入门教程 | Hyperbase交互方式,以及Hyperbase表、Hyperdrive表的区别、创建语法使用
友情链接:
- Hyperbase手册
- Hyperbase安装视频
- 社区版下载地址
- 企业版申请试用
- Transwarp HyperBase 运行模式解答(cluster/local)
- Hyperbase基本用法(Hbase Shell)
- Hyperbase介绍以及在日常监测管理系统场景中的应用实践
- 更多资源汇总及问题指南链接
本篇内容仅展示快速上手所使用的部分SQL命令,并以银行客户信息表为场景介绍Hyperbase中的SQL快速入门使用方法,不代表Hyperbase仅支持该部分命令。如需查看完整详细的操作语句及参数说明请查看《Hyperbase使用手册》。
Hyperbase基础
Transwarp HyperbaseNoSQL宽表数据库是一个具有高可靠,高性能,可伸缩,实时读写,并且面向列的一个分布式NewSQL数据库,其既具有NoSQL数据库的海量数据存储管理能力,同时又继承了关系型数据库的SQL特性,列式存储的特性使得了其对Schema限制很少,可以自由添加列,适合存储海量的半结构化数据。
Hyperbase同时也是一个Key-Value数据库,按Key的字典序顺序存储,主要通过Key实现数据的增删改查以及扫库操作。Hyperbas采用HDFS为文件存储系统,可以高效的支持各类如批处理应用、全局搜索或高并发图形数据库检索应用等等。
注意,社区版用户需要确保已经上传并安装好Hyperbase的产品包,并申请了对应的许可证 (TDH基础安装包安装完成后申请的许可证内不含有Hyperbase的许可证,因此,社区版用户需要在新上传其他子产品后再次执行申请许可证的步骤方可生成对应产品的许可证)
Hyperbase安装视频
Hyperbase管理页面
打开 Hyperbase Active Master 管理页面的方法有两种:
A)根据集群的active master的ip地址打开: http://master_node_ip:60010 。如下图
B)通过 TDH 管理页面中 Hyperbase 服务的 HMaster 的 Service Link 打开,详细流程如下:
- Transwarp Data Hub WEB 管理页面也要根据集群的 Active Master 的 IP 地址打开,地址一般是 http://master_node_ip:8180
- 打开对应的Hyperbase服务的 Roles 页面。如下图:
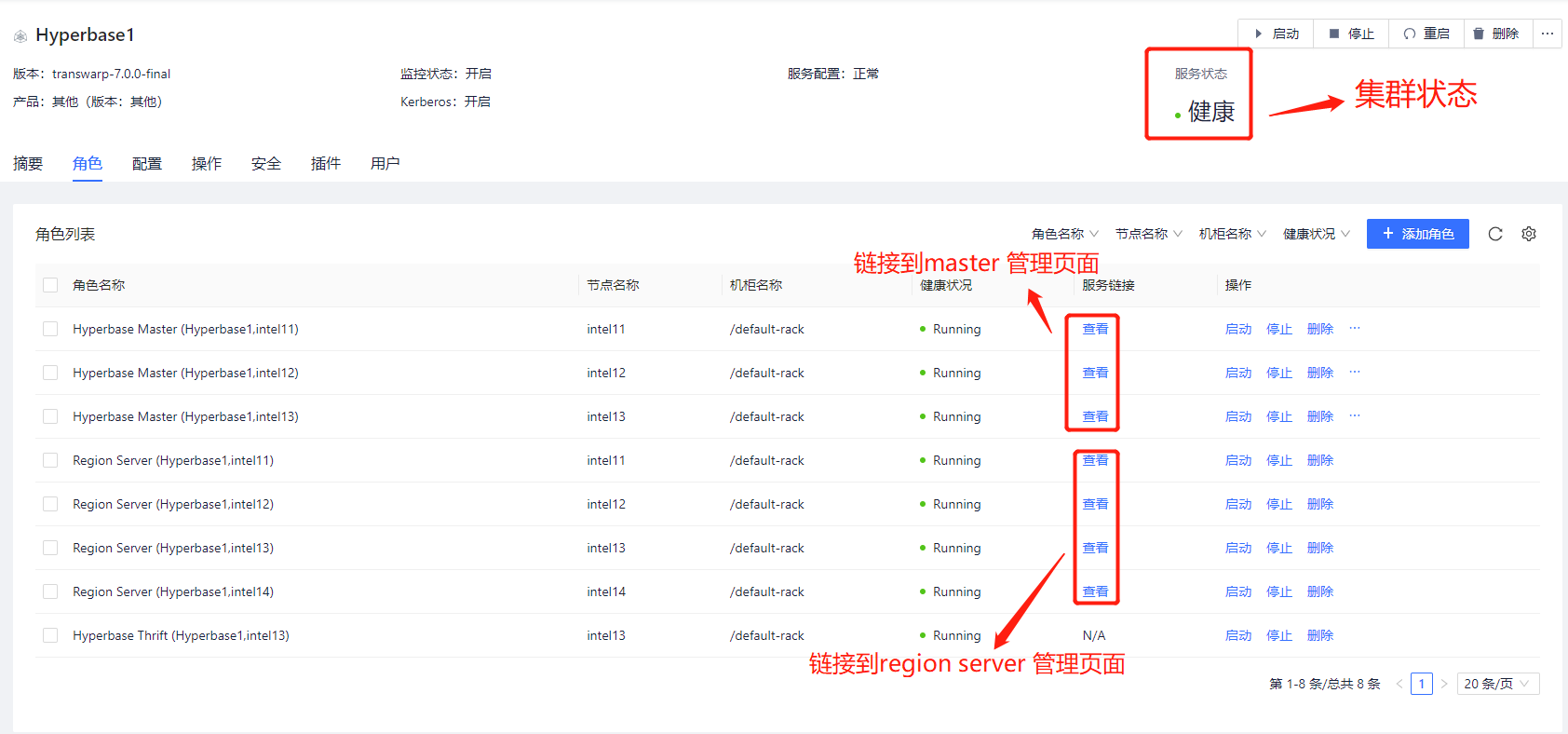
页面左上角服务名后的圆点颜色表示集群中的 Hyperbase 服务的状态,比如当前是绿色的 Green(HEALTHY) ,健康状态。另两种状态是 Yellow(WARNING) 和 Red(DOWN)。
通过每个 HMaster 对应的 Service Link 可以打开 HMaster 管理页面。如下图:
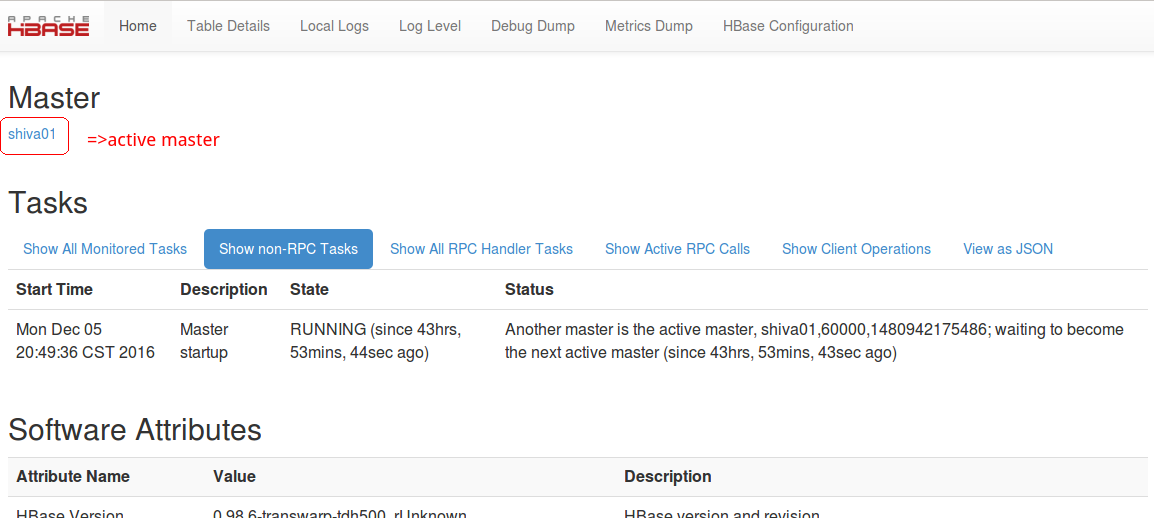
若打开的 Master 并非当前集群的 Active Master,可点击页面左上角 Master 下的 shiva01 的链接,即为 Active Master 的管理页面 。
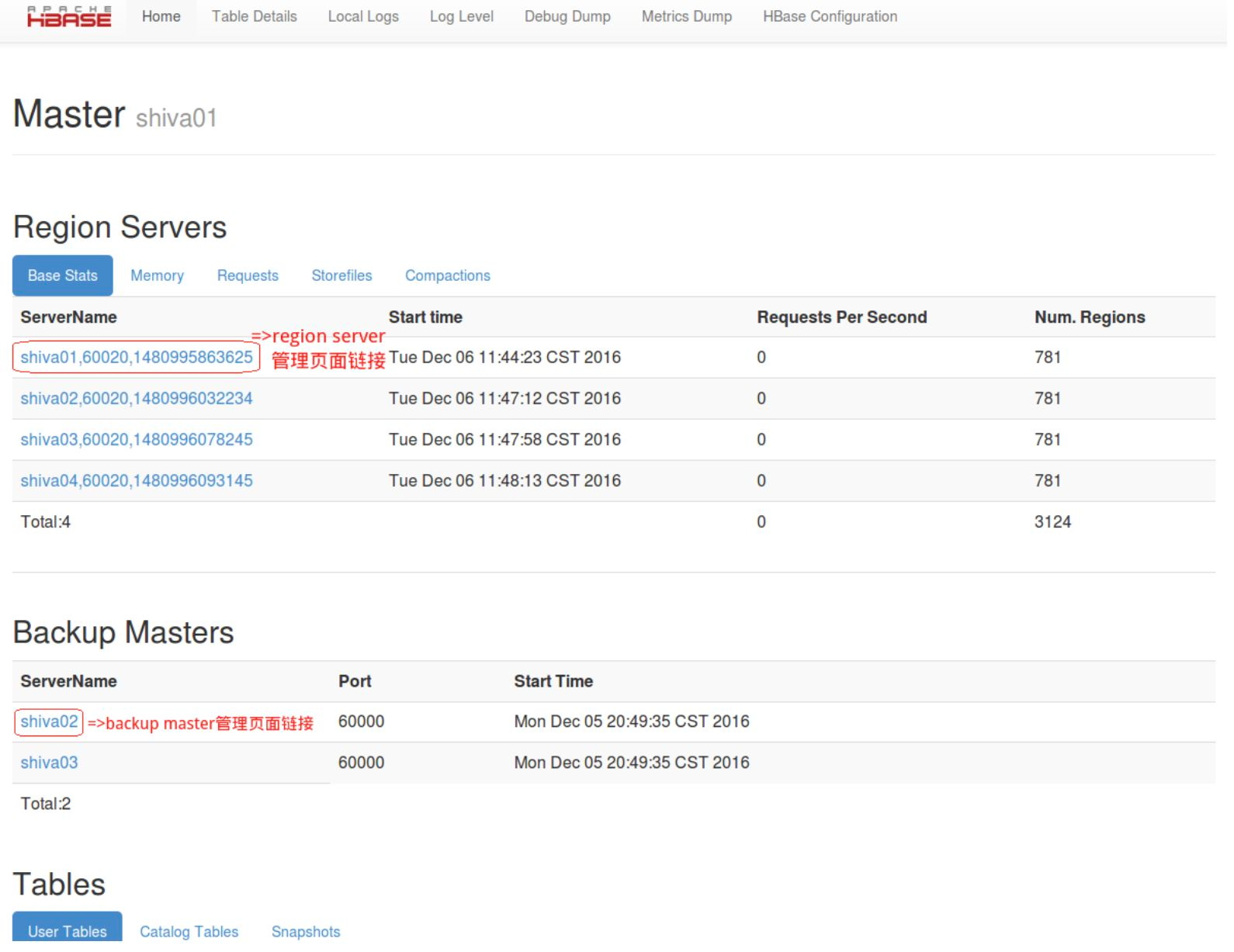
Active Master 的管理页面 主要包含 Region Servers, Backup Masters, Tables, Tasks 等相关信息。下面将主要介绍一些常见操作。
- Region Servers
Hyperbase 主页面的第一块区域包含 Hyperbase 集群的所有 Region Server 的信息: Base Stats, Memory, Requests, Storefiles, Compactions。
其中,每个 ServerName 的链接如 RegionServer shiva01,60020,1480995863625 ,对应相应 Region Server 的管理页面,可查看更详细的信息。
同样可以通过 Hyperbase 角色页面每个 Region Server 对应的 Service Link 都可以直接链接到对应 Server 的 Web 管理页面。
- Backup Masters
Hyperbase主页面的第一块区域包含Backup Masters的信息:ServerName, Port, Start Time等。打开ServerName下的链接可以链接到对应节点的管理页面,如 shiva02 管理页面。
- Tables
包含Hyperbase中所有的表:User Tables,Catalog Tables和Snapshots。这里将主要介绍User Tables和Catalog Tables中的hbase:meta表。
i) User Tables
包含Hyperbase中所有的用户表,并且可以查看表名,Region数目和表的元数据
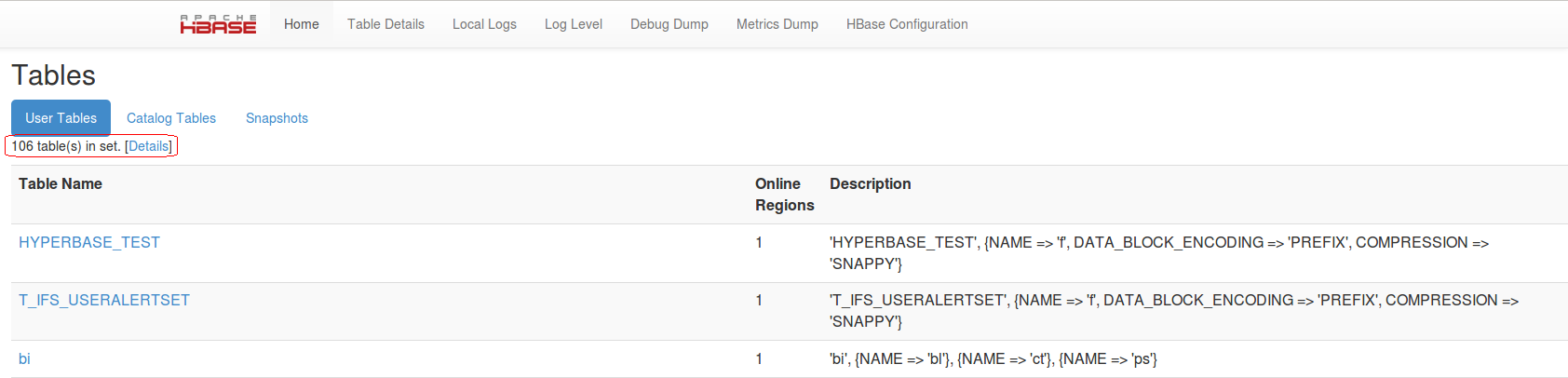
并且可以点击 Details 链接查看所有用户表的不同Region所在的Region Server,以及起止的Row Key。如下图:

ii) hbase:meta表
Catalog Tables中包含三个特殊的表:hbase:meta表,hbase:namespace表和hbase:snapshot表。如下图:
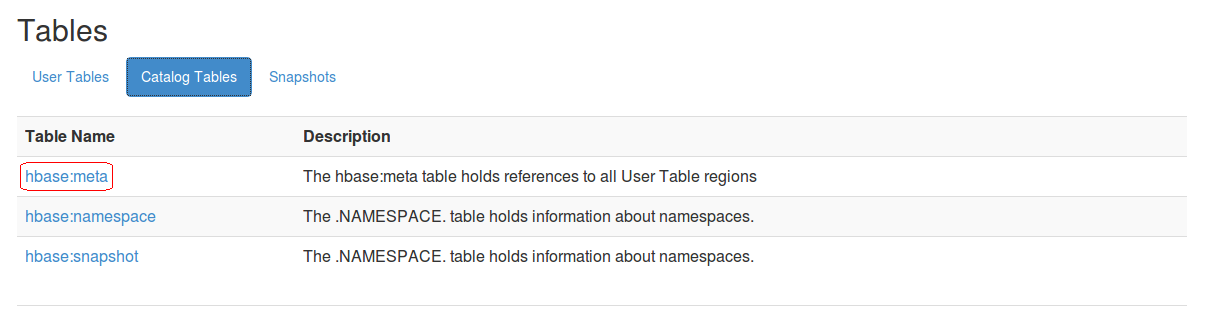
打开hbase:meta的链接如下图:

可以查看到hbase:meta表所在的Region Server是 shiva01:60030 ,以及一些其他相关信息。
和Hyperbase交互
和Hyperbase交互有以下三种方式:
1. SQL(推荐方式):
和Hyperbase交互推荐使用SQL,您在链接上Inceptor engine后即可使用SQL进行数据库操作。
我们的SQL引擎Inceptor Engine提供了丰富的SQL语法,并对SQL的执行进行了充分的优化,使用SQL和Hyperbase交互在正确性和性能方面都有很好的保证。 您可以在链接数据库以及SQL参考章节详细了解链接数据库的教程以及Inceptor支持的SQL语法。
2. Shell:
Hyperbase提供交互式Shell以及一系列Shell指令用于数据操作,细节请参考Hyperbase Shell命令。
a)在 Hyperbase Client 执行 hbase shell : Hyperbase Client 集成在 TDH-Client 中,需要执行以下命令(开安全)
source ./TDH-Client/init.sh
kinit -kt /etc/hypberase1/conf/hyperbase.keytab hbase/${hostname}
hbase shellb)在服务 pod 中执行 hbase shell (开安全):
kubectl exec -it hmasterPodName bash
export HBASE_OPTS="-Djava.security.auth.login.config=/etc/hyperbase1/conf/jaas.conf"
kinit -kt /etc/hyperbase1/conf/hyperbase.keytab hbase/${hostname}
hbase shell3. Java API:
Hyperbase支持Apache Hyperbase原生的API,同时还提供多种自有的API,细节请参考Hyperbase API使用说明。
Hyperbase表 跟 Hyperdrive表的对比及区别
Hyperbase支持创建两种格式的表 Hyperbase表 以及 Hyperdrive表,以下是他们的对比及区别。
| 表类 | Hyperbase表 | Hyperdrive表 |
|---|---|---|
| 背景 | 基于开源Hive HBaseStorageHandler研发 | 星环自主研发,更贴合Inceptor的设计,性能更优 |
| 优势 | 简单 | 优化语句、支持多种数据类型、数据存储压缩率高。详见下文 |
| 劣势 | 缺少Schema信息,一些SQL功能支持不好,无法做一些性能优化 | 附带Schema信息,直接操作底层Hyperbase表较复杂 |
| 适用场景 | Inceptor对接Hyperbase外表 | Inceptor建内表 |
Hyperbase表
- Hyperbase表 基于开源Hive HBaseStorageHandler研发,本身设计比较简单,Hyperbase底层不存储表的Schema信息,数据的序列化反序列化依赖于上层Hive。这造成了很多功能和性能上的问题,例如:Null值与空字符串的区分,SQL执行计划的优化等。因此在与Inceptor配合使用的情况下不推荐使用Hyperbase表。只有一种场景比较适合:在Hyperbase中已存在一张表,需要通过Inceptor的外表功能进行对接。这样保证了Inceptor对原生Hyperbase表的访问功能。
Hyperdrive表
为了解决Hyperbase表的一些设计缺陷,星环科技自主研发了Hyperdrive表,去除了开源Hive HBaseStorageHandler的设计,并增加了新的功能,使其能更高效地通过Inceptor访问存储在Hyperbase中的数据。
- 在底层Hyperbase中加入表的Schema信息,数据存储压缩率更高,序列化/反序列化更高效。数据类型支持BOOLEAN、TINYINT、SMALLINT、INTEGER、BIGINT、DATE、TIMESTAMP、DECIMAL、FLOAT、DOUBLE、STRING、VARCHAR、STRUCT、BINARY等多种类型。
- 对接Inceptor通用的存储访问层Stargate,可以支持完整的Filter转换下推、Global Lookup Join等特性,显著提升SQL性能。
- Elasticsearch语法对接,不需要再使用以前的那套contains语句了,直接使用现有的条件即可。=、<、>、in、like、between and、not in、!=等对应的语句即可。
- 可以通过指定使用索引的方式使用对应的索引(i.e. hint)
- 支持 NULL值占位符,可正确表达NULL值
- 对接HUE
其他通用功能
Hyperbase表和Hyperdrive表均具备以下星环科技自研功能:
- 多种索引实现
- 支持全局、局部、高维索引和高级过滤器,可用于高并发低延时的OLAP查询。并可以自动利用索引加速数据检索,无需显式的指定索引。
- 超高并发CRUD
- 支持超高并发的查询业务,满足上百万用户的高并发查询需求,从百亿历史数据中找到精确结果,并在毫秒级内返回查询结果。同时支持超高并发的插入/修改/删除操作,实现高速的数据入库。
- 非结构化数据的支持
- 支持文档型数据(如JSON/BSON/XML)的存储、索引和搜索。
- 完备的工具库
- 自带如SQL Bulkload等数据迁移工具和DSTool等一键修复集群的工具,极大降低运维成本。
Hyperbase SQL 使用说明
Hyperbase SQL 分为DDL、index DDL、DML和DQL四部分。本章节将以银行客户信息表为例介绍Hyperbase SQL 的建表、建索引、插入数据和数据查询等基本操作。其他详细操作请参考《Hyperbase使用手册》。
快速创建Hyperbase数据表
由前文介绍可知,hbase表有内外表之分,两者的建表语句也存在一定的差别,下面将分别介绍:
创建内表:CREATE TABLE
语法. 建hyperbase内表
CREATE TABLE <tableName> (
<key> <data_type>,
<column> <data_type>,
<column> <data_type>,
...
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' --[1]
[WITH SERDEPROPERTIES('hbase.columns.mapping'=':key,<f1:c1>,<f1:c2>,...')] --[2]
[TBLPROPERTIES ("hbase.table.name"="<hbase_table>")]; --[3]- 选项1: 指定表使用的Storage Handler。建Hyperbase表的固定写法;
- 可选项2: 推荐使用默认映射关系;
- 可选项3: 推荐使用默认值即tableName;
为帮助您更好的理解Hyperbase内表,下面我们将通过建Hyperbase内表语法创建一张银行客户信息内表
示例. 创建了一张名为hbase_inner_table的内表,存储格式为HBaseStorageHandler
create table hbase_inner_table(
key1 string,
name string,
password string,
email string,
cellphone string,
balance double
)STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler';Hyperbase表支持的数据类型
BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, DATE, TIMESTAMP, FLOAT, DOUBLE, STRING, VARCHAR, DECIMAL 和 STRUCT。
所有数据类型映射在实际 Hyperbase 表中的类型都是 byte[]。
具体数据类型的相关介绍请参考Inceptor支持的数据类型。
查看元数据信息
建表后可通过 DESCRIBE FORMATTED 查看 hbase_inner_table 的元数据信息,确认是否创建成功。如下:
describe formatted hbase_inner_table;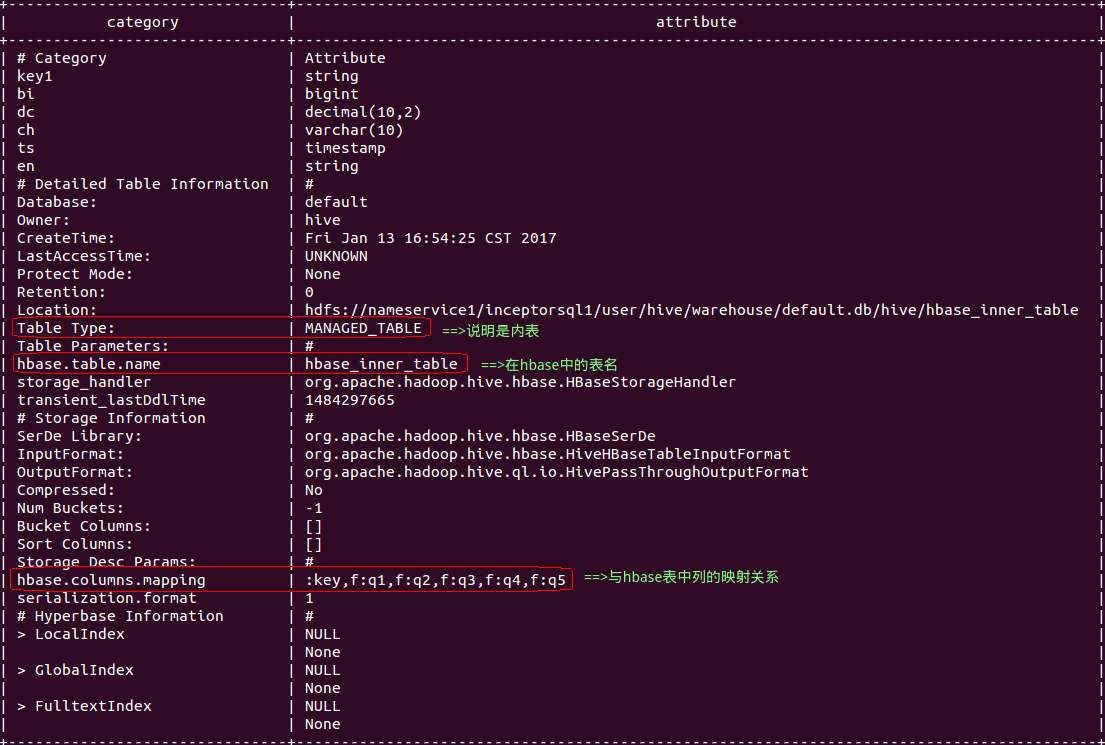
由上图可见,hbase_inner_table表的列名、数据类型、映射关系等等。
创建外表:CREATE EXTERNAL TABLE
语法. 建hyperbase外表
CREATE EXTERNAL TABLE <tableName> (
<key> <data_type>,
<column> <data_type>,
<column> <data_type>,
...
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES('hbase.columns.mapping'=':key,<f:q1>,<f:q2>,...') --[1]
TBLPROPERTIES ("hbase.table.name"="<hbase_table>"); --[2]- 必选项1: 建外表时必须定义映射表和Hyperbase表列之间的映射关系。映射表第一项 :key 为固定写法,剩余项为 <column_family>:<column_qualifier> 的自定义组合;
- 必选项2:TBLPROPERTIES 中的 hbase.table.name 属性定义映射表对应的Hyperbase表的表名。 hbase_table 必须为Hyperbase中一个已存在的表名;
示例. 建Hyperbase外表
CREATE EXTERNAL TABLE hbase_external_table(
key1 string,
ex1 double,
ex3 date,
ex5 string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,f:q1,f:q4,f:q5") --[1]
TBLPROPERTIES ("hbase.table.name"="test.hbase_inner_table"); --[2]- 选项1: 指定外表 hbase_external_table 中的列与源表的映射关系。映射时数据类型强行转换,转换失败则为NULL。
- 选项2: hbase_external_table 和已存在的 hbase_inner_table 表的列映射关系。
查看元数据信息
建表后可通过 DESCRIBE FORMATTED 查看 hbase_inner_table 的元数据信息,确认是否创建成功。如下:
describe formatted hbase_external_table;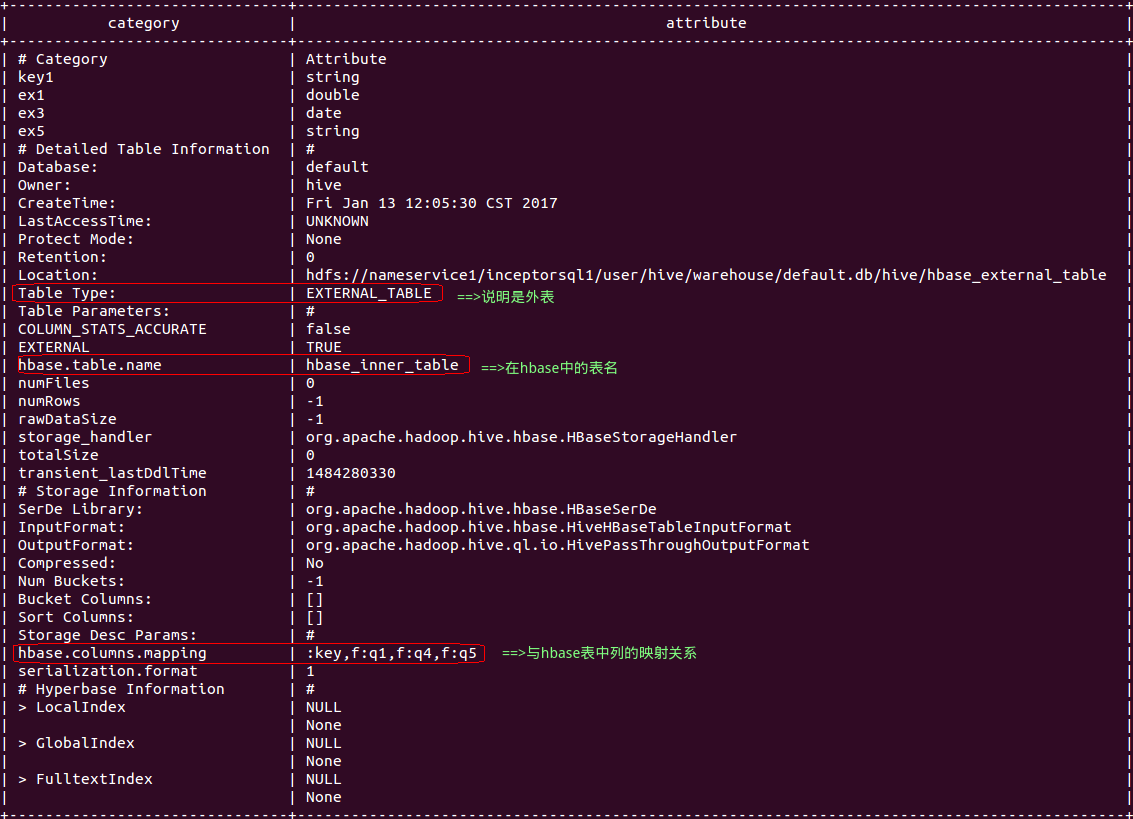
由上图可见,hbase_external_table表的列名、数据类型、映射关系等等。
Hyperbase SQL 索引操作
Hyperbase SQL的Index DDL支持创建和删除表的全局索引和全文索引,包括:
创建索引:CREATE INDEX
- 创建全局索引: CREATE GLOBAL INDEX
- 创建全文索引: CREATE FULLTEXT INDEX
删除索引:DROP INDEX
- 删除全局索引: DROP GLOBAL INDEX
- 删除全文索引: DROP FULLTEXT INDEX
创建索引:CREATE INDEX
Hyperbase表只支持创建全局索引(GLOBAL INDEX) 和全文索引(FULLTEXT INDEX),下面将分别介绍。
创建全局索引:CREATE GLOBAL INDEX
语法. 为Hyperbase表建全局索引
CREATE GLOBAL INDEX <index_name> ON <tableName> (
<column1> <SEGMENT LENGTH length1>|<(length1)> --[1]
[,<column2> <SEGMENT LENGTH length2>|<(length2)>,...] --[2]
);- 选项1- column1:指根据哪个列建全局索引,可以有多个列,但不可包含首列(因该列映射为RowKey)。
- 选项2- SEGMENT LENGTH length1:每个列在索引词条中所占字段的长度,可简写为 (length1) 。注意,简写必须有括号 。建议SEGMENT LENGTH 的设定最好大于等于字段的实际长度。
示例. 为内表创建全局索引
--根据name列创建一个名为name_global的全局索引,并指定该索引字段长度为10
CREATE GLOBAL INDEX name_global ON hbase_inner_table(name(10));创建全文索引:CREATE FULLTEXT INDEX
语法. 为Hyperbase表建全文索引
CREATE FULLTEXT INDEX ON <tableName> ( --[1]
<column1> [DOCVALUES <TRUE|FALSE>] --[2]
[,<column2> [DOCVALUES <TRUE|FALSE>],...] --[3]
)SHARD NUM <n>; --[4]- 选项1:一张表只能有 一个全文索引 ,所以建全文索引无须指定索引名
- 选项2:任意 column1 的数据类型不可以是:decimal,date,timestamp,会报错。且同样不可包含首列。
- 选项3:DOCVALUES 是一个优化查询的开关,推荐使用默认值打开(TRUE)。
- 选项4:SHARD NUM 指定全文索引的分片数,分片数只能在创建时指定,不可修改,需要用户预估索引数据的数量,一个SHARD上的数据不要超过25G。
示例. 为内表创建全文索引
--为内表hbase_inner_table根据列name、balance来创建全文索引
CREATE FULLTEXT INDEX ON hbase_inner_table(name,balance) SHARD NUM 1;删除索引
删除全局索引:DROP INDEX
因一张表可以有多个全局索引,所以需要指定索引名:index_name
语法
DROP INDEX [IF EXISTS] <index_name> ON <tableName>;示例
DROP INDEX name_global ON hbase_inner_table;删除全文索引:DROP FULLTEXT INDEX
因一张表只有一个全文索引,所以只需指定表名
语法
DROP FULLTEXT INDEX [IF EXISTS] ON <tableName>;Hyperbase SQL DML 操作
Hyperbase SQL中的DML(Data Manipulation Language)包括:
- 插入数据:INSERT
- 更新数据:UPDATE
- 删除数据:DELETE
下面将一一介绍。
插入数据
Hyperbase SQL 支持向Hyperbase表中单条插入数据或者批量插入查询结果。
单条插入数据
单条插入数据语法一次只可插入一条记录,具体语法如下:
语法
INSERT INTO TABLE <tableName> [(<column1>, <column2>, ...)] VALUES (<value1>, <value2>, ...);示例. 向hbase_inner_table表中单条插入数据
INSERT INTO TABLE hbase_inner_table VALUES ('1','Alice','Alice123','Alice@126.com', '12341234123', 10000.0);
INSERT INTO TABLE hbase_inner_table VALUES ('2','Bob','Bob123','Bob@126.com','13571357135', 20000.0);批量插入数据
不同于单条插入语法一次只能插入一条记录,批量插入语法可一次性插入任意多条记录。具体语法如下:
语法
BATCHINSERT INTO <tableName> [(<column1>, <column2>, ...)] BATCHVALUES(VALUES(<value1>, <value2>, ...), VALUES(<value1>, <value2>,...),...);- (<column1>, <column2>, …)可选,在插入数据时如果每列都会插入数据,则可以不指定插入的数据列名。
示例. 向hbase_inner_table表中批量插入数据
BATCHINSERT INTO hbase_inner_table BATCHVALUES (
VALUES('3','Carol','Carol123','Carol@126.com','12345234523', 30000.0),
VALUES('4','Derek','Derek123','Derek@126.com','13456345634', 40000.0));示例. 查看hbase_inner_table表中数据
select * from hbase_inner_table;
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
| 2 | Bob | Bob123 | Bob@126.com | 13571357135 | 20000.0 |
| 3 | Carol | Carol123 | Carol@126.com | 12345234523 | 30000.0 |
| 4 | Derek | Derek123 | Derek@126.com | 13456345634 | 40000.0 |
+-----+-------+----------+---------------+-------------+---------+并且,从hbase_external_table中也可以查询到上述数据,因两者映射Hyperbase中的同一张表。
更新数据
数据插入后可以通过UPDATE语法来更新数据
语法
UPDATE <tableName> SET <column> = <value> WHERE <filter_conditions>;示例. 更新满足过滤条件filter_conditions的记录
UPDATE hbase_inner_table SET balance = 50000.0 WHERE name = 'Carol';删除记录
数据插入后可以通过DELETE语句来删除数据
语法
DELETE FROM <tableName> WHERE <filter_conditions>;示例. 删除满足过滤条件filter_conditions的记录
DELETE FROM hbase_inner_table WHERE key1 = '4';Hyperbase SQL DQL 操作
指定索引查询模式
指定全局索引和全文索引进行查询,只有在 local mode 下才会生效,该模式的参数设置如下:
设置local mode
set ngmr.exec.mode = local;该参数设置完成后才能利用索引进行有效的查询。
下面我们分别介绍对hyperbase映射表指定全局索引和全文索引进行查询的语法。而全局索引和全文索引如何创建请参考前文的介绍。
指定全局索引查询Hyperbase表
语法
SELECT /*+USE_INDEX(<table_alias> USING <index_name>)*/... --[1]
FROM <tableName> <table_alias> --[2]
WHERE <filter_conditions>; --[3]- ./+USE_INDEX(<table_alias> USING <index_name>)/为指定索引的提示,在提示内必须使用表的化名 table_alias
- 必须为表起化名
- filter_conditions:过滤条件中至少含一个使用的索引中的列
下面将以前文创建的全局索引name_global举例如何查询。
例:用全局索引name_global查询姓名为Alice的用户信息
SELECT /*+USE_INDEX(t USING name_global)*/ * FROM hbase_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+指明不使用全局索引查询
若用户想对含全局索引的表做普通的查询时,需明确指定不使用任何索引
具体语法如下:
SELECT /*+USE_INDEX(<table_alias> USING NOT_USE_INDEX)*/ ... FROM <tableName> <table_alias> WHERE <filter_condition>;例:不使用全局索引name_global查询姓名为Alice的用户信息
SELECT /*+USE_INDEX(t USING NOT_USE_INDEx)*/ * FROM hbase_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+指定全文索引查询
Hyperbase表的全文索引通过CONTAINS函数使用,目前支持精准匹配,前缀查询,模糊查询和范围查询四种语义,支持检索条件的逻辑组合。
语法
SELECT ... FROM <tableName>
WHERE CONTAINS (<column>, "<fulltext_query>") --[1]
[AND|OR CONTAINS(<column>, "<fulltext_query>") AND|OR CONTAINS(<column>, "<fulltext_query>")...]; --[2]- 选项1:CONTAINS 函数需要两个参数:列名<column>和检索表达式"<fulltext_query>"(注意,检索条件要放在双引号中),且两者是一一匹配的。
- 选项2:CONTAINS 中包含全文检索条件,一次查询中可以使用多个CONTAINS,之间用AND或者OR连接。
- CONTAINS函数中的检索表达式"<fulltext_query>"需要有如下形式:
"<operator> '<search_contents>' [and|or <operator> '<search_contents>' and|or <operator> '<search_contents>'...]"其中,<operator> 为全文检索运算符, '<search_contents>' 为检索内容(注意单引号)。一个全文检索条件可以由多个 <operator> <search_contents> 组成,之间用 and 或 or 连接。 全文检索操作符<OPERATOR>包括:
| 操作符 | 支持的数据类型 | |
|---|---|---|
| 精确匹配 | term | 所有数据类型 |
| 前缀查询 | prefix | STRING类型 |
| 正则表达式 | regexp | STRING类型 |
| 模糊查询 | wildcard | STRING类型 |
| 全文搜索 | match | STRING类型 |
| in查询 | in | 所有数据类型 |
| 范围查询 | range | 所有数据类型 |
| > | 所有数据类型 | |
| < | 所有数据类型 | |
| >= | 所有数据类型 | |
| <= | 所有数据类型 |
下面给出几个具体事例。
a. 示例. 精确匹配(term)查询name列的值精确等于Alice的记录
select * from hbase_inner_table where contains(name, "term 'Alice'");
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+a. 示例. 范围表达式(range)查询balance列的值满足[10000,30000)的记录
select * from hbase_inner_table where contains(balance, "range '[10000,30000)'");
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
| 2 | Bob | Bob123 | Bob@126.com | 13571357135 | 20000.0 |
+-----+-------+----------+---------------+-------------+---------+Hyperdrive SQL 使用说明
Hyperdrive SQL 分为DDL、index DDL、DML和DQL四部分。 本章节将以银行信息表为例介绍Hyperdrive SQL 的建表、建索引、插入数据和数据查询等基本操作。其他详细操作请参考《Hyperbase使用手册》
快速创建Hyperdrive 数据表
创建内表:CREATE TABLE
语法
建Hyperdrive我们推荐使用较简单的方法。
CREATE TABLE <tableName> (
<key> <data_type>,
<column> <data_type>,
<column> <data_type>,
...
)
STORED AS HYPERDRIVE; --[1]
- 选项1:指定存储格式。建Hyperdrive表的简化写法
Hyperdrive表支持的数据类型包括: BOOLEAN、 TINYINT、 SMALLINT、 INTEGER、 BIGINT、 DATE、 TIMESTAMP、 DECIMAL、 FLOAT、 DOUBLE、 STRING、 VARCHAR和STRUCT,有自己的编码和解码方式,解决了 NULL 等特殊类型在Hyperbase中的表示。
示例. 建Hyperdrive内表
create table hd_inner_table(
key1 string,
name string,
password string,
email string,
cellphone string,
balance double
)STORED AS HYPERDRIVE;查看元数据信息
建表后可通过 DESCRIBE FORMATTED 查看 hd_inner_table 的元数据信息,确认是否创建成功。如下:
describe formatted hd_inner_table;因外表众多功能无法实现,不推荐建Hyperdrive外表。
Hyperdrive SQL 索引
索引相关的DDL语法包括创建和删除hyperdrive表的全局索引和全文索引:
创建索引:CREATE INDEX
- 创建全局索引: CREATE GLOBAL INDEX
- 创建全文索引: CREATE FULLTEXT INDEX
删除索引:DROP INDEX
- 删除全局索引: DROP GLOBAL INDEX
- 删除全文索引: DROP FULLTEXT INDEX
下面将具体介绍创建和删除索引的语法。
创建索引
创建全局索引: CREATE GLOBAL INDEX
语法
CREATE GLOBAL INDEX <index_name> ON <tableName> (
<column1> [SEGMENT LENGTH length1]|[(length1)] --[1]
[,<column2> [SEGMENT LENGTH length2]|[(length2)],...] --[2]
);- 选项1 - column1 :指根据哪个列建全局索引,可以有多个列,但不可包含首列(因该列映射为RowKey)。
- 选项2 - SEGMENT LENGTH length1 :只有string类型列需要指定字段长度,可简写为 (length1) 。注意简写必须有 () 。用STRING类型列创建全局索引时要指定字段长度。一个字段的SEGMENT LENGTH 的设定最好大于等于字段的实际长度。
下面将以hd_inner_table表为例,创建全局索引。
示例. 为内表hd_inner_table创建全局索引
CREATE GLOBAL INDEX name_balance_global_index ON hd_inner_table(name(10), balance);
-- 因列name是string类型,因此需要指定长度创建全文索引: CREATE FULLTEXT INDEX
语法
CREATE FULLTEXT INDEX ON <tableName> ( --[1]
<column1> [DOCVALUES <TRUE|FALSE>] --[2]
[,<column2> [DOCVALUES <TRUE|FALSE>],...] --[3]
)SHARD NUM <n>; --[4]- 选项1:一张表只能有 一个全文索引 ,所以建全文索引无须指定索引名。
- 选项2:任意 column1 的数据类型不可以是:decimal,date,timestamp,会报错。且同样不可包含首列。
- 选项3:DOCVALUES 是一个优化查询的开关,推荐使用默认打开(TRUE)。
- 选项4:SHARD NUM 指定全文索引的分片数,分片数只能在创建时指定,不可修改,需要用户预估索引数据的数量,一个SHARD上的数据不要超过25G。
示例. 为内表创建全文索引
CREATE FULLTEXT INDEX ON hd_inner_table(name,balance) SHARD NUM 1;
--为内表hd_inner_table根据列name、balance来创建全文索引,一个分片建全文索引无需指定STRING类型的字段长度
删除索引
删除全局索引:DROP INDEX
因一张表可以有多个全局索引,所以需要指定索引名:index_name。
语法
DROP INDEX [IF EXISTS] <index_name> ON <tableName>;示例
DROP INDEX name_balance_global_index ON hd_inner_table;
--删除创建的全局索引 name_balance_global_indexHyperdrive SQL DML
Hyperdrive SQL中的DML(Data Manipulation Language)包括:
- 插入数据:INSERT
- 更新数据:UPDATE
- 删除数据:DELETE
下面将一一介绍。
插入数据
Hyperdrive SQL 支持向Hyperbase表中单条插入数据或者批量插入查询结果。
单条插入数据
单条插入数据语法一次只可插入一条记录,具体如下:
语法
INSERT INTO TABLE <tableName> [(<column1>, <column2>, ...)] VALUES (<value1>, <value2>, ...);示例. 向hd_inner_table表中单条插入数据
INSERT INTO TABLE hd_inner_table VALUES ('1','Alice','Alice123','Alice@126.com', '12341234123', 10000.0);
INSERT INTO TABLE hd_inner_table VALUES ('2','Bob','Bob123','Bob@126.com','13571357135', 20000.0);批量插入数据
不同于单条插入语法一次只能插入一条记录,批量插入语法可一次性插入任意多条记录,具体如下:
语法
BATCHINSERT INTO <tableName> [(<column1>, <column2>, ...)] BATCHVALUES(VALUES(<value1>, <value2>, ...), VALUES(<value1>, <value2>,...),...);示例. 向hd_inner_table表中批量插入数据
BATCHINSERT INTO hd_inner_table BATCHVALUES (
VALUES('3','Carol','Carol123','Carol@126.com','12345234523', 30000.0),
VALUES('4','Derek','Derek123','Derek@126.com','13456345634', 40000.0));更新数据
数据插入后可以通过UPDATE语法来更新数据,具体如下:
语法
UPDATE <tableName> SET <column> = <value> WHERE <filter_conditions>;示例. 更新满足过滤条件filter_conditions的记录
UPDATE hd_inner_table SET balance = 50000.0 WHERE name = 'Carol';删除记录
数据插入后可以通过DELETE语句来删除数据,具体如下:
语法
DELETE FROM <tableName> WHERE <filter_conditions>;示例. 删除满足过滤条件filter_conditions的记录
DELETE FROM hd_inner_table WHERE key1 = '4';Hyperdrive SQL DQL
指定索引查询模式
指定全局索引和全文索引进行查询,只有在 local mode 下才会生效,该模式的参数设置如下:
设置local mode
set ngmr.exec.mode = local;该参数设置完成后才能利用索引进行有效的查询
指定索引查询Hyperdrive表
全局索引查询Hyperdrive表
语法
SELECT /*+USE_INDEX(<table_alias> USING <index_name>)*/... --[1]
FROM <tableName> <table_alias> --[2]
WHERE <filter_conditions>; --[3]- 选项1:/+USE_INDEX(<table_alias> USING <index_name>)/为指定索引的提示,在提示内必须使用表的化名 table_alias。
- 选项2:必须为表起化名
- 选项3:filter_conditions:过滤条件中至少含一个使用的索引中的列
示例. 指定全局索引查询内表hd_inner_table
SELECT /*+USE_INDEX(t USING name_balance_global_index)*/ * FROM hd_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+利用全局索引 name_balance_global_index 查询满足条件:t.name = 'Alice’的数据
使用索引查询时必须要给表起化名,并在指定索引时使用表化名。
明确不使用全局索引查询
语法
SELECT /*+USE_INDEX(<table_alias> USING NOT_USE_INDEX)*/ ... FROM <tableName> <table_alias> WHERE <filter_condition>;示例. 不使用全局索引进行查询
SELECT /*+USE_INDEX(t using NOT_USE_INDEX)*/ * FROM hd_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+明确不使用索引查询满足条件:t.name = 'Alice’的数据
指定全文索引查询
语法
SELECT /*+USE_INDEX(<table_alias> USING FULLTEXT)*/ ... FROM <table> <table_alias> WHERE <filter_conditions>;示例. 指定全文索引查询内表hd_inner_table
SELECT /*+USE_INDEX(t USING FULLTEXT)*/ * FROM hd_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+利用全文索引查询满足条件:t.name = 'Alice’的数据。
如果上述内容对您有提供帮助,欢迎多多点赞支持~😎


友情链接:
- Hyperbase手册
- Hyperbase安装视频
- 社区版下载地址
- 企业版申请试用
- Transwarp HyperBase 运行模式解答(cluster/local)
- Hyperbase基本用法(Hbase Shell)
- Hyperbase介绍以及在日常监测管理系统场景中的应用实践
- 更多资源汇总及问题指南链接
本篇内容仅展示快速上手所使用的部分SQL命令,并以银行客户信息表为场景介绍Hyperbase中的SQL快速入门使用方法,不代表Hyperbase仅支持该部分命令。如需查看完整详细的操作语句及参数说明请查看《Hyperbase使用手册》。
Hyperbase基础
Transwarp HyperbaseNoSQL宽表数据库是一个具有高可靠,高性能,可伸缩,实时读写,并且面向列的一个分布式NewSQL数据库,其既具有NoSQL数据库的海量数据存储管理能力,同时又继承了关系型数据库的SQL特性,列式存储的特性使得了其对Schema限制很少,可以自由添加列,适合存储海量的半结构化数据。
Hyperbase同时也是一个Key-Value数据库,按Key的字典序顺序存储,主要通过Key实现数据的增删改查以及扫库操作。Hyperbas采用HDFS为文件存储系统,可以高效的支持各类如批处理应用、全局搜索或高并发图形数据库检索应用等等。
注意,社区版用户需要确保已经上传并安装好Hyperbase的产品包,并申请了对应的许可证 (TDH基础安装包安装完成后申请的许可证内不含有Hyperbase的许可证,因此,社区版用户需要在新上传其他子产品后再次执行申请许可证的步骤方可生成对应产品的许可证)
Hyperbase安装视频
Hyperbase管理页面
打开 Hyperbase Active Master 管理页面的方法有两种:
A)根据集群的active master的ip地址打开: http://master_node_ip:60010 。如下图
B)通过 TDH 管理页面中 Hyperbase 服务的 HMaster 的 Service Link 打开,详细流程如下:
- Transwarp Data Hub WEB 管理页面也要根据集群的 Active Master 的 IP 地址打开,地址一般是 http://master_node_ip:8180
- 打开对应的Hyperbase服务的 Roles 页面。如下图:
页面左上角服务名后的圆点颜色表示集群中的 Hyperbase 服务的状态,比如当前是绿色的 Green(HEALTHY) ,健康状态。另两种状态是 Yellow(WARNING) 和 Red(DOWN)。
通过每个 HMaster 对应的 Service Link 可以打开 HMaster 管理页面。如下图:
若打开的 Master 并非当前集群的 Active Master,可点击页面左上角 Master 下的 shiva01 的链接,即为 Active Master 的管理页面 。
Active Master 的管理页面 主要包含 Region Servers, Backup Masters, Tables, Tasks 等相关信息。下面将主要介绍一些常见操作。
- Region Servers
Hyperbase 主页面的第一块区域包含 Hyperbase 集群的所有 Region Server 的信息: Base Stats, Memory, Requests, Storefiles, Compactions。
其中,每个 ServerName 的链接如 RegionServer shiva01,60020,1480995863625 ,对应相应 Region Server 的管理页面,可查看更详细的信息。
同样可以通过 Hyperbase 角色页面每个 Region Server 对应的 Service Link 都可以直接链接到对应 Server 的 Web 管理页面。
- Backup Masters
Hyperbase主页面的第一块区域包含Backup Masters的信息:ServerName, Port, Start Time等。打开ServerName下的链接可以链接到对应节点的管理页面,如 shiva02 管理页面。
- Tables
包含Hyperbase中所有的表:User Tables,Catalog Tables和Snapshots。这里将主要介绍User Tables和Catalog Tables中的hbase:meta表。
i) User Tables
包含Hyperbase中所有的用户表,并且可以查看表名,Region数目和表的元数据
并且可以点击 Details 链接查看所有用户表的不同Region所在的Region Server,以及起止的Row Key。如下图:
ii) hbase:meta表
Catalog Tables中包含三个特殊的表:hbase:meta表,hbase:namespace表和hbase:snapshot表。如下图:
打开hbase:meta的链接如下图:
可以查看到hbase:meta表所在的Region Server是 shiva01:60030 ,以及一些其他相关信息。
和Hyperbase交互
和Hyperbase交互有以下三种方式:
1. SQL(推荐方式):
和Hyperbase交互推荐使用SQL,您在链接上Inceptor engine后即可使用SQL进行数据库操作。
我们的SQL引擎Inceptor Engine提供了丰富的SQL语法,并对SQL的执行进行了充分的优化,使用SQL和Hyperbase交互在正确性和性能方面都有很好的保证。 您可以在链接数据库以及SQL参考章节详细了解链接数据库的教程以及Inceptor支持的SQL语法。
2. Shell:
Hyperbase提供交互式Shell以及一系列Shell指令用于数据操作,细节请参考Hyperbase Shell命令。
a)在 Hyperbase Client 执行 hbase shell : Hyperbase Client 集成在 TDH-Client 中,需要执行以下命令(开安全)
source ./TDH-Client/init.sh
kinit -kt /etc/hypberase1/conf/hyperbase.keytab hbase/${hostname}
hbase shellb)在服务 pod 中执行 hbase shell (开安全):
kubectl exec -it hmasterPodName bash
export HBASE_OPTS="-Djava.security.auth.login.config=/etc/hyperbase1/conf/jaas.conf"
kinit -kt /etc/hyperbase1/conf/hyperbase.keytab hbase/${hostname}
hbase shell3. Java API:
Hyperbase支持Apache Hyperbase原生的API,同时还提供多种自有的API,细节请参考Hyperbase API使用说明。
Hyperbase表 跟 Hyperdrive表的对比及区别
Hyperbase支持创建两种格式的表 Hyperbase表 以及 Hyperdrive表,以下是他们的对比及区别。
| 表类 | Hyperbase表 | Hyperdrive表 |
|---|---|---|
| 背景 | 基于开源Hive HBaseStorageHandler研发 | 星环自主研发,更贴合Inceptor的设计,性能更优 |
| 优势 | 简单 | 优化语句、支持多种数据类型、数据存储压缩率高。详见下文 |
| 劣势 | 缺少Schema信息,一些SQL功能支持不好,无法做一些性能优化 | 附带Schema信息,直接操作底层Hyperbase表较复杂 |
| 适用场景 | Inceptor对接Hyperbase外表 | Inceptor建内表 |
Hyperbase表
- Hyperbase表 基于开源Hive HBaseStorageHandler研发,本身设计比较简单,Hyperbase底层不存储表的Schema信息,数据的序列化反序列化依赖于上层Hive。这造成了很多功能和性能上的问题,例如:Null值与空字符串的区分,SQL执行计划的优化等。因此在与Inceptor配合使用的情况下不推荐使用Hyperbase表。只有一种场景比较适合:在Hyperbase中已存在一张表,需要通过Inceptor的外表功能进行对接。这样保证了Inceptor对原生Hyperbase表的访问功能。
Hyperdrive表
为了解决Hyperbase表的一些设计缺陷,星环科技自主研发了Hyperdrive表,去除了开源Hive HBaseStorageHandler的设计,并增加了新的功能,使其能更高效地通过Inceptor访问存储在Hyperbase中的数据。
- 在底层Hyperbase中加入表的Schema信息,数据存储压缩率更高,序列化/反序列化更高效。数据类型支持BOOLEAN、TINYINT、SMALLINT、INTEGER、BIGINT、DATE、TIMESTAMP、DECIMAL、FLOAT、DOUBLE、STRING、VARCHAR、STRUCT、BINARY等多种类型。
- 对接Inceptor通用的存储访问层Stargate,可以支持完整的Filter转换下推、Global Lookup Join等特性,显著提升SQL性能。
- Elasticsearch语法对接,不需要再使用以前的那套contains语句了,直接使用现有的条件即可。=、<、>、in、like、between and、not in、!=等对应的语句即可。
- 可以通过指定使用索引的方式使用对应的索引(i.e. hint)
- 支持 NULL值占位符,可正确表达NULL值
- 对接HUE
其他通用功能
Hyperbase表和Hyperdrive表均具备以下星环科技自研功能:
- 多种索引实现
- 支持全局、局部、高维索引和高级过滤器,可用于高并发低延时的OLAP查询。并可以自动利用索引加速数据检索,无需显式的指定索引。
- 超高并发CRUD
- 支持超高并发的查询业务,满足上百万用户的高并发查询需求,从百亿历史数据中找到精确结果,并在毫秒级内返回查询结果。同时支持超高并发的插入/修改/删除操作,实现高速的数据入库。
- 非结构化数据的支持
- 支持文档型数据(如JSON/BSON/XML)的存储、索引和搜索。
- 完备的工具库
- 自带如SQL Bulkload等数据迁移工具和DSTool等一键修复集群的工具,极大降低运维成本。
Hyperbase SQL 使用说明
Hyperbase SQL 分为DDL、index DDL、DML和DQL四部分。本章节将以银行客户信息表为例介绍Hyperbase SQL 的建表、建索引、插入数据和数据查询等基本操作。其他详细操作请参考《Hyperbase使用手册》。
快速创建Hyperbase数据表
由前文介绍可知,hbase表有内外表之分,两者的建表语句也存在一定的差别,下面将分别介绍:
创建内表:CREATE TABLE
语法. 建hyperbase内表
CREATE TABLE <tableName> (
<key> <data_type>,
<column> <data_type>,
<column> <data_type>,
...
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' --[1]
[WITH SERDEPROPERTIES('hbase.columns.mapping'=':key,<f1:c1>,<f1:c2>,...')] --[2]
[TBLPROPERTIES ("hbase.table.name"="<hbase_table>")]; --[3]- 选项1: 指定表使用的Storage Handler。建Hyperbase表的固定写法;
- 可选项2: 推荐使用默认映射关系;
- 可选项3: 推荐使用默认值即tableName;
为帮助您更好的理解Hyperbase内表,下面我们将通过建Hyperbase内表语法创建一张银行客户信息内表
示例. 创建了一张名为hbase_inner_table的内表,存储格式为HBaseStorageHandler
create table hbase_inner_table(
key1 string,
name string,
password string,
email string,
cellphone string,
balance double
)STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler';Hyperbase表支持的数据类型
BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, DATE, TIMESTAMP, FLOAT, DOUBLE, STRING, VARCHAR, DECIMAL 和 STRUCT。
所有数据类型映射在实际 Hyperbase 表中的类型都是 byte[]。
具体数据类型的相关介绍请参考Inceptor支持的数据类型。
查看元数据信息
建表后可通过 DESCRIBE FORMATTED 查看 hbase_inner_table 的元数据信息,确认是否创建成功。如下:
describe formatted hbase_inner_table;
由上图可见,hbase_inner_table表的列名、数据类型、映射关系等等。
创建外表:CREATE EXTERNAL TABLE
语法. 建hyperbase外表
CREATE EXTERNAL TABLE <tableName> (
<key> <data_type>,
<column> <data_type>,
<column> <data_type>,
...
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES('hbase.columns.mapping'=':key,<f:q1>,<f:q2>,...') --[1]
TBLPROPERTIES ("hbase.table.name"="<hbase_table>"); --[2]- 必选项1: 建外表时必须定义映射表和Hyperbase表列之间的映射关系。映射表第一项 :key 为固定写法,剩余项为 <column_family>:<column_qualifier> 的自定义组合;
- 必选项2:TBLPROPERTIES 中的 hbase.table.name 属性定义映射表对应的Hyperbase表的表名。 hbase_table 必须为Hyperbase中一个已存在的表名;
示例. 建Hyperbase外表
CREATE EXTERNAL TABLE hbase_external_table(
key1 string,
ex1 double,
ex3 date,
ex5 string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,f:q1,f:q4,f:q5") --[1]
TBLPROPERTIES ("hbase.table.name"="test.hbase_inner_table"); --[2]- 选项1: 指定外表 hbase_external_table 中的列与源表的映射关系。映射时数据类型强行转换,转换失败则为NULL。
- 选项2: hbase_external_table 和已存在的 hbase_inner_table 表的列映射关系。
查看元数据信息
建表后可通过 DESCRIBE FORMATTED 查看 hbase_inner_table 的元数据信息,确认是否创建成功。如下:
describe formatted hbase_external_table;
由上图可见,hbase_external_table表的列名、数据类型、映射关系等等。
Hyperbase SQL 索引操作
Hyperbase SQL的Index DDL支持创建和删除表的全局索引和全文索引,包括:
创建索引:CREATE INDEX
- 创建全局索引: CREATE GLOBAL INDEX
- 创建全文索引: CREATE FULLTEXT INDEX
删除索引:DROP INDEX
- 删除全局索引: DROP GLOBAL INDEX
- 删除全文索引: DROP FULLTEXT INDEX
创建索引:CREATE INDEX
Hyperbase表只支持创建全局索引(GLOBAL INDEX) 和全文索引(FULLTEXT INDEX),下面将分别介绍。
创建全局索引:CREATE GLOBAL INDEX
语法. 为Hyperbase表建全局索引
CREATE GLOBAL INDEX <index_name> ON <tableName> (
<column1> <SEGMENT LENGTH length1>|<(length1)> --[1]
[,<column2> <SEGMENT LENGTH length2>|<(length2)>,...] --[2]
);- 选项1- column1:指根据哪个列建全局索引,可以有多个列,但不可包含首列(因该列映射为RowKey)。
- 选项2- SEGMENT LENGTH length1:每个列在索引词条中所占字段的长度,可简写为 (length1) 。注意,简写必须有括号 。建议SEGMENT LENGTH 的设定最好大于等于字段的实际长度。
示例. 为内表创建全局索引
--根据name列创建一个名为name_global的全局索引,并指定该索引字段长度为10
CREATE GLOBAL INDEX name_global ON hbase_inner_table(name(10));创建全文索引:CREATE FULLTEXT INDEX
语法. 为Hyperbase表建全文索引
CREATE FULLTEXT INDEX ON <tableName> ( --[1]
<column1> [DOCVALUES <TRUE|FALSE>] --[2]
[,<column2> [DOCVALUES <TRUE|FALSE>],...] --[3]
)SHARD NUM <n>; --[4]- 选项1:一张表只能有 一个全文索引 ,所以建全文索引无须指定索引名
- 选项2:任意 column1 的数据类型不可以是:decimal,date,timestamp,会报错。且同样不可包含首列。
- 选项3:DOCVALUES 是一个优化查询的开关,推荐使用默认值打开(TRUE)。
- 选项4:SHARD NUM 指定全文索引的分片数,分片数只能在创建时指定,不可修改,需要用户预估索引数据的数量,一个SHARD上的数据不要超过25G。
示例. 为内表创建全文索引
--为内表hbase_inner_table根据列name、balance来创建全文索引
CREATE FULLTEXT INDEX ON hbase_inner_table(name,balance) SHARD NUM 1;删除索引
删除全局索引:DROP INDEX
因一张表可以有多个全局索引,所以需要指定索引名:index_name
语法
DROP INDEX [IF EXISTS] <index_name> ON <tableName>;示例
DROP INDEX name_global ON hbase_inner_table;删除全文索引:DROP FULLTEXT INDEX
因一张表只有一个全文索引,所以只需指定表名
语法
DROP FULLTEXT INDEX [IF EXISTS] ON <tableName>;Hyperbase SQL DML 操作
Hyperbase SQL中的DML(Data Manipulation Language)包括:
- 插入数据:INSERT
- 更新数据:UPDATE
- 删除数据:DELETE
下面将一一介绍。
插入数据
Hyperbase SQL 支持向Hyperbase表中单条插入数据或者批量插入查询结果。
单条插入数据
单条插入数据语法一次只可插入一条记录,具体语法如下:
语法
INSERT INTO TABLE <tableName> [(<column1>, <column2>, ...)] VALUES (<value1>, <value2>, ...);示例. 向hbase_inner_table表中单条插入数据
INSERT INTO TABLE hbase_inner_table VALUES ('1','Alice','Alice123','Alice@126.com', '12341234123', 10000.0);
INSERT INTO TABLE hbase_inner_table VALUES ('2','Bob','Bob123','Bob@126.com','13571357135', 20000.0);批量插入数据
不同于单条插入语法一次只能插入一条记录,批量插入语法可一次性插入任意多条记录。具体语法如下:
语法
BATCHINSERT INTO <tableName> [(<column1>, <column2>, ...)] BATCHVALUES(VALUES(<value1>, <value2>, ...), VALUES(<value1>, <value2>,...),...);- (<column1>, <column2>, …)可选,在插入数据时如果每列都会插入数据,则可以不指定插入的数据列名。
示例. 向hbase_inner_table表中批量插入数据
BATCHINSERT INTO hbase_inner_table BATCHVALUES (
VALUES('3','Carol','Carol123','Carol@126.com','12345234523', 30000.0),
VALUES('4','Derek','Derek123','Derek@126.com','13456345634', 40000.0));示例. 查看hbase_inner_table表中数据
select * from hbase_inner_table;
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
| 2 | Bob | Bob123 | Bob@126.com | 13571357135 | 20000.0 |
| 3 | Carol | Carol123 | Carol@126.com | 12345234523 | 30000.0 |
| 4 | Derek | Derek123 | Derek@126.com | 13456345634 | 40000.0 |
+-----+-------+----------+---------------+-------------+---------+并且,从hbase_external_table中也可以查询到上述数据,因两者映射Hyperbase中的同一张表。
更新数据
数据插入后可以通过UPDATE语法来更新数据
语法
UPDATE <tableName> SET <column> = <value> WHERE <filter_conditions>;示例. 更新满足过滤条件filter_conditions的记录
UPDATE hbase_inner_table SET balance = 50000.0 WHERE name = 'Carol';删除记录
数据插入后可以通过DELETE语句来删除数据
语法
DELETE FROM <tableName> WHERE <filter_conditions>;示例. 删除满足过滤条件filter_conditions的记录
DELETE FROM hbase_inner_table WHERE key1 = '4';Hyperbase SQL DQL 操作
指定索引查询模式
指定全局索引和全文索引进行查询,只有在 local mode 下才会生效,该模式的参数设置如下:
设置local mode
set ngmr.exec.mode = local;该参数设置完成后才能利用索引进行有效的查询。
下面我们分别介绍对hyperbase映射表指定全局索引和全文索引进行查询的语法。而全局索引和全文索引如何创建请参考前文的介绍。
指定全局索引查询Hyperbase表
语法
SELECT /*+USE_INDEX(<table_alias> USING <index_name>)*/... --[1]
FROM <tableName> <table_alias> --[2]
WHERE <filter_conditions>; --[3]- ./+USE_INDEX(<table_alias> USING <index_name>)/为指定索引的提示,在提示内必须使用表的化名 table_alias
- 必须为表起化名
- filter_conditions:过滤条件中至少含一个使用的索引中的列
下面将以前文创建的全局索引name_global举例如何查询。
例:用全局索引name_global查询姓名为Alice的用户信息
SELECT /*+USE_INDEX(t USING name_global)*/ * FROM hbase_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+指明不使用全局索引查询
若用户想对含全局索引的表做普通的查询时,需明确指定不使用任何索引
具体语法如下:
SELECT /*+USE_INDEX(<table_alias> USING NOT_USE_INDEX)*/ ... FROM <tableName> <table_alias> WHERE <filter_condition>;例:不使用全局索引name_global查询姓名为Alice的用户信息
SELECT /*+USE_INDEX(t USING NOT_USE_INDEx)*/ * FROM hbase_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+指定全文索引查询
Hyperbase表的全文索引通过CONTAINS函数使用,目前支持精准匹配,前缀查询,模糊查询和范围查询四种语义,支持检索条件的逻辑组合。
语法
SELECT ... FROM <tableName>
WHERE CONTAINS (<column>, "<fulltext_query>") --[1]
[AND|OR CONTAINS(<column>, "<fulltext_query>") AND|OR CONTAINS(<column>, "<fulltext_query>")...]; --[2]- 选项1:CONTAINS 函数需要两个参数:列名<column>和检索表达式"<fulltext_query>"(注意,检索条件要放在双引号中),且两者是一一匹配的。
- 选项2:CONTAINS 中包含全文检索条件,一次查询中可以使用多个CONTAINS,之间用AND或者OR连接。
- CONTAINS函数中的检索表达式"<fulltext_query>"需要有如下形式:
"<operator> '<search_contents>' [and|or <operator> '<search_contents>' and|or <operator> '<search_contents>'...]"其中,<operator> 为全文检索运算符, '<search_contents>' 为检索内容(注意单引号)。一个全文检索条件可以由多个 <operator> <search_contents> 组成,之间用 and 或 or 连接。 全文检索操作符<OPERATOR>包括:
| 操作符 | 支持的数据类型 | |
|---|---|---|
| 精确匹配 | term | 所有数据类型 |
| 前缀查询 | prefix | STRING类型 |
| 正则表达式 | regexp | STRING类型 |
| 模糊查询 | wildcard | STRING类型 |
| 全文搜索 | match | STRING类型 |
| in查询 | in | 所有数据类型 |
| 范围查询 | range | 所有数据类型 |
| > | 所有数据类型 | |
| < | 所有数据类型 | |
| >= | 所有数据类型 | |
| <= | 所有数据类型 |
下面给出几个具体事例。
a. 示例. 精确匹配(term)查询name列的值精确等于Alice的记录
select * from hbase_inner_table where contains(name, "term 'Alice'");
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+a. 示例. 范围表达式(range)查询balance列的值满足[10000,30000)的记录
select * from hbase_inner_table where contains(balance, "range '[10000,30000)'");
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
| 2 | Bob | Bob123 | Bob@126.com | 13571357135 | 20000.0 |
+-----+-------+----------+---------------+-------------+---------+Hyperdrive SQL 使用说明
Hyperdrive SQL 分为DDL、index DDL、DML和DQL四部分。 本章节将以银行信息表为例介绍Hyperdrive SQL 的建表、建索引、插入数据和数据查询等基本操作。其他详细操作请参考《Hyperbase使用手册》
快速创建Hyperdrive 数据表
创建内表:CREATE TABLE
语法
建Hyperdrive我们推荐使用较简单的方法。
CREATE TABLE <tableName> (
<key> <data_type>,
<column> <data_type>,
<column> <data_type>,
...
)
STORED AS HYPERDRIVE; --[1]
- 选项1:指定存储格式。建Hyperdrive表的简化写法
Hyperdrive表支持的数据类型包括: BOOLEAN、 TINYINT、 SMALLINT、 INTEGER、 BIGINT、 DATE、 TIMESTAMP、 DECIMAL、 FLOAT、 DOUBLE、 STRING、 VARCHAR和STRUCT,有自己的编码和解码方式,解决了 NULL 等特殊类型在Hyperbase中的表示。
示例. 建Hyperdrive内表
create table hd_inner_table(
key1 string,
name string,
password string,
email string,
cellphone string,
balance double
)STORED AS HYPERDRIVE;查看元数据信息
建表后可通过 DESCRIBE FORMATTED 查看 hd_inner_table 的元数据信息,确认是否创建成功。如下:
describe formatted hd_inner_table;因外表众多功能无法实现,不推荐建Hyperdrive外表。
Hyperdrive SQL 索引
索引相关的DDL语法包括创建和删除hyperdrive表的全局索引和全文索引:
创建索引:CREATE INDEX
- 创建全局索引: CREATE GLOBAL INDEX
- 创建全文索引: CREATE FULLTEXT INDEX
删除索引:DROP INDEX
- 删除全局索引: DROP GLOBAL INDEX
- 删除全文索引: DROP FULLTEXT INDEX
下面将具体介绍创建和删除索引的语法。
创建索引
创建全局索引: CREATE GLOBAL INDEX
语法
CREATE GLOBAL INDEX <index_name> ON <tableName> (
<column1> [SEGMENT LENGTH length1]|[(length1)] --[1]
[,<column2> [SEGMENT LENGTH length2]|[(length2)],...] --[2]
);- 选项1 - column1 :指根据哪个列建全局索引,可以有多个列,但不可包含首列(因该列映射为RowKey)。
- 选项2 - SEGMENT LENGTH length1 :只有string类型列需要指定字段长度,可简写为 (length1) 。注意简写必须有 () 。用STRING类型列创建全局索引时要指定字段长度。一个字段的SEGMENT LENGTH 的设定最好大于等于字段的实际长度。
下面将以hd_inner_table表为例,创建全局索引。
示例. 为内表hd_inner_table创建全局索引
CREATE GLOBAL INDEX name_balance_global_index ON hd_inner_table(name(10), balance);
-- 因列name是string类型,因此需要指定长度创建全文索引: CREATE FULLTEXT INDEX
语法
CREATE FULLTEXT INDEX ON <tableName> ( --[1]
<column1> [DOCVALUES <TRUE|FALSE>] --[2]
[,<column2> [DOCVALUES <TRUE|FALSE>],...] --[3]
)SHARD NUM <n>; --[4]- 选项1:一张表只能有 一个全文索引 ,所以建全文索引无须指定索引名。
- 选项2:任意 column1 的数据类型不可以是:decimal,date,timestamp,会报错。且同样不可包含首列。
- 选项3:DOCVALUES 是一个优化查询的开关,推荐使用默认打开(TRUE)。
- 选项4:SHARD NUM 指定全文索引的分片数,分片数只能在创建时指定,不可修改,需要用户预估索引数据的数量,一个SHARD上的数据不要超过25G。
示例. 为内表创建全文索引
CREATE FULLTEXT INDEX ON hd_inner_table(name,balance) SHARD NUM 1;
--为内表hd_inner_table根据列name、balance来创建全文索引,一个分片建全文索引无需指定STRING类型的字段长度
删除索引
删除全局索引:DROP INDEX
因一张表可以有多个全局索引,所以需要指定索引名:index_name。
语法
DROP INDEX [IF EXISTS] <index_name> ON <tableName>;示例
DROP INDEX name_balance_global_index ON hd_inner_table;
--删除创建的全局索引 name_balance_global_indexHyperdrive SQL DML
Hyperdrive SQL中的DML(Data Manipulation Language)包括:
- 插入数据:INSERT
- 更新数据:UPDATE
- 删除数据:DELETE
下面将一一介绍。
插入数据
Hyperdrive SQL 支持向Hyperbase表中单条插入数据或者批量插入查询结果。
单条插入数据
单条插入数据语法一次只可插入一条记录,具体如下:
语法
INSERT INTO TABLE <tableName> [(<column1>, <column2>, ...)] VALUES (<value1>, <value2>, ...);示例. 向hd_inner_table表中单条插入数据
INSERT INTO TABLE hd_inner_table VALUES ('1','Alice','Alice123','Alice@126.com', '12341234123', 10000.0);
INSERT INTO TABLE hd_inner_table VALUES ('2','Bob','Bob123','Bob@126.com','13571357135', 20000.0);批量插入数据
不同于单条插入语法一次只能插入一条记录,批量插入语法可一次性插入任意多条记录,具体如下:
语法
BATCHINSERT INTO <tableName> [(<column1>, <column2>, ...)] BATCHVALUES(VALUES(<value1>, <value2>, ...), VALUES(<value1>, <value2>,...),...);示例. 向hd_inner_table表中批量插入数据
BATCHINSERT INTO hd_inner_table BATCHVALUES (
VALUES('3','Carol','Carol123','Carol@126.com','12345234523', 30000.0),
VALUES('4','Derek','Derek123','Derek@126.com','13456345634', 40000.0));更新数据
数据插入后可以通过UPDATE语法来更新数据,具体如下:
语法
UPDATE <tableName> SET <column> = <value> WHERE <filter_conditions>;示例. 更新满足过滤条件filter_conditions的记录
UPDATE hd_inner_table SET balance = 50000.0 WHERE name = 'Carol';删除记录
数据插入后可以通过DELETE语句来删除数据,具体如下:
语法
DELETE FROM <tableName> WHERE <filter_conditions>;示例. 删除满足过滤条件filter_conditions的记录
DELETE FROM hd_inner_table WHERE key1 = '4';Hyperdrive SQL DQL
指定索引查询模式
指定全局索引和全文索引进行查询,只有在 local mode 下才会生效,该模式的参数设置如下:
设置local mode
set ngmr.exec.mode = local;该参数设置完成后才能利用索引进行有效的查询
指定索引查询Hyperdrive表
全局索引查询Hyperdrive表
语法
SELECT /*+USE_INDEX(<table_alias> USING <index_name>)*/... --[1]
FROM <tableName> <table_alias> --[2]
WHERE <filter_conditions>; --[3]- 选项1:/+USE_INDEX(<table_alias> USING <index_name>)/为指定索引的提示,在提示内必须使用表的化名 table_alias。
- 选项2:必须为表起化名
- 选项3:filter_conditions:过滤条件中至少含一个使用的索引中的列
示例. 指定全局索引查询内表hd_inner_table
SELECT /*+USE_INDEX(t USING name_balance_global_index)*/ * FROM hd_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+利用全局索引 name_balance_global_index 查询满足条件:t.name = 'Alice’的数据
使用索引查询时必须要给表起化名,并在指定索引时使用表化名。
明确不使用全局索引查询
语法
SELECT /*+USE_INDEX(<table_alias> USING NOT_USE_INDEX)*/ ... FROM <tableName> <table_alias> WHERE <filter_condition>;示例. 不使用全局索引进行查询
SELECT /*+USE_INDEX(t using NOT_USE_INDEX)*/ * FROM hd_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+明确不使用索引查询满足条件:t.name = 'Alice’的数据
指定全文索引查询
语法
SELECT /*+USE_INDEX(<table_alias> USING FULLTEXT)*/ ... FROM <table> <table_alias> WHERE <filter_conditions>;示例. 指定全文索引查询内表hd_inner_table
SELECT /*+USE_INDEX(t USING FULLTEXT)*/ * FROM hd_inner_table t WHERE t.name = 'Alice';
+-----+-------+----------+---------------+-------------+---------+
| key1| name | password | email | cellphone | balance |
+-----+-------+----------+---------------+-------------+---------+
| 1 | Alice | Alice123 | Alice@126.com | 12312341234 | 10000.0 |
+-----+-------+----------+---------------+-------------+---------+利用全文索引查询满足条件:t.name = 'Alice’的数据。
如果上述内容对您有提供帮助,欢迎多多点赞支持~😎
 登录后可评论
登录后可评论








.jpg)



