【TDH社区版】集群使用时遇到kubectl命令执行失败,排查步骤及对应解决方案
排查流程原理解释:
在TDH社区版(分布式)集群中,kubectl命令执行时请求流转为kubectl-->haproxy–>apiserver–>etcd; haproxy在这里起到代理作用,将请求分发给后面的apiserver,具体可看haproxy配置;etcd则可以理解为TOS的“元数据库“。因此,当kubectl命令执行失败时,可以依据请求流转步骤进行排查,逐步定位问题并解决。
详细说明
1.检查TOS是否正常
通过确定kubelet服务状态,可以判断出TOS的健康状态。kubelet 是 Kubernetes(简称 K8s)集群中每个工作节点(worker node)上的核心组件之一,负责管理节点上的容器化应用实例(Pods)的生命周期,并确保节点与 Kubernetes 控制平面(主要是 kube-apiserver)保持通信,实现节点资源的有效利用和集群中容器的正确调度与运行。
执行命令查看:
systemctl status kubelet -l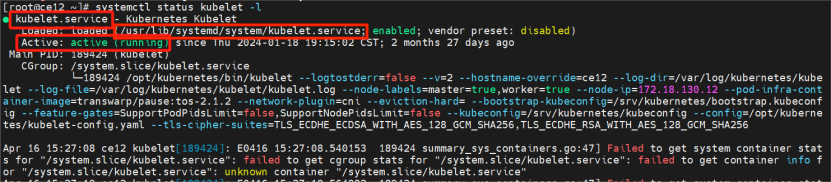
注意:其配置文件必须是/usr/lib/systemd/system/kubelet.service,以及其内容未被篡改
2.检查kubectl命令的详细信息
执行which kubectl查看kubectl命令的详细信息。 
TDH环境指定了别名,全称是如下所示,如果没有别名、或别名中使用到的配置文件丢失等都会导致kubectl命令无法使用。
alias kubectl='kubectl -s https://127.0.0.1:6443 --certificate-authority=/srv/kubernetes/ca.pem --client-certificate=/srv/kubernetes/admin.pem --client-key=/srv/kubernetes/admin-key.pem'
/usr/bin/kubectl3.测试指定apiserver执行命令
尝试指定apiserver的方式执行命令,示例如下:(如果指定apiserver可以执行,那么大概率是haproxy代理转发出了问题)
kubectl get pod --server=https://<节点IP:端口> ##其中server为apiserver的地址 
4.检查haproxy服务
查看haproxy服务是否正常,端口是否在监听,配置文件是否包含apiserver地址;
(1) 执行命令查看haproxy服务状态;
systemctl status haproxy
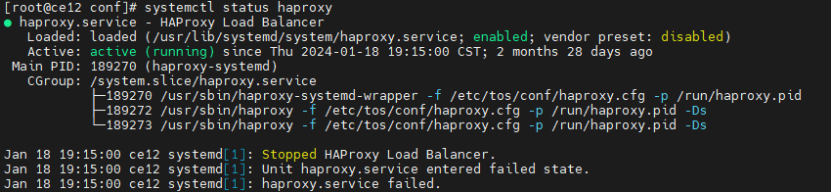
(2) 查看端口是否被监听;
netstat -anp | grep 6443less
(3) 检查配置文件是否包含apiserver地址;
/etc/tos/conf/haproxy.cfg4.1 haproxy服务启动失败问题举例,并展示解决方案。
(1) TDH升级/卸载重装时TOS启动失败
该类场景下,启动 TOS 相关角色时失败,执行systemctl status haproxy查看服务状态 或执行 journalctl -u haproxy | egrep -i "fail|error"查看报错日志。 若出现如下类似错误:
Failed at step EXEC spawning /usr/sbin/haproxy-systemd-wrapper:No such file or directory
问题原因分析:该问题可能是安装时缺失文件导致
解决解决思路:以 Centos7 为例,可用如下方法解决
# 备份 haproxy.service 文件
[root@amen01-7 ~]# mv /usr/lib/systemd/system/haproxy.service{,.rpmsave}
# 重装 haproxy
[root@amen01-7 ~]# yum erase -y haproxy && yum install -y haproxy
# 把备份好的 haproxy.service 还原
[root@amen01-7 ~]# mv -f /usr/lib/systemd/system/haproxy.service.rpmsave /usr/lib/systemd/system/haproxy.service
# 重启 haproxy
[root@amen01-7 ~]# systemctl daemon-reload && systemctl restart haproxy && systemctl enable haproxy
(2) 服务器系统打补丁或升级后,TOS 启动失败
该类场景下启动 TOS 相关角色时,TOS slave 能启动成功,但是其余 TOS 角色启动失败,排查线索如下:
# K8s 连接 apiserver 被拒
[root@amen01-7 ~]# kubectl get po -n kube-system
The connection to the server 127.0.0.1:6443 was refused - did you specify the right host or port?
# 查看 6443 端口没在监听
[root@amen01-7 ~]# ss -lanp | egrep 6443 | grep -i listen
[root@amen01-7 ~]#
# 查看 haproxy 状态正常 running
[root@amen01-7 ~]# systemctl status haproxy.service
● haproxy.service - HAProxy Load Balancer
Loaded: loaded (/usr/lib/systemd/system/haproxy.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2020-07-22 16:47:57 CST; 12min ago
--但可以看到 haproxy 的启动参数里的异常如下图,路径不对。正常 TOS 的 haproxy 角色该启动参数应为: /etc/tos/conf/haproxy.cfg

解决方案:
- 修改 /usr/lib/systemd/system/haproxy.service,或者从正常节点拷贝一个到有问题的节点。

- 重启 haproxy,以 Centos7 为例,可以看到 6443 端口已经处于 LISTEN 状态,然后再重试启动 TOS。
[root@amen01-7 ~]# systemctl daemon-reload && systemctl restart haproxy && ss -lanp | egrep 6443 | grep -i listen
tcp LISTEN 0 1024 *:6443 *:* 5.检查etcd状态
Etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现,它通过Raft一致性算法处理日志复制以保证强一致性,我们可以理解它为一个高可用强一致性的服务发现存储仓库。在TDH社区版集群中,所有etcd必须全部健康。
(1) 检查etcd的pod状态
执行下述命令查看所有的etcd pod状态,确定有几个etcd pod状态不正常,然后进行故障修复。
kubectl -n kube-system get pod -owide 确认etcd pod是否为 1/1 running
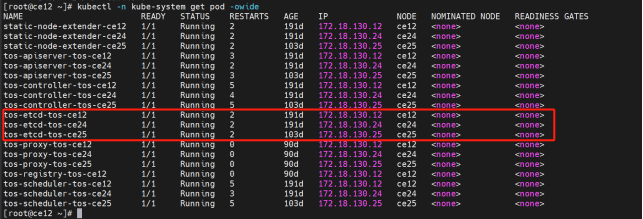
(2)检查etcd是否都是healthy:successfully
执行下方命令,命令中的hostname注意要换成自己集群etcd所在节点的。
ETCDCTL_API=3 etcdctl --cacert /srv/kubernetes/etcd-ca.pem --cert /srv/kubernetes/etcd.pem --key /srv/kubernetes/etcd-key.pem --endpoints https://ce12:4001,https://ce24:4001,https://ce25:4001 endpoint health
5.1 单节点的etcd故障修复
下述修复方式仅针对出现单一节点的etcd故障。
(注意:多节点或全部节点故障,请咨询技术人员寻求技术支持)
执行下方命令:
mv /opt/kubernetes/manifests-multi/tos-etcd.manifest /tmp/tos-etcd.manifest
mv /var/etcd/data /var/etcd/data_bak
编辑 /tmp/tos-etcd.manifest,修改参数–initial-cluster-state的值为existing,如果new,则new改为existing
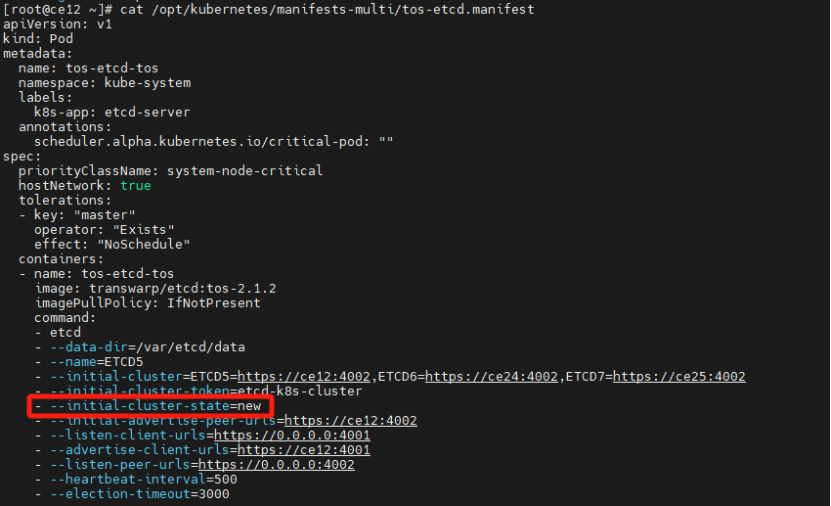
修改完成后,执行下方命令:
mv /tmp/tos-etcd.manifest /opt/kubernetes/manifests-multi/tos-etcd.manifest检查etcd是否恢复健康状态。
相关文章链接:
 登录后可回答问题
登录后可回答问题









.jpg)



