StellarDB社区开发版Demo——《诡秘之主》中人物关系探索
TDH社区版本次发布StellarDB社区版开发版,让更多用户地低资源成本上手体验企业级图数据库。如果您感兴趣的话,可以访问星环官网进行产品下载,StellarDB社区开发版是免费提供给大家的,欢迎大家下载使用。
StellarDB社区开发版相关链接
操作前提
您需要先基于安装手册完成StellarDB图数据库的安装后才可以开始进行下方操作。
一、 描述场景
在本次数据分析项目中,我们将借助知识图谱探索工具KG Explorer深入剖析西方玄幻小说《诡秘之主》中的人物关系网络。通过精细化挖掘角色间的错综关联,掲示那些潜藏于文字背后的微妙线索,这一过程可以为读者和研究者提供洞见,助力预测和解析小说情节未来发展趋势。
二、 数据集介绍
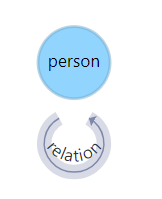
数据集结构:
节点:person
边:relation
数据集获取:
三、 创建图谱并导入数据
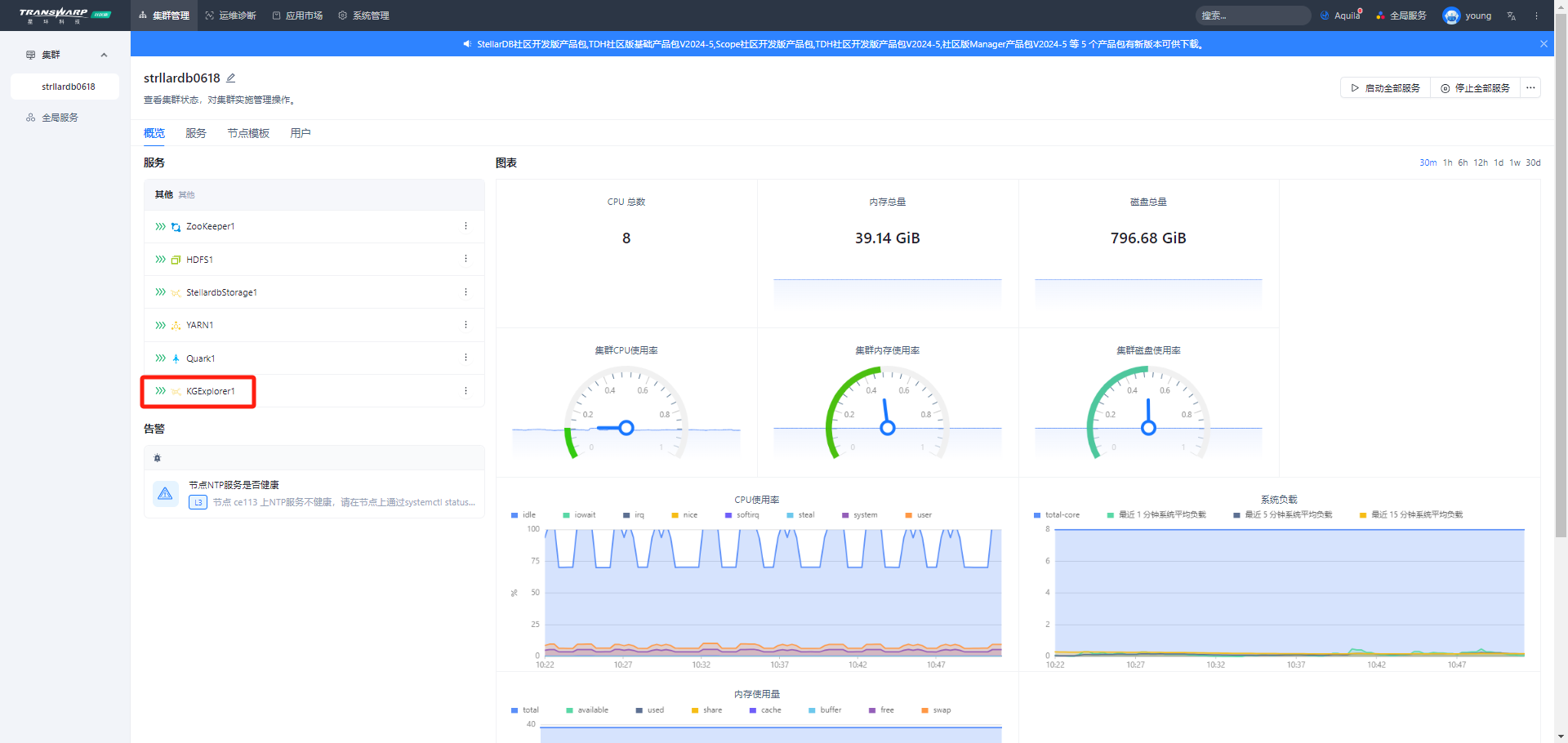
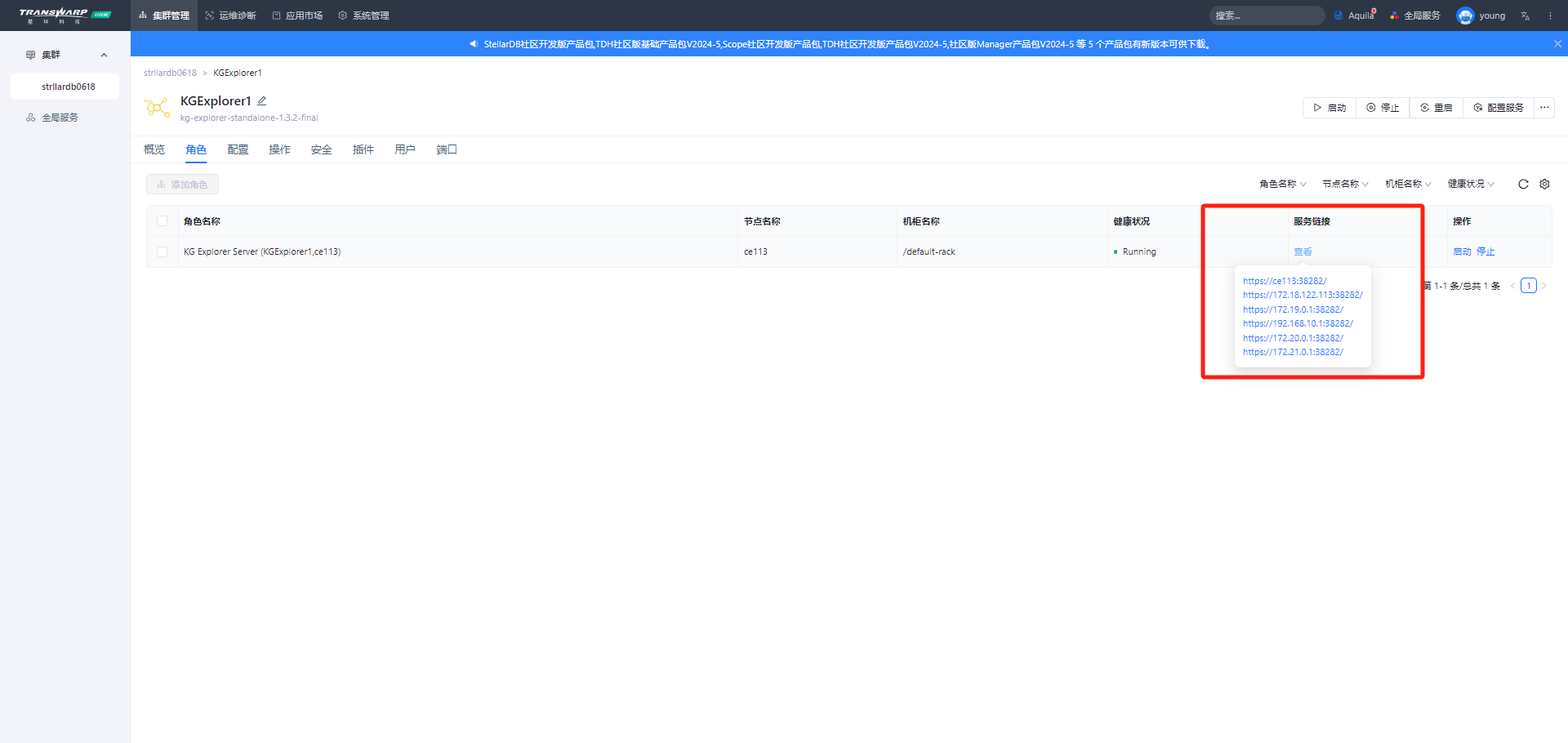
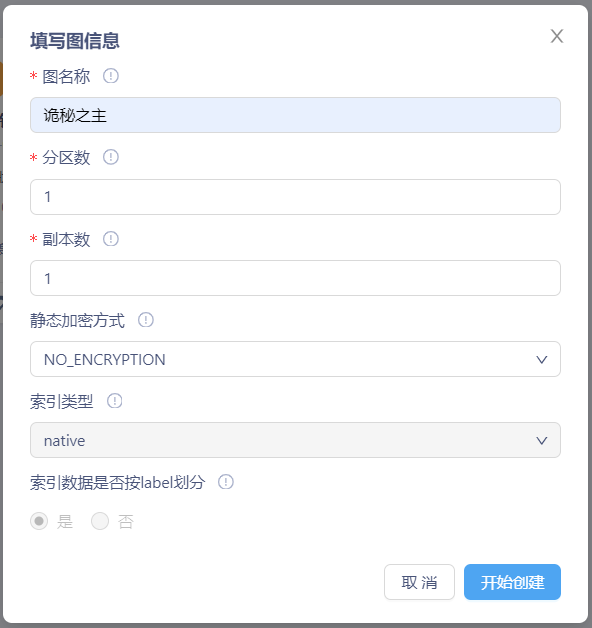
1. 创建图谱(schema)
进入KG Explorer后,点击右上角“创建图”按钮,填写图名称后点击“开始创建”进入图谱编辑页面。
注意:StellarDB社区开发版创建图时,副本数只能为1。
2. 定义图谱
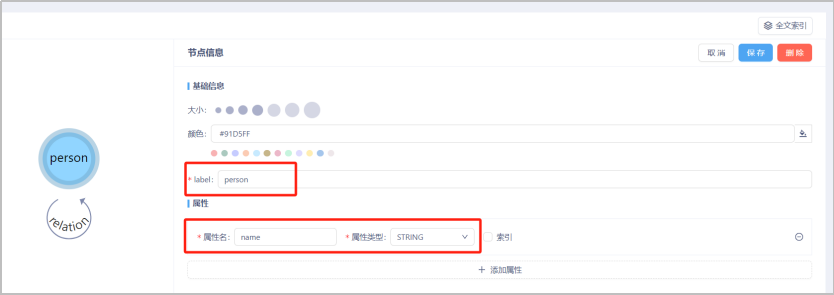
- 添加节点
添加节点:按alt/command+左键单击。在画布中添加节点后,将节点的“label”定义为“person”,并为其添加“name”属性,属性类型为“STRING”。添加完成后点击“保存”。
- 添加关系
添加关系:按住shift键同时选中两个节点完成关系添加。本数据集中仅涉及一种节点,此处可按住shift键同时双击节点即可。将边的“label”定义为“relation”,为其添加“关系”属性,属性类型设定为“STRING”。添加完成后点击“保存”。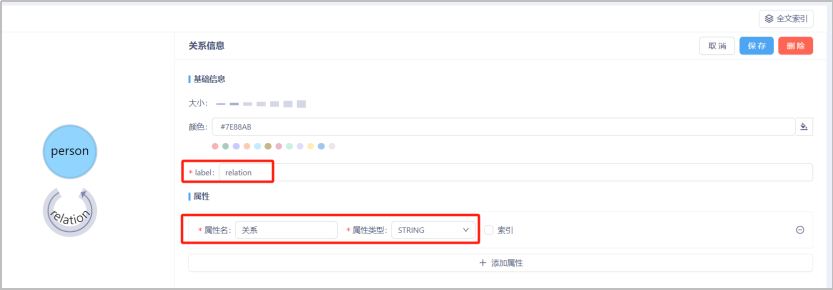
此时,图谱已经构建完成,点击右上角“发布”后,便可导入数据进行人物关系分析。
3. 导入数据
注意:在上传文件之前,需要提前对‘hive’用户进行赋权,否则上传时将报错。操作方式有两种,推荐使用Guardian赋权的方式解决。
1. 在Guardian服务界面点击 ‘一键开启集群安全’,对hive用户赋予HDFS的 ‘/’ 目录可读可写可执行的权限。(推荐操作)
2. 未开启Guardian时,在服务端初始化客户端后,执行如下命令:
export HADOOP_USER_NAME=hdfs
hdfs dfs -chmod -R 777 /
- 数据集上传
在图管理页面找到刚刚创建的图谱,点击“导数”进入数据导入页面
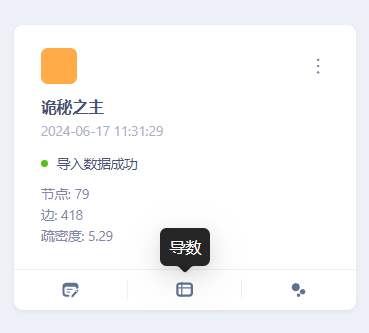
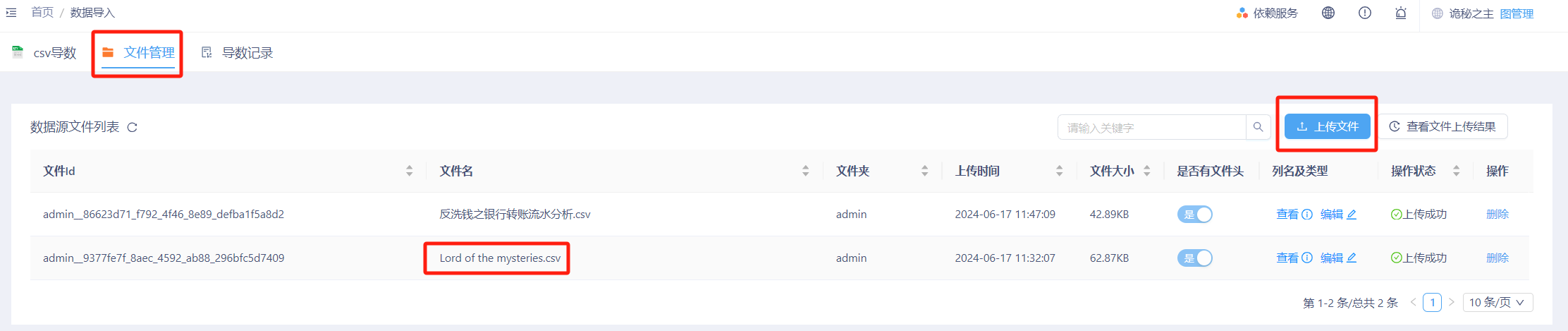
在“数据导入”页面中选择“文件管理”,点击“上传文件”后,选中您刚刚下载的csv文件,将其上传至KG。上传成功后可以看到数据源文件列表中有对应的文件显示。
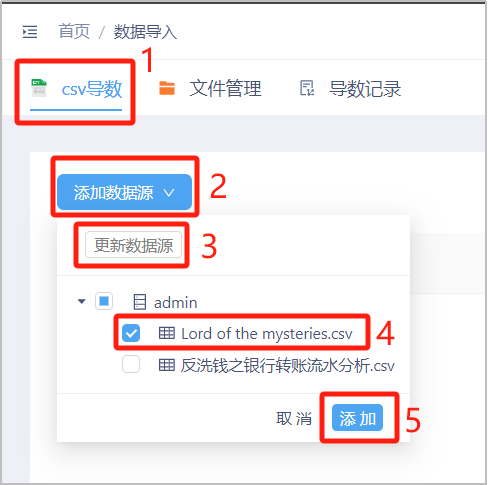
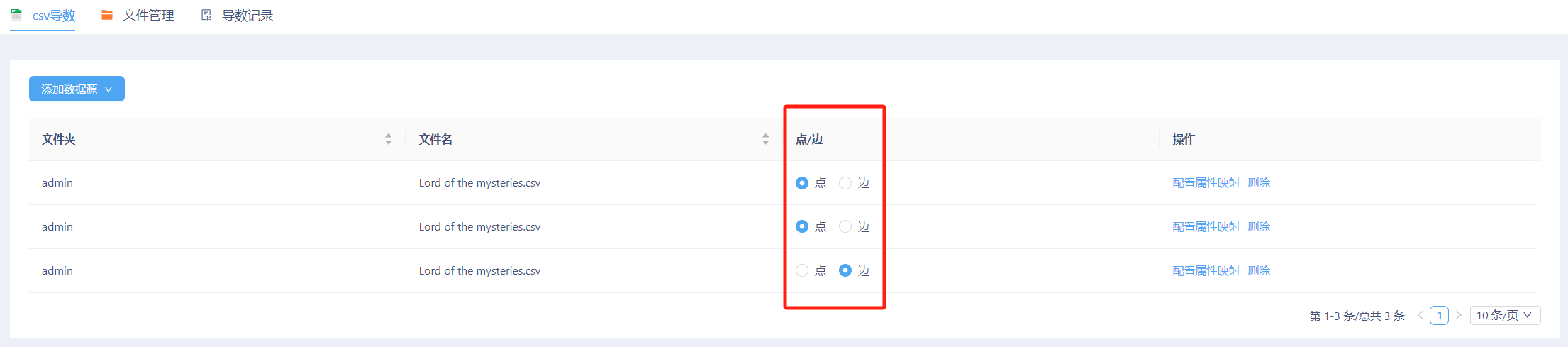
然后,返回csv导数页面,按照如下顺序,依次点击选中目标数据集。注意:由于人物信息与关系信息集中于一个文件中,此处需添加3次数据源(即点击“添加”按钮3次),然后将添加文件分别将“点/边”设定为“点”、“点”、“边”。如下图所示:
- 配置属性映射
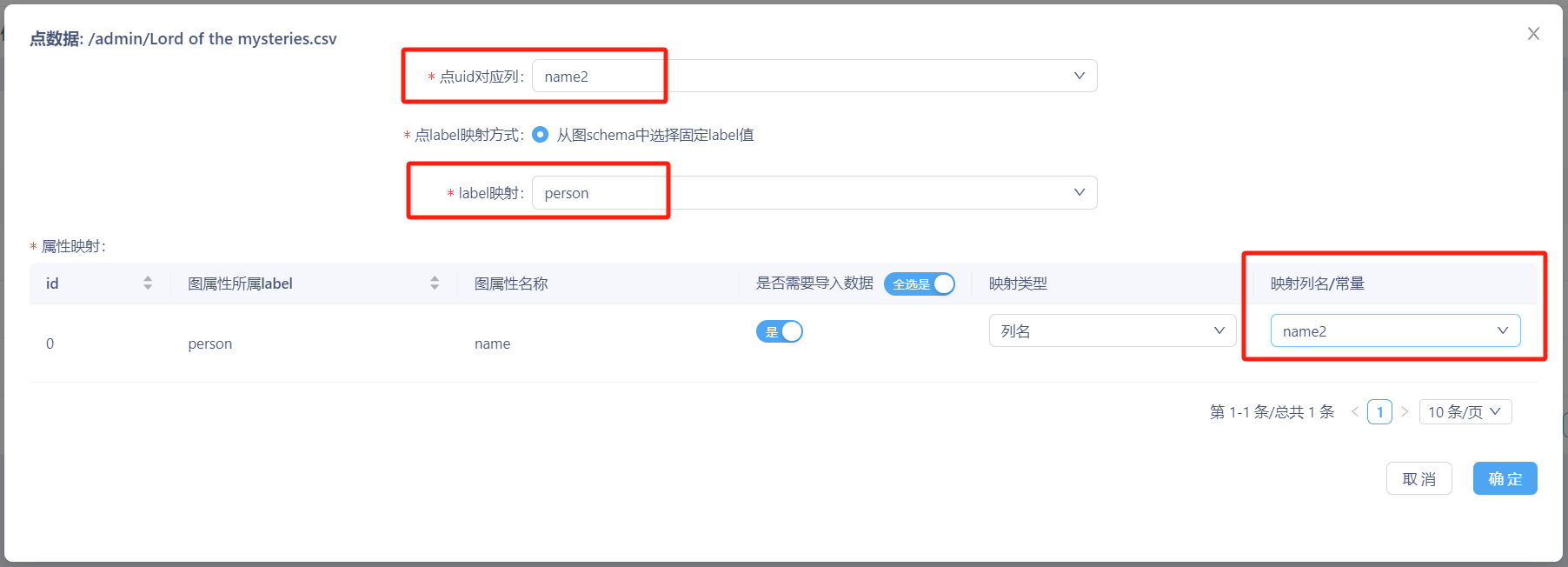
步骤一:对两个点数据进行配置。具体映射配置为:
第一个点数据对应点的uid对应列为‘col0’,label映射为‘person’,映射列名/常量为‘col0’;
第二个点数据对应点的uid对应列为‘name2’,label映射为‘person’,映射列名/常量为‘name2’。
可参照下图进行配置: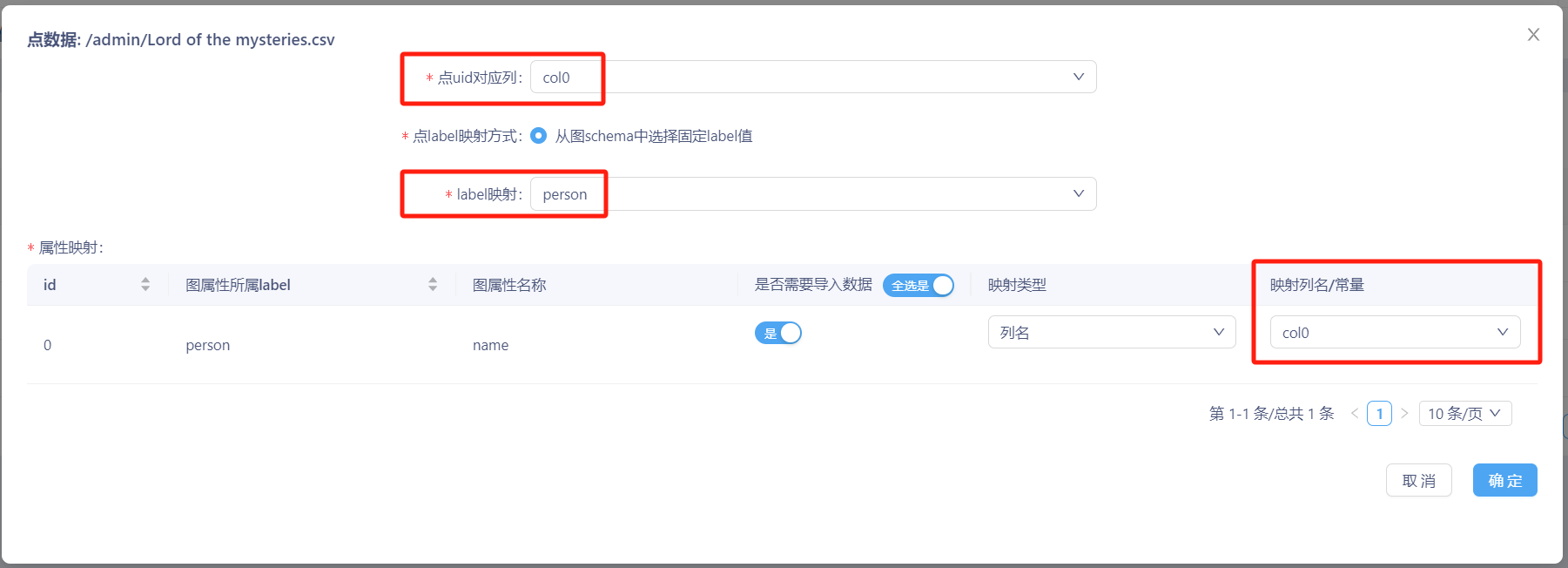
步骤二:对边数据进行配置。具体映射配置为:
边label映射为 ‘relation’、起点uid对应列为 ‘col0’、起点label映射为 ‘person’、终点uid对应列为 ‘name2’、终点label映射为 ‘person’,此外,属性映射中的映射列名/常量为 ‘relation’。
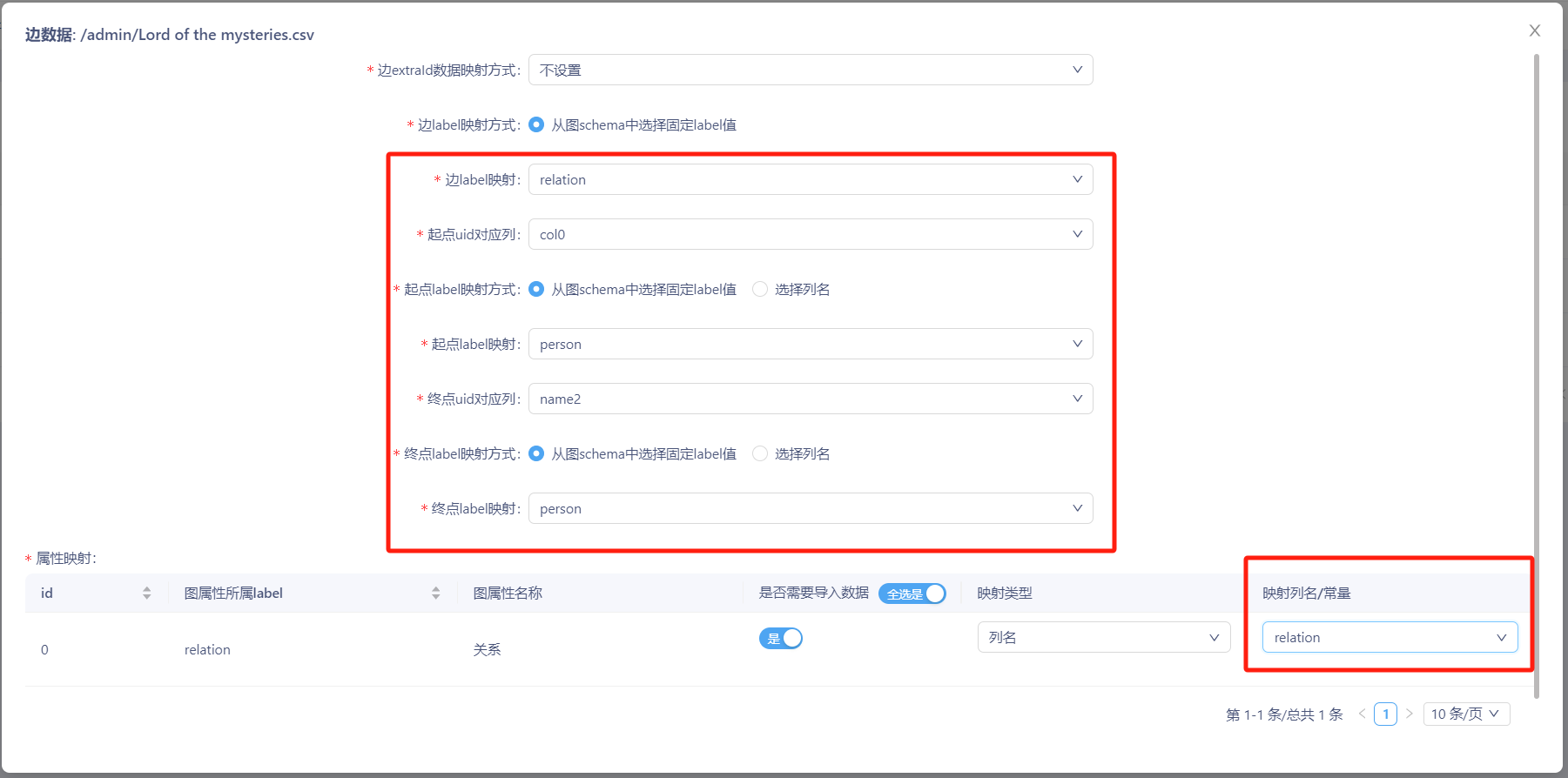
配置完成后,点击右下角“导入”,等待数秒钟后,即可完成数据导入。
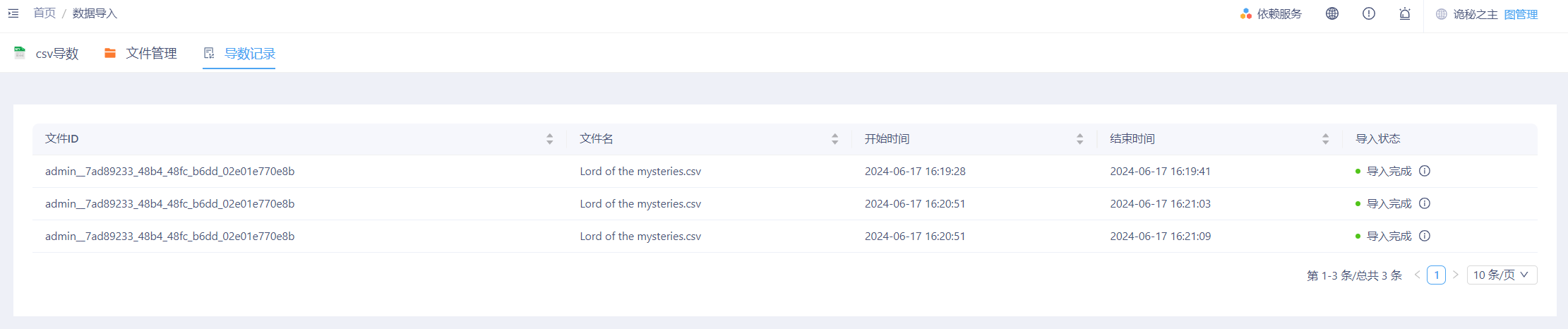
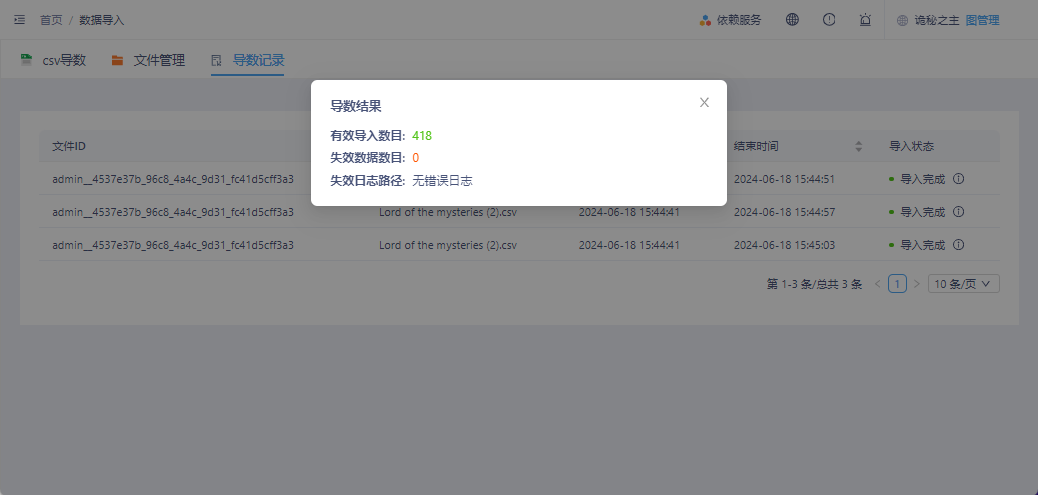
导入完成后,可以查看导入状态,并点击导入状态栏中的标识查看数据导入详情(确保失效数据数目为‘0’),确定导入成功后可以进行数据查询分析。
四、 人物关系查询
接下来,我们共同探索小说中多个关键人物的关系。在图管理页面中点击“诡秘之主”的“图探索”按钮,便可以探寻人物之间的关系。
1. 命令行快速查询
KG Explorer支持您使用 TEoC语言与SQL语言进行查询
(1) 默认语句查询
首先进入图数据查询画布,我们点击右侧查询按钮,使用默认语句查询查找所有相连的节点对以及它们之间关系的信息,并且只返回最先找到的10条记录。可以看到“A先生”与其他人物的关系,此时您可以点击节点或者边查看其基础信息与相关属性。
MATCH (n)-[f]-(m)
RETURN n, m, f
LIMIT 10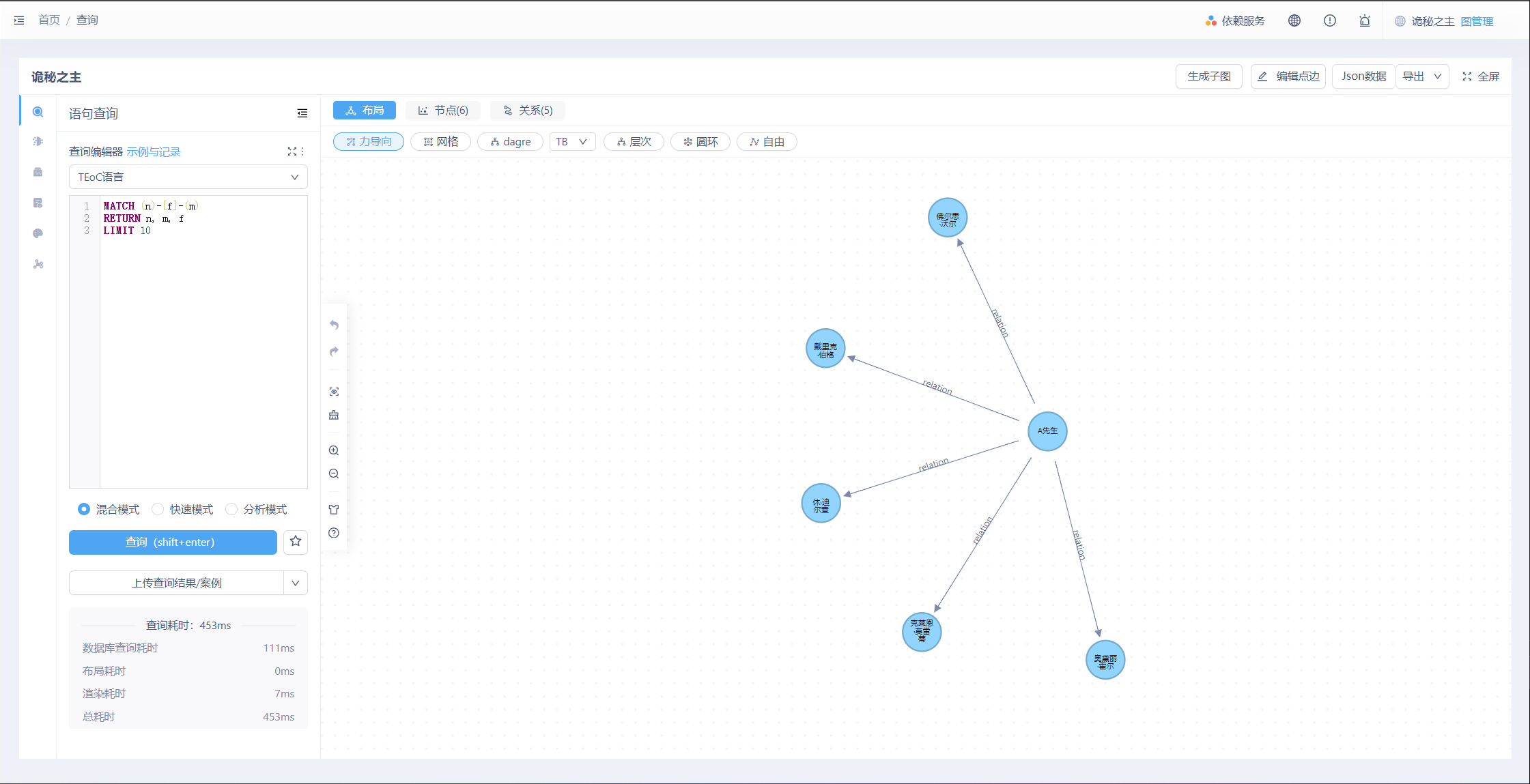
此时我们看到小说的主人公之一“克莱恩·莫雷蒂”也在其中,我们将其设定为橙色,并单击右键选择“展开节点”,此时可以看到所有与克莱恩·莫雷蒂存在关系的人物,并可以查看边来确定他们之间的关系。
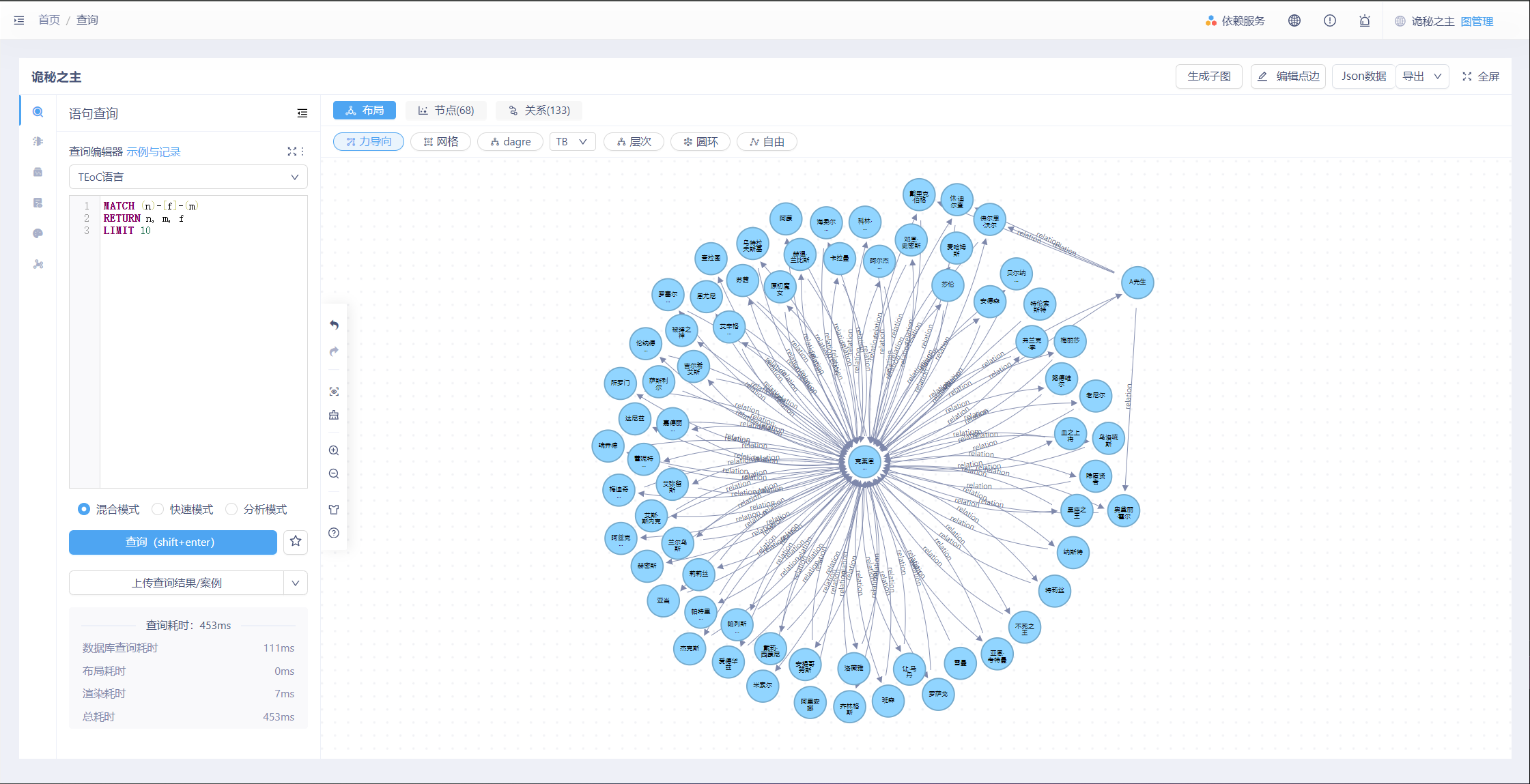
我们将“A先生”隐藏,然后选中“奥黛丽·霍尔”将其变更为红色,重复“展开节点”操作,可以看克莱恩·莫雷蒂与奥黛丽·霍尔共同存有关系的人物角色,以及奥黛丽·霍尔单独存有关系的角色。
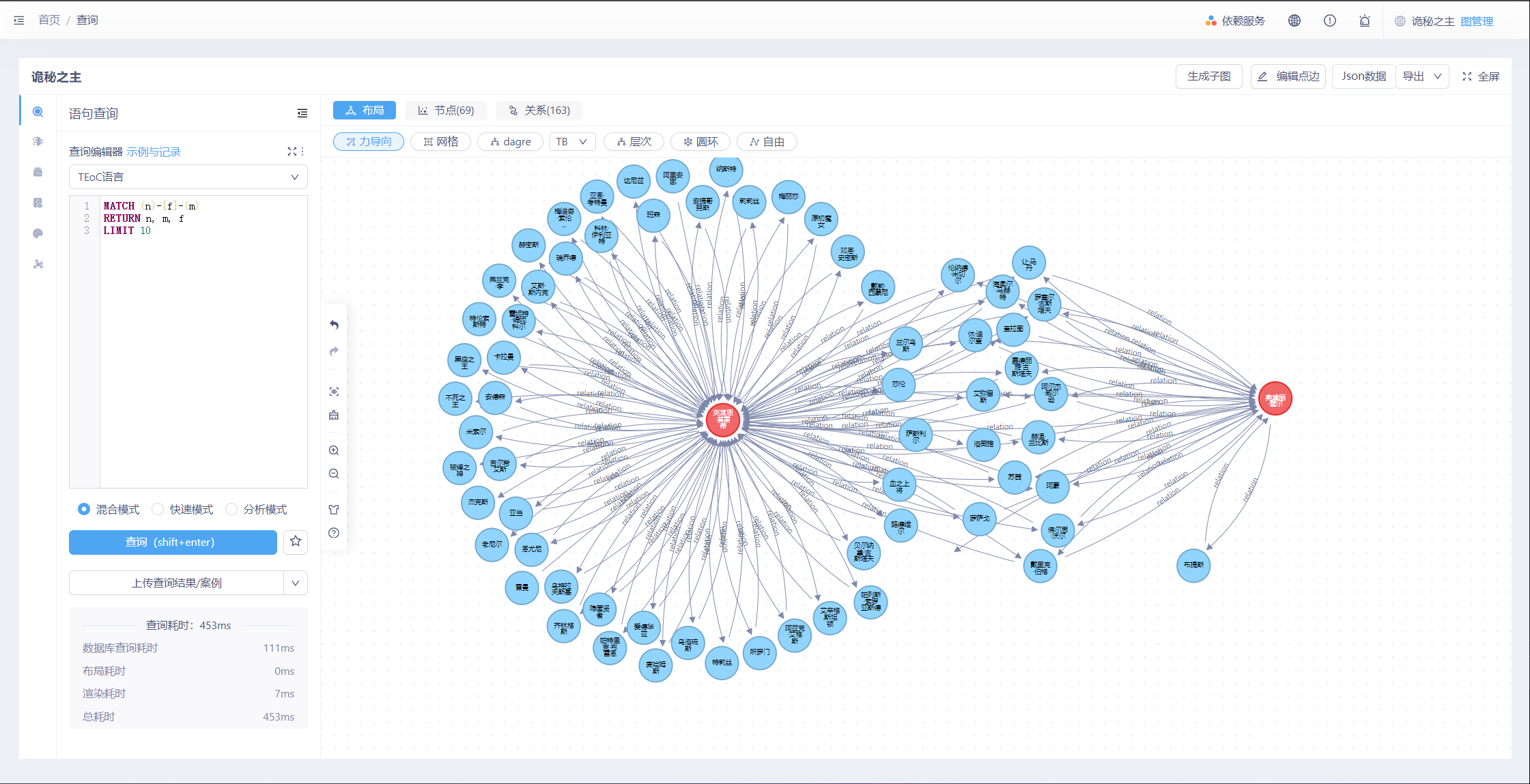
(2) 进阶命令查询信息
- 根据点的属性进行查询
查询名字为“克莱恩·莫雷蒂”、“阿兹克·艾格斯”、“让·马丹”、“奥黛丽·霍尔”的点。
参考下方命令:
MATCH (p:person)
WHERE p.name IN ['克莱恩·莫雷蒂', '阿兹克·艾格斯', '让·马丹', '奥黛丽·霍尔']
RETURN p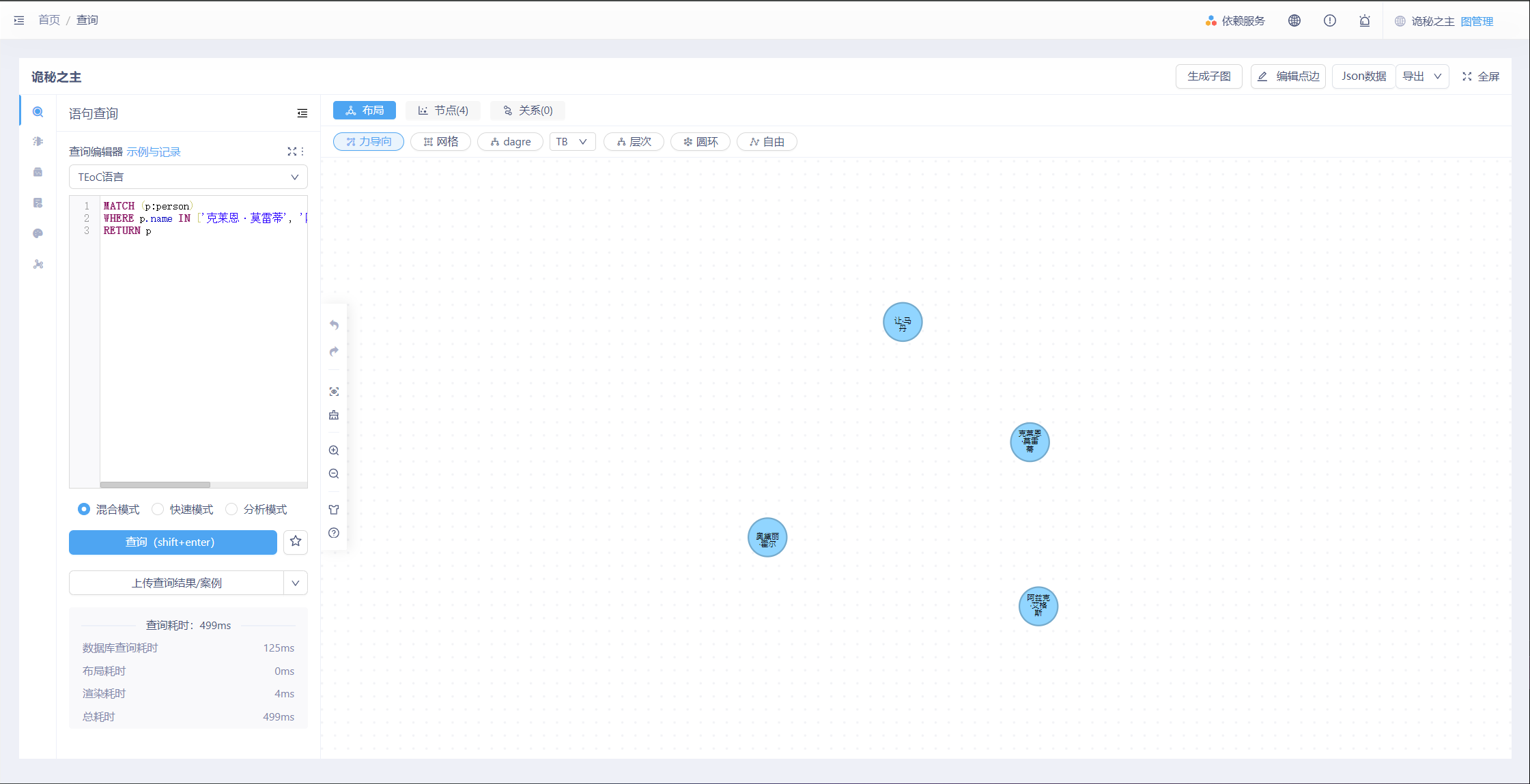
- 根据关系的属性进行查询
查询与“克莱恩·莫雷蒂”有“伙伴”关系的点,并展示边。
参考下方命令:
MATCH (p1:person {name: '克莱恩·莫雷蒂'})-[r:relation {关系: '伙伴'}]->(p2:person)
RETURN p1, r, p2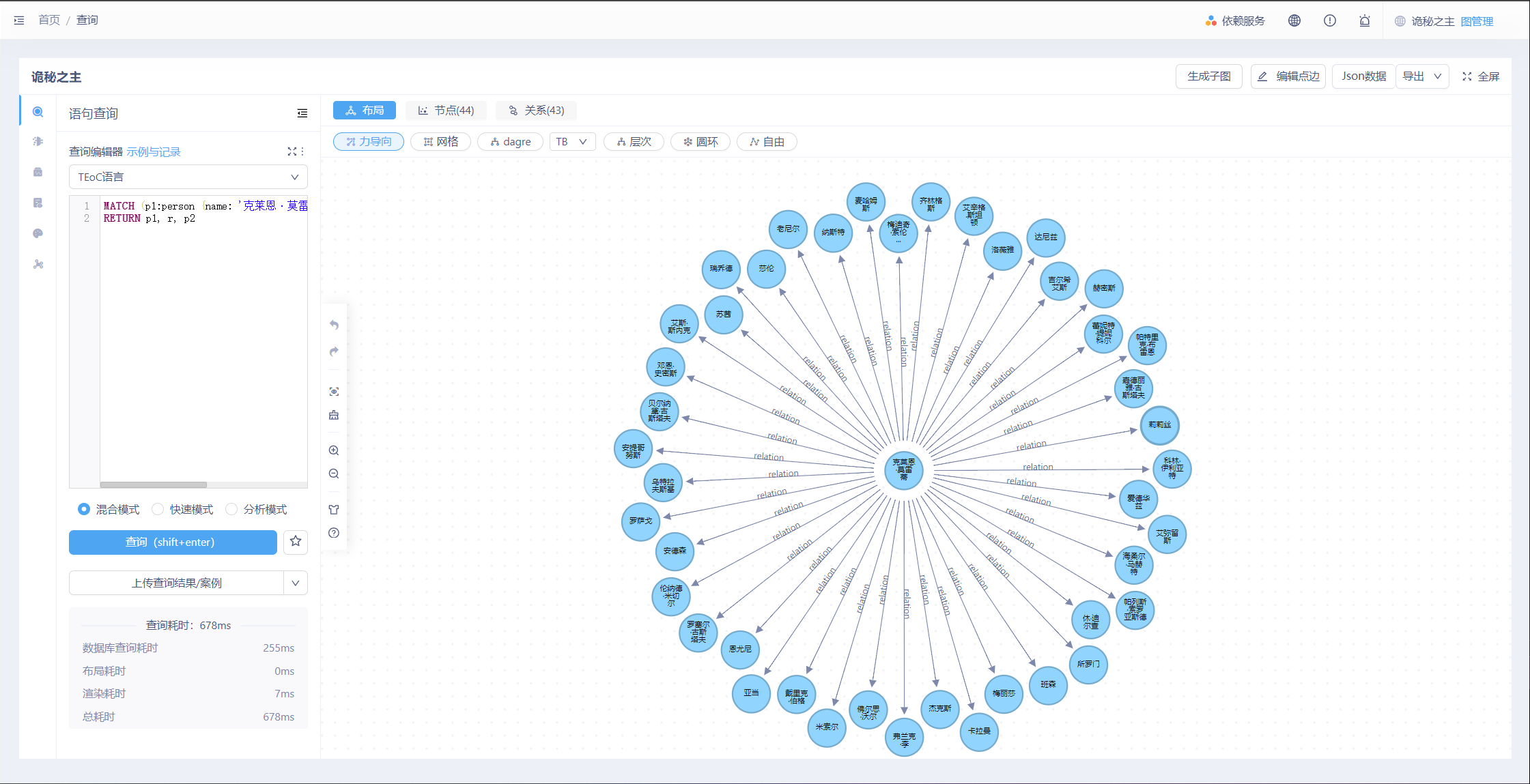
- 根据属性重叠进行查询
查询与“克莱恩·莫雷蒂”具有伙伴关系,并同时与“让·马丹”为“敌对”关系的角色,并展示边。
参考下方命令:
MATCH (p1:person)-[r1:relation {关系: '伙伴'}]->(common:person)<-[r2:relation {关系: '敌对'}]-(p2:person)
WHERE p1.name = '克莱恩·莫雷蒂' AND p2.name = '让·马丹'
RETURN common,r1,r2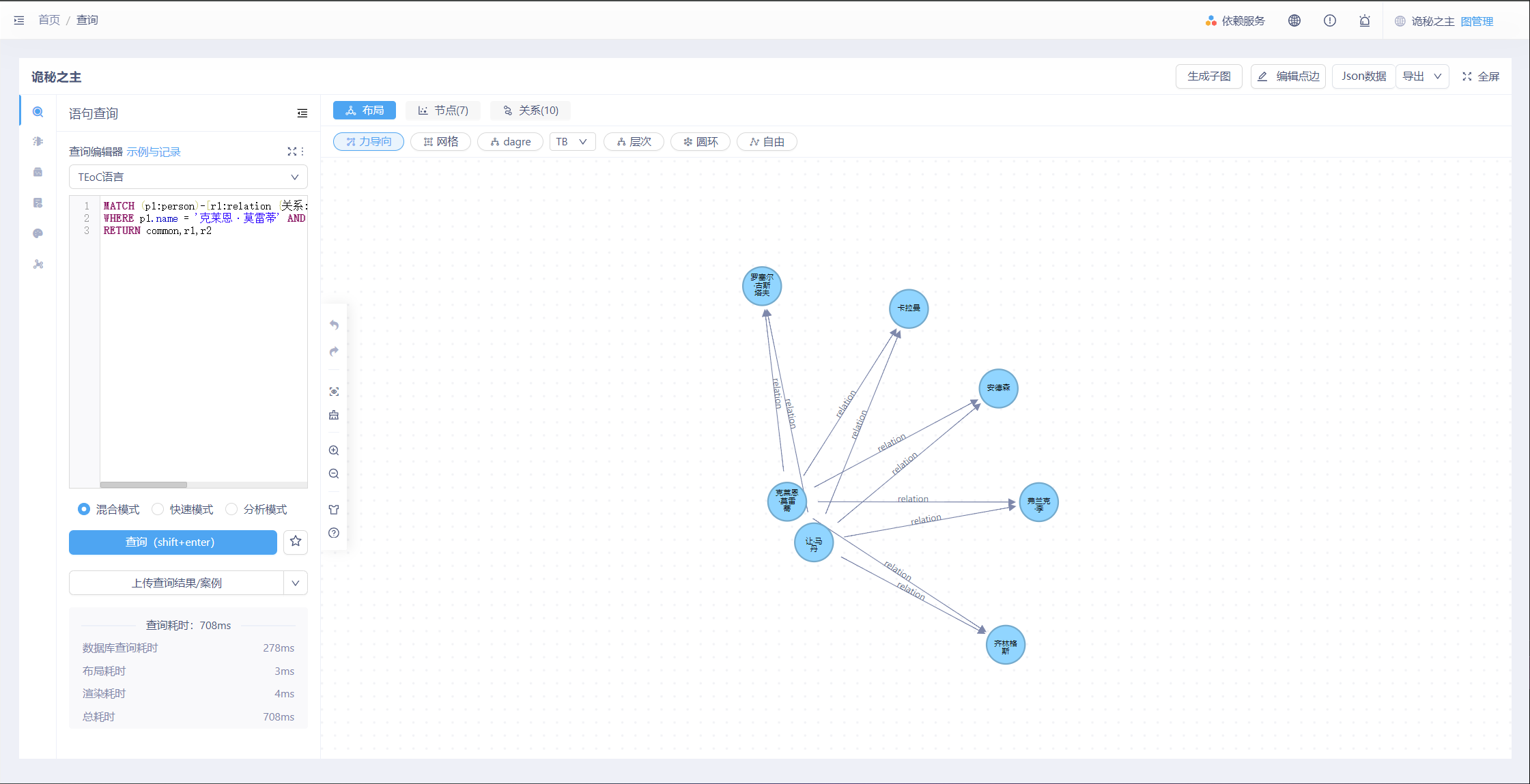
- 有向关联查询
查询10个与“戴里克·伯格”点具有2层有向关联点的名字。
参考下方命令:
MATCH (a:person {
name: "戴里克·伯格"
})-[ ]->()<-[ ]-(b :person)
RETURN b.name
LIMIT 10;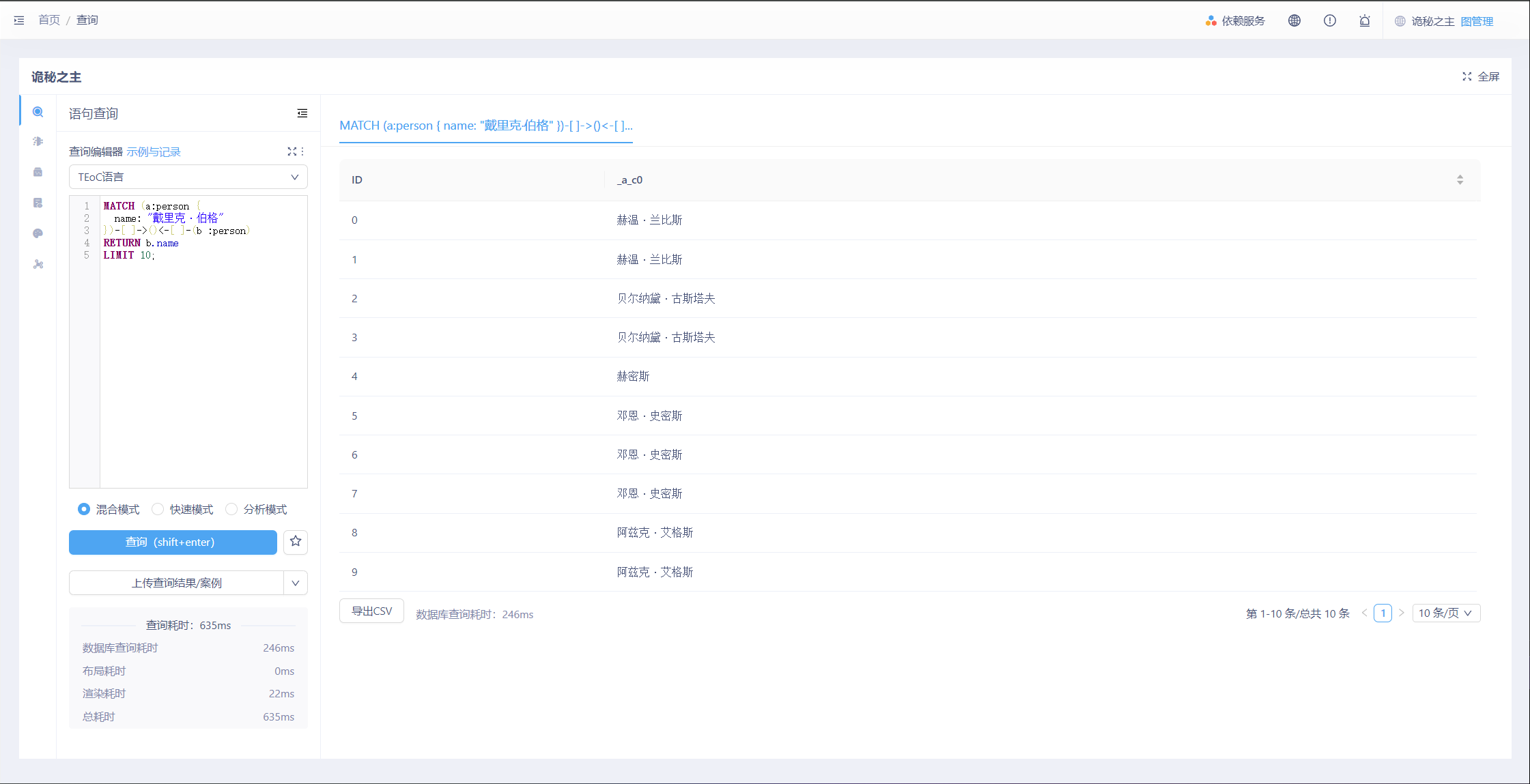
2. 过滤查询功能查询
同样,我们可以使用左侧工具栏中的:过滤查询功能,进行可视化的查询操作。
查询名字为“戴里克·伯格”的点,在节点过滤中将过滤条件设置为person,将name属性的值设定为“戴里克·伯格”。点击查询,便可以出现对应的点。右键点击“展开节点”便可以看到所有与其存在关系的人物。
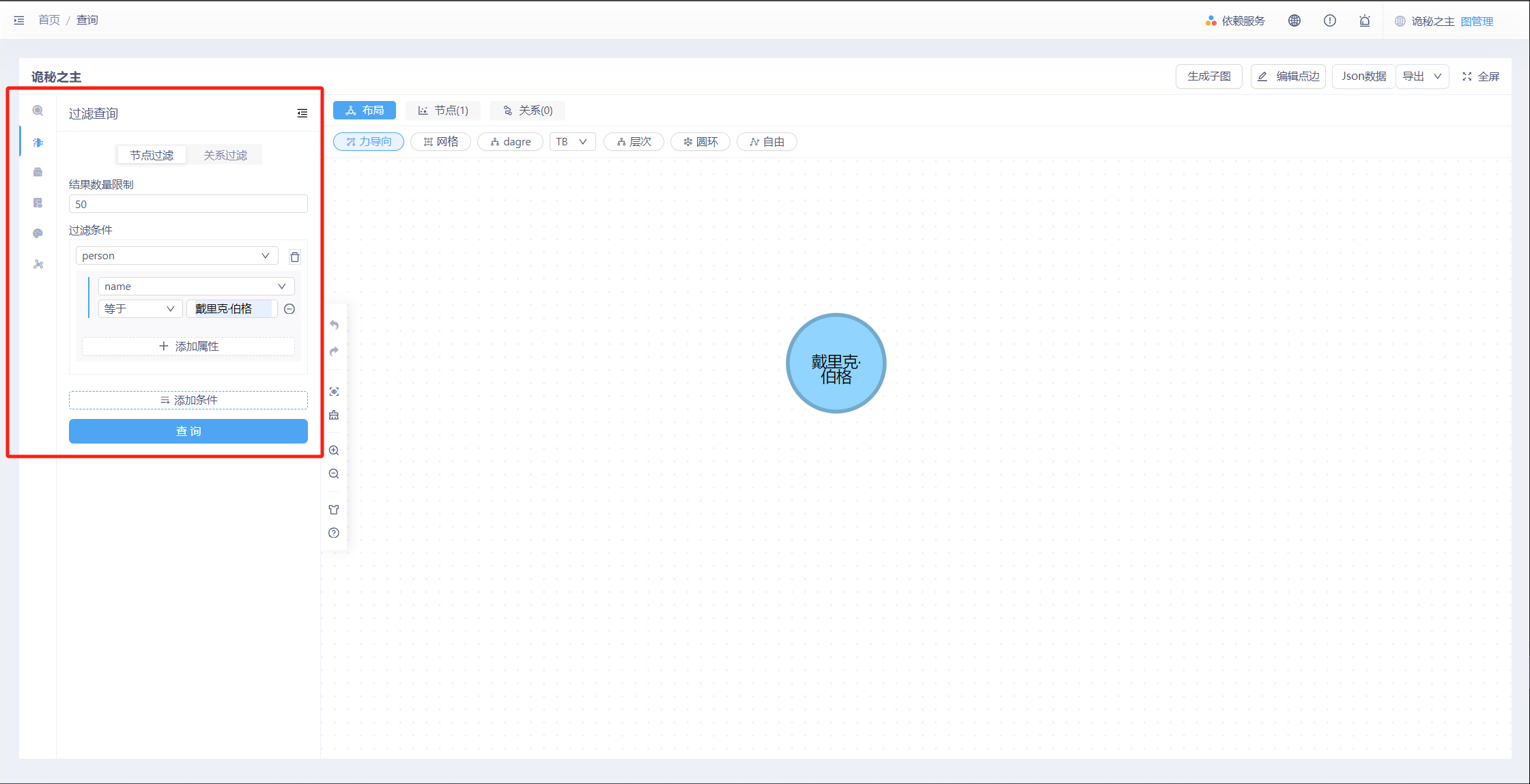
然后,我们进行更佳精准的查询,查询以“戴里克·伯格”为起点uid,并与其为“伙伴”关系的人物角色。如下图所示,在“关系过滤”中,设定对应的过滤条件便可以实现。

五、 结果查看与导出
1. Json数据查看
查询完成后,我们可以查看Json数据,点击页面右上角可以看到:

2. 数据结果导出
在数据查询结束后,您可以根据需要导出PNG文件、CSV文件、查询结果以及原始案例文件。
相关链接:数据集来源为中文开放知识图谱http://data.openkg.cn/dataset/lord-of-the-mysteries
TDH社区版本次发布StellarDB社区版开发版,让更多用户地低资源成本上手体验企业级图数据库。如果您感兴趣的话,可以访问星环官网进行产品下载,StellarDB社区开发版是免费提供给大家的,欢迎大家下载使用。
StellarDB社区开发版相关链接
操作前提
您需要先基于安装手册完成StellarDB图数据库的安装后才可以开始进行下方操作。
一、 描述场景
在本次数据分析项目中,我们将借助知识图谱探索工具KG Explorer深入剖析西方玄幻小说《诡秘之主》中的人物关系网络。通过精细化挖掘角色间的错综关联,掲示那些潜藏于文字背后的微妙线索,这一过程可以为读者和研究者提供洞见,助力预测和解析小说情节未来发展趋势。
二、 数据集介绍
数据集结构:
节点:person
边:relation
数据集获取:
三、 创建图谱并导入数据
1. 创建图谱(schema)
进入KG Explorer后,点击右上角“创建图”按钮,填写图名称后点击“开始创建”进入图谱编辑页面。
注意:StellarDB社区开发版创建图时,副本数只能为1。
2. 定义图谱
- 添加节点
添加节点:按alt/command+左键单击。在画布中添加节点后,将节点的“label”定义为“person”,并为其添加“name”属性,属性类型为“STRING”。添加完成后点击“保存”。
- 添加关系
添加关系:按住shift键同时选中两个节点完成关系添加。本数据集中仅涉及一种节点,此处可按住shift键同时双击节点即可。将边的“label”定义为“relation”,为其添加“关系”属性,属性类型设定为“STRING”。添加完成后点击“保存”。
此时,图谱已经构建完成,点击右上角“发布”后,便可导入数据进行人物关系分析。
3. 导入数据
注意:在上传文件之前,需要提前对‘hive’用户进行赋权,否则上传时将报错。操作方式有两种,推荐使用Guardian赋权的方式解决。
1. 在Guardian服务界面点击 ‘一键开启集群安全’,对hive用户赋予HDFS的 ‘/’ 目录可读可写可执行的权限。(推荐操作)
2. 未开启Guardian时,在服务端初始化客户端后,执行如下命令:
export HADOOP_USER_NAME=hdfs
hdfs dfs -chmod -R 777 /
- 数据集上传
在图管理页面找到刚刚创建的图谱,点击“导数”进入数据导入页面
在“数据导入”页面中选择“文件管理”,点击“上传文件”后,选中您刚刚下载的csv文件,将其上传至KG。上传成功后可以看到数据源文件列表中有对应的文件显示。
然后,返回csv导数页面,按照如下顺序,依次点击选中目标数据集。注意:由于人物信息与关系信息集中于一个文件中,此处需添加3次数据源(即点击“添加”按钮3次),然后将添加文件分别将“点/边”设定为“点”、“点”、“边”。如下图所示:
- 配置属性映射
步骤一:对两个点数据进行配置。具体映射配置为:
第一个点数据对应点的uid对应列为‘col0’,label映射为‘person’,映射列名/常量为‘col0’;
第二个点数据对应点的uid对应列为‘name2’,label映射为‘person’,映射列名/常量为‘name2’。
可参照下图进行配置:
步骤二:对边数据进行配置。具体映射配置为:
边label映射为 ‘relation’、起点uid对应列为 ‘col0’、起点label映射为 ‘person’、终点uid对应列为 ‘name2’、终点label映射为 ‘person’,此外,属性映射中的映射列名/常量为 ‘relation’。
配置完成后,点击右下角“导入”,等待数秒钟后,即可完成数据导入。
导入完成后,可以查看导入状态,并点击导入状态栏中的标识查看数据导入详情(确保失效数据数目为‘0’),确定导入成功后可以进行数据查询分析。
四、 人物关系查询
接下来,我们共同探索小说中多个关键人物的关系。在图管理页面中点击“诡秘之主”的“图探索”按钮,便可以探寻人物之间的关系。
1. 命令行快速查询
KG Explorer支持您使用 TEoC语言与SQL语言进行查询
(1) 默认语句查询
首先进入图数据查询画布,我们点击右侧查询按钮,使用默认语句查询查找所有相连的节点对以及它们之间关系的信息,并且只返回最先找到的10条记录。可以看到“A先生”与其他人物的关系,此时您可以点击节点或者边查看其基础信息与相关属性。
MATCH (n)-[f]-(m)
RETURN n, m, f
LIMIT 10
此时我们看到小说的主人公之一“克莱恩·莫雷蒂”也在其中,我们将其设定为橙色,并单击右键选择“展开节点”,此时可以看到所有与克莱恩·莫雷蒂存在关系的人物,并可以查看边来确定他们之间的关系。
我们将“A先生”隐藏,然后选中“奥黛丽·霍尔”将其变更为红色,重复“展开节点”操作,可以看克莱恩·莫雷蒂与奥黛丽·霍尔共同存有关系的人物角色,以及奥黛丽·霍尔单独存有关系的角色。
(2) 进阶命令查询信息
- 根据点的属性进行查询
查询名字为“克莱恩·莫雷蒂”、“阿兹克·艾格斯”、“让·马丹”、“奥黛丽·霍尔”的点。
参考下方命令:
MATCH (p:person)
WHERE p.name IN ['克莱恩·莫雷蒂', '阿兹克·艾格斯', '让·马丹', '奥黛丽·霍尔']
RETURN p
- 根据关系的属性进行查询
查询与“克莱恩·莫雷蒂”有“伙伴”关系的点,并展示边。
参考下方命令:
MATCH (p1:person {name: '克莱恩·莫雷蒂'})-[r:relation {关系: '伙伴'}]->(p2:person)
RETURN p1, r, p2
- 根据属性重叠进行查询
查询与“克莱恩·莫雷蒂”具有伙伴关系,并同时与“让·马丹”为“敌对”关系的角色,并展示边。
参考下方命令:
MATCH (p1:person)-[r1:relation {关系: '伙伴'}]->(common:person)<-[r2:relation {关系: '敌对'}]-(p2:person)
WHERE p1.name = '克莱恩·莫雷蒂' AND p2.name = '让·马丹'
RETURN common,r1,r2
- 有向关联查询
查询10个与“戴里克·伯格”点具有2层有向关联点的名字。
参考下方命令:
MATCH (a:person {
name: "戴里克·伯格"
})-[ ]->()<-[ ]-(b :person)
RETURN b.name
LIMIT 10;
2. 过滤查询功能查询
同样,我们可以使用左侧工具栏中的:过滤查询功能,进行可视化的查询操作。
查询名字为“戴里克·伯格”的点,在节点过滤中将过滤条件设置为person,将name属性的值设定为“戴里克·伯格”。点击查询,便可以出现对应的点。右键点击“展开节点”便可以看到所有与其存在关系的人物。
然后,我们进行更佳精准的查询,查询以“戴里克·伯格”为起点uid,并与其为“伙伴”关系的人物角色。如下图所示,在“关系过滤”中,设定对应的过滤条件便可以实现。
五、 结果查看与导出
1. Json数据查看
查询完成后,我们可以查看Json数据,点击页面右上角可以看到:
2. 数据结果导出
在数据查询结束后,您可以根据需要导出PNG文件、CSV文件、查询结果以及原始案例文件。
相关链接:数据集来源为中文开放知识图谱http://data.openkg.cn/dataset/lord-of-the-mysteries
 登录后可评论
登录后可评论
热门问答









.jpg)



