Hyperbase 基本用法之 Hbase Shell
Hyperbase基础介绍
Transwarp HyperbaseNoSQL宽表数据库是一个具有高可靠,高性能,可伸缩,实时读写,并且面向列的一个分布式NewSQL数据库,其既具有NoSQL数据库的海量数据存储管理能力,同时又继承了关系型数据库的SQL特性,列式存储的特性使得了其对Schema限制很少,可以自由添加列,适合存储海量的半结构化数据。
Hyperbase同时也是一个Key-Value数据库,按Key的字典序顺序存储,主要通过Key实现数据的增删改查以及扫库操作。Hyperbas采用HDFS为文件存储系统,可以高效的支持各类如批处理应用、全局搜索或高并发图形数据库检索应用等等。
注意,社区版用户需要确保已经上传并安装好Hyperbase的产品包,并申请了对应的许可证 (TDH基础安装包安装完成后申请的许可证内不含有Hyperbase的许可证,因此,社区版用户需要在新上传其他子产品后再次执行申请许可证的步骤方可生成对应产品的许可证)
Hyperbase安装视频
Hyperbase交互方式
Hyperbase交互有以下三种方式:
1. SQL(推荐方式)
和Hyperbase交互推荐使用SQL,您在连接上Inceptor engine后即可使用SQL进行数据库操作。
我们的SQL引擎Inceptor Engine提供了丰富的SQL语法,并对SQL的执行进行了充分的优化,使用SQL和Hyperbase交互在正确性和性能方面都有很好的保证。 您可以在链接数据库以及SQL参考章节详细了解链接数据库的教程以及Inceptor支持的SQL语法。
2. Shell
Hyperbase提供交互式Shell以及一系列Shell指令用于数据操作。
a. 在 Hyperbase Client 执行 hbase shell : Hyperbase Client 集成在 TDH-Client 中,需要执行以下命令(开安全)
source ./TDH-Client/init.sh
kinit -kt /etc/hypberase1/conf/hyperbase.keytab hbase/${hostname}
hbase shellb. 在服务 pod 中执行 hbase shell (开安全):
kubectl exec -it hmasterPodName bash
export HBASE_OPTS="-Djava.security.auth.login.config=/etc/hyperbase1/conf/jaas.conf"
kinit -kt /etc/hyperbase1/conf/hyperbase.keytab hbase/${hostname}
hbase shell3. Java API
Hyperbase支持Apache Hyperbase原生的API,同时还提供多种自有的API,细节请参考Hyperbase API使用说明。
Hbase Shell交互教程
本节主要介绍基于Shell交互的最基础的使用方法,目的是让您可以迅速地熟悉Hyperbase shell 的使用方式。在安装了Hyperbase的节点上执行 hbase shell 操作可以进入命令行。
接下来为您介绍如何通过命令行进行一些简单操作,包括建表,插入数据,删除数据和删除表。
Note!! 操作注意事项!!
1. 和SQL不同,Hyperbase Shell指令区分大小写,例如 create 指令不能写成 CREATE;
2. 所有名字如表名和列名都必须使用单引号进行引用: 如 'table1', 'key1'。
3. 创建和修改表的配置时使用的是 Ruby Hashes,如 {'key1' ⇒ 'value1', 'key2' ⇒ 'value2', …}。它需用 "{" 和 "}" 表明整个对象的开始和结尾,每对 Key, Value 之间通过逗号分隔,Key 和 Value 之间通过 "⇒" 分隔。
4. 如果想输入二进制的数值,需用双引号进行引用,并且使用 16 进制表示法,如:
get 't1', "key\x03\x3f\xcd"
get 't1', "key\003\023\011"
put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"1. 进入Hyperbase命令行
步骤1 启动TDH Client,用hbase shell命令进入Hyperbase命令行。
source /root/TDH-Client/init.sh // 执行init.sh脚本,启动TDH Client步骤2 进入Hyperbase命令行
hbase shell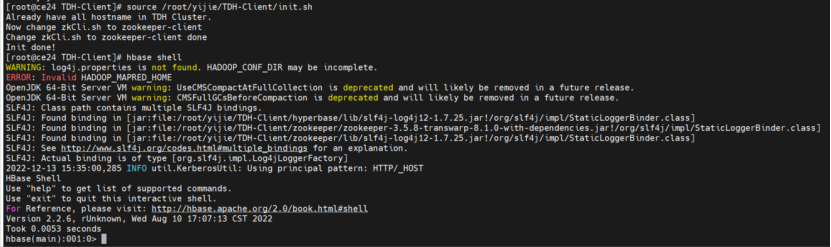
2. 创建表,并插入数据
步骤1 创建NameSpace
create_namespace '{namespace_user_name}' 示例:
create_namespace 'namespace_yijie_test' 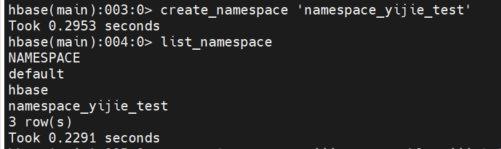
步骤2 在当前NameSpace下创建表
create '{namespace_user_name}:{table_user_name}', 'column_family' 示例:
create 'namespace_yijie_test:table_yijie','cf'Note: Hyperbase中表 、 列族和列限定符名都要尽量短,以减少读写时的I/O负载。
步骤3 列出当前namespace下所有表
list_namespace_tables '{namespace_user_name}' 示例:
list_namespace_tables 'namespace_yijie_test'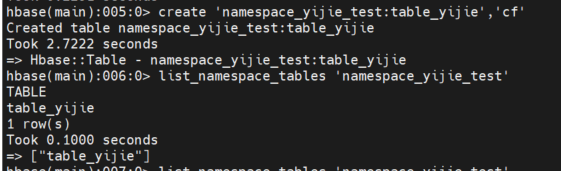
步骤4 插入数据
put '{namespace_user_name}:{table_user_name}', 'row_key', 'column_family:column_qualifier', 'cell_value' 示例:
put 'namespace_yijie_test:table_yijie','row1','cf:a','value1'
put 'namespace_yijie_test:table_yijie','row2','cf:b','value2'
put 'namespace_yijie_test:table_yijie','row3','cf:c','value3'3. 读取数据
步骤1 读取Cell
get '{namespace_user_name}:{table_user_name}', 'row_key'示例:
get 'namespace_yijie_test:table_yijie','row1'步骤2 读取前10行
scan '{namespace_user_name}:{table_user_name}',{LIMIT=>10} 示例:
scan 'namespace_yijie_test:table_yijie',{LIMIT=>10}步骤3 统计行数
count '{namespace_user_name}:{table_user_name}'示例:
count 'namespace_yijie_test:table_yijie'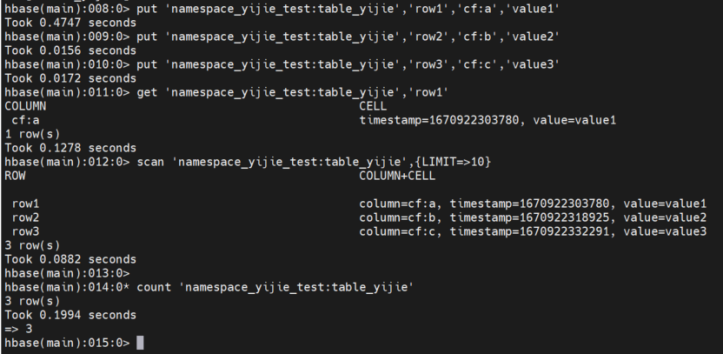
4. 修改表属性
步骤1 将表下线(禁用,要删除或者改设置需要先disable)
disable '{namespace_user_name}:{table_user_name}'步骤2 更改表属性
alter '{namespace_user_name}:{table_user_name}', {<PROPERTY_1> => <value_1>, <PROPERTY_2> => <value_2>, ...}, {...}, ...alter 可以用于添加和修改表或表中列族的元数据,可以同时修改多个列簇。使用 <PROPERTY> => <value> 的方式设置表或列族的属性。如果只修改一组元数据,可以不加 {};如果同时修改多组元数据(例如修改多个列族元数据),每组属性需要放在不同的 {} 中。
示例1
alter 'namespace_yijie_test:table_yijie',{NAME=>'cf',COMPRESSION => 'snappy', DATA_BLOCK_ENCODING => 'PREFIX'}
示例2
将表t1中的列簇f1改为常驻内存, 并将列簇f2的版本改为5:
alter 't1', {NAME => 'f1', IN_MEMORY => true}, {NAME => 'f2', VERSION => 5}步骤3 将表上线
enable '{namespace_user_name}:{table_user_name}'示例
enable 'namespace_yijie_test:table_yijie'步骤4 查看表属性
desc '{namespace_user_name}:{table_user_name}'示例
desc 'namespace_yijie_test:table_yijie'
5. 表的分裂
步骤1 插入数据
put 'namespace_yijie_test:table_yijie', 'row4', 'cf:a', 'value4'
put 'namespace_yijie_test:table_yijie', 'row5', 'cf:b', 'value5'
put 'namespace_yijie_test:table_yijie', 'row6', 'cf:c', 'value6'步骤2 将数据溢写磁盘
flush 'namespace_yijie_test:table_yijie'步骤3 分裂表
split 'namespace_yijie_test:table_yijie', 'row3'6. 导出表属性到本地文件
利用describeInJson命令将表属性导出到本地Json文件,并查看表属性。
步骤1 将表属性导出到本地Json文件
describeInJson '{namespace_user_name}:{table_user_name}','true','/transwarp/Desktop/hbase.json'
exit步骤2 查看表属性文件
cat /transwarp/Desktop/hbase.json7. 查看META表
语法
scan 'hbase:meta'8. 删除表
需要先将表下线,再删除。
disable '{namespace_user_name}:{table_user_name}'
drop '{namespace_user_name}:{table_user_name}'9. Hyperbase数据导入
在Waterdrop中创建Hyperdrive内表,并建立外表,将数据导入到内表中。
步骤1 在Inceptor中创建外表
SQL:
use {database_name};
drop table if exists hyper_external_table;
create external table hyper_external_table(
rowkey string,
num int,
country int,
rd string)
row format delimited fields terminated by ','
location '/images/hyper_data';步骤2 在Inceptor中创建Hyperbase内表
drop table if exists hyper_table;
create table hyper_table(
rowkey string,
num int,
country int,
rd string)
stored as hyperdrive;步骤3 将Inceptor外表中的前100条数据导入到Hyperbase内表中
insert into hyper_table select rowkey,num,country,rd from hyper_external_table order by rowkey limit 100;
select * from hyper_table limit 10;Hyperbase基础介绍
Transwarp HyperbaseNoSQL宽表数据库是一个具有高可靠,高性能,可伸缩,实时读写,并且面向列的一个分布式NewSQL数据库,其既具有NoSQL数据库的海量数据存储管理能力,同时又继承了关系型数据库的SQL特性,列式存储的特性使得了其对Schema限制很少,可以自由添加列,适合存储海量的半结构化数据。
Hyperbase同时也是一个Key-Value数据库,按Key的字典序顺序存储,主要通过Key实现数据的增删改查以及扫库操作。Hyperbas采用HDFS为文件存储系统,可以高效的支持各类如批处理应用、全局搜索或高并发图形数据库检索应用等等。
注意,社区版用户需要确保已经上传并安装好Hyperbase的产品包,并申请了对应的许可证 (TDH基础安装包安装完成后申请的许可证内不含有Hyperbase的许可证,因此,社区版用户需要在新上传其他子产品后再次执行申请许可证的步骤方可生成对应产品的许可证)
Hyperbase安装视频
Hyperbase交互方式
Hyperbase交互有以下三种方式:
1. SQL(推荐方式)
和Hyperbase交互推荐使用SQL,您在连接上Inceptor engine后即可使用SQL进行数据库操作。
我们的SQL引擎Inceptor Engine提供了丰富的SQL语法,并对SQL的执行进行了充分的优化,使用SQL和Hyperbase交互在正确性和性能方面都有很好的保证。 您可以在链接数据库以及SQL参考章节详细了解链接数据库的教程以及Inceptor支持的SQL语法。
2. Shell
Hyperbase提供交互式Shell以及一系列Shell指令用于数据操作。
a. 在 Hyperbase Client 执行 hbase shell : Hyperbase Client 集成在 TDH-Client 中,需要执行以下命令(开安全)
source ./TDH-Client/init.sh
kinit -kt /etc/hypberase1/conf/hyperbase.keytab hbase/${hostname}
hbase shellb. 在服务 pod 中执行 hbase shell (开安全):
kubectl exec -it hmasterPodName bash
export HBASE_OPTS="-Djava.security.auth.login.config=/etc/hyperbase1/conf/jaas.conf"
kinit -kt /etc/hyperbase1/conf/hyperbase.keytab hbase/${hostname}
hbase shell3. Java API
Hyperbase支持Apache Hyperbase原生的API,同时还提供多种自有的API,细节请参考Hyperbase API使用说明。
Hbase Shell交互教程
本节主要介绍基于Shell交互的最基础的使用方法,目的是让您可以迅速地熟悉Hyperbase shell 的使用方式。在安装了Hyperbase的节点上执行 hbase shell 操作可以进入命令行。
接下来为您介绍如何通过命令行进行一些简单操作,包括建表,插入数据,删除数据和删除表。
Note!! 操作注意事项!!
1. 和SQL不同,Hyperbase Shell指令区分大小写,例如 create 指令不能写成 CREATE;
2. 所有名字如表名和列名都必须使用单引号进行引用: 如 'table1', 'key1'。
3. 创建和修改表的配置时使用的是 Ruby Hashes,如 {'key1' ⇒ 'value1', 'key2' ⇒ 'value2', …}。它需用 "{" 和 "}" 表明整个对象的开始和结尾,每对 Key, Value 之间通过逗号分隔,Key 和 Value 之间通过 "⇒" 分隔。
4. 如果想输入二进制的数值,需用双引号进行引用,并且使用 16 进制表示法,如:
get 't1', "key\x03\x3f\xcd"
get 't1', "key\003\023\011"
put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"1. 进入Hyperbase命令行
步骤1 启动TDH Client,用hbase shell命令进入Hyperbase命令行。
source /root/TDH-Client/init.sh // 执行init.sh脚本,启动TDH Client步骤2 进入Hyperbase命令行
hbase shell
2. 创建表,并插入数据
步骤1 创建NameSpace
create_namespace '{namespace_user_name}' 示例:
create_namespace 'namespace_yijie_test'
步骤2 在当前NameSpace下创建表
create '{namespace_user_name}:{table_user_name}', 'column_family' 示例:
create 'namespace_yijie_test:table_yijie','cf'Note: Hyperbase中表 、 列族和列限定符名都要尽量短,以减少读写时的I/O负载。
步骤3 列出当前namespace下所有表
list_namespace_tables '{namespace_user_name}' 示例:
list_namespace_tables 'namespace_yijie_test'
步骤4 插入数据
put '{namespace_user_name}:{table_user_name}', 'row_key', 'column_family:column_qualifier', 'cell_value' 示例:
put 'namespace_yijie_test:table_yijie','row1','cf:a','value1'
put 'namespace_yijie_test:table_yijie','row2','cf:b','value2'
put 'namespace_yijie_test:table_yijie','row3','cf:c','value3'3. 读取数据
步骤1 读取Cell
get '{namespace_user_name}:{table_user_name}', 'row_key'示例:
get 'namespace_yijie_test:table_yijie','row1'步骤2 读取前10行
scan '{namespace_user_name}:{table_user_name}',{LIMIT=>10} 示例:
scan 'namespace_yijie_test:table_yijie',{LIMIT=>10}步骤3 统计行数
count '{namespace_user_name}:{table_user_name}'示例:
count 'namespace_yijie_test:table_yijie'
4. 修改表属性
步骤1 将表下线(禁用,要删除或者改设置需要先disable)
disable '{namespace_user_name}:{table_user_name}'步骤2 更改表属性
alter '{namespace_user_name}:{table_user_name}', {<PROPERTY_1> => <value_1>, <PROPERTY_2> => <value_2>, ...}, {...}, ...alter 可以用于添加和修改表或表中列族的元数据,可以同时修改多个列簇。使用 <PROPERTY> => <value> 的方式设置表或列族的属性。如果只修改一组元数据,可以不加 {};如果同时修改多组元数据(例如修改多个列族元数据),每组属性需要放在不同的 {} 中。
示例1
alter 'namespace_yijie_test:table_yijie',{NAME=>'cf',COMPRESSION => 'snappy', DATA_BLOCK_ENCODING => 'PREFIX'}
示例2
将表t1中的列簇f1改为常驻内存, 并将列簇f2的版本改为5:
alter 't1', {NAME => 'f1', IN_MEMORY => true}, {NAME => 'f2', VERSION => 5}步骤3 将表上线
enable '{namespace_user_name}:{table_user_name}'示例
enable 'namespace_yijie_test:table_yijie'步骤4 查看表属性
desc '{namespace_user_name}:{table_user_name}'示例
desc 'namespace_yijie_test:table_yijie'
5. 表的分裂
步骤1 插入数据
put 'namespace_yijie_test:table_yijie', 'row4', 'cf:a', 'value4'
put 'namespace_yijie_test:table_yijie', 'row5', 'cf:b', 'value5'
put 'namespace_yijie_test:table_yijie', 'row6', 'cf:c', 'value6'步骤2 将数据溢写磁盘
flush 'namespace_yijie_test:table_yijie'步骤3 分裂表
split 'namespace_yijie_test:table_yijie', 'row3'6. 导出表属性到本地文件
利用describeInJson命令将表属性导出到本地Json文件,并查看表属性。
步骤1 将表属性导出到本地Json文件
describeInJson '{namespace_user_name}:{table_user_name}','true','/transwarp/Desktop/hbase.json'
exit步骤2 查看表属性文件
cat /transwarp/Desktop/hbase.json7. 查看META表
语法
scan 'hbase:meta'8. 删除表
需要先将表下线,再删除。
disable '{namespace_user_name}:{table_user_name}'
drop '{namespace_user_name}:{table_user_name}'9. Hyperbase数据导入
在Waterdrop中创建Hyperdrive内表,并建立外表,将数据导入到内表中。
步骤1 在Inceptor中创建外表
SQL:
use {database_name};
drop table if exists hyper_external_table;
create external table hyper_external_table(
rowkey string,
num int,
country int,
rd string)
row format delimited fields terminated by ','
location '/images/hyper_data';步骤2 在Inceptor中创建Hyperbase内表
drop table if exists hyper_table;
create table hyper_table(
rowkey string,
num int,
country int,
rd string)
stored as hyperdrive;步骤3 将Inceptor外表中的前100条数据导入到Hyperbase内表中
insert into hyper_table select rowkey,num,country,rd from hyper_external_table order by rowkey limit 100;
select * from hyper_table limit 10; 登录后可评论
登录后可评论








.jpg)



