常见错误排查攻略以及使用问题(问题持续更新中,最近更新时间为2024.01.26)
友情链接:
- 如何根据错误信息定位出现问题的发生阶段以及错误类别
- Hyperbase运维&问题排查思路
- 启动TDH服务失败如何定位问题以及一些相关的常见问题
- 如果遇到Inceptor相关问题报错,可以根据报错代码在该《Inceptor错误代码与信息查询手册》手册中进行查询
安装前须知
一、TDH社区版用户在安装前一定要记得进行以下检查步骤,这样未来在使用产品的过程中可以减少大量的风险和阻碍:
1. 硬件检查
a)jdk1.8
b)CentOs 7.3-7.9
c)Red Hat Enterprise Linux 7.3-7.9
d)必须是3台以上服务器组成,每台服务器最低配置如下
- 4核心或以上带超线程x86指令集CPU的服务器
- 8GB以上内存
- 2个300G以上的硬盘做RAID1,作为系统盘
- 4个以上的300GB容量以上的硬盘作为数据存放硬盘
- 2个千兆以上网卡
注意事项:
- 上述配置仅限测试功能以及使用基础组件,不支持跑批量数据等场景,如需跑批,以及使用更多组件,如Guardian,为实现更好的性能,请基于自身需求将配置增加至至少4核64GB及以上;
- 如果只是验证功能,单做测试搭建,而且数据量不大的话docker盘和数据盘适当将降低至各100G左右也可以;
2. 冲突包检查(务必保证)
a)是否存在与 tos,manager 安装相冲突的包
b)冲突包list:
- 检查manager所在节点是否已有mysql,如果有建议卸载,如果不想卸载,可更换一个干净的节点安装Manager;
- 检查原操作系统是否有自带的docker,如果有,建议卸载再进行安装;
- 检查container-selinux是否冲突,如果有冲突建议执行rpm -qa|grep selinux然后执行,rpm -e container-selinux,可能会提示有依赖,需要逐步把依赖的包都卸载掉;
3. docker 分区挂载检查(务必保证)
须确保单独挂载 /var/lib/docker 目录
4. docker 分区大小检查(务必保证)
/var/lib/docker 分区大于100G
5. docker 分区检查(务必保证)
/var/lib/docker 分区 ftype = 1
6. sudo 用户检查(务必保证)
安装用户需要具有 sudo 权限,并且NOPASSWD,或是root用户
7. 根分区大小检查(推荐)
推荐大于100GB
8. 日志分区挂载检查(推荐)
单独挂载 /var/log 目录
9. 日志分区大小检查(推荐)
/var/log 分区推荐大于100G
二、Host文件务必按照下方要求配置,确保后续顺利安装,其中hostname需保证一致性,临时hostname、静态hostname、fqdn三者主机名需要保持一致。
新用户可以使用 hostnamectl set-hostname hostname 命令来修改主机名,参考以下示例:
[root@localhost ~]# hostnamectl set-hostname tw-node2125
[root@localhost ~]# hostname
tw-node2125注:
a)集群的节点名称不能重复,且必须符合DNS-1123规范,由数字、小写字母或“-”组成,不能包含大写字母,长度小于63;
b)/etc/hosts 文件的第一行必须为127.0.0.1的记录,不能将此行注释掉,也不能将当前主机名写在该行中。通常如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
使用前须知
1) 一键开启安全,杜绝挨个开启
Guardian开启安全时需要一键开启,不建议一个一个的开启组件安全。同时,TDH 有统一的认证管理 不要用开源查到的参数配置Krb5
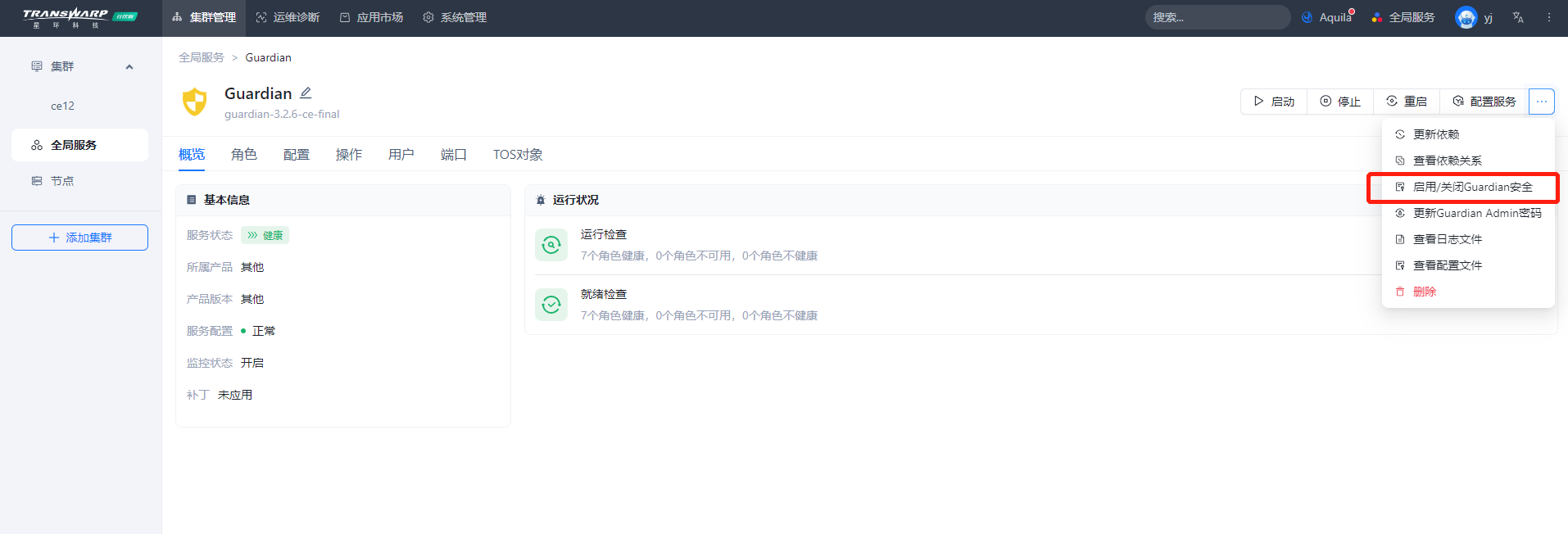
注意:开启安全或关闭安全均需要重新下载TDH-Client才可以包含开启安全或关闭安全后的配置
2) 出现大面积宕机,优先解决核心基础服务(TOS/License/guardian/transwarp-manager-agent),解决后可以看每个组件的依赖关系图。底层的基础服务正常了,就可以重启这个服务了
通常大致顺序是:zk-->hdfs-->yarn-->hyperbase-->quark,具体还需查看自己的集群服务情况
3) 操作雷区,避免此类操作
4) 检查下载的产品包文件是否被损坏
① 与产品包中带的md5文件或sha256文件进行对比,文件里包括一个md5或sha256值,用于查看产品包是否被损坏。
md5文件校验命令指令:md5sum <pkg>
sha256文件校验命令指令:sha256sum <pkg>
一些常见运维指令
1)社区版Manager操作指令集 -- 如何查看状态、启停
Manager支持以下几种指令:status | stop | start | restart
a) gent进程
systemctl <status | stop | start | restart> transwarp-manager-agent
b) master进程
systemctl <status | stop | start | restart> transwarp-manager
c) manager自身使用的mariadb
systemctl <status | stop | start | restart> transwarp-manager-db
社区开发版只需执行 docker exec -it [容器id] bash 进入对应容器后执行上述指令即可
2)社区版开发版镜像&容器相关指令
docker images //查镜像
docker pa //查看当前正在运行的容器(容器是基于镜像创建)
docker ps -a //查看节点所有容器
docker exec -it [容器id] bash //进入容器内
docker start 启动容器
更详细的内容可查看后续<常见的Docker指令>小节
3)常见的Linux运维指令
目录操作
- bin:存放最常用的命令
- boot:存放linux启动的核心文件
- home:用户的主目录
- dev:设备的缩写,存放的是linux的外部设备
- lost+found:存放非法关机文件
- etc:存放系统管理所需要的配置文件
- usr:重要软件存放地点相当于windows 的program file
//src:内核源代码默认的放置目录
//bin:用户使用的应用程序
- opt:主机额外安装的摆放的目录,xmind、redis、Oracle等
- var:扩张的内存存放
- run:存放临时文件,当系统重启时会被删除
- temp:临时文件存放目录用完即丢
- www: 存放服务器网站的相关资源
文件系统以及权限
ll显示文件属性和权限,linux是一个多用户系统,所以权限繁多
- [d] :目录
- [-] : 文件
- [l] : 链接文档
- [b] : 表示为装置文件里面可供存储的接口设备
- [c] : 表示为装置文件的串行设备。例如:鼠标、键盘等
- r: 代表可读 read
- w:代表可写 write
- x: 代表可执行 execute
- 0位:文件类型 d、-、i、b、c
- 1-3位:属主权限 ——root可读、可写、可操作
- 4-6位:属组权限——其他用户无法写
- 7-9位:其他用户权限——其他用户无法写
文件和目录操作
- ls:列出目录内容。
- cd:切换目录。
//绝对路径 /
//相对路径 ../
//用户目录 ~
- pwd:显示当前工作目录。
- mkdir:创建一个目录。
//-p:循环创建目录
- rmdir:删除目录。
//-p:层级删除内部文件
- rm:移除文件或者目录
//-f:忽略不存在的文件,不会出现警告,强制删除
//-r: 递归删除目录
//-i: 互动,询问是否删除
- cp:复制文件或目录。
- mv:移动文件或目录。
- touch:创建空文件或更新文件的访问时间戳。
//文本处理,查看文件内容:
- cat:由第一行开始显示文件内容。
- tac:从最后一行开始显示,可以看出tac是cat的倒写
- grep:在文件中搜索指定模式。
- sed:流编辑器,用于文本替换和处理。
- awk:文本处理工具,支持文本提取、格式化等操作。
- nl:显示的时候,可以输出行号
- more:一页一页地显示文件的内容
//空格是翻页
//enter是向下翻一行
//退出是q命令
- less:与more类似但是可以往前面翻页
- head: 只看头几行
- tail:只看尾部几行
可以使用man 命令来查看各个命令的使用文档
进程管理
- ps:显示当前进程状态。
- top:实时显示系统资源使用情况和进程信息。
- kill:终止指定进程。
- pkill:根据进程名终止进程。
用户和权限管理
- useradd:创建新用户。
- passwd:设置用户密码。
- usermod:修改用户属性。
- userdel:删除用户。
- chown:修改文件或目录的所有者。
- chmod:修改文件或目录的权限。
系统信息
- uname:显示系统信息。
- hostname:显示主机名。
- df:显示磁盘空间使用情况。
- free:显示内存使用情况。
- uptime:显示系统运行时间和平均负载。
网络管理
- ifconfig 或 ip addr:显示网络接口信息。
- ping:测试网络连接。
- netstat:显示网络状态和连接信息。
- traceroute:跟踪数据包的路径。
包管理
- apt(Debian/Ubuntu):用于包管理、安装、更新和删除软件包
- yum(CentOS/RHEL):用于包管理、安装、更新和删除软件包
Vim编辑器基本操作
vim基本上分为三种模式
1) 命令模式
2) 输入模式
- home/end :移动光标到行首行位
- PageUp/PageDown : 上下翻页
3) 底线命令模式
- n :跳转到第n行:
- /word : 向光标之下寻找word
- ?word:向光标之上寻找word
- n/N:基础上寻找下一位
- w:写入
- q:退出
- !:强制
- wq:先写入,后离开
- ZZ:如果变更写入离开,如果没变更直接离开
- set nu:显示行号
- set nonu :取消行号
账号管理
linux是一个多用户的分时管理系统,用户账号的管理工作主要涉及到用户账号的添加、删除、修改
1) 添加用户
- useradd -选项 用户名
- -m:自动创建这个用户的主目录/home
- -G: 分配一个用户组
2) 删除用户
- userdel -r 用户名
3) 修改用户
- usermod -参数 用户名
- -d: 用户主目录
- -g:用户组目录
4) 切换用户
- su username
5) 锁定用户
- passwd -l username
- passwd -d username 将密码清空,无法下次登录
以上是一些常用的 Linux 运维指令,涵盖了日常系统管理和操作的基本需求,如需了解更多详细指令,可前往星环开发者社区了解 【Linux基础——常用命令(第一篇)】。
4)常见的Docker指令
常用的基础操作
容器状态介绍
- created:已创建
- restarting:重启中
- running:运行中
- removing:迁移中
- paused:暂停
- exited:停止
- dead:死亡
容器管理
- docker ps:列出正在运行的容器。
- docker ps -a:列出所有状态的容器,包括正在运行的和已停止的。
- docker stop <container_id>:停止运行容器。
- docker restart <container_id>:重启容器。
- docker rm <container_id>:删除已停止的容器。
- docker logs <container_id>:查看容器的日志,-f参数实时刷新日志。
//docker logs -f --tail=500 <container_id>:实时查看最后500条日志;
//docker logs --since 30m <container_id>:查看最近30分钟的日志;
- docker exec -it <container_id> <command>:在运行中的容器中执行命令。
- docker exec -it XXX sh:使用sh命令进入运行中的容器的控制台中
注:
# 容器名不可重复,不会覆盖,创建新版本的同名容器之前需要先停止并删除旧容器
# 可以使用容器id或容器名作为容器的唯一标识,命令中可以更换使用
运行
- a. 启动container, 运行某一个image: docker run -it <image_id or image_tag> bash
- b. 提交image的修改: docker commit <container_id> <image_tag>
- c. push image的修改: docker push <image_tag>
其他进阶操作
容器使用
$ docker run -it ubuntu /bin/bash
- -i: 交互式操作
- -t: 终端
- ubuntu: 镜像名
- /bin/bash: 启动 shell 交互式命令
其他参数
- -d: 后台运行
镜像管理
a)docker images:列出本地的存在的镜像列表。
- image_tag 若为空,则使用默认的latest tag:docker pull imange_name:image_tag
- 注:在本地的docker操作时,镜像id和镜像名+tag均可作为容器的唯一标识,在命令中可替换使用
b)docker pull <image_name>:从仓库拉取镜像。
c)docker tag XXX new_tag:为镜像打标签,若标签已存在,会将标签赋给新镜像,原镜像标签为空(悬空镜像)
d)镜像输出为tar包:
- docker save XXX -o name.tar
- docker save XXX > name.tar
e)导入镜像包:
- docker load -i name.tar
- cat name.tar > docker load
f)docker rmi <image_id>:删除镜像。
- 注:在docker build 的过程中会出现中间镜像。中间镜像不一定会自动删除。会占用存储空间
- 可以通过docker images -f dangling=true命令查找悬空的镜像。
g)docker rmi $(docker images -f "dangling=true" -q):删除悬空镜像。
h)docker build <path_to_dockerfile>:根据 Dockerfile 构建镜像。
网络管理
- docker network ls:列出 Docker 网络。
- docker network inspect <network_id>:查看特定网络的详细信息。
数据卷管理
- docker volume ls:列出 Docker 数据卷。
- docker volume create <volume_name>:创建数据卷。
- docker volume inspect <volume_name>:查看数据卷的详细信息。
系统管理
- docker info:显示 Docker 系统信息。
- docker version:显示 Docker 版本信息。
- docker system df:显示 Docker 使用的磁盘空间信息。
- docker system prune:清理未使用的资源(容器、镜像、数据卷等)。
以上是一些常用的Docker指令,你可以根据具体的需求进一步了解和使用。
5)常见的K8S命令
本篇章主要讲述在处理pod故障时的常用命令。
查看某个资源
kubectl get {pod|node|deploy|rs} {资源名} [-o [wide|yaml|json]] [-n defalt|kube-system]
[资源名选填,如果写上代表只获得这个资源的具体信息]
- -o wide 代表扩展pod信息,增加了 NODE 和 IP 信息
- -o yaml|json 代表以 yaml|json 形式展示 pod 的信息
- -n 选填,不选表示所有 defalut namespace 下的资源
# 例如:查看 default namespace 下的所有 hdfs 相关的 pod 资源
[root@tdh-01~]# kubectl get pods -o wide |grep hdfs查看默认namespace下的pod
kubectl get pods
查看某个pod的pod日志
kubectl logs {pod名} [-f]
-f:表示实时动态展示具体pod的pod日志
# 例如:查看 podname 为 inceptor-server-inceptor1-3529736423-qh58n 的 pod 日志
[root@tdh-01~]# kubectl logs inceptor-server-inceptor1-3529736423-qh58n查看某个资源的详细信息
kubectl describe {pod|node|deploy|rs} {资源名}
该命令可以获取某个资源的具体信息,该资源可以是pod,node,deployment,replicaset等
# 例如:查看 podname 为 inceptor-server-inceptor1-3529736423-qh58n 的 pod 描述信息以及事件信息
[root@tdh-01~]# kubectl describe pods inceptor-server-inceptor1-3529736423-qh58n删除某个资源
kubectl delete {pod|node|deply|rs} {资源名}
# 例如:删除 podname 为 inceptor-server-inceptor1-3529736423-qh58n 的 pod
[root@tdh-01~]# kubectl delete pods inceptor-server-inceptor1-3529736423-qh58n删除所有资源(慎用慎用慎用哦)
kubectl delete {pod|node|deply|rs} --all
删除所有非Running的pod(慎用慎用慎用哦)
for i in `kubectl get pod -o wide | grep -v Running | grep -v NAME | awk '{print$1}'`; do kubectl delete pod ${i}; done
编辑某个资源(不熟悉的话不建议用哦)
kubectl edit {pod|node|deploy|rs} {资源名}
运行
a. 运行默认namespace下的pod:
kubectl exec -it <pod_id> bash
b. 运行指定namespace下的pod
kubectl exec -it <pod_id> bash --namespace <namespace_name>
【社区版】安装Manager向导过程中可能遇到的问题
安装Manager向导显示需要配置RPM库,如何配置
进入安装向导页面显示需升级或安装失败后安装页面变为升级页面
【解决方法】在服务端执行yum remove transwarp-manager-common -y后,重新进行Manager的安装。
安装向导检查环境页面报错显示“无法解析hostname”
【核心原因】获取hostname 失败,需要开启机器的ping功能
【解决办法】echo 0 >/proc/sys/net/ipv4/icmp_echo_ignore_all 开启
安装向导显示提取文件失败,报错“The package container-selinux conflicts with manager...”
【核心原因】container-selinux 冲突了
【解决方法】
执行下述命令:
rpm -qa|grep selinux
rpm -e container-selinux注:可能会提示有依赖,需要逐步把依赖的包都卸载掉就可以了
配置RPM库显示失败,报错显示“failed to mount ISO file /opt/xxx.iso”

【核心原因】/media/osmedia目录已经被挂载
【解决方法】unmount掉这个挂载再重试
安装过程中报错显示“Fail to start database service”

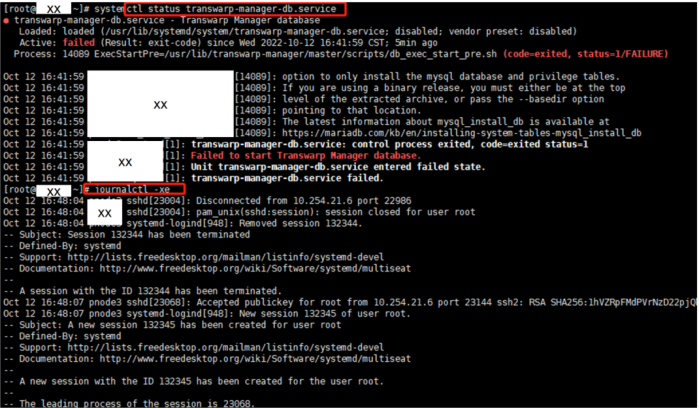
【解决方法】用户需要修改创建数据库的参数
/usr/lib/transwarp-manager/master/scripts/db_exec_start_pre.sh里面,/usr/bin/mysql_install_db加--force参数
安装失败,报错显示“The directory /var/lib/docker is not on a separate partition”
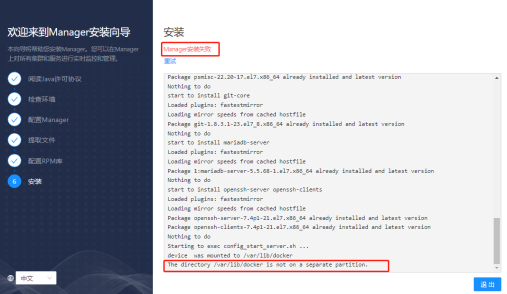
【报错原因】显示不是一个独立的分区,没有挂载docker目录
【解决方法】可以执行mount | grep " /var/lib/docker "检查,如果未挂载,需要把docker目录重新挂载,挂载后重试即可。如果重启后没有自动挂载上,依然失败,修改/etc/fstab后重启,再次重新安装。
安装失败,报错显示“failed to install ntp”
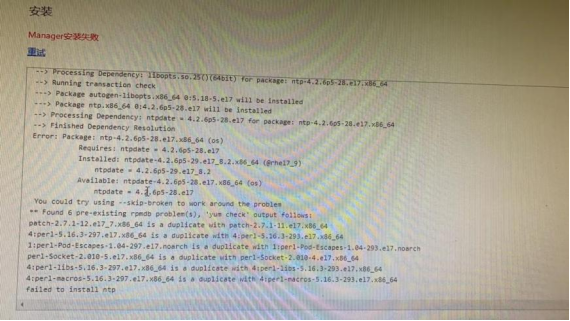
【核心原因】设置的操作系统软件源有冲突,如果用户自己配了软件源,可以在安装时直接选择后台手工配置,就不用manager配了
【解决方法】把已有的ntp卸载后重试即可
安装失败,报错显示“系统已经安装过xxx”,但服务连不上
【核心原因】安装社区版的时候,没有创建 /var/lib/docker 目录,导致最后一步安装失败,安装向导显示 “系统已经安装过Manager-8.1.3-1.noarch”,连不上服务
【解决方法】在服务端执行下述指令,重新安装即可
rpm -e transwarp-manager-common
rpm -e transwarp-manager
或yum remove transwarp-manager-common -y安装失败,报错显示“failed to install MariaDB server”
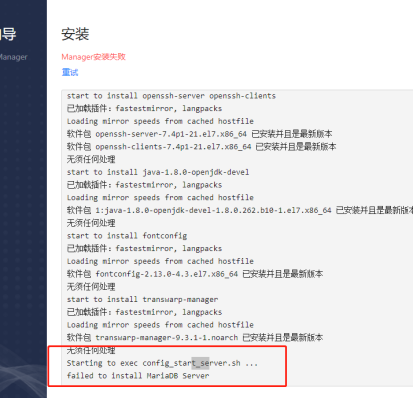
【核心原因】显示与机器上已有的mysql冲突
【解决方法】建议删除机器上的mysql,如果用户不想删除,可以考虑换台机器装Manager
配置集群过程中可能遇到的问题
添加节点过程中报错显示“主机名或IP为xxx的节点不存在”
【报错信息】
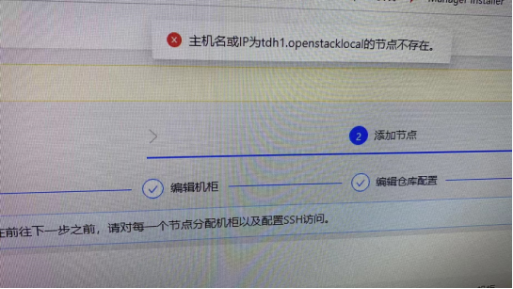
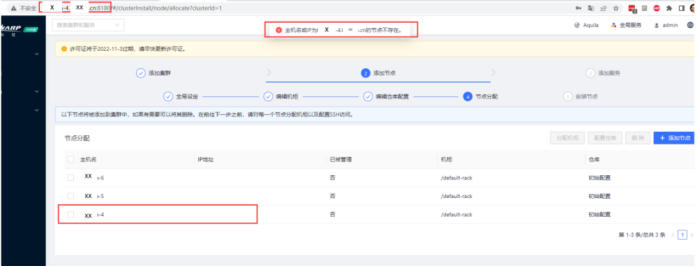
【核心原因】
出现此类报错,请优先检查hostname以及/etc/hosts文件中的主机名是否一致。
下面将介绍两个因为同一个原因导致报错的用户示例,出现报错的核心原因是因为搞混了 hostname 和带domain的hostname。
注意,hostname和全域名(FQDN)是不一样的,FQDN包含两个部分,hostname和域名,hostname就是FQDN的第一个点前面的部分,所以hostname是不包含点的。
如果您也遇到了类似的问题,可参考下述方法进行解决。
【用户现象1】
用户设置的hostname如下图所示,此时ping进行解析的时候实际上解析的是前半部分,比如tdh2而不是tdh2.openstacklocal。
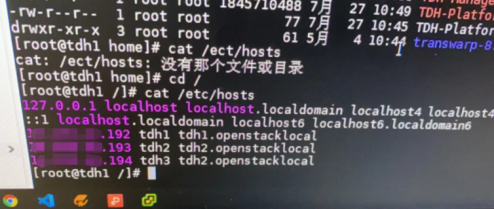
【解决方法】修改hostname后修改hosts文件即可解决(修改为不带后缀“.”),需要注意,修改完之后需要用systemctl restart transwarp-manager-agent重启agent。
【用户现象2】
用户的hostname设置为了xx-4.bigdata.cn,host文件设置的内容则是:
10.xxxx.2 bigdata-6
10.xxxx.3 bigdata-4
10.xxxx.4 bigdata-5【解决方法】使用下述指令修改hostname
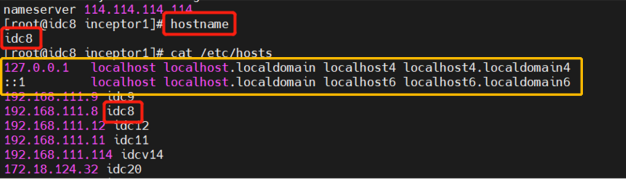
hostnamectl set-hostname bigdata-4安装集群xx中的3个节点失败,日志报错显示:error.nodeHostNotFound

3个节点名称为别为tdh1,tdh2,tdh3

【核心原因】Host文件配置有问题
【解决方法】/etc/hosts 文件的第一行必须为127.0.0.1的记录,不能将此行注释掉。需要参考下方黄色框里的内容,与其基本一致,部署时不要修改该部分,不能把当前主机名写在该行中。
添加节点步骤报错显示“节点无法加入,原因:error.nodeGetHostnameFail”
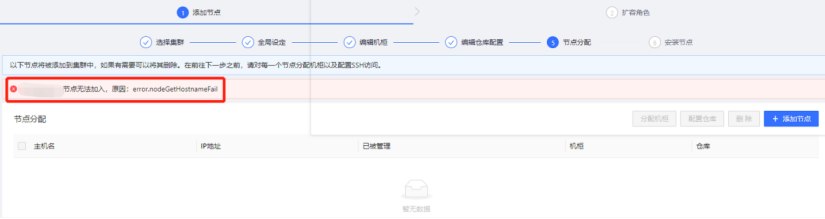
【核心原因】非root用户,必须使用无密码的sudo用户

添加节点时,访问节点身份使用sudo用户,报错显示“节点无法加入,sudo:需要密码”
【用户描述】在安装社区版的时候,用的是非root用户,但是有sudo权限,这里提示需要sudo密码,这个应该在哪儿设置?
【解决方法】需要配置下,使sudo用户无需输入密码。具体执行命令如下:
- root用户登录,执行 vim /etc/sudoers
- 修改 /etc/sudoers文件
%admin ALL=(ALL)改为 %%admin ALL=(ALL) NOPASSWD: ALL3. 保存并退出。重新进行添加节点操作。
安装产品服务过程中可能遇到的问题
通用的排错方法
添加服务阶段初始化服务失败如何定位问题
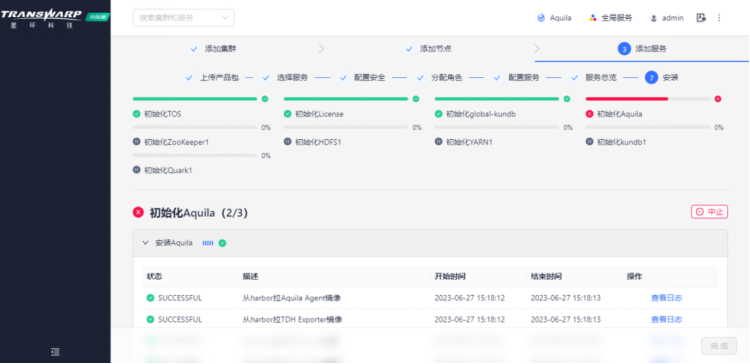
示例一. 初始化Aquila失败,报错步骤为“通过TOS启动service失败”
【问题描述】
社区版安装时,在添加服务步骤初始化Aquila失败,报错内容为“通过TOS启动service失败”,最终导致添加服务失败。显示内容如下图所示:
【排查过程】
1. 查看报错日志
通常在安装过程中出现报错,可以优先查看该步骤右侧的日志排查报错原因。
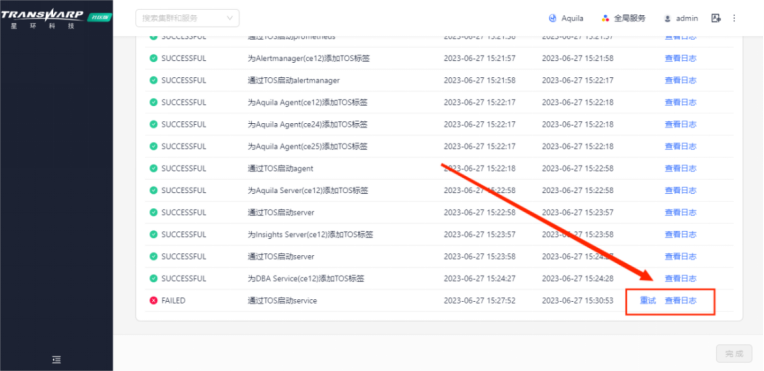

由此可知,安装任务失败是由于Aquila的角色之一DBA Service的Pod出现问题导致,所以需要进一步查看Pod的状态以及日志信息,来定位根因。
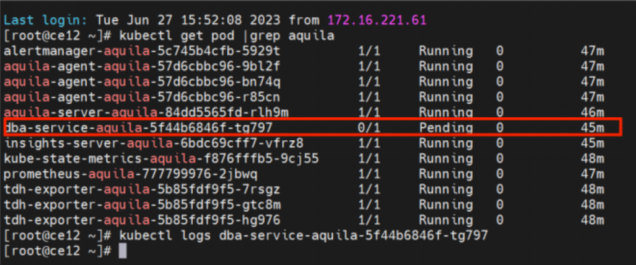
2. 查询DBA Service Pod状态
确定失败服务后,使用 kubectl get pod | grep <组件名称> 命令查询组件相关Pod的运行状态。由下图可以看出,DBA Service Pod处于pending状态。因此,接下来需要展开该Pod的详细信息,来进一步定位问题。
Tips:如果您在查看Pod状态时,显示为Failed或其他状态比如冲突,您可以通过kubectl logs <pod id>,来查看Pod的相关日志。
3. 查看Pod信息
使用命令kubectl describe pod <pod id> 查看信息。
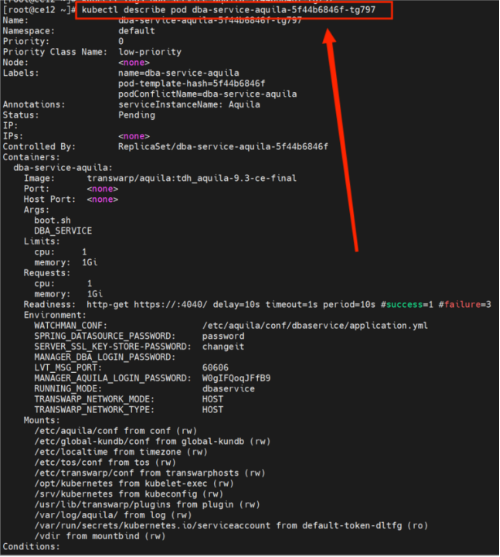
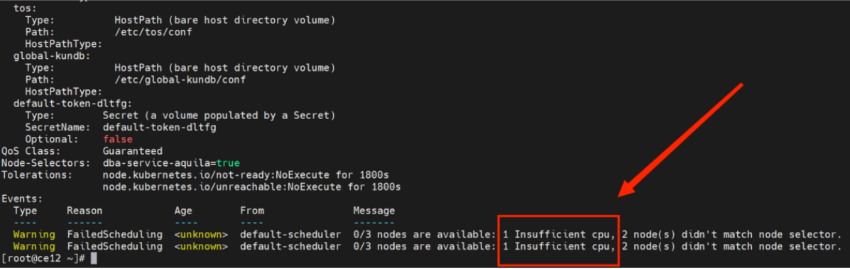
由上图可以看出,这个问题的根因为服务器分配给Aquila的资源不足,CPU资源限制导致该Pod无法启动。
至此,该问题报错的根因已找到,接下来就是做出问题修复,在这提供解决思路和预防措施。
【解决方法】
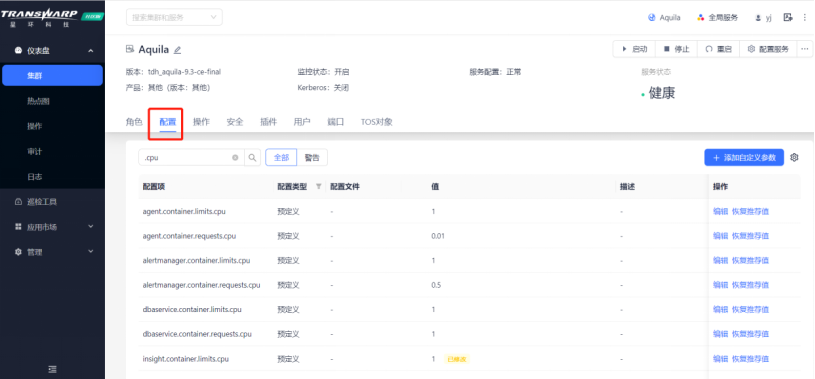
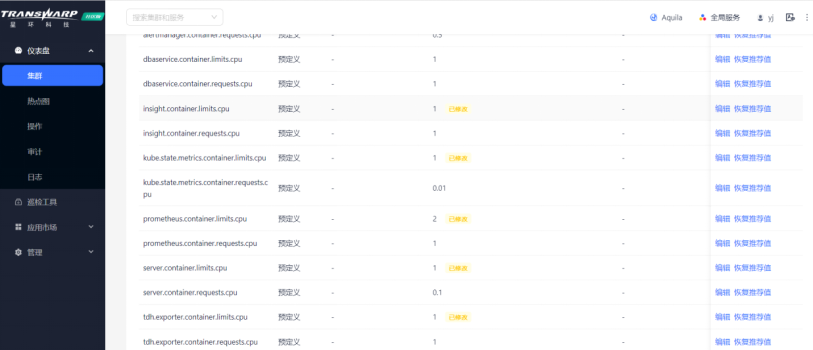
1. 解决思路:修改Aquila服务的资源分配
TDH基于TCOS云原生统一资源调度系统可以实现对各服务所占用的硬件、软件资源做出统一调配。因此在Manager界面可以配置分配给服务的CPU资源,以实现服务的正常运行。修改完成后需要点击“配置服务”,然后重启服务。参考示例如下:
2. 预防措施:均匀分配Aquila角色安装节点
在TDH社区版中,会为大家提供默认的服务配置,大部分服务角色会默认安装在主节点中。若您的的服务器资源较为紧张,您可以通过在安装阶段将Aquila个别服务角色均匀分配在不同节点上,缓解单一节点的负载压力,来预防该问题的发生。
服务配置所处的阶段为:集群搭建--安装服务--分配角色(参考下图)。点击角色可选择不同的安装节点,选择其他节点即可。
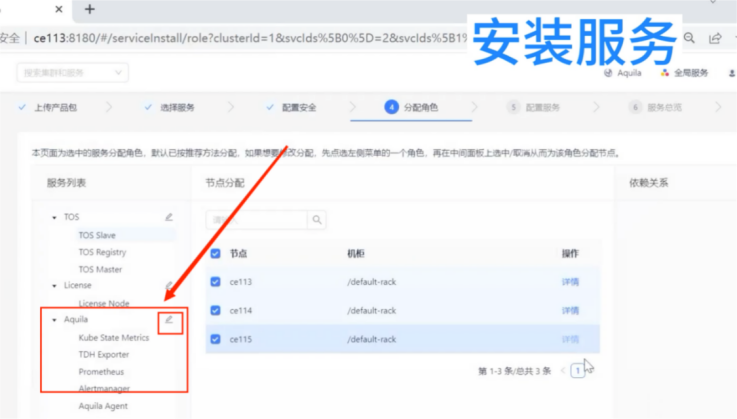
示例二. 初始化Quark失败,报错步骤为“无法启动Quark的角色”
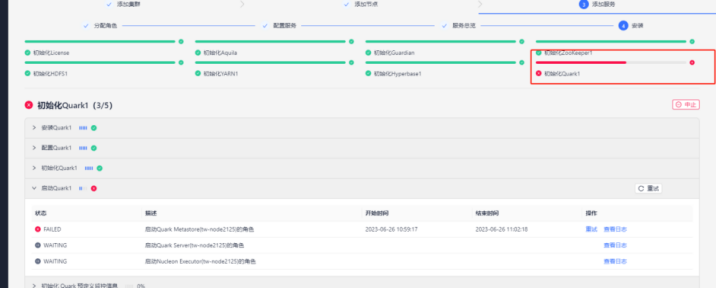
【核心原因】
- 数据库中表缺失
- 因为某些操作,导致数据库中缺失“INCEPTOR_LIBRARY”表,通过执行SQL命令创建表实现修复。
【排查过程】
① 查看Manager界面报错时右侧的查看日志,检查报错原因。
一个小tips:通常页面显示某一步骤失败,可以查看失败日志,日志里一般会提示是执行了什么命令,然后等待600s没变成健康状态,比如这个问题所对应的报错日志中有这么一个信息。

② 查看服务状态
执行docker ps -a命令查看容器id后,执行docker exec -it <containerid> bash的命令,进入容器。进入容器后执行 systemctl status transwarp-quark-metastore@quark1 命令查看服务状态

服务状态显示为失败,因此执行systemctl start transwarp-quark-metastore@quark1启动服务。

③ 修复后重试
执行完成后,在Manger界面重试启动Quark,仍报错。
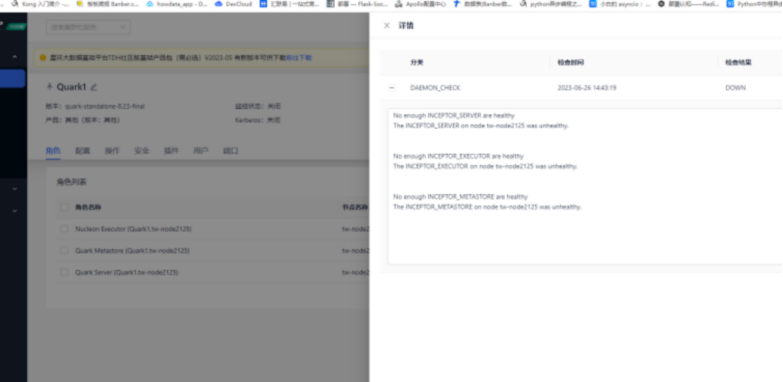
④ 继续排查错误
进入容器后用journalctl -u查看metastore角色的信息,执行journalctl -u transwarp-quark-metastore@quark1
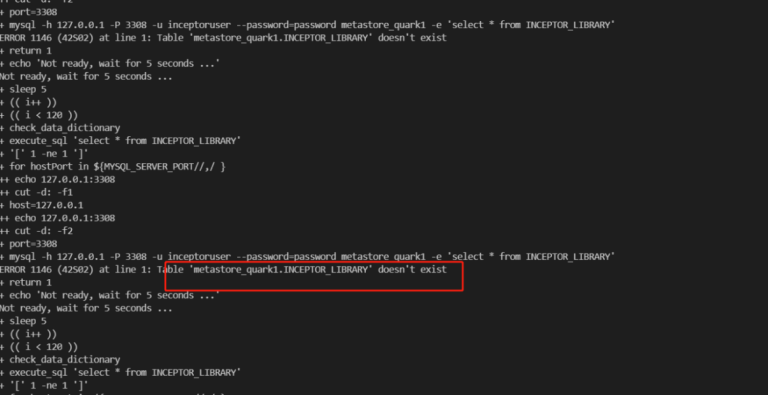
此时查看返回信息,信息显示缺失INCEPTOR_LIBRARY表。因此需要修复该问题。
⑤ 确认报错原因
连接数据库,指令:
# mysql -h 127.0.0.1 -P 3308 -u inceptoruser --password=password metastore_quark1
# show tables;
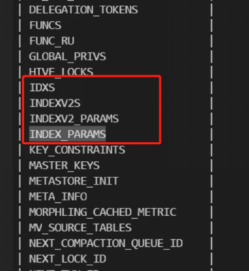
发现上述缺失的表确实不存在,因此需要进行修复。
⑥ 问题修复
执行以下SQL命令修复表。
create table if not exists INCEPTOR_LIBRARY(library_name varchar(200) PRIMARY KEY, library_version varchar(100));
insert into INCEPTOR_LIBRARY values('data-dictionary',1.0);⑦ 重试
执行后回到Manager界面进行重试,重试后即可启动Quark。问题解决。
上传产品包失败
根因1:还没添加完节点就上传产品包
通过报错错误信息中TOS version is显示为空,可以判断出用户还没添加节点就上传产品包了,如下图所示。因此添加完节点再上传就可以了
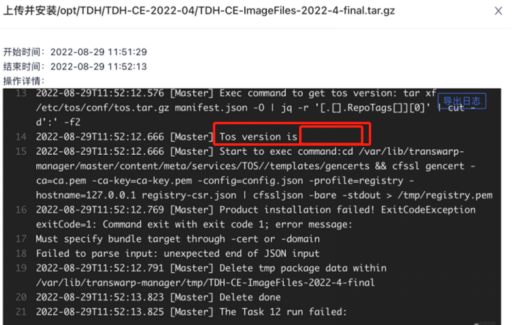
根因2:目录磁盘性能较差,上传超时
如果超过20分钟,则会显示失败,解决方法:
a.解决磁盘io弱的问题;
b.或者联系工作人员单独出私包,将时间修改为60分钟;
根因3:根目录磁盘空间不足,解压失败
根因4:产品包并非标准格式,可能是传输错误,或者是上传了其他的zip包没有解压
根因5:集群registry(TOS的角色)异常
许可证页面打不开、上传产品包失败

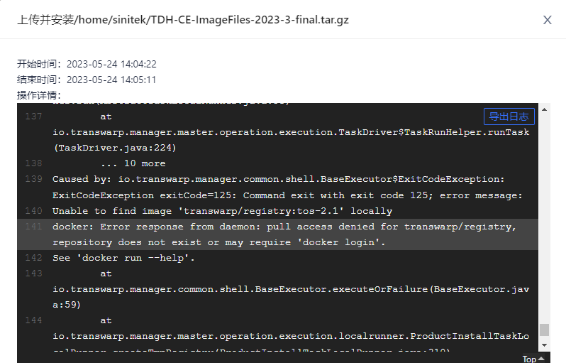
【解决方法】
首次配置时,在配置服务点需要先配置TOS服务。该服务会配置镜像地址等等,上面问题均会解决
安装过程中,配置Quark失败,报错步骤为“生成Collector配置,配置Quark Metastore”

【核心原因】
有可能是没装kundb,所以quark没有依赖上
【解决方法】
安装kundb,更新quark依赖,下推配置,重启quark。


安装Guardian服务报错:“/api/market/install/advices: 500 Internal Server Error”
【核心原因】没有上传产品包,产品包同样在官网下载弹窗中获取
【解决方法】下载并上传
【安装教程】 视频教程
安装guardian的时候报错显示“error code 48000...unauthorized”
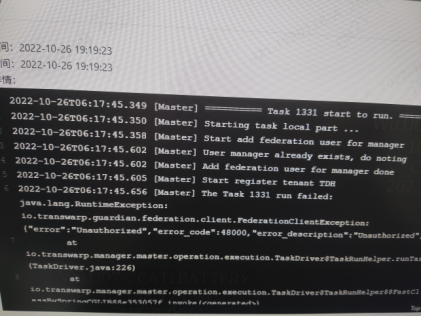
【解决方法】
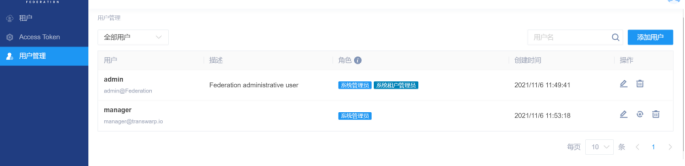
重新开启一个页面进入Guardian服务,角色栏中点击‘Guardian Federation Service’右侧的查看中的链接,进入登录页面,选择用“平台用户登录”,登录后进到用户管理页面,把“manager”这个用户删了,然后返回报错的页面点击“重试“即可。


第二次安装Guardian时卡住了,报错显示“error code 403...Access is denied”
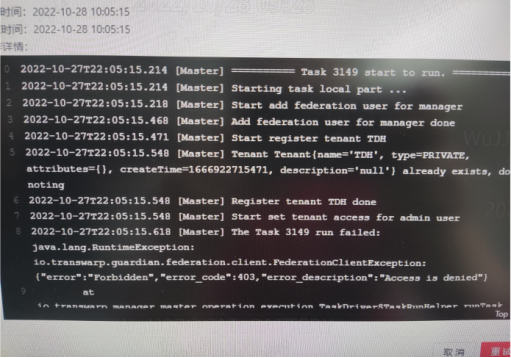
【解决方法】
重新开启一个页面访问Guardian Server进到对应的TDH的租户里面,点击访问管理,点击‘+’把manager用户加成这个租户的管理员,然后返回报错的页面点击“重试“即可。

安装过程中,初始化HDFS失败

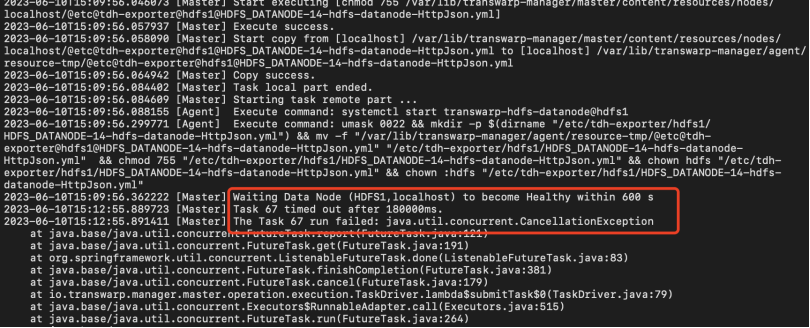
【核心原因】未更改主机名
【解决办法】请在服务器端使用hostnamectl set-hostname [hostname]。主机名注意需符合DNS-1123规范,由数字、小写字母或“-”组成,不能包含大写字母,长度小于63
Dashboard安装完成后状态显示不可用
先重启,如果重启后依然显示不可用的话,修改/var/lib/transwarp-manager/master/content/meta/services/DASHBOARD/tos-2.1/templates/下面的dashboard-deployment.yaml和dashboard-service.yaml文件:
a) dashboard-deployment.yaml文件这么改:

b) dashboard-service.yaml文件这么改:
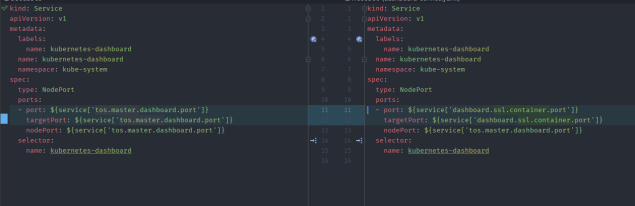
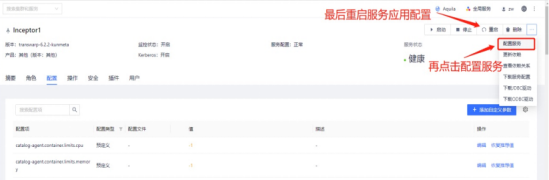
然后再重启manager,重启后选择右上角配置服务,配置完成后再dashboard配置服务,之后重启dashboard就好了
注:dashboard配置服务在服务右上角的菜单里
TOS服务显示待安装状态,安装时报错无法添加register角色
【问题描述】
TDH第一次安装,在安装tos的时候显示 待安装状态,然后添加角色显示tos-tos registry:要求最少节点数为1,但是加不上register角色,这样要怎么解决?
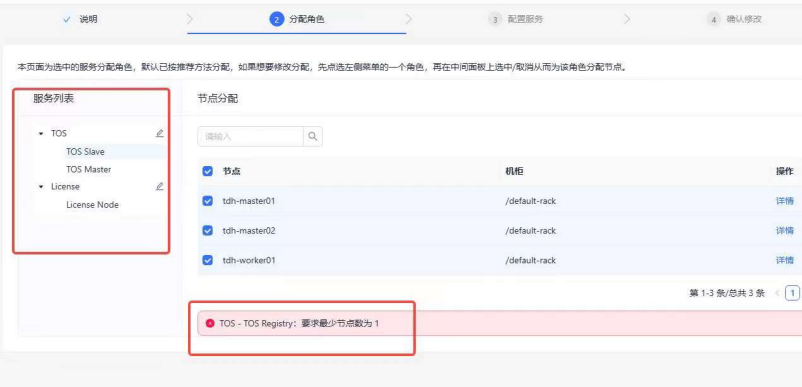
【解决方法】TOS服务未安装成功,可以在TOS服务页面删除服务后,重新安装服务。安装流程:集群—添加服务—其他—TOS。
...未完待续
 登录后可回答问题
登录后可回答问题








.jpg)



