【最新案例】ArgoDB新功能之读写分离,助力某医药集团打造高效数据中心,消除传统方案的灵活性限制,确保响应时间的可预测性
友情链接:
- 【数据处理效率提升实践】ArgoDB如何助力企业全面实现数据处理效率最大化?
- 【指标查询调优实践案例】ArgoDB助力某银行实现性能全面提升
- 【CDH国产化替代案例】全面简化架构,降低成本,大幅提升数据处理效率
前言
面临企业愈加复杂的数据处理需求,ArgoDB 推出了读写分离功能,不仅可实现不同的业务物理隔离所需计算/存储资源,同时避免了多次的数据流转带来的时间和存储成本。
产品功能请查看: ArgoDB读写分离功能详解
更多有关ArgoDB的产品功能请查看:ArgoDB官方文档站

背景介绍
在传统部署中,ArgoDB 的 TDDMS 组件通常承担着为大数据处理平台提供统一的数据存储服务,随着企业数据量的激增和业务类型的多样化,单一集群往往需要同时处理日常的批量数据处理任务和即时查询业务,可能引发计算和存储资源的抢占,进而影响了业务的执行效率。
TDDMS 是星环自主研发的分布式数据管理系统,具有数据多副本一致性保障、自动数据重分布、数据高可用等特点。
更多有关TDDMS的介绍可参考:星环分布式存储TDDMS大揭秘系列文章
面临此类问题时,通常会尝试通过错峰执行和资源调度手段,来解决资源的竞争和查询效率的优化。虽然这些策略在某些情况下有效,但它们也存在一些局限性,这些局限性可能会影响系统的整体性能和效率:
| 类别 | 局限性 |
|---|---|
| 错峰执行 | 时间限制:错峰执行要求批处理作业在系统负载较低的时段执行,通常为夜间或周末,影响数据的时效性。灵活性不足:错峰执行不适应那些需要即时数据处理或分析的业务场景,因为它无法提供实时或近实时的数据处理能力。 |
| 资源调度 | 优先级管理复杂:资源调度需要精细的优先级规划,当系统中运行多种不同的作业时,设置合适的优先级变得非常复杂。响应时间不确定:由于资源是动态分配的,且资源不是完全隔离的,对于查询业务,其响应时间可能因其他作业(如批处理)的影响而变得不可预测。 |
读写分离能力介绍
为了克服上述局限性,ArgoDB 的读写分离功能提供了一种全新的解决方案,您可以在统一的存储基础上划分出多个逻辑上独立的集群,专注于各自的业务,实现存储和计算资源的隔离。例如,我们可以单独为查询业务划分出只读集群中,该集群中仅存储表的副本数据,同时按需分配计算资源,从而保证日常的批处理业务和查询业务能够高效、无干扰地运行。
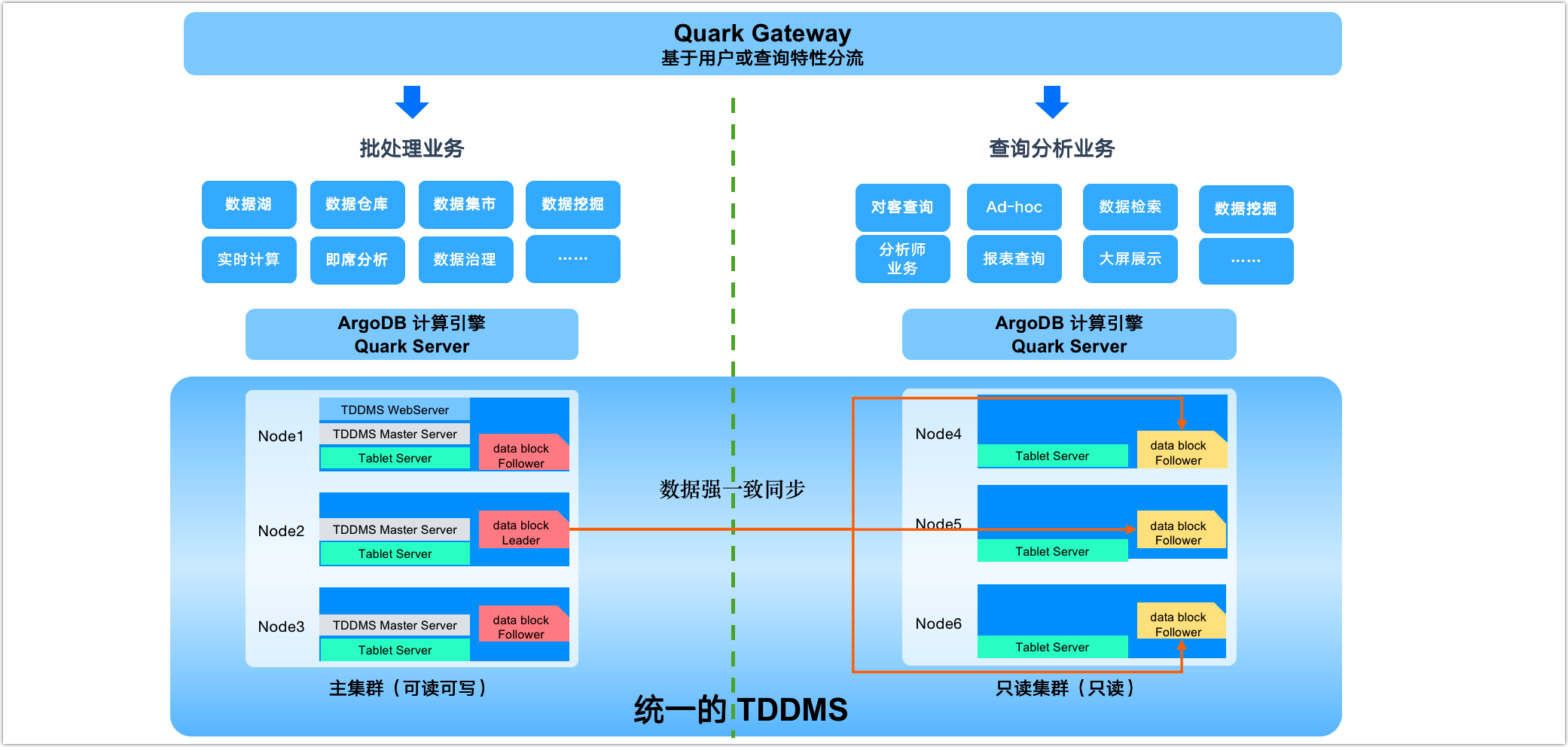
图. 数据工作区示例
数据一致性与高可用性
基于Raft一致性协议,读写分离能力提供了高度一致和可靠的数据同步机制,确保业务连续性和数据完整性,同时为集群扩展提供了无缝支持。
Raft协议算法剖析与详解: https://community.transwarp.cn/article/956
全面资源隔离
通过逻辑主备集群的划分,实现了计算和存储资源的完全隔离,使得批处理和查询业务能够在最适宜的环境下运行,提高了系统的整体效率。
业务隔离与性能优化
可分别为批处理和查询业务分配了专门的逻辑集群,基于业务需求优化执行引擎和参数设定,实现了业务逻辑的隔离和性能的最大化。
减少数据流转成本
只读集群作为 Follower 只同步必要的数据变更,大幅减少了数据流转所需的时间和存储成本,提升了数据时效性。
操作流程
本案例中,某企业为了适应业务需求的增长并优化系统性能,需要将现行的 4 节点集群扩展至 8 节点。同时,需要在此基础上进一步细化资源分配,以便更好地适应各类业务的具体需求:
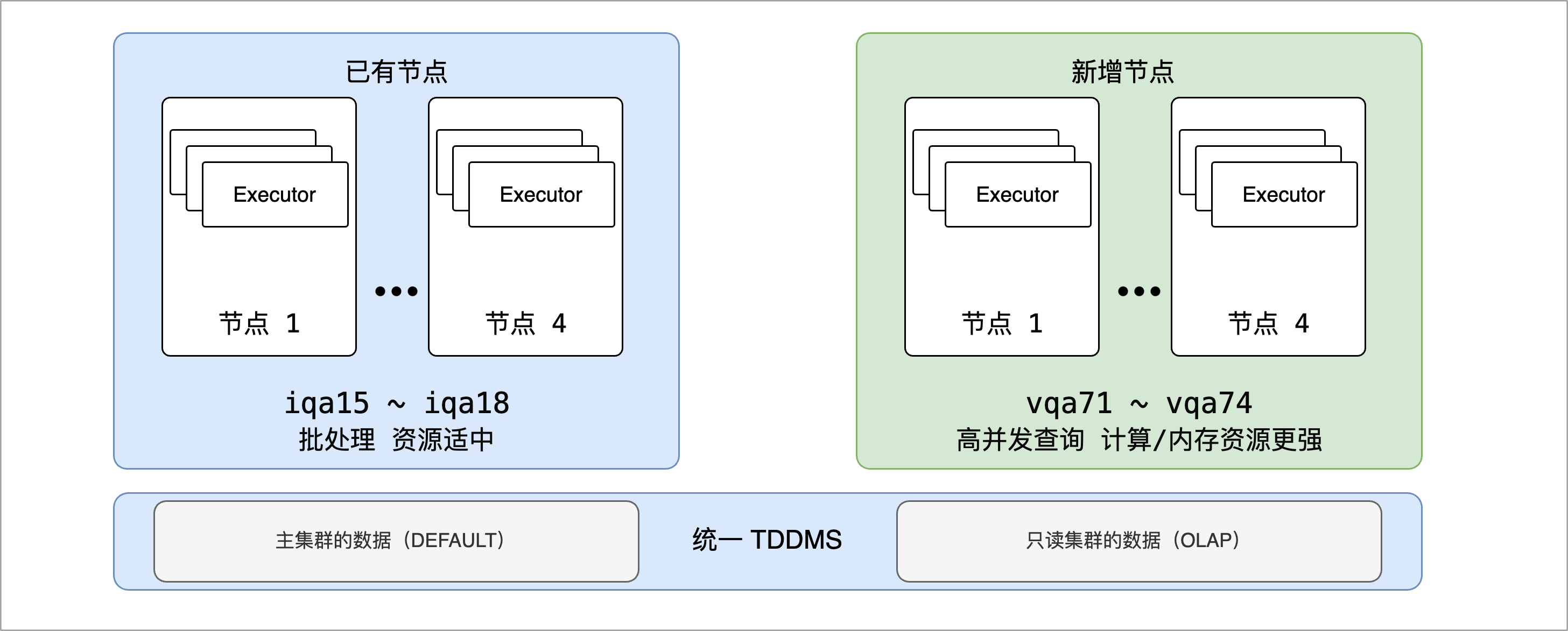
图. 集群扩容与多数据工作区示例
- 已有节点:继续支持全天候的批处理业务,将配备适中的计算和内存资源,确保稳定运行而无需过量的资源投入。
- 新增节点:主要服务于高并发查询业务,这些节点将搭载高性能处理器和更多容量的内存,并将其与执行批处理任务的节点进行资源隔离,避免查询操作不会受到长时间运行的批处理作业的资源争夺影响。
通过这种配置,我们保障了业务的连续性和查询的响应性,同时实现了成本效益的平衡。批处理节点和查询节点能够在为它们量身定制的环境中高效执行,确保了整个集群的性能最优化。
如需基于集群的已有节点设置读写分离集群,您需要将相关节点上的 TDDMS 服务执行缩容,随后重新扩容以实现数据分片的角色重分布,具体操作可参考《故障排查手册》中的更换硬盘章节。您也可以联系星环科技,由专业的技术团队详细评估您的需求并提供解决方案。
1. 登录 Transwarp Manager 平台,完成添加节点的操作。
具体操作,见添加节点。
2. 为新节点添加 TDDMS Tablet Server 角色服务,为后续同步主集群的表副本数据提供基础能力。
a. 在左侧导航栏,选择仪表盘 > 集群。
b. 在 Transwarp ArgoDB 区域,单击 TDDMS 服务卡片。
c. 在角色页签,单击添加角色并单击下一步。
d. 在左侧的服务列表,选择 TDDMS Tablet Server 角色,然后为其分配新节点并单击下一步。
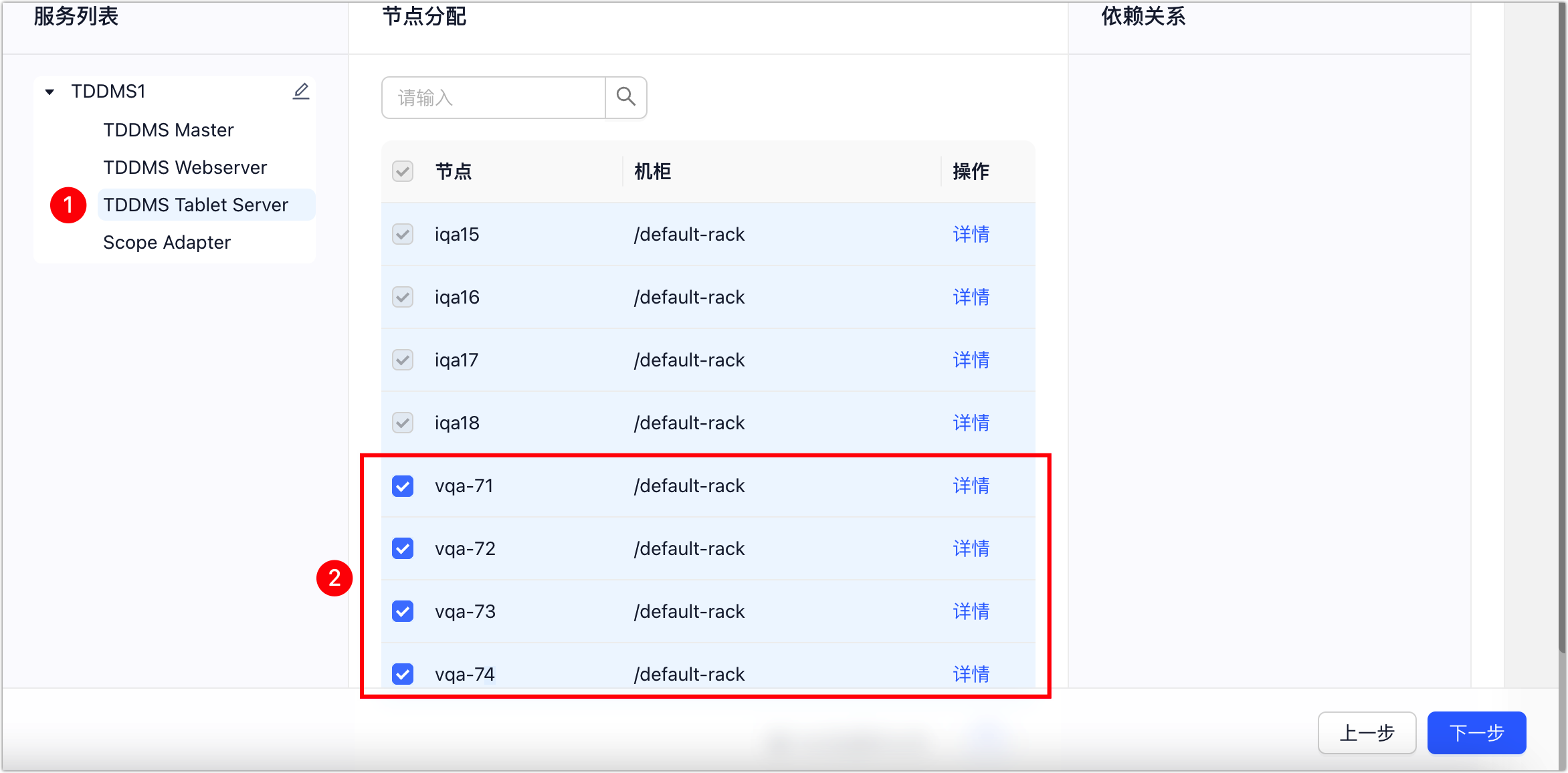
图. 分片角色
e. 在基础参数标签页,下翻找到配置项 topology.topology.datacenter,单击编辑,然后为新增的角色定义一个具有业务意义的值,例如 OLAP(代表用于 OLAP 查询)。
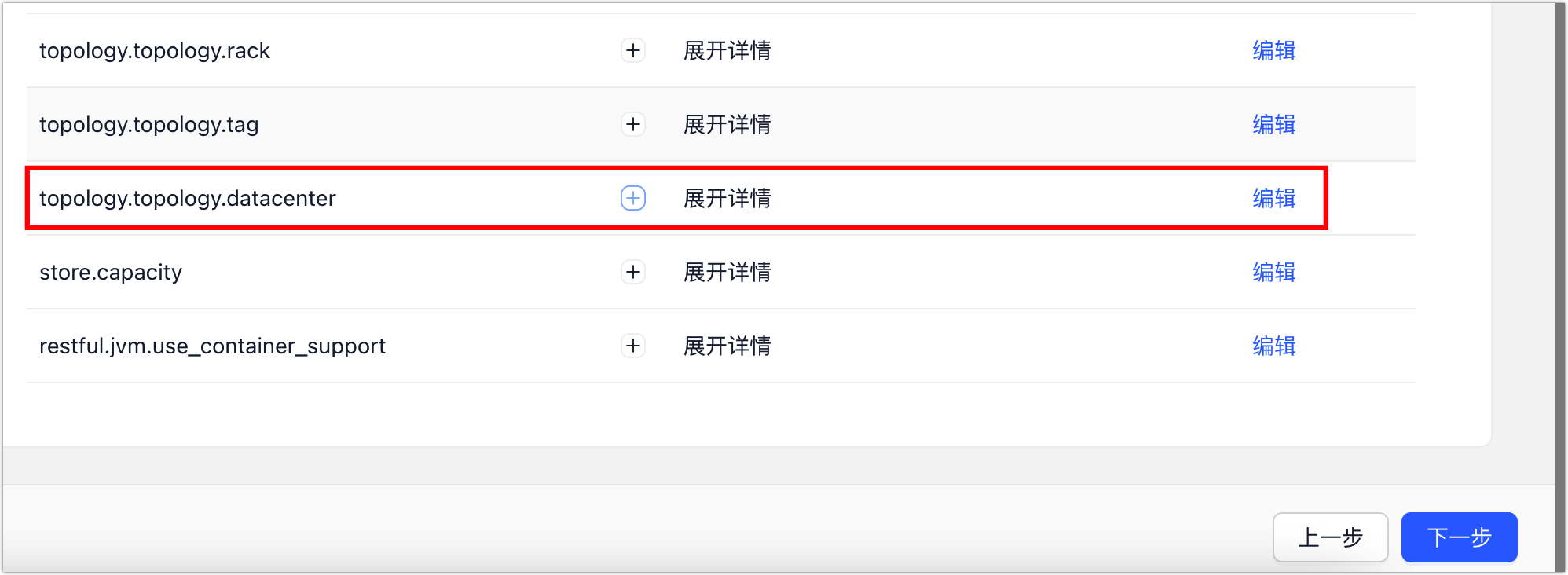
图. 修改参数
f. 单击下一步,选择是否立即重启 TDDMS 的关联服务,包括 Quark、 Compact Service、Slipstream(如有)。
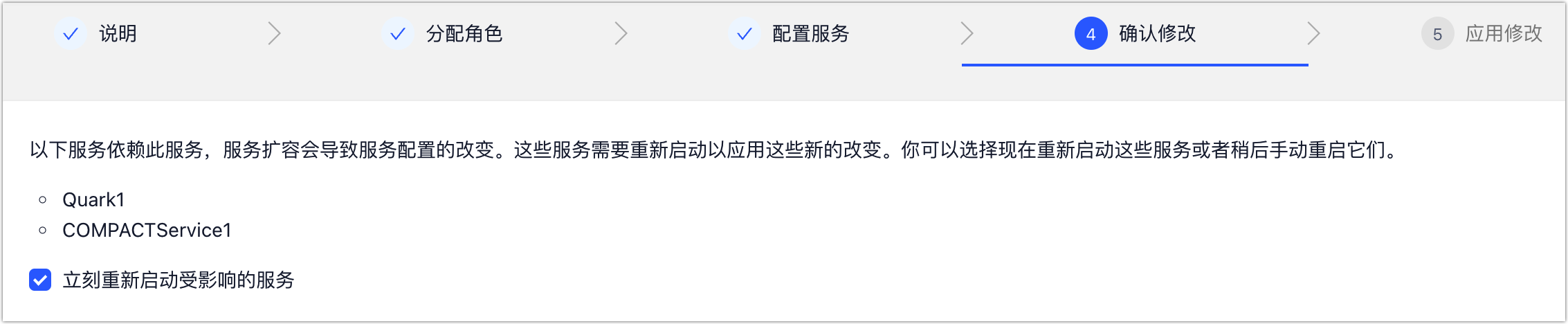
图. 是否重启相关服务
为避免影响业务运行,您也可以不选中立即重启受影响的的服务,稍后在合适的时间(例如业务低峰期)手动重启相关服务。
3. 为新节点添加 Quark、Compact Service 服务,用于为只读集群提供查询能力。
具体操作流程,见添加服务。
在部署服务时,各服务的角色应分配在只读集群所属的节点中,从而实现计算资源与主集群的完全隔离。
4. 创建表,通过表属性的设置来控制表的副本在各集群中的分布。
更多关于建表语法的介绍,见创建表。
CREATE TABLE demotable (
`eid` STRING DEFAULT NULL,
`funds` FLOAT DEFAULT NULL,
`username` STRING DEFAULT NULL
)
STORED AS holodesk
TBLPROPERTIES (
'data.center' = 'DEFAULT',
'disaster.preparedness.enabled' = 'true',
'dc.affinity.enabled' = 'true'
);- data.center:指定主集群,默认为 DEFAULT。
- disaster.preparedness.enabled:是否开启跨逻辑集群的高可用能力,即表副本可分布至只读集群,默认为 false,需设置为 true。
- dc.affinity.enabled:是否开启主集群的数据亲和性,默认为 false,设置为 true 后,ArgoDB 会将数据分片的 Leader 角色自动分配或迁移到主集群,从而实现读写分离的效果,即只读集群仅承担数据分片的 Follower 角色以对外提供读服务。
-- 除在建表时设置外,您也可以对已有表通过修改表属性的方法来实现,格式为 ALTER TABLE table_name SET TBLPROPERTIES ('property_name'= 'property_value'),例如 ALTER TABLE demotable SET TBLPROPERTIES ('data.center'= 'DEFAULT')。
-- 修改已有表可能触发数据分片角色的自动迁移,迁移的完成时间受数据规模、任务负载等因素综合影响。您可以通过 TDDMS 管理页面查看表的角色分布(定期刷新),如未及时更新,您也可以执行 curl -XPOST "{TDDMS 服务地址}:4567/cluster/gc 格式的命令来手动刷新角色分布信息。
5. 通过 TDDMS 查看数据分片的角色分布。
a. 登录 Transwarp Manager 平台。
b. 选择仪表盘 > 集群,然后单击 Transwarp ArgoDB 区域中的 TDDMS 服务卡片。
c. 在角色标签页,找到并单击 TDDMS Webserver 对应的服务链接。
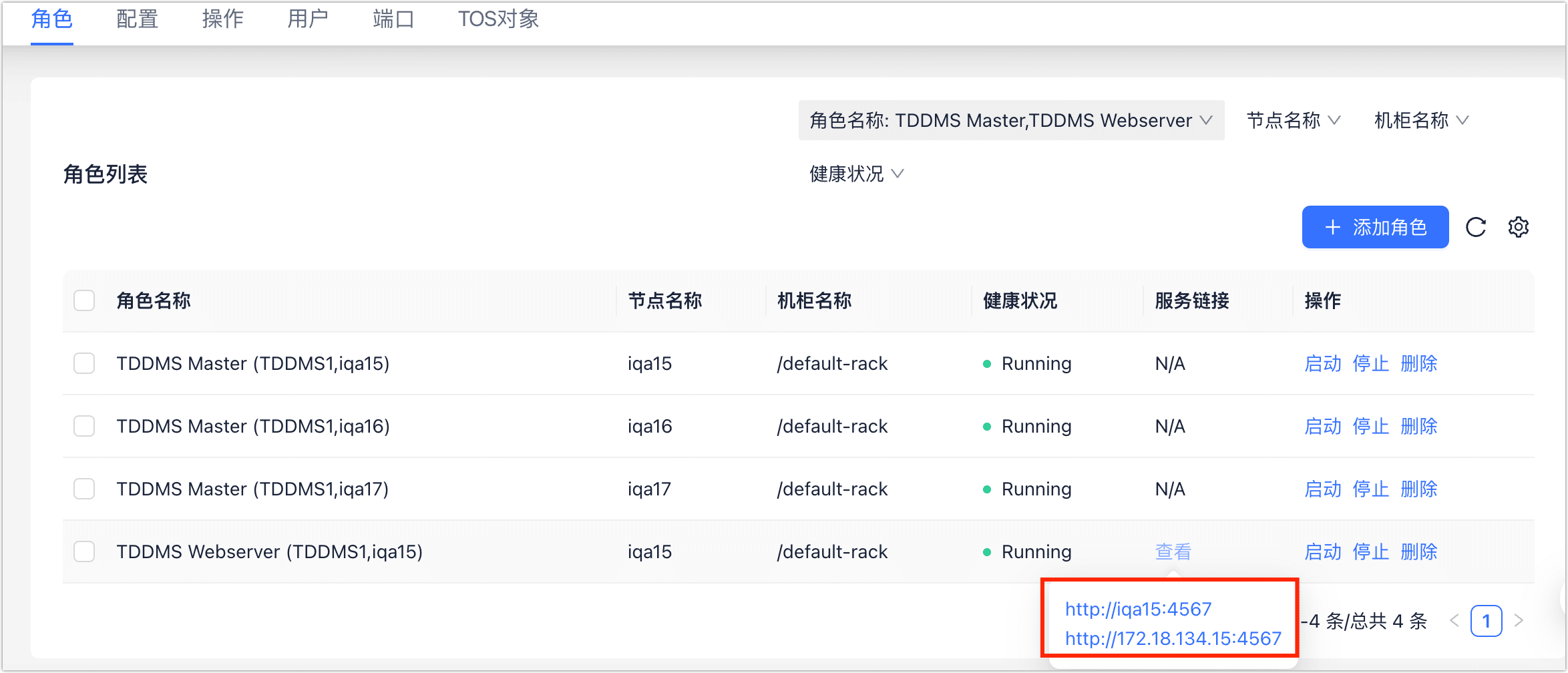
图. 获取服务链接
d. 在跳转到的页面,完成登录,默认账密为 shiva。
e. 单击 Tables 标签页,搜索并单击名称前缀为刚刚创建的表(包含库名),本案例中的库名和表名的组合为 multi_dc.demotable。
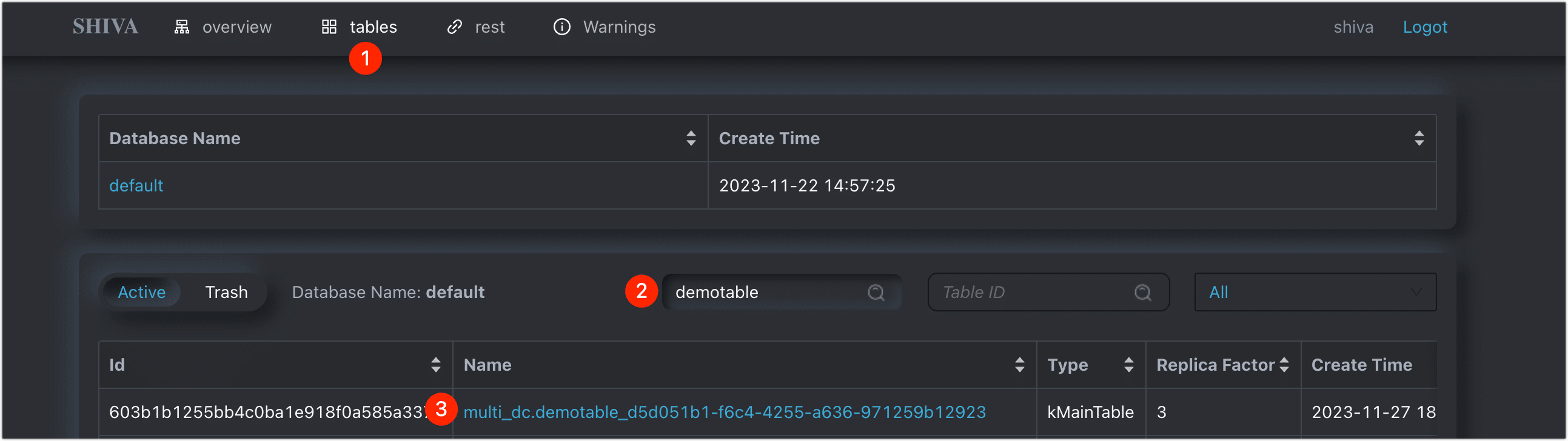
图. 查找表
f. 在跳转到的 Tablets 页面,可以查看到角色的分布信息,如下图所示 demotable 共有 8 个数据分片,每个数据分片包含 3 个副本,分别是 1 个 Leader,2 个 Follower,从而保障数据的高可用。
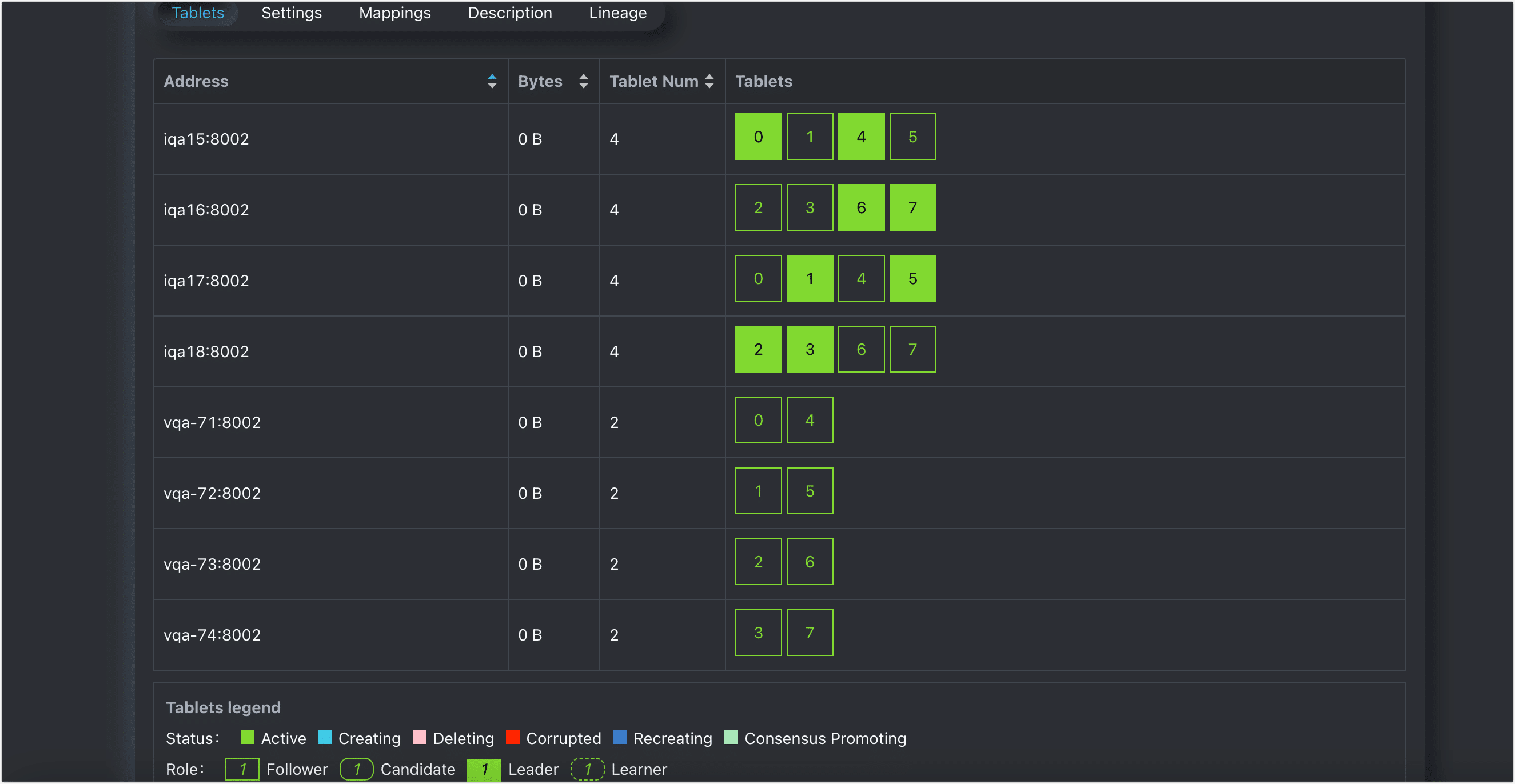
图. 角色分布
| 类别 | 节点 | 说明 |
|---|---|---|
| 主集群DEFAULT | iqa15 ~ iqa18 | 存放每个分片的 1 个 Leader 和 1 个 Follower 角色,保障数据高可用,提供对外的数据读写能力。 |
| 只读集群OLAP | vqa-71 ~ vqa74 | 仅存放每个分片的 1 个 Follower 角色,提供对外的数据只读能力。 |
类别 节点 说明
此时,通过数据分片的分布可以看出,我们通过单个 TDDMS 实现了逻辑层面的读写分离能力,我们可以基于业务特性为不同的逻辑集群定制分配不同的计算资源,更好地提高资源利用率,契合业务需求。
6. 安装只读集群对应的 Qurak 服务,在执行安装时,依赖已有的 TDDMS 服务并将对应的 Executor 分布在只读集群对应的节点上。
7. (可选)通过 Quark Gateway 组件,实现基于用户或规则的分流,让批处理业务和 OLAP 查询业务分别自动分配至相应的 Quark 服务上。
具体配置方法和案例介绍,见 Quark Gateway 使用手册。
除此以外,为更好地发挥性能,连接数据库后,推荐执行 set argodb.prefer.same.data.center.enabled = true (默认为 false),从而优先读取相同同逻辑集群的数据,避免跨逻辑集群读取数据,此功能仅支持 local 模式和 localfast 模式。关于模式的更多介绍,见附录章节中的SQL 执行模式说明。
友情链接:
- 【数据处理效率提升实践】ArgoDB如何助力企业全面实现数据处理效率最大化?
- 【指标查询调优实践案例】ArgoDB助力某银行实现性能全面提升
- 【CDH国产化替代案例】全面简化架构,降低成本,大幅提升数据处理效率
前言
面临企业愈加复杂的数据处理需求,ArgoDB 推出了读写分离功能,不仅可实现不同的业务物理隔离所需计算/存储资源,同时避免了多次的数据流转带来的时间和存储成本。
产品功能请查看: ArgoDB读写分离功能详解
更多有关ArgoDB的产品功能请查看:ArgoDB官方文档站
背景介绍
在传统部署中,ArgoDB 的 TDDMS 组件通常承担着为大数据处理平台提供统一的数据存储服务,随着企业数据量的激增和业务类型的多样化,单一集群往往需要同时处理日常的批量数据处理任务和即时查询业务,可能引发计算和存储资源的抢占,进而影响了业务的执行效率。
TDDMS 是星环自主研发的分布式数据管理系统,具有数据多副本一致性保障、自动数据重分布、数据高可用等特点。
更多有关TDDMS的介绍可参考:星环分布式存储TDDMS大揭秘系列文章
面临此类问题时,通常会尝试通过错峰执行和资源调度手段,来解决资源的竞争和查询效率的优化。虽然这些策略在某些情况下有效,但它们也存在一些局限性,这些局限性可能会影响系统的整体性能和效率:
| 类别 | 局限性 |
|---|---|
| 错峰执行 | 时间限制:错峰执行要求批处理作业在系统负载较低的时段执行,通常为夜间或周末,影响数据的时效性。灵活性不足:错峰执行不适应那些需要即时数据处理或分析的业务场景,因为它无法提供实时或近实时的数据处理能力。 |
| 资源调度 | 优先级管理复杂:资源调度需要精细的优先级规划,当系统中运行多种不同的作业时,设置合适的优先级变得非常复杂。响应时间不确定:由于资源是动态分配的,且资源不是完全隔离的,对于查询业务,其响应时间可能因其他作业(如批处理)的影响而变得不可预测。 |
读写分离能力介绍
为了克服上述局限性,ArgoDB 的读写分离功能提供了一种全新的解决方案,您可以在统一的存储基础上划分出多个逻辑上独立的集群,专注于各自的业务,实现存储和计算资源的隔离。例如,我们可以单独为查询业务划分出只读集群中,该集群中仅存储表的副本数据,同时按需分配计算资源,从而保证日常的批处理业务和查询业务能够高效、无干扰地运行。
图. 数据工作区示例
数据一致性与高可用性
基于Raft一致性协议,读写分离能力提供了高度一致和可靠的数据同步机制,确保业务连续性和数据完整性,同时为集群扩展提供了无缝支持。
Raft协议算法剖析与详解: https://community.transwarp.cn/article/956
全面资源隔离
通过逻辑主备集群的划分,实现了计算和存储资源的完全隔离,使得批处理和查询业务能够在最适宜的环境下运行,提高了系统的整体效率。
业务隔离与性能优化
可分别为批处理和查询业务分配了专门的逻辑集群,基于业务需求优化执行引擎和参数设定,实现了业务逻辑的隔离和性能的最大化。
减少数据流转成本
只读集群作为 Follower 只同步必要的数据变更,大幅减少了数据流转所需的时间和存储成本,提升了数据时效性。
操作流程
本案例中,某企业为了适应业务需求的增长并优化系统性能,需要将现行的 4 节点集群扩展至 8 节点。同时,需要在此基础上进一步细化资源分配,以便更好地适应各类业务的具体需求:
图. 集群扩容与多数据工作区示例
- 已有节点:继续支持全天候的批处理业务,将配备适中的计算和内存资源,确保稳定运行而无需过量的资源投入。
- 新增节点:主要服务于高并发查询业务,这些节点将搭载高性能处理器和更多容量的内存,并将其与执行批处理任务的节点进行资源隔离,避免查询操作不会受到长时间运行的批处理作业的资源争夺影响。
通过这种配置,我们保障了业务的连续性和查询的响应性,同时实现了成本效益的平衡。批处理节点和查询节点能够在为它们量身定制的环境中高效执行,确保了整个集群的性能最优化。
如需基于集群的已有节点设置读写分离集群,您需要将相关节点上的 TDDMS 服务执行缩容,随后重新扩容以实现数据分片的角色重分布,具体操作可参考《故障排查手册》中的更换硬盘章节。您也可以联系星环科技,由专业的技术团队详细评估您的需求并提供解决方案。
1. 登录 Transwarp Manager 平台,完成添加节点的操作。
具体操作,见添加节点。
2. 为新节点添加 TDDMS Tablet Server 角色服务,为后续同步主集群的表副本数据提供基础能力。
a. 在左侧导航栏,选择仪表盘 > 集群。
b. 在 Transwarp ArgoDB 区域,单击 TDDMS 服务卡片。
c. 在角色页签,单击添加角色并单击下一步。
d. 在左侧的服务列表,选择 TDDMS Tablet Server 角色,然后为其分配新节点并单击下一步。
图. 分片角色
e. 在基础参数标签页,下翻找到配置项 topology.topology.datacenter,单击编辑,然后为新增的角色定义一个具有业务意义的值,例如 OLAP(代表用于 OLAP 查询)。
图. 修改参数
f. 单击下一步,选择是否立即重启 TDDMS 的关联服务,包括 Quark、 Compact Service、Slipstream(如有)。
图. 是否重启相关服务
为避免影响业务运行,您也可以不选中立即重启受影响的的服务,稍后在合适的时间(例如业务低峰期)手动重启相关服务。
3. 为新节点添加 Quark、Compact Service 服务,用于为只读集群提供查询能力。
具体操作流程,见添加服务。
在部署服务时,各服务的角色应分配在只读集群所属的节点中,从而实现计算资源与主集群的完全隔离。
4. 创建表,通过表属性的设置来控制表的副本在各集群中的分布。
更多关于建表语法的介绍,见创建表。
CREATE TABLE demotable (
`eid` STRING DEFAULT NULL,
`funds` FLOAT DEFAULT NULL,
`username` STRING DEFAULT NULL
)
STORED AS holodesk
TBLPROPERTIES (
'data.center' = 'DEFAULT',
'disaster.preparedness.enabled' = 'true',
'dc.affinity.enabled' = 'true'
);- data.center:指定主集群,默认为 DEFAULT。
- disaster.preparedness.enabled:是否开启跨逻辑集群的高可用能力,即表副本可分布至只读集群,默认为 false,需设置为 true。
- dc.affinity.enabled:是否开启主集群的数据亲和性,默认为 false,设置为 true 后,ArgoDB 会将数据分片的 Leader 角色自动分配或迁移到主集群,从而实现读写分离的效果,即只读集群仅承担数据分片的 Follower 角色以对外提供读服务。
-- 除在建表时设置外,您也可以对已有表通过修改表属性的方法来实现,格式为 ALTER TABLE table_name SET TBLPROPERTIES ('property_name'= 'property_value'),例如 ALTER TABLE demotable SET TBLPROPERTIES ('data.center'= 'DEFAULT')。
-- 修改已有表可能触发数据分片角色的自动迁移,迁移的完成时间受数据规模、任务负载等因素综合影响。您可以通过 TDDMS 管理页面查看表的角色分布(定期刷新),如未及时更新,您也可以执行 curl -XPOST "{TDDMS 服务地址}:4567/cluster/gc 格式的命令来手动刷新角色分布信息。
5. 通过 TDDMS 查看数据分片的角色分布。
a. 登录 Transwarp Manager 平台。
b. 选择仪表盘 > 集群,然后单击 Transwarp ArgoDB 区域中的 TDDMS 服务卡片。
c. 在角色标签页,找到并单击 TDDMS Webserver 对应的服务链接。
图. 获取服务链接
d. 在跳转到的页面,完成登录,默认账密为 shiva。
e. 单击 Tables 标签页,搜索并单击名称前缀为刚刚创建的表(包含库名),本案例中的库名和表名的组合为 multi_dc.demotable。
图. 查找表
f. 在跳转到的 Tablets 页面,可以查看到角色的分布信息,如下图所示 demotable 共有 8 个数据分片,每个数据分片包含 3 个副本,分别是 1 个 Leader,2 个 Follower,从而保障数据的高可用。
图. 角色分布
| 类别 | 节点 | 说明 |
|---|---|---|
| 主集群DEFAULT | iqa15 ~ iqa18 | 存放每个分片的 1 个 Leader 和 1 个 Follower 角色,保障数据高可用,提供对外的数据读写能力。 |
| 只读集群OLAP | vqa-71 ~ vqa74 | 仅存放每个分片的 1 个 Follower 角色,提供对外的数据只读能力。 |
类别 节点 说明
此时,通过数据分片的分布可以看出,我们通过单个 TDDMS 实现了逻辑层面的读写分离能力,我们可以基于业务特性为不同的逻辑集群定制分配不同的计算资源,更好地提高资源利用率,契合业务需求。
6. 安装只读集群对应的 Qurak 服务,在执行安装时,依赖已有的 TDDMS 服务并将对应的 Executor 分布在只读集群对应的节点上。
7. (可选)通过 Quark Gateway 组件,实现基于用户或规则的分流,让批处理业务和 OLAP 查询业务分别自动分配至相应的 Quark 服务上。
具体配置方法和案例介绍,见 Quark Gateway 使用手册。
除此以外,为更好地发挥性能,连接数据库后,推荐执行 set argodb.prefer.same.data.center.enabled = true (默认为 false),从而优先读取相同同逻辑集群的数据,避免跨逻辑集群读取数据,此功能仅支持 local 模式和 localfast 模式。关于模式的更多介绍,见附录章节中的SQL 执行模式说明。
 登录后可评论
登录后可评论








.jpg)



