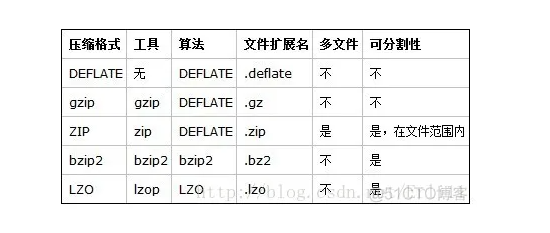
注意:有些压缩文件,是没法分split的,一个文件只能一个task处理
CSV
如果是csv格式的话,每个csv文件对应一个task,单个csv文件本身不会被拆分为多个task处理。
ORC
再比如说如果数据源是orc格式,那么对应的则是OrcInputFormat,OrcInputFormat的算法逻辑是由参数hive.exec.orc.split.strategy控制在读取ORC表时生成split的策略,策略分为BI、ETL、HYBRID等等,不同策略划分方式不一样。比如BI策略则是以文件为粒度进行split划分。
通常默认是256MB一个split,但是由于切分实际并不准确,经常会有超过256MB的文件不能分split。
在星环的计算框架中Inputformat 主要用于和一些开源的格式适配,它的缺点是速度比较慢,而且接口比较固定不灵活。
所以如果数据源是星环自研的格式,例如holodesk、timelyre、stelallardb等等,则使用的是星环自研的stargate接口。该接口定义了如何分块,不同格式算法不一样,会针对map处理的数据量以及map总数量做一个权衡。
Holodesk表默认是256MB一个split,切分相对较准。
其他:
分桶表
一般分桶数就是task数目。Holodesk表超过256MB会切。实际观察下来,TORC一般不会切。
分区分桶表
- 如果没有分区过滤,task数目 = 分区数 * 桶数
- 如果有分区过滤,task数目 = 过滤后分区数 * 桶数
Reduce阶段
当两个算子之间需要进行数据的重分布时会需要重新计算下一个Stage的task数,reduce task的数量决定了最终输出文件的数目。
这个阶段的task数量主要是由map 的数量以及和operator类型设置的阈值决定的,计算方式为:
Join & group by
因为星环计算引擎是以Shuffle来切分Stage的,因此只有两个算子之间需要进行数据的重分布(比如ArgoDB中使用Hash Shuffle)时,会需要重新计算下一个Stage的task数,而计算的方式为:
- group by:上一个stage task数 * hive.groupby.aggregateratio(default:0.6)
0.6的比值由 hive.groupby.aggregateratio 参数决定
- join:一般是task更多的stage task数 * hive.join.aggregateratio(default:1.0) 也就是 task数目 = max(map task数)
union/union all
单独计算不同部分的map&reduce task数目,然后相加
Limit
当进行limit时会进行预估,裁剪掉不必要的task。默认会先2个Task执行(参数 ngmr.num.parts.try.limit 决定,limit不够再起新的task),因此建议用户不要进行大数据量的limit,否则性能会差很多。
Insert
如果需要向目标表中插入数据,数据插入时,Stage的task数取决于是否向分桶表插入数据。
这是因为分桶的逻辑是根据数据的Hash值进行数据的分布计算,将数据写到不同的Tablet中,因此入库时的task数量一般是:
- 分桶表:无论是否分区,入库的task数均为分桶数;
- 非分桶表:入库的task数位上一个stage的task数;
其他操作
一般跟max(map task数)一致
全局参数控制
读表stage的task数参数:
通过开启AutoMerge,让一个Task读取多个Small Block,来实现减少Task数的效果
- holodesk.automerge.enabled开启AutoMerge
- holodesk.automerge.mergesize设置AutoMerge的数据合并大小阈值
- holodesk.automerge.filesize设置AutoMerge的数据合并数量阈值
Reduce stage的task数参数:
手动设置以下参数,会影响读表stage以外的stage的task数,可以增大或减少task数
mapred.reduce.tasks 设置reduce 个数
mapred.minreduce.tasks 设置最小reduce个数
对分桶表插入,如果mapred.reduce.tasks跟桶数不一致,结果可能有问题,所以分桶表插入时,不要设置mapred.reduce.tasks。
Reduce task控制相关参数
- mapred.minreduce.tasks 默认4
- hive.join.aggregateratio 默认1.0
- hive.groupby.aggregateratio 默认0.6
- hive.intersect.aggregateratio 默认1.0
- hive.except.aggregateratio 默认1.0
- hive.reducer.control.max.reducenum 默认-1,无效
- mapred.reduce.tasks 默认-1,无效
task数限制参数
主要是通过ngmr.topo.mapred.limit,来控制任意两个Stage之间Map数量和Reduce数量乘积,如果大于这个值则会报错,默认值:1000000000(10亿)
前言
在分布式计算系统中,计算任务(Task)的数量对于整个系统的性能和效率至关重要。比如:
- 资源利用率:合理的任务数量可以帮助系统更有效地利用集群中的资源,避免某些节点过载而其他节点空闲,从而实现负载均衡,避免出现数据倾斜等弊端(数据倾斜原理及处理方法系列文章);
- 计算效率:任务数量直接影响计算的并行度。如果任务太少,可能会导致资源浪费和计算效率低下;如果任务太多,可能会导致资源争用和调度开销增加;
- 数据处理和传输:在MapReduce、Spark等计算框架中,任务数量通常与数据的分割方式有关。合理的任务划分可以减少数据传输和存储的开销,提高数据处理速度;
- 任务调度和执行任务调度器需要根据任务数量和资源状况来优化任务的分配和执行顺序。合理的任务数量有助于提高调度效率和执行速度;
- 性能瓶颈:任务数量的不合理配置可能导致性能瓶颈。例如,如果某些任务因为数据倾斜而处理的数据量远大于其他任务,这将导致这些任务执行时间过长,成为性能瓶颈;
- ...
综上所述,计算任务数量的合理配置对于分布式计算系统的性能、效率、稳定性和扩展性都有着直接的影响。
在Inceptor/ArgoDB中task数量如何计算
Inceptor的后台执行引擎是Spark,Spark的基本执行单位是Task,Task的数目是由RDD的分区数决定的。Inceptor中把一个SQL的执行划分为map阶段和reduce阶段,这两个阶段的task数目受到很多因素影响。
其次ArgoDB的任务分配是以Task为粒度执行的,每一个Task同时只会执行在一个Executor上,是用一个vCore资源,因此如果要充分利用上CPU,就必须要干预Task数量。
Map阶段
数据集主要是存储在磁盘中,在启动一个MR程序后,数据会被拆分成一个或多个InputSplits并分配给单独的Mapper生成对应数量的map tasks,数据的拆分方式取决于不同的数据源,受很多因素影响。
如果是开源的格式,例如text,orc等,那么InputFormat则定义了如何拆分和读取Input Files以及RecordReader。举个例子:
Text表
如果数据源是text格式,那么数据在输入时会基于设定的块大小(比如128MB)进行切分。然后TextInputFormat会把输入文件的每一行作为单独的一个记录,按行读取每条记录,此格式对应的key是行的字节偏移量,value则是行的内容。然后后续将键值对发送到mapper进行进一步处理,一个block则对应一个task。
也就是说处理text表的task数目是由HDFS文件的文件数数和split决定的,一个split对应一个task。一个大文件,HDFS 默认根据block size (TDH默认128MB)来分split。
注意:有些压缩文件,是没法分split的,一个文件只能一个task处理
CSV
如果是csv格式的话,每个csv文件对应一个task,单个csv文件本身不会被拆分为多个task处理。
ORC
再比如说如果数据源是orc格式,那么对应的则是OrcInputFormat,OrcInputFormat的算法逻辑是由参数hive.exec.orc.split.strategy控制在读取ORC表时生成split的策略,策略分为BI、ETL、HYBRID等等,不同策略划分方式不一样。比如BI策略则是以文件为粒度进行split划分。
通常默认是256MB一个split,但是由于切分实际并不准确,经常会有超过256MB的文件不能分split。
在星环的计算框架中Inputformat 主要用于和一些开源的格式适配,它的缺点是速度比较慢,而且接口比较固定不灵活。
所以如果数据源是星环自研的格式,例如holodesk、timelyre、stelallardb等等,则使用的是星环自研的stargate接口。该接口定义了如何分块,不同格式算法不一样,会针对map处理的数据量以及map总数量做一个权衡。
Holodesk表默认是256MB一个split,切分相对较准。
其他:
分桶表
一般分桶数就是task数目。Holodesk表超过256MB会切。实际观察下来,TORC一般不会切。
分区分桶表
- 如果没有分区过滤,task数目 = 分区数 * 桶数
- 如果有分区过滤,task数目 = 过滤后分区数 * 桶数
Reduce阶段
当两个算子之间需要进行数据的重分布时会需要重新计算下一个Stage的task数,reduce task的数量决定了最终输出文件的数目。
这个阶段的task数量主要是由map 的数量以及和operator类型设置的阈值决定的,计算方式为:
Join & group by
因为星环计算引擎是以Shuffle来切分Stage的,因此只有两个算子之间需要进行数据的重分布(比如ArgoDB中使用Hash Shuffle)时,会需要重新计算下一个Stage的task数,而计算的方式为:
- group by:上一个stage task数 * hive.groupby.aggregateratio(default:0.6)
0.6的比值由 hive.groupby.aggregateratio 参数决定
- join:一般是task更多的stage task数 * hive.join.aggregateratio(default:1.0) 也就是 task数目 = max(map task数)
union/union all
单独计算不同部分的map&reduce task数目,然后相加
Limit
当进行limit时会进行预估,裁剪掉不必要的task。默认会先2个Task执行(参数 ngmr.num.parts.try.limit 决定,limit不够再起新的task),因此建议用户不要进行大数据量的limit,否则性能会差很多。
Insert
如果需要向目标表中插入数据,数据插入时,Stage的task数取决于是否向分桶表插入数据。
这是因为分桶的逻辑是根据数据的Hash值进行数据的分布计算,将数据写到不同的Tablet中,因此入库时的task数量一般是:
- 分桶表:无论是否分区,入库的task数均为分桶数;
- 非分桶表:入库的task数位上一个stage的task数;
其他操作
一般跟max(map task数)一致
全局参数控制
读表stage的task数参数:
通过开启AutoMerge,让一个Task读取多个Small Block,来实现减少Task数的效果
- holodesk.automerge.enabled开启AutoMerge
- holodesk.automerge.mergesize设置AutoMerge的数据合并大小阈值
- holodesk.automerge.filesize设置AutoMerge的数据合并数量阈值
Reduce stage的task数参数:
手动设置以下参数,会影响读表stage以外的stage的task数,可以增大或减少task数
mapred.reduce.tasks 设置reduce 个数
mapred.minreduce.tasks 设置最小reduce个数
对分桶表插入,如果mapred.reduce.tasks跟桶数不一致,结果可能有问题,所以分桶表插入时,不要设置mapred.reduce.tasks。
Reduce task控制相关参数
- mapred.minreduce.tasks 默认4
- hive.join.aggregateratio 默认1.0
- hive.groupby.aggregateratio 默认0.6
- hive.intersect.aggregateratio 默认1.0
- hive.except.aggregateratio 默认1.0
- hive.reducer.control.max.reducenum 默认-1,无效
- mapred.reduce.tasks 默认-1,无效
task数限制参数
主要是通过ngmr.topo.mapred.limit,来控制任意两个Stage之间Map数量和Reduce数量乘积,如果大于这个值则会报错,默认值:1000000000(10亿)
 登录后可评论
登录后可评论








.jpg)



