【数据处理效率提升实践】ArgoDB如何助力企业全面实现数据处理效率最大化?
友情链接:
- 【最新案例】ArgoDB新功能之读写分离,助力某医药集团打造高效数据中心,消除传统方案的灵活性限制,确保响应时间的可预测性
- 【指标查询调优实践案例】ArgoDB助力某银行实现性能全面提升
- 【CDH国产化替代案例】全面简化架构,降低成本,大幅提升数据处理效率
背景介绍
ArgoDB 是星环自主研发的分布式分析型数据库,可以替代 Hadoop + MPP 的混合架构。我们使用标准的 SQL 语法支持用户业务的建设,并且能够给用户提供多模型数据分析、实时数据处理、存储与计算模块解耦、异构服务器混合部署等先进技术能力。用户可以通过一个 ArgoDB 数据库,实现其数据仓库业务、实时数据仓库业务、数据集市业务、OLAP 数据分析业务、事务型分析型业务混合负载业务、异构数据联邦分析计算业务等各种场景的建设需求。
产品介绍:ArgoDB官方文档站
本篇文章将以星环某医药集团客户为例,为读者从三个方面介绍ArgoDB是如何全面实现数据处理性能大幅提升:
- 通过查询入口层(Gateway)的结果集动态缓存,实现了百并发 50 毫秒的极速响应;
功能具体介绍: 结果集缓存
- 全新的物化视图 2.0 突破了传统方案的语法限制和 MBO 改写限制,为复杂查询提供了更快、更精准的加速能力。
功能具体介绍: 物化视图2.0
- 在复杂查询场景下,Linac + Localfast 的优化组合将执行效率提升至 26 倍;
功能具体介绍: Linac计算引擎

核心点一 基于 Gateway 缓存加速查询
基础介绍
执行态调优是在完成建表与数据导入后,针对查询性能进行的一系列动态优化过程。此阶段通过不断的分析和尝试,逐步提升查询效率。首先运行查询语句,判断其性能是否满足客户需求;如果未达到预期,则分析性能瓶颈并进行有针对性的优化。优化方法包括调整执行计划、优化查询语句,以及利用 Gateway 缓存机制减少重复查询的影响。反复试跑和优化,直到达到性能目标为止。
下面将为读者介绍基于Gateway的缓存机制是如何进一步提升查询性能的。
什么是Gateway
Quark Gateway 是连接客户端与 Quark 服务的一个中间件,可帮助均衡 Quark 服务的业务流量,便捷实现查询入口的高可用、自定义路由转发和负载均衡能力。
前提条件
ArgoDB 和 Quark Gateway 升级到最新软件版本,并安装最新的补丁(Patch)。
已为 Quark Gateway 对接了一个或多个 Quark 服务,具体操作,见 Quark Gateway 使用手册。
背景介绍
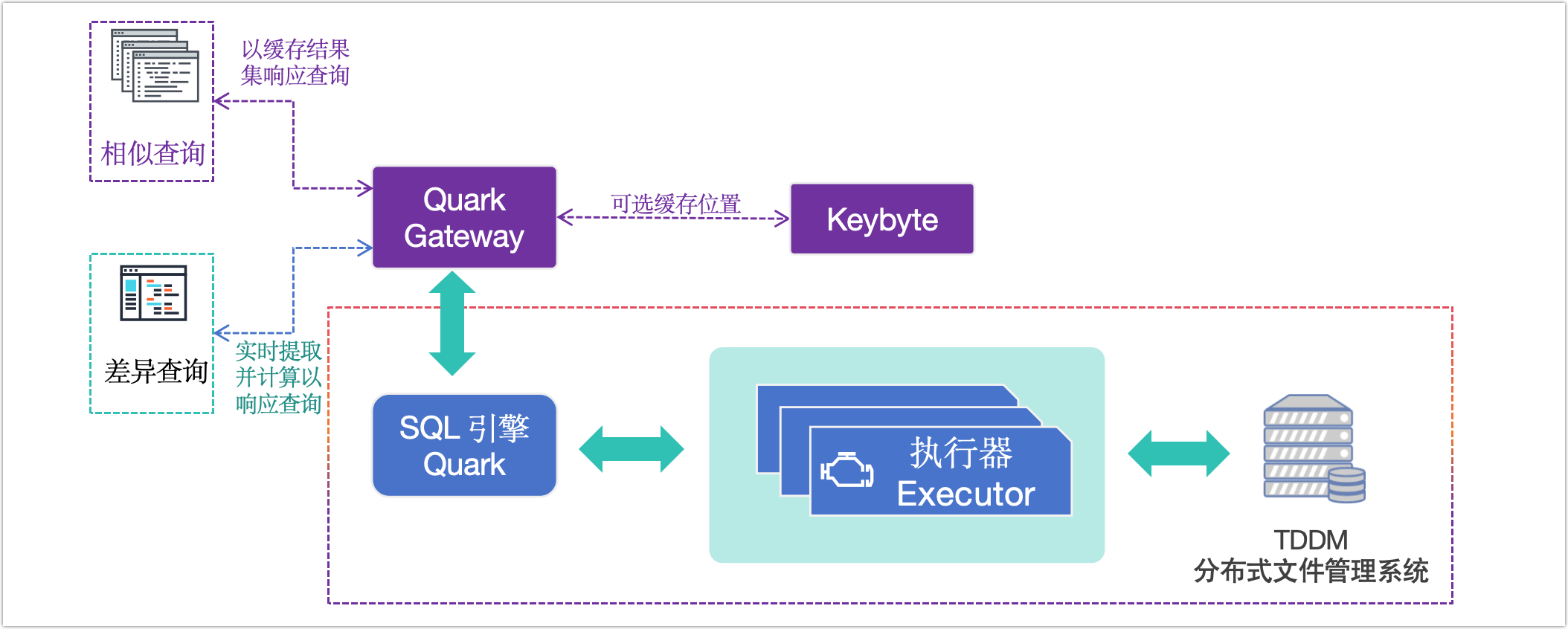
图. Gateway 缓存
为提升查询性能,Quark Gateway 引入了结果集缓存功能,通过缓存常用查询结果,显著减少重复查询对 Quark 服务的影响,加快相同查询的响应速度。此外,Quark Gateway 还提供了 TTL(缓存过期时间)、定时刷新等多种缓存更新策略,您可根据具体任务需求灵活选择最优方案。
- 提升查询效率
对重复或常规的查询请求进行缓存,显著减少数据处理时间,提升查询响应速率。
- 降低系统负担
有效减轻 Quark 服务的处理压力,减少对后端服务的重复查询,系统能够将更多资源集中用于处理更多更复杂的查询请求。
缓存对象说明
Quark Gateway 支持将 Holodesk 表和外部表(如 TEXT 表)的查询结果缓存,从而提升查询性能,适用于绝大多数 SQL 语句。但以下场景由于其 SQL 语义的特性,无法缓存查询结果:
- 非确定性函数:如序列函数、获取当前时间的函数,每次结果不同。
- 临时表:会话结束后自动删除,且其他用户无法访问。
- 系统表:数据变更频繁且规模较小。
- dblink:连接外部数据源,难以监测数据变化,无法确保缓存结果的实时性。
缓存失效机制
为确保缓存数据的实时性与一致性,Quark Gateway 提供了多种策略来管理缓存的自动失效:
- DML 操作感知:当通过 Quark Gateway 执行数据的增删改操作时,系统会自动感知受影响的表,并使与之关联的缓存立即失效。
- DDL 操作感知:执行表结构变更(如创建、删除或修改表结构)时,Quark Gateway 会检测到表的元数据变化,自动使相关表的缓存失效。
- 数据版本监测:实时监测 TDDMS 存储服务的数据版本,一旦检测到数据更新,立即使相关缓存失效。
使用流程
- 登录 Transwarp Manger 平台。
- 在左侧导航栏,选择仪表盘 > 集群。
- 在 Transwarp ArgoDB 区域中,找到并单击 Quark Gateway。
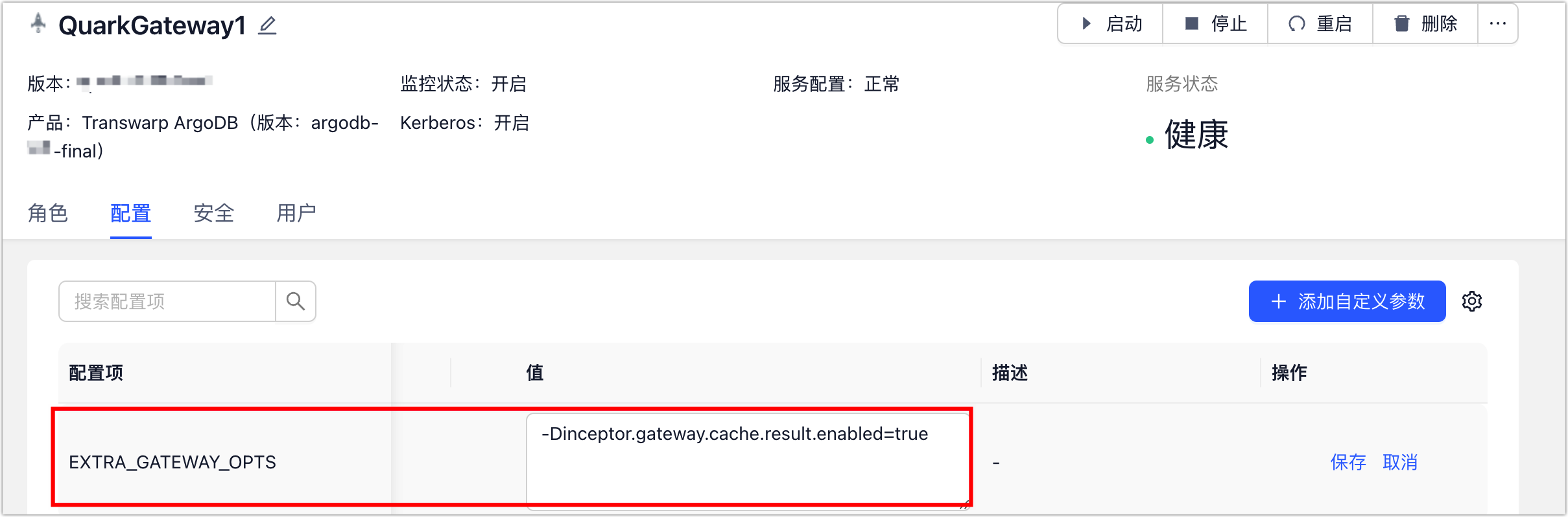
- 单击配置页签,找到 EXTRA_GATEWAY_OPTS 参数并单击其编辑。
填写参数:-Dinceptor.gateway.cache.result.enabled=true,用于开启结果集缓存功能。若需设置多个参数,请用空格分隔。具体参数说明如下:
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.result.enabled | false | 是否开启结果集缓存功能,默认为关闭状态 |
| inceptor.gateway.cache.max.entry.size | 100MB | 一个查询的结果是否被缓存的阈值,如果超过该值,该查询的结果不再被缓存,如果值设置为纯数字(不含单位),则单位为字节 |
| inceptor.gateway.cache.max.memory.usage | 512MB | 缓存结果使用的最大内存,如果值未包含单位,则单位为字节 |
| inceptor.gateway.cache.result.expire.time | 3600 | 缓存有效期,单位为秒 |
| inceptor.gateway.cache.wait.time | 5000 | 单位毫秒,如果多个客户端同时发起同一查询,其中一个会发送到Server 执行,其他的会等待,如果等待时间超过该值,则该查询也被发送到 Server 执行 |
| inceptor.gateway.cache.keywords | 空 | 只缓包含这些关键词的查询的结果 |
参数说明
5. 参考上一步的参数设置方法,开启 TDDMS 数据变化探测功能,保障缓存与原始数据的一致性。
设置案例:-Dinceptor.gateway.cache.tddms.check=true -Dinceptor.gateway.cache.jdbc.url=jdbc:transwarp2://iqa15:8080/default
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.tddms.check | true | 是否开启 Holodesk 表状态探测功能,默认为开启状态 |
| inceptor.gateway.cache.jdbc.url | 无 | 任一 Quark 服务的 JDBC 连接地址,通过该连接,Quark Gateway 可获取到表在 TDDMS 服务上的名称,格式例如 jdbc:transwarp2://<server_ip/hostname>:<port>/<database_name>,更多介绍,见通过 Beeline 命令行连接。 |
| inceptor.gateway.cache.jdbc.username | 无 | 用户名,开启 LDAP 认证时需填写 |
| inceptor.gateway.cache.jdbc.password | 无 | 用户密码,开启 LDAP 认证时需填写 |
| inceptor.gateway.meta.cache.expire.time | 30000 | 元数据信息的过期时间,单位为毫秒 |
参数说明
为更好地匹配您的业务需求,您可以通过设置更多参数来控制缓存行为,例如缓存存储位置、黑名单等,更多介绍,见后文的管理缓存章节。
6. 保存设置后,单击页面右上角的配置服务来下发修改的配置。
7. 在业务低峰期,单击页面右上角的重启,配置将正式生效。
8. (可选)连接 Quark Gateway 并执行 SQL 查询后,可通过调用下述接口来查看缓存命中情况。
# 执行时需要替换真实的 Quark Gateway 服务地址
curl -X GET http://{Quark Gateway 服务地址}:6066/v1/resultcache执行示例:
curl -X GET http://iqa15:6066/v1/resultcache |jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 44 0 44 0 0 816 0 --:--:-- --:--:-- --:--:-- 830
{
"cacheCout": 1,
"hintCount": 1,
"enabled": true
}管理缓存
默认的参数值可满足绝大多数的业务场景,同时,Quark Gateway 还支持基于业务需求调整参数,例如设置缓存清理规则、管理黑名单等,从而更好匹配复杂的业务需求。
管理缓存生命周期
为避免闲置缓存占用内存,Quark Gateway 提供缓存清理功能,您可以通过下述参数控制缓存清理/更新策略,确保数据的有效性并节省内存空间。
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.ttl.autocheck.enable | true | 是否开启缓存自动清理功能,默认为开启状态 |
| inceptor.gateway.cache.ttl.autocheck.time | inceptor.gateway.cache.result.expire.time * 1.5 | 默认ttl即扫描时间间隔为1.5倍的缓存有效时间,单位秒。非特殊需求不必修改该值。 |
| inceptor.gateway.cache.schedule.clean.enable | false | 是否定期清空所有缓存数据 |
| inceptor.gateway.cache.schedule.clean.cron | 0 1 0 * * ? | 缓存清理任务默认为每天凌晨 0 点执行,适用于源表定时更新的场景(如 T+1 场景),可通过 cron 表达式进行配置 |
参数说明
管理黑名单
当查询的结果超出 inceptor.gateway.cache.max.entry.size 的值,Quark Gateway 会自动将其加入黑名单,黑名单中的 SQL 不会尝试建立缓存,您可以通过下述参数控制黑名单行为:
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.black.list.enable | true | 是否开启缓存黑名单功能 |
| inceptor.gateway.cache.black.list.expire.time | 10800 | 黑名单过期时间,单位为秒,从最后一次加入黑名单时开始计算 |
| inceptor.gateway.cache.black.list.size | 10000 | 黑名单数量上限 |
| inceptor.gateway.cache.black.list.check.time | 86400 | 黑名单定时清理的时间间隔,单位秒 |
参数说明
管理存储位置
默认情况下,Quark Gateway 生成的缓存信息存放在自身内存中,如您的集群安装了星环键值数据库 Transwarp KeyByte,您还可以选择将缓存数据对接至该服务,进一步提升管理便捷性和资源利用率。
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.storage.use.keybyte | false | 是否将缓存信息存储在 KeyByte 服务中 |
| inceptor.gateway.cache.keybyte.ip | 0.0.0.0 | KeyByte 服务的 IP 地址 |
| inceptor.gateway.cache.keybyte.port | 6399 | KeyByte 的服务端口 |
| inceptor.gateway.cache.keybyte.password | 空 | KeyByte 的连接密码 |
| inceptor.gateway.cache.keybyte.max.total | 200 | KeyByte 连接池的最大连接 |
| inceptor.gateway.cache.keybyte.max.idle | 20 | KeyByte 连接池的最大空闲连接 |
| inceptor.gateway.cache.keybyte.min.idle | 1 | KeyByte 连接池的最小空闲连接 |
| inceptor.gateway.cache.storage.keybyte.time.threshold.enabled | false | 当缓存超过时间阈值,是否将其从内存转为 Keybyte 存储 |
| inceptor.gateway.cache.storage.keybyte.time.threshold | 60 | 缓存超时阈值,单位为秒 |
| inceptor.gateway.cache.storage.keybyte.size.threshold.enabled | false | 当缓存超过大小阈值,是否将其从内存存储转为 Keybyte 存储 |
| inceptor.gateway.cache.storage.keybyte.size.threshold | inceptor.gateway.cache.max.entry.size / 1000 | 缓存大小阈值,如果值设置为纯数字(不含单位),则单位为字节 |
核心点二 全新物化视图2.0
物化视图VS.传统视图
视图(VIEW)用于保存复杂的 SQL 查询,以便简化后续操作,但其本质仍是执行保存的 SQL 语句,因此无法提升查询性能。为了解决这一问题,ArgoDB 推出了物化视图 2.0,突破了传统物化视图的 MBO 改写限制和对复杂语法支持有限的问题,显著提高数据同步效率,为您提供更快速、更精准的数据查询加速能力。
| 对比项 | 物化视图 2.0 | 传统物化视图 |
|---|---|---|
| 创建支持 | 无限制 | 创建语法受限 |
| 语法支持 | 无限制 | 仅简单语法 |
| 查询原理 | 基于视图查询,系统自动替换为关联的物化表 | 基于源表查询,系统基于 MBO 改写 |
| 更新原理 | 基于源表最新数据创建新物化表并自动关联,随后删除旧物化表 | 原地更新(清空表+写入新数据) |
| 结果集匹配 | 在编译前匹配视图的结果集与其对应的物化表 | 在执行计划阶段匹配 SQL 查询语句的结果集与物化视图 |
| 数据过期表现 | 不会读到过期数据(自动转查基表) | 可能会读到过期数据 |
语法介绍
使用下述语法创建物化视图 2.0,系统将会自动执行相关 SQL 并将其结果集关联至一个不可见的物理表,后续对该视图执行查询时,系统将在将执行编译前自动转换查询对象为其关联的物化表,无需再执行原 SQL 中的复杂查询,从而极大加速查询效率。
物化视图 2.0 仍然是普通视图,支持执行常规的视图操作,如替换定义、修改、删除等操作。
注意事项
由于每次数据变更可能触发物化表重建,源表频繁更新时,可能会有多个未删除的过期物化表副本。
语法格式
CREATE VIEW [IF NOT EXISTS] <view_name>
[<column_name1> COMMENT "<column_text>", ...]
WITH MATERIALIZED
[COMMENT "<view_text>"]
[REFRESH IMMEDIATE|DEFERRED ON (<source_table1>, <source_table2>, ...)]
[ON (<table_name>, ...)]]
[PARTITIONED ON (<partition_key>, ...)]
[CLUSTERED BY (<bucket_key>, ...)]
[SORTED BY (<sort_key> [ASC | DESC], ...)]
[INTO <num_buckets> BUCKETS]
[STORED AS HOLODESK]
[WITH TABLESIZE <table_size>KB|MB|GB|TB|PB|EB|ZB|BB [REPLICATION <replication_num>]]
[TBLPROPERTIES ('<property_name>'='<property_value>', ...)]
AS SELECT <select_statement>;参数说明
- <view_name>:视图名称,通过可选项 IF NOT EXISTS 可在创建视图前检测是否已存在同名视图。
- <column_name>:视图中的字段列名称。
- <column_text>:列注释,支持对视图查询的结果字段定义列名称、注释。
- <view_text>:视图注释,支持使用 COMMENT 为视图加注释,注意注释要放在引号中。
- IMMEDIATE|DEFERRED:定义的数据更新机制,更多介绍,见更新物化视图。
- <table_source>:更新视图绑定的物化表时,指定更新依赖的源表名称。
- <partition_key>:指定视图绑定的物化表的分区列名称,支持单值分区表,分区字段必须出现在查询子句 <select_statement> 中,且位于字段列表最末尾。
- <bucket_key>:指定视图绑定的物化表的分桶列名称。
- <sort_key>:指定视图绑定的物化表的分桶排序列名称,默认为升序排序,可以支持指定 DESC 表示降序,ASC 表示升序。
- <num_buckets>:指定视图绑定的物化表的分桶数。
- <property_name>:视图绑定的物化表属性名称。
- <table_storage_format>:支持使用 STORED AS 指定表的存储格式。
- <table_size>:当选择物化为 Holodesk 表时,支持设置表大小,或者可以通过参数 hive.materializedview.holodesk.default.table.size 设置,默认为 11GB
- <replication_num>:表的副本数。
- <property_value>:视图绑定的物化表属性值。
示例
假设我们有一个名为 orders 的表,该表包含订单相关信息,包括 order_id、customer_id、order_amount、order_date 和 customer_region 等字段。
现在我们创建一个名为 new_mv 的物化视图,该物化视图将包含在 2023 年内北美地区消费总额超过 1000 的客户信息,并显示每个客户的总消费、订单数量和平均订单金额,按总消费金额从高到低排序,便于快速识别高价值客户群体。
CREATE VIEW new_mv with MATERIALIZED AS
SELECT
customer_id,
SUM(order_amount) AS total_spent,
COUNT(order_id) AS total_orders,
AVG(order_amount) AS avg_order_value
FROM
orders
WHERE
order_date BETWEEN '2023-01-01' AND '2023-12-31'
AND customer_region = 'North America'
GROUP BY
customer_id
HAVING
SUM(order_amount) > 1000
ORDER BY
total_spent DESC;更新物化表
当视图查询的源表变更时(如 INSERT),默认情况下视图关联的结果集物化表会过期,此时执行 SQL 查询视图时将不会进行替换加速。
为避免物化表结果过期,您可以选择设置更新策略并开启自动更新,工作原理如下:
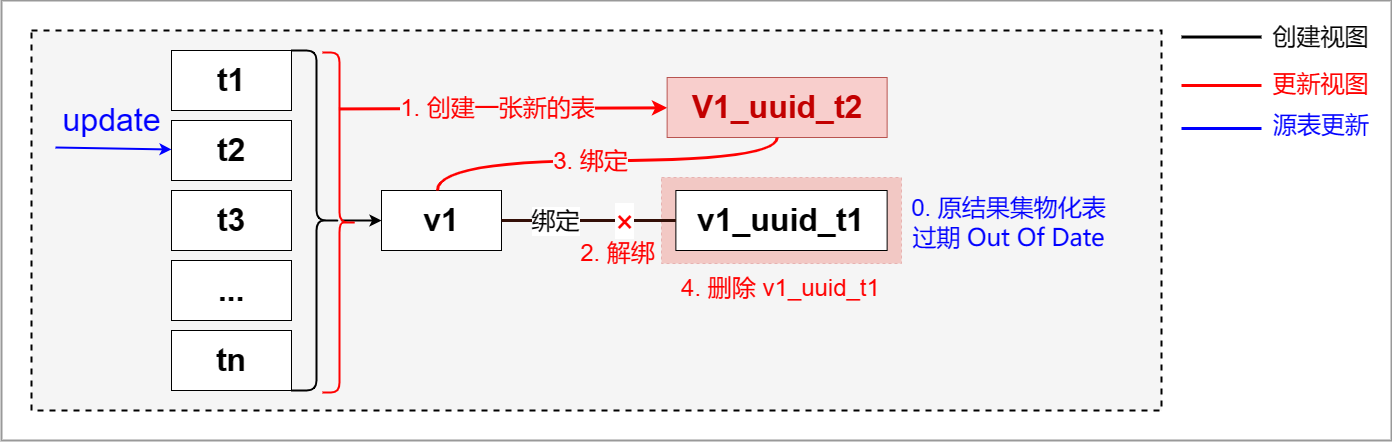
图. 更新数据
操作流程
1. 开启自动更新模式,当源表数据产生更新时,视图关联的物化表会自动触发更新。
set quark.mbo.rebuild.auto=true;当视图绑定的结果集物化表在开启自动更新参数之前已经过期时,系统将不会执行自动更新任务。此时,必须通过手动更新的方式强制执行重建。
2. (可选)通过 ALTER VIEW REBUILD 手动更新物化表,示例如下:
ALTER VIEW <view_name> REBUILD;此外,您还可以执行 set quark.mbo.force.rebuild = true; 命令,配合上述命令实现强制更新。
3. (可选)默认情况下,源表数据更新时立即同步更新物化表,如需调整更新策略,可执行下述格式的命令进行设置。
ALTER VIEW <view_name> REFRESH IMMEDIATE|DEFERRED -- [1]
[ON (<source_table1>, <source_table2>, ...)]; -- [2]- 设置更新策略:
-- IMMEDIATE(默认):在源表数据更新时立即同步更新物化表。
-- DEFERRED:在查询时才更新物化表。建议在源表存在字段增删操作时使用 DEFERRED 模式,以避免频繁重建物化表。
- 设置监听源表:
-- 默认监听所有源表的更新,您也可以通过 ON (<source_table1>, <source_table2>, …) 指定更新依赖源表,例如在流水表和维表的关联查询场景中,只监听流水表的更新,避免因维表变更触发无效的物化表更新,从而提升更新效率。
开启查询加速
1. 登录 Manager 平台,单击 Quark 服务。
2. 单击配置页签,添加自定义参数,将 Quark 参数 quark.view.materialized.rewrite.enable 设置为 true,以启用视图查询自动重写功能,利用其物化表实现查询加速。
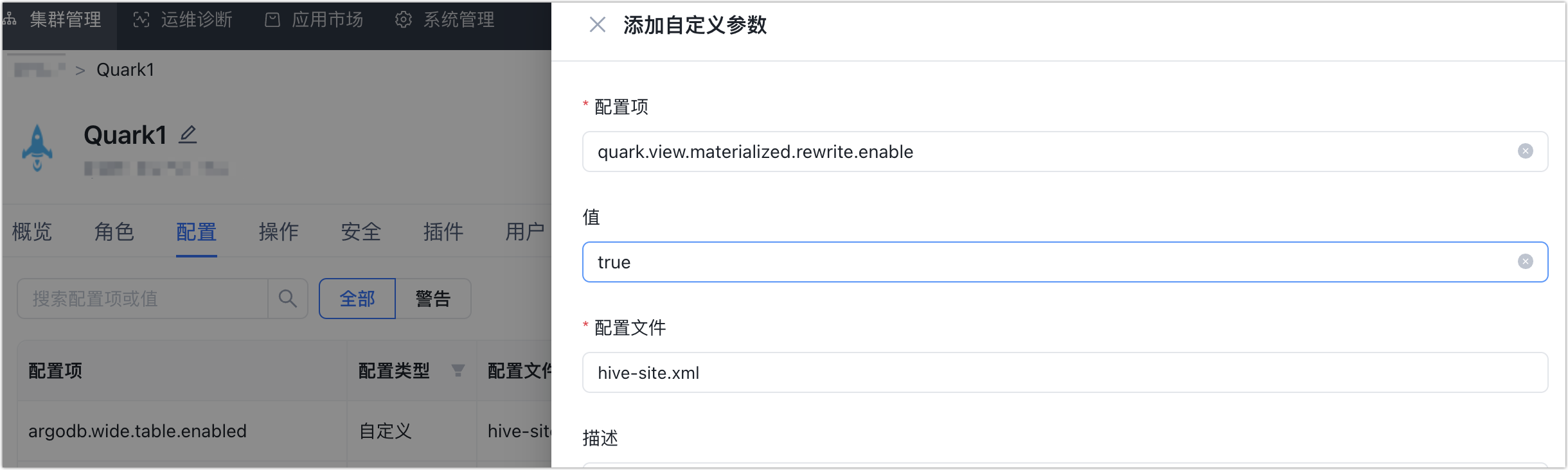
图. 启用视图自动重写
您也可以通过执行 set quark.view.materialized.rewrite.enable=true 命令,使该设置在当前会话中生效。
3. 通过 DESC FORMATTED new_mv 命令,查看我们在前面创建的物化视图 new_mv 及关联的物化表,查询结果如下,关键字为 materialized_table 对应的值。
-- 省略部分内容
| last_modified_by | admin |
| last_modified_time | 1726737832 |
| materialized_table | demodata.new_mv_deec066d |
| transient_lastDdlTime | 1726737832 |
| ...... | ...... |您还可以执行 DESC FORMATTED <物化表> 命令查看物化表的属性,通过 View Out Of Date 属性的值判断该物化表是否过期(即值为 YES)。
4. 使用 PLANT 命令打印 SQL 查询语法树,检查 TOK_TABNAME 是否为视图绑定的物化表名称,如果是,则表示查询已成功替换为物化表查询,实现了加速效果。
-- 将查询视图自动转换为查询该视图绑定的集物化表
set quark.view.materialized.rewrite.enable = true;
-- 执行 PLANT 命令
PLANT select * from new_mv;
-- 查询结果,省略部分内容
| (TOK_QUERY |
| (TOK_FROM |
| (TOK_TABREF |
| (TOK_TABNAME |
| (demodata) |
| (new_mv_deec066d))) |
| (new_mv_aa2fb850))) |
| (TOK_INSERT |
| (TOK_DESTINATION |
| (TOK_DIR |
| (TOK_TMP_FILE))) |
| (TOK_SELECT |
| (TOK_SELEXPR |
| (TOK_ALLCOLREF))))) |
| |
+----------------------------------------------------+参数调优
| 参数 | 默认值 | 说明 |
|---|---|---|
| quark.mbo.rebuild.auto | false | 控制是否自动更新结果集缓存表和物化视图,建议全局设置。设为 true 后,当源表数据更新,自动即时更新重建。 |
| quark.mbo.rebuild.delay.time | 0 | 更新延迟时间,允许过去一段时间内更新过的物化视图或结果集表不触发更新,单位为秒(s)。 |
| quark.mbo.force.rebuild | false | 执行 alter [MATERIALIZED] view rebuild 语句时不关心视图状态强制更新 |
| hive.materializedview.fileformat | ORC | 指定结果集缓存的表类型,即视图持久化数据时采用的存储格式,取值包含:none、HOLODESK、TextFile、equenceFile、RCfile、ORC、HYPERDRIVE。设置本参数自定义存储格式时,需设置该存储格式对应的 Serde 类型参数当设为 HOLODESK 时,可通过设置参数 holodesk.default.storage.format 控制为普通表(normal)或性能表(performance) |
| hive.materializedview.serde | 见描述 | 当需要自定义持久化存储类型时,设置本参数指定对应的 Serde 的类型 。默认为 org.apache.hadoop.hive.ql.io.orc.OrcSerde 为 ORC 格式对应的 Serde。 |
| quark.view.materialized.rewrite.enable | false | 【物化视图 2.0 相关参数】控制是否在查询视图时,自动替换为查询关联的结果集物化表,开启此参数可以有效提高查询视图的性能,建议全局设置。 |
| quark.show.hidden.materialized.table | false | 【物化视图 2.0 相关参数】控制是否显示数据库下基于物化视图 2.0 建立的物化表,默认不显示,即 SHOW TABLES 不展示物化表。 |
| quark.view.materialized.refresh.time | 0 | 【物化视图 2.0 相关参数】用于设置查询视图时能否替换为查询管理的物化表。设为 -1 时,允许查询视图时使用过期物化表进行替换 |
核心点三 创新的Linac引擎
ArgoDB 是一款创新型分布式数据库,旨在为用户提供超大规模的数据处理能力、高效的性能表现、稳定的运行环境以及极简的使用体验。广泛应用于 Teradata、Oracle、CDH 等产品的替换场景中,成为众多企业的首选解决方案。为进一步提升计算效率和性能稳定性,ArgoDB 6.0 正式推出了基于 C++ 语言实现的高性能 Linac 计算引擎。
Linac 介绍
优势
Linac 引擎目前已经在多个用户生产中落地应用,实现了对 Impala、Oracle、Inceptor 业务的改造和上线,能实现数倍的性能提升。区别于 ArgoDB 传统 JAVA 引擎,Linac 是基于 C++ 语言改写的高性能计算引擎,对比原 JAVA 引擎有如下优势:
- 兼容适配:支持 Inceptor、Oracle、Teradata 三种语法兼容,提供 Inceptor、Oracle、Teradata、Impala 各引擎的 UDF兼容性。
- 内存管理:Linac 引擎自通过灵活的内存管理方式,任务执行结束后能够迅速释放占用的内存资源,缓解多进程高负载集群的内存压力。
- 性能领先:大幅度提升算子性能,针对存储引擎和数据存储格式进行改造,同时优化了执行计划、任务调度、算子识别等场景。保证了任务提交后不回退,以及性能稳定提升。
Linac 引擎已经实现常见算子的本地化,且实现了算子的性能提升,其中性能提升最大的如下:
- Group by:性能提升接近10倍,聚合率越高(Pre-Group by 效果好),性能提升越大
- Filter( UDF):在 SQL 中使用了较多 UDF 进行字段的处理和聚合时,性能有超过10倍的提升
- Join:对于所有 Join 类型,性能都有很大幅度的提升,甚至可以依靠 Linac 强行计算出数据倾斜的 Cross Join。
对于一些大数据量的 Order By/Sort By/窗口函数(Rand、row_number)等,由于对内存的开销比较大,Linac 在计算时仍会有部分数据落盘以保证稳定性,因此性能提升幅度与数据量及内存配置相关。在使用时,我们一般建议保留足够的堆内内存空间,可以适当地调小堆外的内存。
执行模式
Linac 引擎支持 Cluster、Localfast 和 OLAP 模式,不支持 Local 模式。对应在 DBA Service 中依次显示为 linac-cluster、linac-localfast、linac-olap 三种模式。
使用 Linac 模式时,若为单机本地读场景,建议使用 Localfast 模式,此时您需要同时设置以下参数:
set use.linac=true;
set ngmr.windrunner.enabled=true;
set ngmr.local.fast.enabled=true;SQL 执行模式的更多信息请参考章节:SQL 执行模式
使用 Linac
开启 Linac
Linac 引擎作为 ArgoDB 高性能计算引擎,支持通过参数控制功能的开启
当启动 Linac 引擎总开关 use.linac =true 后,为了保证计算任务能够正常使用 Linac 引擎,且任务逻辑能够自洽,ArgoDB 后台会自动配置以下参数:
set hive.merge.nway.joins = false;
set inceptor.filterjoin.enabled = false;
set windrunner.aggregate.check = false;
set windrunner.nlssort.check = false;
set ngmr.windrunner.nonquery.enabled = true;
set ngmr.windrunner.session.subquery.enabled = true;
set inceptor.winfunc.collapse.optimize = false;
set inceptor.winfunc.transform.enabled = false;
set inceptor.withas.material.fileformat = holodesk_performance;限制条件
Linac 计算引擎针对 Holodesk 列式存储进行计算,可以兼容不同存储格式和 SQL 语法,但仍然存在以下限制边界,当开启 Linac 引擎但遇到不支持的场景时,则会自动回退至 Windrunner 引擎进行执行计算。
- 存储格式
Linac 引擎兼容 Holodesk 列存格式,目前仅支持 Holodesk 性能表、Holodesk 宽表(可支持 1000+ 列的高性能查询),暂不支持其他存储格式,会自动回退至 Windrunner 引擎。
- SQL 查询类型
对于以上支持的存储类型,Linac 引擎执行 SQL 操作时 Linac 的支持情况如下:
- 支持 DML 中的插入、更新、删除数据操作 INSERT/UPDATE/DELETE。但不支持 MERGE INTO,会自动回退至 Windrunnenr 引擎。
- 支持使用 INSERT INTO SELECT 的方式插入数据至非分区分桶 Holodesk 表,和指定分区的单值分区非分桶表。
- 支持 DQL 查询操作 SELECT。
DCL 操作,以及 DDL 操作中的 创建、删除、清空表操作 CREATE/DROP/TRUNCATE TABLE、修改表或字段名称操作 ALTER TABLE/COLUMN RENAME,不调用计算引擎。
功能参数
| 参数名称 | 默认值 | 参数说明 |
|---|---|---|
| use.linac | false | Linac 引擎总开关,设置为 true 后即使用 Linac 引擎,且会开启一系列 Linac 优化参数,具体请参考 Linac 引擎自动优化参数 |
| quark.linac.fail.no.retry | false | 控制 Linac 引擎总的任务重试机制,开启后对性能有一定影响 |
| inceptor.filterjoin.enabled | true | 控制是否开启 FilterJoin 优化。FilterJoin 是基于 MapJoin 的优化,适用于语句中有多个级联 MapJoin 的场景,加快这类语句的执行速度。 |
| hive.merge.nway.joins | true | 控制是否将相邻的 JOIN 连接操作合并为一个多路连接(n-way JOIN)。 |
| inceptor.withas.material.fileformat | AUTO | 设置物化 with-as 表的默认文件格式。可选项为 auto, orc, holodesk, holodesk_performance |
Linac 优化参数
| 参数名称 | 默认值 | 参数说明 |
|---|---|---|
| quark.ignore.linac.error | true | 默认编译时 Linac 不支持的任务会自动回退至 Java 引擎,设置成 false 后,则会产生会报错,适合业务兼容性验证测试时使用 |
| quark.qtrace.enabled | false | 开启后,会在 Quark Server 日志目录生成 Qtrace 日志文件,可以帮助分析每个算子和计算节点的性能开销 |
| inceptor.log.level | warn | 6.0 版本的默认日志级别已经修改为 warn,如果需要查看更细节的日子信息,可将参数设置为 info,如果测试高并发性能,则将参数设置为 error |
业务测试场景参数
| 参数名称 | 默认值 | 参数说明 |
|---|---|---|
| character.literal.as.string | false | ArgoDB 5.x 之后,字符串常量的默认类型为 CHAR(n),此时 '' 等于 NULL。开启此参数后,字符串常量默认类型为 STRING。 |
| inceptor.udf.compatible.with.oracle | false | 开启此参数后,UDF 函数行为将与 Oracle 兼容 |
| plsql.server.dialect | oracle | 支持 PLSQL 的方言,当开启 Linac 模式时不支持 db2 方言。 |
| server.dialect.parser.oracle | false | 设置是否在编译阶段使用 Oracle 方言,用于多方言存储保证解析行为的统一性 |
| linac.udf.compatible.mode | quark | 设置 Linac 模式下,UDF 函数的兼容模式,可选项有 quark,oracle,impala,td |
兼容性参数
友情链接:
- 【最新案例】ArgoDB新功能之读写分离,助力某医药集团打造高效数据中心,消除传统方案的灵活性限制,确保响应时间的可预测性
- 【指标查询调优实践案例】ArgoDB助力某银行实现性能全面提升
- 【CDH国产化替代案例】全面简化架构,降低成本,大幅提升数据处理效率
背景介绍
ArgoDB 是星环自主研发的分布式分析型数据库,可以替代 Hadoop + MPP 的混合架构。我们使用标准的 SQL 语法支持用户业务的建设,并且能够给用户提供多模型数据分析、实时数据处理、存储与计算模块解耦、异构服务器混合部署等先进技术能力。用户可以通过一个 ArgoDB 数据库,实现其数据仓库业务、实时数据仓库业务、数据集市业务、OLAP 数据分析业务、事务型分析型业务混合负载业务、异构数据联邦分析计算业务等各种场景的建设需求。
产品介绍:ArgoDB官方文档站
本篇文章将以星环某医药集团客户为例,为读者从三个方面介绍ArgoDB是如何全面实现数据处理性能大幅提升:
- 通过查询入口层(Gateway)的结果集动态缓存,实现了百并发 50 毫秒的极速响应;
功能具体介绍: 结果集缓存
- 全新的物化视图 2.0 突破了传统方案的语法限制和 MBO 改写限制,为复杂查询提供了更快、更精准的加速能力。
功能具体介绍: 物化视图2.0
- 在复杂查询场景下,Linac + Localfast 的优化组合将执行效率提升至 26 倍;
功能具体介绍: Linac计算引擎
核心点一 基于 Gateway 缓存加速查询
基础介绍
执行态调优是在完成建表与数据导入后,针对查询性能进行的一系列动态优化过程。此阶段通过不断的分析和尝试,逐步提升查询效率。首先运行查询语句,判断其性能是否满足客户需求;如果未达到预期,则分析性能瓶颈并进行有针对性的优化。优化方法包括调整执行计划、优化查询语句,以及利用 Gateway 缓存机制减少重复查询的影响。反复试跑和优化,直到达到性能目标为止。
下面将为读者介绍基于Gateway的缓存机制是如何进一步提升查询性能的。
什么是Gateway
Quark Gateway 是连接客户端与 Quark 服务的一个中间件,可帮助均衡 Quark 服务的业务流量,便捷实现查询入口的高可用、自定义路由转发和负载均衡能力。
前提条件
ArgoDB 和 Quark Gateway 升级到最新软件版本,并安装最新的补丁(Patch)。
已为 Quark Gateway 对接了一个或多个 Quark 服务,具体操作,见 Quark Gateway 使用手册。
背景介绍
图. Gateway 缓存
为提升查询性能,Quark Gateway 引入了结果集缓存功能,通过缓存常用查询结果,显著减少重复查询对 Quark 服务的影响,加快相同查询的响应速度。此外,Quark Gateway 还提供了 TTL(缓存过期时间)、定时刷新等多种缓存更新策略,您可根据具体任务需求灵活选择最优方案。
- 提升查询效率
对重复或常规的查询请求进行缓存,显著减少数据处理时间,提升查询响应速率。
- 降低系统负担
有效减轻 Quark 服务的处理压力,减少对后端服务的重复查询,系统能够将更多资源集中用于处理更多更复杂的查询请求。
缓存对象说明
Quark Gateway 支持将 Holodesk 表和外部表(如 TEXT 表)的查询结果缓存,从而提升查询性能,适用于绝大多数 SQL 语句。但以下场景由于其 SQL 语义的特性,无法缓存查询结果:
- 非确定性函数:如序列函数、获取当前时间的函数,每次结果不同。
- 临时表:会话结束后自动删除,且其他用户无法访问。
- 系统表:数据变更频繁且规模较小。
- dblink:连接外部数据源,难以监测数据变化,无法确保缓存结果的实时性。
缓存失效机制
为确保缓存数据的实时性与一致性,Quark Gateway 提供了多种策略来管理缓存的自动失效:
- DML 操作感知:当通过 Quark Gateway 执行数据的增删改操作时,系统会自动感知受影响的表,并使与之关联的缓存立即失效。
- DDL 操作感知:执行表结构变更(如创建、删除或修改表结构)时,Quark Gateway 会检测到表的元数据变化,自动使相关表的缓存失效。
- 数据版本监测:实时监测 TDDMS 存储服务的数据版本,一旦检测到数据更新,立即使相关缓存失效。
使用流程
- 登录 Transwarp Manger 平台。
- 在左侧导航栏,选择仪表盘 > 集群。
- 在 Transwarp ArgoDB 区域中,找到并单击 Quark Gateway。
- 单击配置页签,找到 EXTRA_GATEWAY_OPTS 参数并单击其编辑。
填写参数:-Dinceptor.gateway.cache.result.enabled=true,用于开启结果集缓存功能。若需设置多个参数,请用空格分隔。具体参数说明如下:
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.result.enabled | false | 是否开启结果集缓存功能,默认为关闭状态 |
| inceptor.gateway.cache.max.entry.size | 100MB | 一个查询的结果是否被缓存的阈值,如果超过该值,该查询的结果不再被缓存,如果值设置为纯数字(不含单位),则单位为字节 |
| inceptor.gateway.cache.max.memory.usage | 512MB | 缓存结果使用的最大内存,如果值未包含单位,则单位为字节 |
| inceptor.gateway.cache.result.expire.time | 3600 | 缓存有效期,单位为秒 |
| inceptor.gateway.cache.wait.time | 5000 | 单位毫秒,如果多个客户端同时发起同一查询,其中一个会发送到Server 执行,其他的会等待,如果等待时间超过该值,则该查询也被发送到 Server 执行 |
| inceptor.gateway.cache.keywords | 空 | 只缓包含这些关键词的查询的结果 |
参数说明
5. 参考上一步的参数设置方法,开启 TDDMS 数据变化探测功能,保障缓存与原始数据的一致性。
设置案例:-Dinceptor.gateway.cache.tddms.check=true -Dinceptor.gateway.cache.jdbc.url=jdbc:transwarp2://iqa15:8080/default
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.tddms.check | true | 是否开启 Holodesk 表状态探测功能,默认为开启状态 |
| inceptor.gateway.cache.jdbc.url | 无 | 任一 Quark 服务的 JDBC 连接地址,通过该连接,Quark Gateway 可获取到表在 TDDMS 服务上的名称,格式例如 jdbc:transwarp2://<server_ip/hostname>:<port>/<database_name>,更多介绍,见通过 Beeline 命令行连接。 |
| inceptor.gateway.cache.jdbc.username | 无 | 用户名,开启 LDAP 认证时需填写 |
| inceptor.gateway.cache.jdbc.password | 无 | 用户密码,开启 LDAP 认证时需填写 |
| inceptor.gateway.meta.cache.expire.time | 30000 | 元数据信息的过期时间,单位为毫秒 |
参数说明
为更好地匹配您的业务需求,您可以通过设置更多参数来控制缓存行为,例如缓存存储位置、黑名单等,更多介绍,见后文的管理缓存章节。
6. 保存设置后,单击页面右上角的配置服务来下发修改的配置。
7. 在业务低峰期,单击页面右上角的重启,配置将正式生效。
8. (可选)连接 Quark Gateway 并执行 SQL 查询后,可通过调用下述接口来查看缓存命中情况。
# 执行时需要替换真实的 Quark Gateway 服务地址
curl -X GET http://{Quark Gateway 服务地址}:6066/v1/resultcache执行示例:
curl -X GET http://iqa15:6066/v1/resultcache |jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 44 0 44 0 0 816 0 --:--:-- --:--:-- --:--:-- 830
{
"cacheCout": 1,
"hintCount": 1,
"enabled": true
}管理缓存
默认的参数值可满足绝大多数的业务场景,同时,Quark Gateway 还支持基于业务需求调整参数,例如设置缓存清理规则、管理黑名单等,从而更好匹配复杂的业务需求。
管理缓存生命周期
为避免闲置缓存占用内存,Quark Gateway 提供缓存清理功能,您可以通过下述参数控制缓存清理/更新策略,确保数据的有效性并节省内存空间。
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.ttl.autocheck.enable | true | 是否开启缓存自动清理功能,默认为开启状态 |
| inceptor.gateway.cache.ttl.autocheck.time | inceptor.gateway.cache.result.expire.time * 1.5 | 默认ttl即扫描时间间隔为1.5倍的缓存有效时间,单位秒。非特殊需求不必修改该值。 |
| inceptor.gateway.cache.schedule.clean.enable | false | 是否定期清空所有缓存数据 |
| inceptor.gateway.cache.schedule.clean.cron | 0 1 0 * * ? | 缓存清理任务默认为每天凌晨 0 点执行,适用于源表定时更新的场景(如 T+1 场景),可通过 cron 表达式进行配置 |
参数说明
管理黑名单
当查询的结果超出 inceptor.gateway.cache.max.entry.size 的值,Quark Gateway 会自动将其加入黑名单,黑名单中的 SQL 不会尝试建立缓存,您可以通过下述参数控制黑名单行为:
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.black.list.enable | true | 是否开启缓存黑名单功能 |
| inceptor.gateway.cache.black.list.expire.time | 10800 | 黑名单过期时间,单位为秒,从最后一次加入黑名单时开始计算 |
| inceptor.gateway.cache.black.list.size | 10000 | 黑名单数量上限 |
| inceptor.gateway.cache.black.list.check.time | 86400 | 黑名单定时清理的时间间隔,单位秒 |
参数说明
管理存储位置
默认情况下,Quark Gateway 生成的缓存信息存放在自身内存中,如您的集群安装了星环键值数据库 Transwarp KeyByte,您还可以选择将缓存数据对接至该服务,进一步提升管理便捷性和资源利用率。
| 参数 | 默认值 | 说明 |
|---|---|---|
| inceptor.gateway.cache.storage.use.keybyte | false | 是否将缓存信息存储在 KeyByte 服务中 |
| inceptor.gateway.cache.keybyte.ip | 0.0.0.0 | KeyByte 服务的 IP 地址 |
| inceptor.gateway.cache.keybyte.port | 6399 | KeyByte 的服务端口 |
| inceptor.gateway.cache.keybyte.password | 空 | KeyByte 的连接密码 |
| inceptor.gateway.cache.keybyte.max.total | 200 | KeyByte 连接池的最大连接 |
| inceptor.gateway.cache.keybyte.max.idle | 20 | KeyByte 连接池的最大空闲连接 |
| inceptor.gateway.cache.keybyte.min.idle | 1 | KeyByte 连接池的最小空闲连接 |
| inceptor.gateway.cache.storage.keybyte.time.threshold.enabled | false | 当缓存超过时间阈值,是否将其从内存转为 Keybyte 存储 |
| inceptor.gateway.cache.storage.keybyte.time.threshold | 60 | 缓存超时阈值,单位为秒 |
| inceptor.gateway.cache.storage.keybyte.size.threshold.enabled | false | 当缓存超过大小阈值,是否将其从内存存储转为 Keybyte 存储 |
| inceptor.gateway.cache.storage.keybyte.size.threshold | inceptor.gateway.cache.max.entry.size / 1000 | 缓存大小阈值,如果值设置为纯数字(不含单位),则单位为字节 |
核心点二 全新物化视图2.0
物化视图VS.传统视图
视图(VIEW)用于保存复杂的 SQL 查询,以便简化后续操作,但其本质仍是执行保存的 SQL 语句,因此无法提升查询性能。为了解决这一问题,ArgoDB 推出了物化视图 2.0,突破了传统物化视图的 MBO 改写限制和对复杂语法支持有限的问题,显著提高数据同步效率,为您提供更快速、更精准的数据查询加速能力。
| 对比项 | 物化视图 2.0 | 传统物化视图 |
|---|---|---|
| 创建支持 | 无限制 | 创建语法受限 |
| 语法支持 | 无限制 | 仅简单语法 |
| 查询原理 | 基于视图查询,系统自动替换为关联的物化表 | 基于源表查询,系统基于 MBO 改写 |
| 更新原理 | 基于源表最新数据创建新物化表并自动关联,随后删除旧物化表 | 原地更新(清空表+写入新数据) |
| 结果集匹配 | 在编译前匹配视图的结果集与其对应的物化表 | 在执行计划阶段匹配 SQL 查询语句的结果集与物化视图 |
| 数据过期表现 | 不会读到过期数据(自动转查基表) | 可能会读到过期数据 |
语法介绍
使用下述语法创建物化视图 2.0,系统将会自动执行相关 SQL 并将其结果集关联至一个不可见的物理表,后续对该视图执行查询时,系统将在将执行编译前自动转换查询对象为其关联的物化表,无需再执行原 SQL 中的复杂查询,从而极大加速查询效率。
物化视图 2.0 仍然是普通视图,支持执行常规的视图操作,如替换定义、修改、删除等操作。
注意事项
由于每次数据变更可能触发物化表重建,源表频繁更新时,可能会有多个未删除的过期物化表副本。
语法格式
CREATE VIEW [IF NOT EXISTS] <view_name>
[<column_name1> COMMENT "<column_text>", ...]
WITH MATERIALIZED
[COMMENT "<view_text>"]
[REFRESH IMMEDIATE|DEFERRED ON (<source_table1>, <source_table2>, ...)]
[ON (<table_name>, ...)]]
[PARTITIONED ON (<partition_key>, ...)]
[CLUSTERED BY (<bucket_key>, ...)]
[SORTED BY (<sort_key> [ASC | DESC], ...)]
[INTO <num_buckets> BUCKETS]
[STORED AS HOLODESK]
[WITH TABLESIZE <table_size>KB|MB|GB|TB|PB|EB|ZB|BB [REPLICATION <replication_num>]]
[TBLPROPERTIES ('<property_name>'='<property_value>', ...)]
AS SELECT <select_statement>;参数说明
- <view_name>:视图名称,通过可选项 IF NOT EXISTS 可在创建视图前检测是否已存在同名视图。
- <column_name>:视图中的字段列名称。
- <column_text>:列注释,支持对视图查询的结果字段定义列名称、注释。
- <view_text>:视图注释,支持使用 COMMENT 为视图加注释,注意注释要放在引号中。
- IMMEDIATE|DEFERRED:定义的数据更新机制,更多介绍,见更新物化视图。
- <table_source>:更新视图绑定的物化表时,指定更新依赖的源表名称。
- <partition_key>:指定视图绑定的物化表的分区列名称,支持单值分区表,分区字段必须出现在查询子句 <select_statement> 中,且位于字段列表最末尾。
- <bucket_key>:指定视图绑定的物化表的分桶列名称。
- <sort_key>:指定视图绑定的物化表的分桶排序列名称,默认为升序排序,可以支持指定 DESC 表示降序,ASC 表示升序。
- <num_buckets>:指定视图绑定的物化表的分桶数。
- <property_name>:视图绑定的物化表属性名称。
- <table_storage_format>:支持使用 STORED AS 指定表的存储格式。
- <table_size>:当选择物化为 Holodesk 表时,支持设置表大小,或者可以通过参数 hive.materializedview.holodesk.default.table.size 设置,默认为 11GB
- <replication_num>:表的副本数。
- <property_value>:视图绑定的物化表属性值。
示例
假设我们有一个名为 orders 的表,该表包含订单相关信息,包括 order_id、customer_id、order_amount、order_date 和 customer_region 等字段。
现在我们创建一个名为 new_mv 的物化视图,该物化视图将包含在 2023 年内北美地区消费总额超过 1000 的客户信息,并显示每个客户的总消费、订单数量和平均订单金额,按总消费金额从高到低排序,便于快速识别高价值客户群体。
CREATE VIEW new_mv with MATERIALIZED AS
SELECT
customer_id,
SUM(order_amount) AS total_spent,
COUNT(order_id) AS total_orders,
AVG(order_amount) AS avg_order_value
FROM
orders
WHERE
order_date BETWEEN '2023-01-01' AND '2023-12-31'
AND customer_region = 'North America'
GROUP BY
customer_id
HAVING
SUM(order_amount) > 1000
ORDER BY
total_spent DESC;更新物化表
当视图查询的源表变更时(如 INSERT),默认情况下视图关联的结果集物化表会过期,此时执行 SQL 查询视图时将不会进行替换加速。
为避免物化表结果过期,您可以选择设置更新策略并开启自动更新,工作原理如下:
图. 更新数据
操作流程
1. 开启自动更新模式,当源表数据产生更新时,视图关联的物化表会自动触发更新。
set quark.mbo.rebuild.auto=true;当视图绑定的结果集物化表在开启自动更新参数之前已经过期时,系统将不会执行自动更新任务。此时,必须通过手动更新的方式强制执行重建。
2. (可选)通过 ALTER VIEW REBUILD 手动更新物化表,示例如下:
ALTER VIEW <view_name> REBUILD;此外,您还可以执行 set quark.mbo.force.rebuild = true; 命令,配合上述命令实现强制更新。
3. (可选)默认情况下,源表数据更新时立即同步更新物化表,如需调整更新策略,可执行下述格式的命令进行设置。
ALTER VIEW <view_name> REFRESH IMMEDIATE|DEFERRED -- [1]
[ON (<source_table1>, <source_table2>, ...)]; -- [2]- 设置更新策略:
-- IMMEDIATE(默认):在源表数据更新时立即同步更新物化表。
-- DEFERRED:在查询时才更新物化表。建议在源表存在字段增删操作时使用 DEFERRED 模式,以避免频繁重建物化表。
- 设置监听源表:
-- 默认监听所有源表的更新,您也可以通过 ON (<source_table1>, <source_table2>, …) 指定更新依赖源表,例如在流水表和维表的关联查询场景中,只监听流水表的更新,避免因维表变更触发无效的物化表更新,从而提升更新效率。
开启查询加速
1. 登录 Manager 平台,单击 Quark 服务。
2. 单击配置页签,添加自定义参数,将 Quark 参数 quark.view.materialized.rewrite.enable 设置为 true,以启用视图查询自动重写功能,利用其物化表实现查询加速。
图. 启用视图自动重写
您也可以通过执行 set quark.view.materialized.rewrite.enable=true 命令,使该设置在当前会话中生效。
3. 通过 DESC FORMATTED new_mv 命令,查看我们在前面创建的物化视图 new_mv 及关联的物化表,查询结果如下,关键字为 materialized_table 对应的值。
-- 省略部分内容
| last_modified_by | admin |
| last_modified_time | 1726737832 |
| materialized_table | demodata.new_mv_deec066d |
| transient_lastDdlTime | 1726737832 |
| ...... | ...... |您还可以执行 DESC FORMATTED <物化表> 命令查看物化表的属性,通过 View Out Of Date 属性的值判断该物化表是否过期(即值为 YES)。
4. 使用 PLANT 命令打印 SQL 查询语法树,检查 TOK_TABNAME 是否为视图绑定的物化表名称,如果是,则表示查询已成功替换为物化表查询,实现了加速效果。
-- 将查询视图自动转换为查询该视图绑定的集物化表
set quark.view.materialized.rewrite.enable = true;
-- 执行 PLANT 命令
PLANT select * from new_mv;
-- 查询结果,省略部分内容
| (TOK_QUERY |
| (TOK_FROM |
| (TOK_TABREF |
| (TOK_TABNAME |
| (demodata) |
| (new_mv_deec066d))) |
| (new_mv_aa2fb850))) |
| (TOK_INSERT |
| (TOK_DESTINATION |
| (TOK_DIR |
| (TOK_TMP_FILE))) |
| (TOK_SELECT |
| (TOK_SELEXPR |
| (TOK_ALLCOLREF))))) |
| |
+----------------------------------------------------+参数调优
| 参数 | 默认值 | 说明 |
|---|---|---|
| quark.mbo.rebuild.auto | false | 控制是否自动更新结果集缓存表和物化视图,建议全局设置。设为 true 后,当源表数据更新,自动即时更新重建。 |
| quark.mbo.rebuild.delay.time | 0 | 更新延迟时间,允许过去一段时间内更新过的物化视图或结果集表不触发更新,单位为秒(s)。 |
| quark.mbo.force.rebuild | false | 执行 alter [MATERIALIZED] view rebuild 语句时不关心视图状态强制更新 |
| hive.materializedview.fileformat | ORC | 指定结果集缓存的表类型,即视图持久化数据时采用的存储格式,取值包含:none、HOLODESK、TextFile、equenceFile、RCfile、ORC、HYPERDRIVE。设置本参数自定义存储格式时,需设置该存储格式对应的 Serde 类型参数当设为 HOLODESK 时,可通过设置参数 holodesk.default.storage.format 控制为普通表(normal)或性能表(performance) |
| hive.materializedview.serde | 见描述 | 当需要自定义持久化存储类型时,设置本参数指定对应的 Serde 的类型 。默认为 org.apache.hadoop.hive.ql.io.orc.OrcSerde 为 ORC 格式对应的 Serde。 |
| quark.view.materialized.rewrite.enable | false | 【物化视图 2.0 相关参数】控制是否在查询视图时,自动替换为查询关联的结果集物化表,开启此参数可以有效提高查询视图的性能,建议全局设置。 |
| quark.show.hidden.materialized.table | false | 【物化视图 2.0 相关参数】控制是否显示数据库下基于物化视图 2.0 建立的物化表,默认不显示,即 SHOW TABLES 不展示物化表。 |
| quark.view.materialized.refresh.time | 0 | 【物化视图 2.0 相关参数】用于设置查询视图时能否替换为查询管理的物化表。设为 -1 时,允许查询视图时使用过期物化表进行替换 |
核心点三 创新的Linac引擎
ArgoDB 是一款创新型分布式数据库,旨在为用户提供超大规模的数据处理能力、高效的性能表现、稳定的运行环境以及极简的使用体验。广泛应用于 Teradata、Oracle、CDH 等产品的替换场景中,成为众多企业的首选解决方案。为进一步提升计算效率和性能稳定性,ArgoDB 6.0 正式推出了基于 C++ 语言实现的高性能 Linac 计算引擎。
Linac 介绍
优势
Linac 引擎目前已经在多个用户生产中落地应用,实现了对 Impala、Oracle、Inceptor 业务的改造和上线,能实现数倍的性能提升。区别于 ArgoDB 传统 JAVA 引擎,Linac 是基于 C++ 语言改写的高性能计算引擎,对比原 JAVA 引擎有如下优势:
- 兼容适配:支持 Inceptor、Oracle、Teradata 三种语法兼容,提供 Inceptor、Oracle、Teradata、Impala 各引擎的 UDF兼容性。
- 内存管理:Linac 引擎自通过灵活的内存管理方式,任务执行结束后能够迅速释放占用的内存资源,缓解多进程高负载集群的内存压力。
- 性能领先:大幅度提升算子性能,针对存储引擎和数据存储格式进行改造,同时优化了执行计划、任务调度、算子识别等场景。保证了任务提交后不回退,以及性能稳定提升。
Linac 引擎已经实现常见算子的本地化,且实现了算子的性能提升,其中性能提升最大的如下:
- Group by:性能提升接近10倍,聚合率越高(Pre-Group by 效果好),性能提升越大
- Filter( UDF):在 SQL 中使用了较多 UDF 进行字段的处理和聚合时,性能有超过10倍的提升
- Join:对于所有 Join 类型,性能都有很大幅度的提升,甚至可以依靠 Linac 强行计算出数据倾斜的 Cross Join。
对于一些大数据量的 Order By/Sort By/窗口函数(Rand、row_number)等,由于对内存的开销比较大,Linac 在计算时仍会有部分数据落盘以保证稳定性,因此性能提升幅度与数据量及内存配置相关。在使用时,我们一般建议保留足够的堆内内存空间,可以适当地调小堆外的内存。
执行模式
Linac 引擎支持 Cluster、Localfast 和 OLAP 模式,不支持 Local 模式。对应在 DBA Service 中依次显示为 linac-cluster、linac-localfast、linac-olap 三种模式。
使用 Linac 模式时,若为单机本地读场景,建议使用 Localfast 模式,此时您需要同时设置以下参数:
set use.linac=true;
set ngmr.windrunner.enabled=true;
set ngmr.local.fast.enabled=true;SQL 执行模式的更多信息请参考章节:SQL 执行模式
使用 Linac
开启 Linac
Linac 引擎作为 ArgoDB 高性能计算引擎,支持通过参数控制功能的开启
当启动 Linac 引擎总开关 use.linac =true 后,为了保证计算任务能够正常使用 Linac 引擎,且任务逻辑能够自洽,ArgoDB 后台会自动配置以下参数:
set hive.merge.nway.joins = false;
set inceptor.filterjoin.enabled = false;
set windrunner.aggregate.check = false;
set windrunner.nlssort.check = false;
set ngmr.windrunner.nonquery.enabled = true;
set ngmr.windrunner.session.subquery.enabled = true;
set inceptor.winfunc.collapse.optimize = false;
set inceptor.winfunc.transform.enabled = false;
set inceptor.withas.material.fileformat = holodesk_performance;限制条件
Linac 计算引擎针对 Holodesk 列式存储进行计算,可以兼容不同存储格式和 SQL 语法,但仍然存在以下限制边界,当开启 Linac 引擎但遇到不支持的场景时,则会自动回退至 Windrunner 引擎进行执行计算。
- 存储格式
Linac 引擎兼容 Holodesk 列存格式,目前仅支持 Holodesk 性能表、Holodesk 宽表(可支持 1000+ 列的高性能查询),暂不支持其他存储格式,会自动回退至 Windrunner 引擎。
- SQL 查询类型
对于以上支持的存储类型,Linac 引擎执行 SQL 操作时 Linac 的支持情况如下:
- 支持 DML 中的插入、更新、删除数据操作 INSERT/UPDATE/DELETE。但不支持 MERGE INTO,会自动回退至 Windrunnenr 引擎。
- 支持使用 INSERT INTO SELECT 的方式插入数据至非分区分桶 Holodesk 表,和指定分区的单值分区非分桶表。
- 支持 DQL 查询操作 SELECT。
DCL 操作,以及 DDL 操作中的 创建、删除、清空表操作 CREATE/DROP/TRUNCATE TABLE、修改表或字段名称操作 ALTER TABLE/COLUMN RENAME,不调用计算引擎。
功能参数
| 参数名称 | 默认值 | 参数说明 |
|---|---|---|
| use.linac | false | Linac 引擎总开关,设置为 true 后即使用 Linac 引擎,且会开启一系列 Linac 优化参数,具体请参考 Linac 引擎自动优化参数 |
| quark.linac.fail.no.retry | false | 控制 Linac 引擎总的任务重试机制,开启后对性能有一定影响 |
| inceptor.filterjoin.enabled | true | 控制是否开启 FilterJoin 优化。FilterJoin 是基于 MapJoin 的优化,适用于语句中有多个级联 MapJoin 的场景,加快这类语句的执行速度。 |
| hive.merge.nway.joins | true | 控制是否将相邻的 JOIN 连接操作合并为一个多路连接(n-way JOIN)。 |
| inceptor.withas.material.fileformat | AUTO | 设置物化 with-as 表的默认文件格式。可选项为 auto, orc, holodesk, holodesk_performance |
Linac 优化参数
| 参数名称 | 默认值 | 参数说明 |
|---|---|---|
| quark.ignore.linac.error | true | 默认编译时 Linac 不支持的任务会自动回退至 Java 引擎,设置成 false 后,则会产生会报错,适合业务兼容性验证测试时使用 |
| quark.qtrace.enabled | false | 开启后,会在 Quark Server 日志目录生成 Qtrace 日志文件,可以帮助分析每个算子和计算节点的性能开销 |
| inceptor.log.level | warn | 6.0 版本的默认日志级别已经修改为 warn,如果需要查看更细节的日子信息,可将参数设置为 info,如果测试高并发性能,则将参数设置为 error |
业务测试场景参数
| 参数名称 | 默认值 | 参数说明 |
|---|---|---|
| character.literal.as.string | false | ArgoDB 5.x 之后,字符串常量的默认类型为 CHAR(n),此时 '' 等于 NULL。开启此参数后,字符串常量默认类型为 STRING。 |
| inceptor.udf.compatible.with.oracle | false | 开启此参数后,UDF 函数行为将与 Oracle 兼容 |
| plsql.server.dialect | oracle | 支持 PLSQL 的方言,当开启 Linac 模式时不支持 db2 方言。 |
| server.dialect.parser.oracle | false | 设置是否在编译阶段使用 Oracle 方言,用于多方言存储保证解析行为的统一性 |
| linac.udf.compatible.mode | quark | 设置 Linac 模式下,UDF 函数的兼容模式,可选项有 quark,oracle,impala,td |
兼容性参数
 登录后可评论
登录后可评论








.jpg)



