图数据库是怎样一种数据库,和传统关系数据库的主要区别在哪里?
友情链接:
什么是图数据库
从前,有个男人叫小帅,他有个弟弟叫小强,他们有个漂亮的邻居叫小美,他们三个在同一所学校读书。小帅喜欢小美,小强也喜欢小美,但小美不喜欢小强,小美喜欢的人是小帅。
没关系,我们画一张简单的图来帮大家理清一下关系。
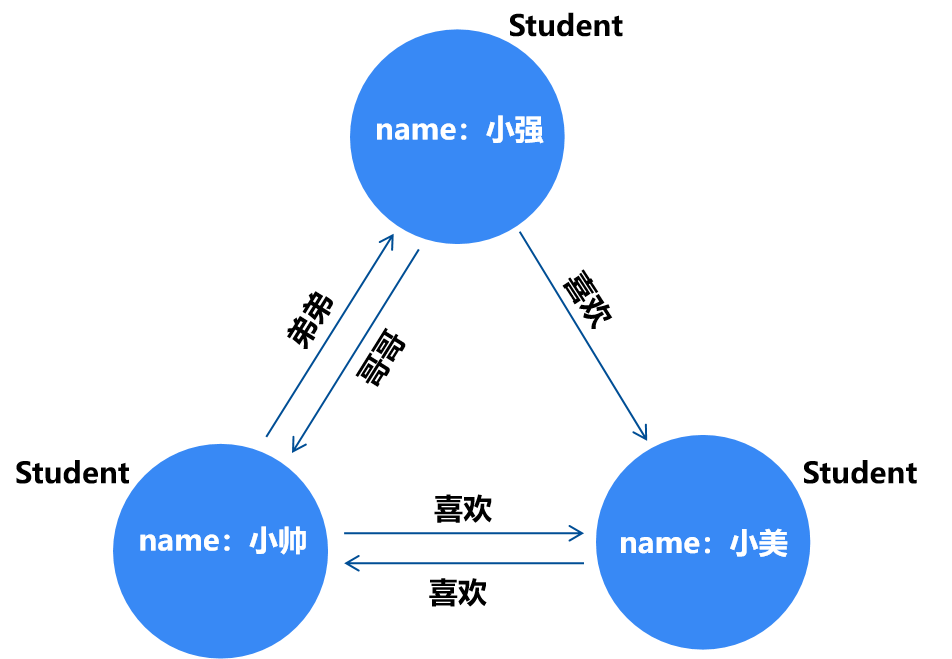
看了上面这张图,有没有一种拨开云雾的赶脚,感觉整个世界都清晰了?
那其实这里我们是用了图结构来表达数据。图是由节点和关系两个元素组成的,每个节点代表一个实体,例如人,地,事物,类别等,每个关系代表两个节点的关联方式。
那图数据库就是一种使用图结构进行存储和查询的数据库,其中节点和边用于对数据进行表示和存储。
常用的图模型有2种,分别是属性图(Property Graph)和资源描述框架(RDF),现在较为知名的图数据库主要是基于属性图,也就是我们上面画的那张图。
属性图由顶点(圆圈)、边(箭头)、属性(key:value)组成。以上面我们画的图为例,三个顶点都有一个标签是student,同时还有属性name,属性值分别是小帅,小强,小美。顶点之间的边表示了他们的关系,哥哥,弟弟,喜欢。如果两人之间的边是双向的,说明两人有相互关系,如果是单向的……
图数据库与传统关系型数据库的区别
小帅和小美两个人平时在学校都是分开上课,接触的机会不多。为了增加和小美相处的机会,小帅想和小美选一样的课,那他们就可以天天在一起了。但小帅又不想直接问小美选什么课,他想以偶遇的方式和小美在课堂上遇见。
为了了解小美选课情况,小帅首先想到的是用传统关系型数据库进行查询。
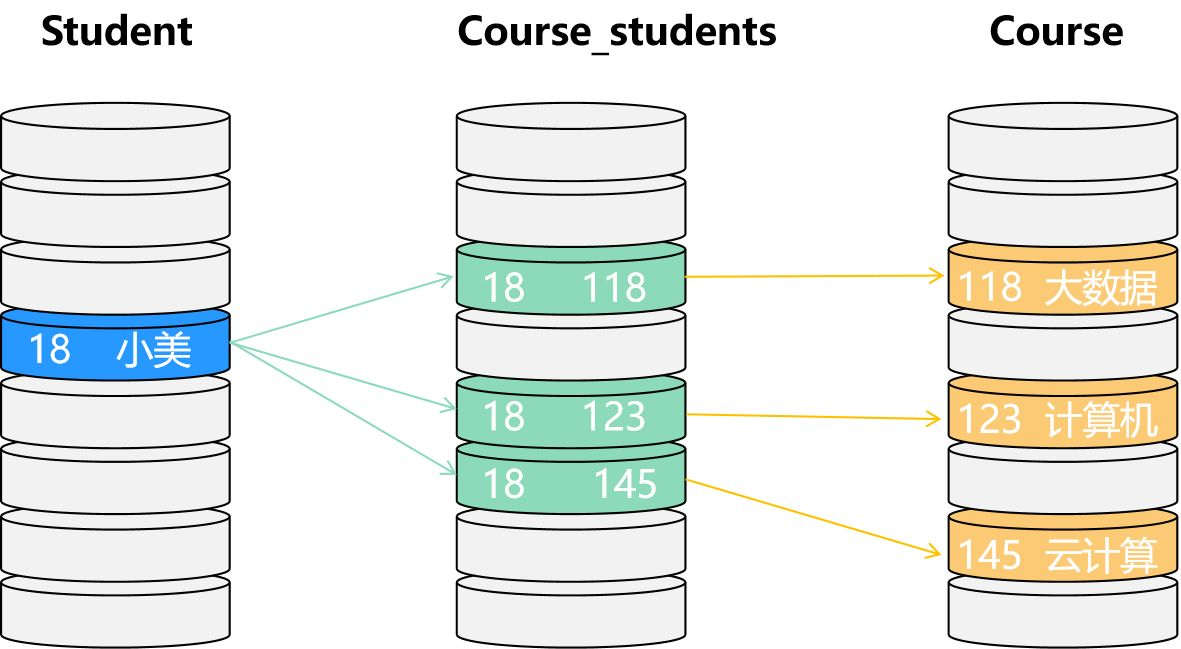
在关系型数据库中,我们一般需要建立学生信息表,学生和课程对应关系表,课程信息表。
小帅想查询小美选了哪些课,需要分3步:
- 第一步a,通过学生信息表找到小美对应的学号18;
- 第二步b,使用学号去学生和课程对应关系表中找到小美选课的课程ID,如118,123,145;
- 第三步c,使用课程ID在课程信息表中找到对应的课程名称等信息,如大数据,计算机,云计算。
第一步a需要一次索引查找过程,第二步b也需要一次索引查找,第三步c需要3次索引查找。大学里有几万名学生,小美又是个学霸,选了很多很多的课,那么学生和课程对应关系表的记录会非常多,通过表与表之间的JOIN操作会带来大量系统性能的损耗,同时会消耗很多时间,查询效率比较低,有时甚至无法返回结果。
所以说,这种情况使用关系型数据库不是不行,只是表形式不擅长描述数据之间的某些特定的复杂关系。
于是,小帅又想到了最近比较火的图数据库,那让我们看看图数据是怎么查询的。
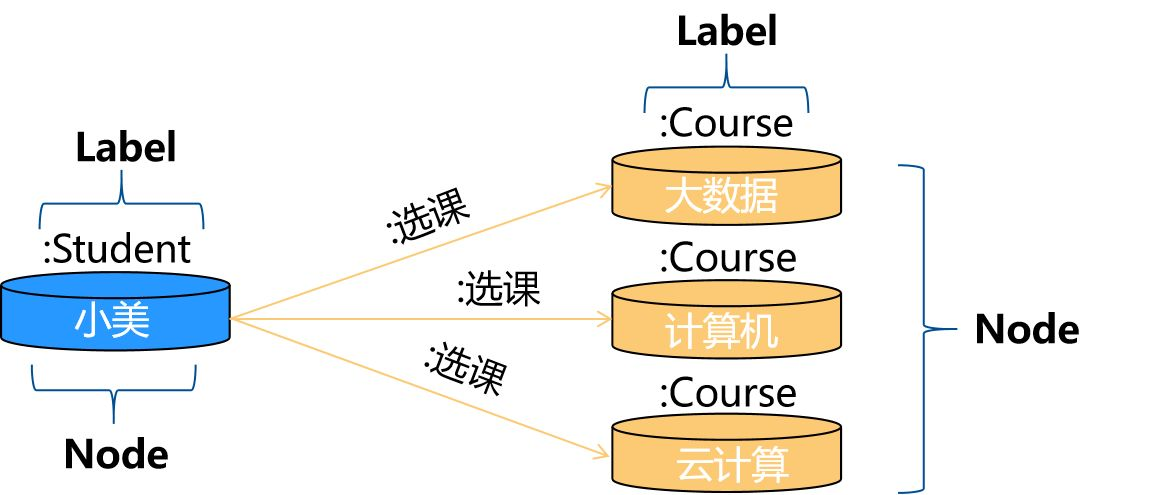
图数据库与关系型数据库的建模方式不同,所以在图数据库中查询就没那么复杂了。在图数据库中,学生和课程都在同一张图中,小美和三门课程都是节点,分别带有标签Student和Course,他们之间通过属性为选课的边建立关联关系。
小帅在查找小美选课情况时也是分为3步:
- 第一步A,通过在学生标签student上建立的索引来找到小美对应的节点;
- 第二步B,再通过节点保存的标签为选课的边来找到对应的课程;
- 第三步C,读取选课课程信息。
虽然图数据库的查询也是分为3步,但效率却大大提高。第一步和传统关系型数据库一样,第二步无需进行索引查找,直接可以通过节点获取,虽然节点存在不同标签的边,但跟学生和课程对应关系表的记录数肯定不是一个数量级的,尤其是在海量数据的情况下,图数据库表现出的性能更加优异,小帅通过图数据库进行数据查询与分析的速度更快。
图数据库的优势
小美有个闺蜜叫大漂亮,大漂亮喜欢小帅的弟弟小强。于是小帅和小美想撮合小强和大漂亮,他们给小强和大漂亮制造了很多相处的机会。经过一段时间的相处,小强逐渐对大漂亮产生了好感。
我们只需在之前的属性图上添加大漂亮这个节点和其与小美、小强的关联边就可以了。
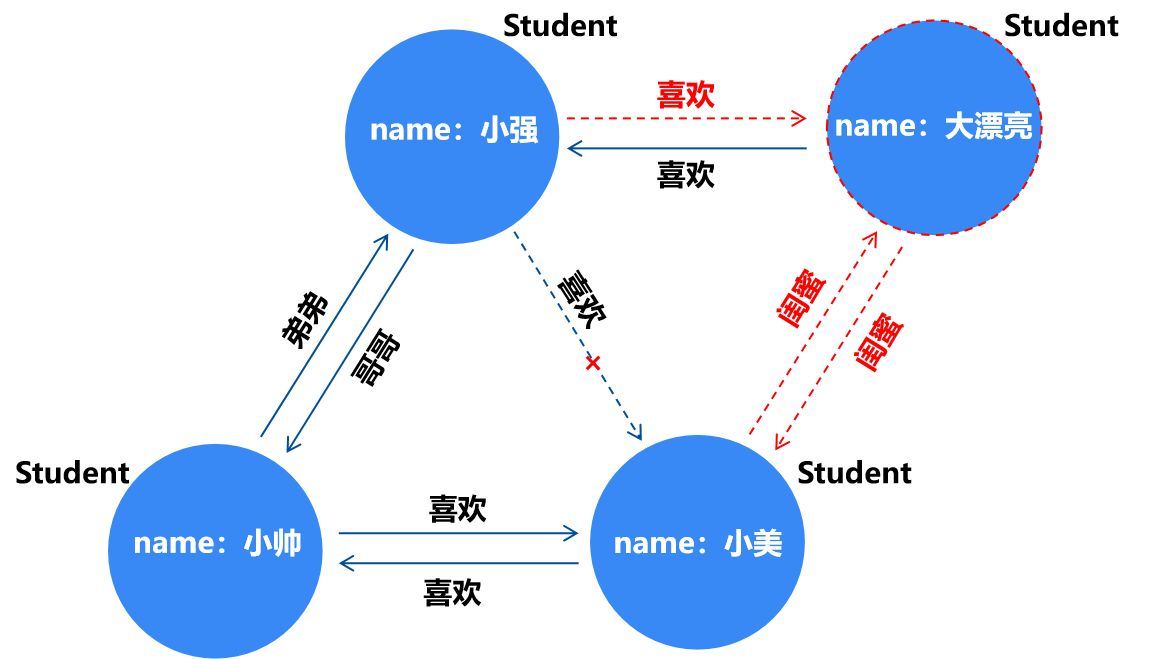
那从上面的介绍你现在知道图数据库有什么优势了么?
与传统关系型数据库相比,图数据库有以下优势:
- 天然解释性:通过用属性图来表达小帅等人以及他们之间的关系,我们可以发现图数据库具有天然解释性。用户可以很自然的表达现实世界中的实体及其关联关系(对应图的顶点及边)。
- 高性能:从小帅通过传统关系型数据库和图数据库进行选课查询可以发现,图数据库在数据关联关系查询中具有更高的性能。传统关系型数据库多个表之间连接操作、外键约束,导致较大的额外开销。而图模型固有的数据索引结构,使得它的数据查询与分析速度更快。
- 灵活性:从大漂亮这个实体以及其关系很自然地融入当前数据中,我们发现图数据灵活的数据模型可以适应不断变化的业务需求,任意添加或删除顶点、边,扩充或者缩小图模型这些都可以轻松实现。
星环科技分布式图数据库StellarDB
鉴于图数据库在数据关系查询方面的优势,小帅决定采用图数据库的方式来查询小美的选课信息,但市面上有那么多图数据库,到底用哪个让小帅很为难。
图数据库根据底层存储实现的不同,可分为原生图数据库和非原生图数据库。
原生图数据库:使用图模型进行数据存储,可以针对图数据做优化,从而带来更好的性能。
非原生图数据库:底层存储使用非图模型进行存储,在存储之上封装图的语义,进行图处理,其优点是易于开发,适合产品众多的大型公司,形成相互配合的产品栈。
Transwarp StellarDB是星环科技自主研发的企业级分布式图数据库,兼容openCypher查询语言,提供海量图数据的存储和分析能力,最大可支持百亿级点、万亿级边的存储,可存储的图数据量可以达到PB级别。此外,对点、边和属性的检索和查询延时可以做到毫秒级。StellarDB还内置二十余种图分析算法和深度图算法,可用于通用的图分析业务场景。

StellarDB可以帮助用户快速开发欺诈检测、推荐引擎、社交网络分析、知识图谱等应用,目前StellarDB在很多行业都有广泛的应用,包括电商、金融、政府和社交网络领域等。
友情链接:
什么是图数据库
从前,有个男人叫小帅,他有个弟弟叫小强,他们有个漂亮的邻居叫小美,他们三个在同一所学校读书。小帅喜欢小美,小强也喜欢小美,但小美不喜欢小强,小美喜欢的人是小帅。
没关系,我们画一张简单的图来帮大家理清一下关系。
看了上面这张图,有没有一种拨开云雾的赶脚,感觉整个世界都清晰了?
那其实这里我们是用了图结构来表达数据。图是由节点和关系两个元素组成的,每个节点代表一个实体,例如人,地,事物,类别等,每个关系代表两个节点的关联方式。
那图数据库就是一种使用图结构进行存储和查询的数据库,其中节点和边用于对数据进行表示和存储。
常用的图模型有2种,分别是属性图(Property Graph)和资源描述框架(RDF),现在较为知名的图数据库主要是基于属性图,也就是我们上面画的那张图。
属性图由顶点(圆圈)、边(箭头)、属性(key:value)组成。以上面我们画的图为例,三个顶点都有一个标签是student,同时还有属性name,属性值分别是小帅,小强,小美。顶点之间的边表示了他们的关系,哥哥,弟弟,喜欢。如果两人之间的边是双向的,说明两人有相互关系,如果是单向的……
图数据库与传统关系型数据库的区别
小帅和小美两个人平时在学校都是分开上课,接触的机会不多。为了增加和小美相处的机会,小帅想和小美选一样的课,那他们就可以天天在一起了。但小帅又不想直接问小美选什么课,他想以偶遇的方式和小美在课堂上遇见。
为了了解小美选课情况,小帅首先想到的是用传统关系型数据库进行查询。
在关系型数据库中,我们一般需要建立学生信息表,学生和课程对应关系表,课程信息表。
小帅想查询小美选了哪些课,需要分3步:
- 第一步a,通过学生信息表找到小美对应的学号18;
- 第二步b,使用学号去学生和课程对应关系表中找到小美选课的课程ID,如118,123,145;
- 第三步c,使用课程ID在课程信息表中找到对应的课程名称等信息,如大数据,计算机,云计算。
第一步a需要一次索引查找过程,第二步b也需要一次索引查找,第三步c需要3次索引查找。大学里有几万名学生,小美又是个学霸,选了很多很多的课,那么学生和课程对应关系表的记录会非常多,通过表与表之间的JOIN操作会带来大量系统性能的损耗,同时会消耗很多时间,查询效率比较低,有时甚至无法返回结果。
所以说,这种情况使用关系型数据库不是不行,只是表形式不擅长描述数据之间的某些特定的复杂关系。
于是,小帅又想到了最近比较火的图数据库,那让我们看看图数据是怎么查询的。
图数据库与关系型数据库的建模方式不同,所以在图数据库中查询就没那么复杂了。在图数据库中,学生和课程都在同一张图中,小美和三门课程都是节点,分别带有标签Student和Course,他们之间通过属性为选课的边建立关联关系。
小帅在查找小美选课情况时也是分为3步:
- 第一步A,通过在学生标签student上建立的索引来找到小美对应的节点;
- 第二步B,再通过节点保存的标签为选课的边来找到对应的课程;
- 第三步C,读取选课课程信息。
虽然图数据库的查询也是分为3步,但效率却大大提高。第一步和传统关系型数据库一样,第二步无需进行索引查找,直接可以通过节点获取,虽然节点存在不同标签的边,但跟学生和课程对应关系表的记录数肯定不是一个数量级的,尤其是在海量数据的情况下,图数据库表现出的性能更加优异,小帅通过图数据库进行数据查询与分析的速度更快。
图数据库的优势
小美有个闺蜜叫大漂亮,大漂亮喜欢小帅的弟弟小强。于是小帅和小美想撮合小强和大漂亮,他们给小强和大漂亮制造了很多相处的机会。经过一段时间的相处,小强逐渐对大漂亮产生了好感。
我们只需在之前的属性图上添加大漂亮这个节点和其与小美、小强的关联边就可以了。
那从上面的介绍你现在知道图数据库有什么优势了么?
与传统关系型数据库相比,图数据库有以下优势:
- 天然解释性:通过用属性图来表达小帅等人以及他们之间的关系,我们可以发现图数据库具有天然解释性。用户可以很自然的表达现实世界中的实体及其关联关系(对应图的顶点及边)。
- 高性能:从小帅通过传统关系型数据库和图数据库进行选课查询可以发现,图数据库在数据关联关系查询中具有更高的性能。传统关系型数据库多个表之间连接操作、外键约束,导致较大的额外开销。而图模型固有的数据索引结构,使得它的数据查询与分析速度更快。
- 灵活性:从大漂亮这个实体以及其关系很自然地融入当前数据中,我们发现图数据灵活的数据模型可以适应不断变化的业务需求,任意添加或删除顶点、边,扩充或者缩小图模型这些都可以轻松实现。
星环科技分布式图数据库StellarDB
鉴于图数据库在数据关系查询方面的优势,小帅决定采用图数据库的方式来查询小美的选课信息,但市面上有那么多图数据库,到底用哪个让小帅很为难。
图数据库根据底层存储实现的不同,可分为原生图数据库和非原生图数据库。
原生图数据库:使用图模型进行数据存储,可以针对图数据做优化,从而带来更好的性能。
非原生图数据库:底层存储使用非图模型进行存储,在存储之上封装图的语义,进行图处理,其优点是易于开发,适合产品众多的大型公司,形成相互配合的产品栈。
Transwarp StellarDB是星环科技自主研发的企业级分布式图数据库,兼容openCypher查询语言,提供海量图数据的存储和分析能力,最大可支持百亿级点、万亿级边的存储,可存储的图数据量可以达到PB级别。此外,对点、边和属性的检索和查询延时可以做到毫秒级。StellarDB还内置二十余种图分析算法和深度图算法,可用于通用的图分析业务场景。
StellarDB可以帮助用户快速开发欺诈检测、推荐引擎、社交网络分析、知识图谱等应用,目前StellarDB在很多行业都有广泛的应用,包括电商、金融、政府和社交网络领域等。
 登录后可评论
登录后可评论
热门问答









.jpg)



