【0-1系列】从0-1快速了解搜索引擎Scope(下)
友情链接:
前言
近日,社区版家族正式发布V2024.5版本,其中,社区开发版系列重磅发布Scope开发版以及StellarDB开发版。
为了可以让大家更进一步了解产品,本系列文章从背景概念开始介绍,深入浅出的为读者介绍Scope的优势以及能力,在上一篇文章中为读者介绍了基础知识、Scope的技术优势以及能力,本篇文章将继续为读者介绍如何安装部署以及使用。
安装与部署
企业版
社区开发版
安装教程
友情提示:安装前请仔细查看安装手册注意事项章节,下方内容仅供参考
步骤一 将从官网下载下来的产品包解压后上传至安装环境
- 产品包名称:TDH-Scope-Standalone-Community-Transwarp-2024.5-X86_64-final.tar.gz
步骤二 执行下述命令进行解压,解压后将出现一个镜像tar包
tar -zxf TDH-Scope-Standalone-Community-Transwarp-2024.5-X86_64-final.tar.gz
步骤三 执行下述命令加载镜像
docker load -i scope-2024.5.tar
步骤四 执行下方指令启动容器并运行镜像,运行格式为:
docker run -d --network host -v <本地目录路径>:/opt/transwarp --privileged <镜像名>
-v参数配置了TDH挂载的本地磁盘路径。该路径下会保存产品运行过程中产生的配置conf、数据data、日志log。再次提醒请不要随意改动做好备份,以及确保该路径下没有历史版本的数据文件。
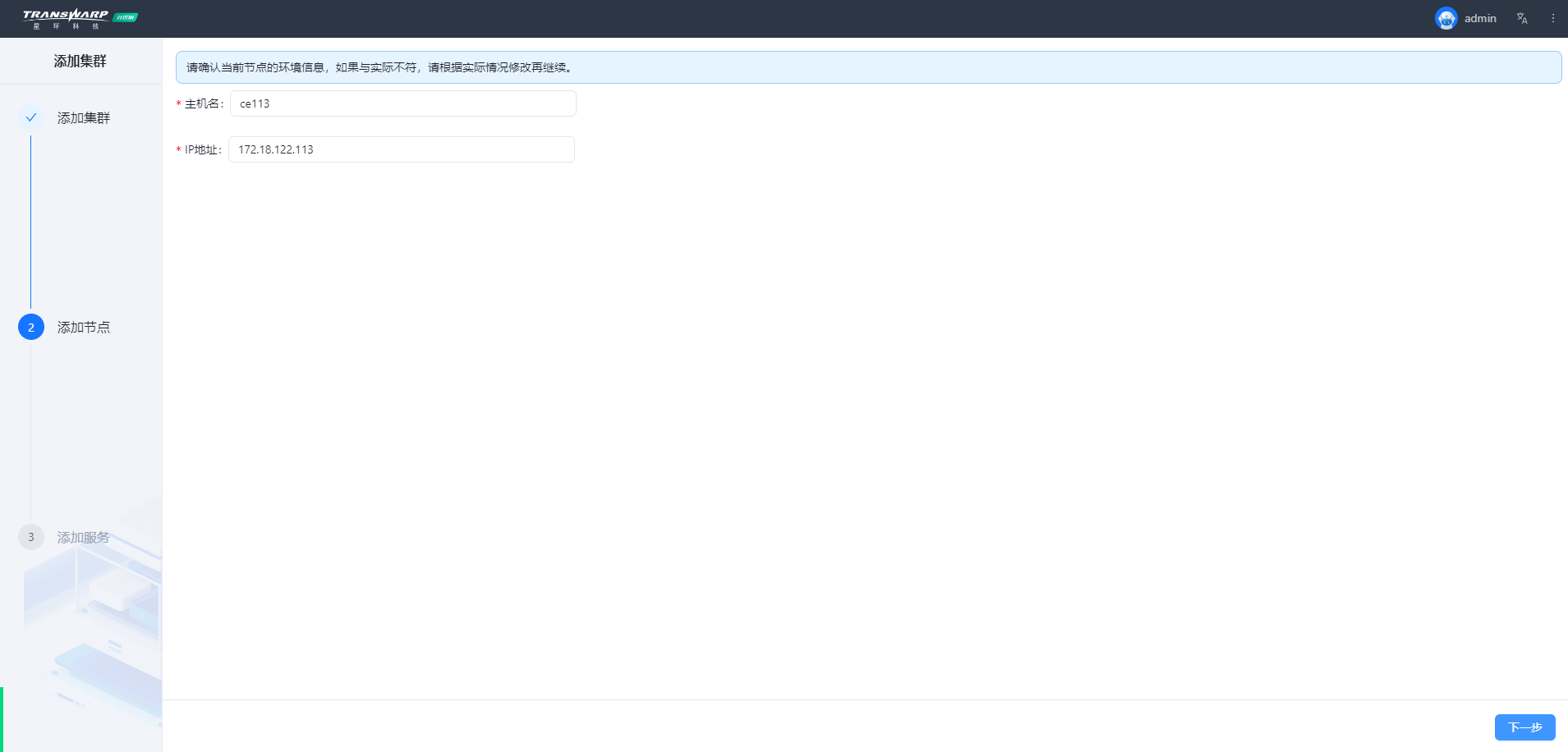
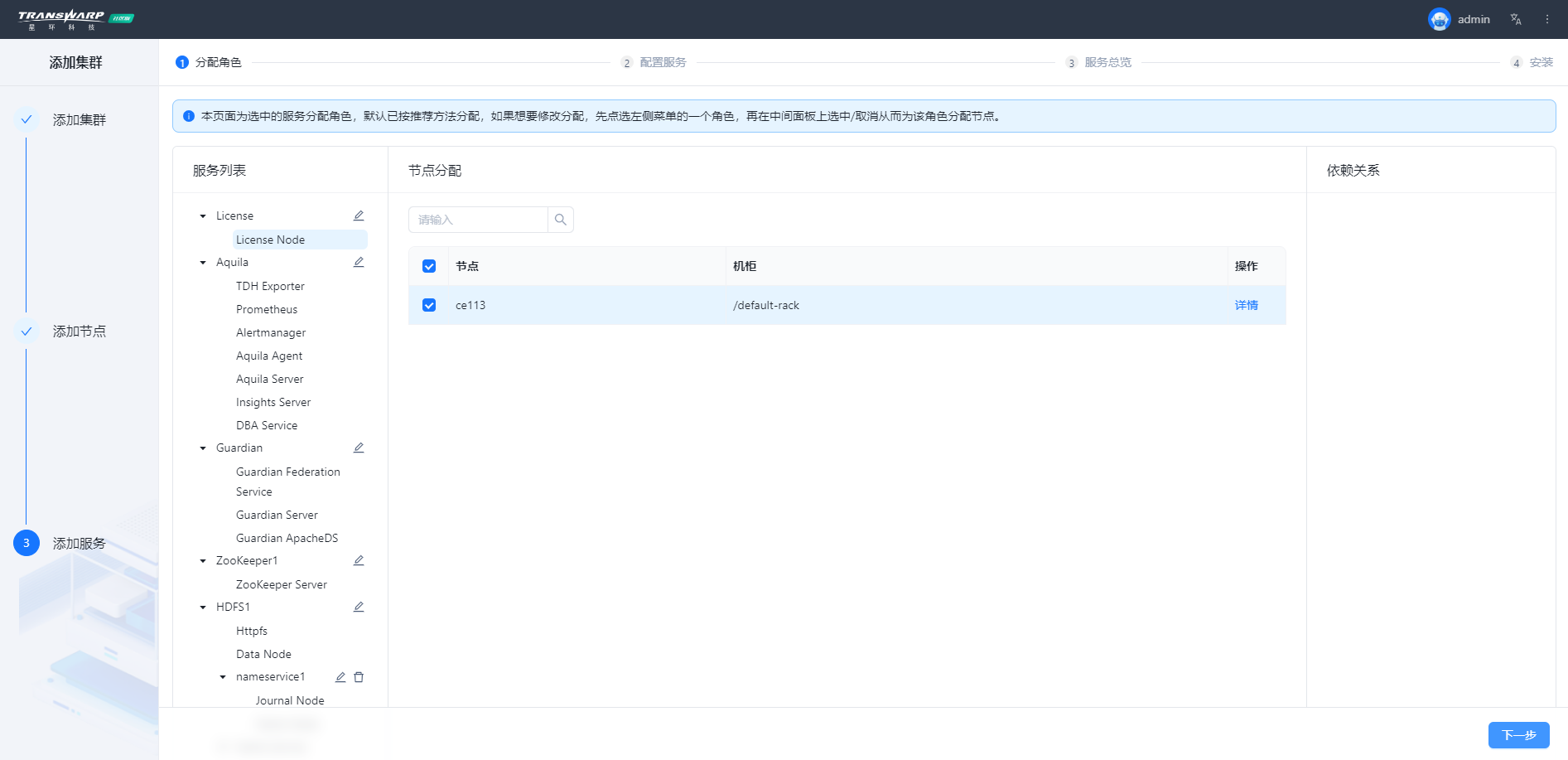
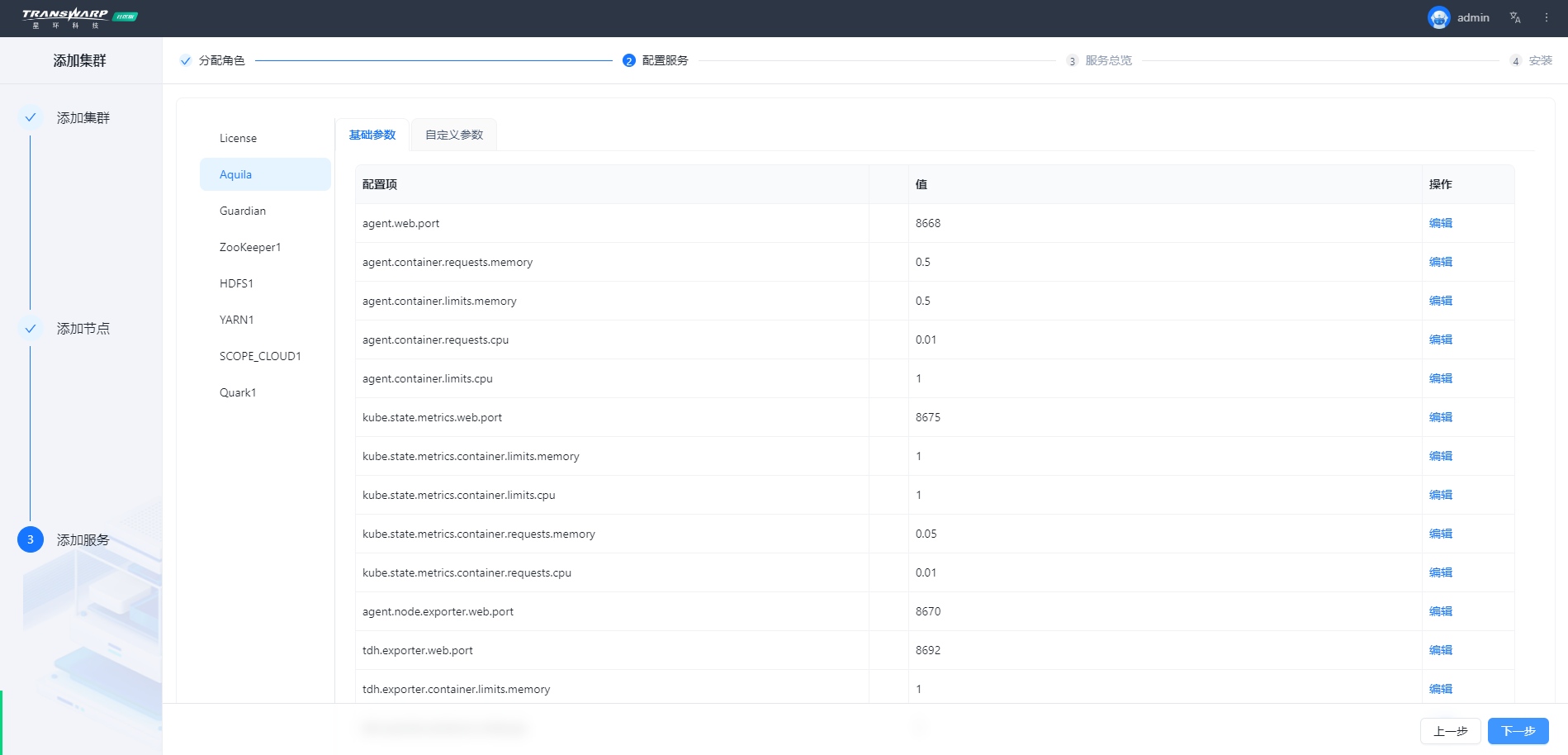
操作示例图

步骤五 容器启动后需等待30s至2分钟
步骤六 浏览器访问管理节点8180端口
打开客户端浏览器(推荐使用Google Chrome浏览器),访问http://host:8180,比如http://172.16.3.108:8180/。访问这个地址,您会看到下面的登录页面。

初次登录以admin的身份登录,密码也是admin。
步骤七 按照向导提示进行集群部署与配置即可
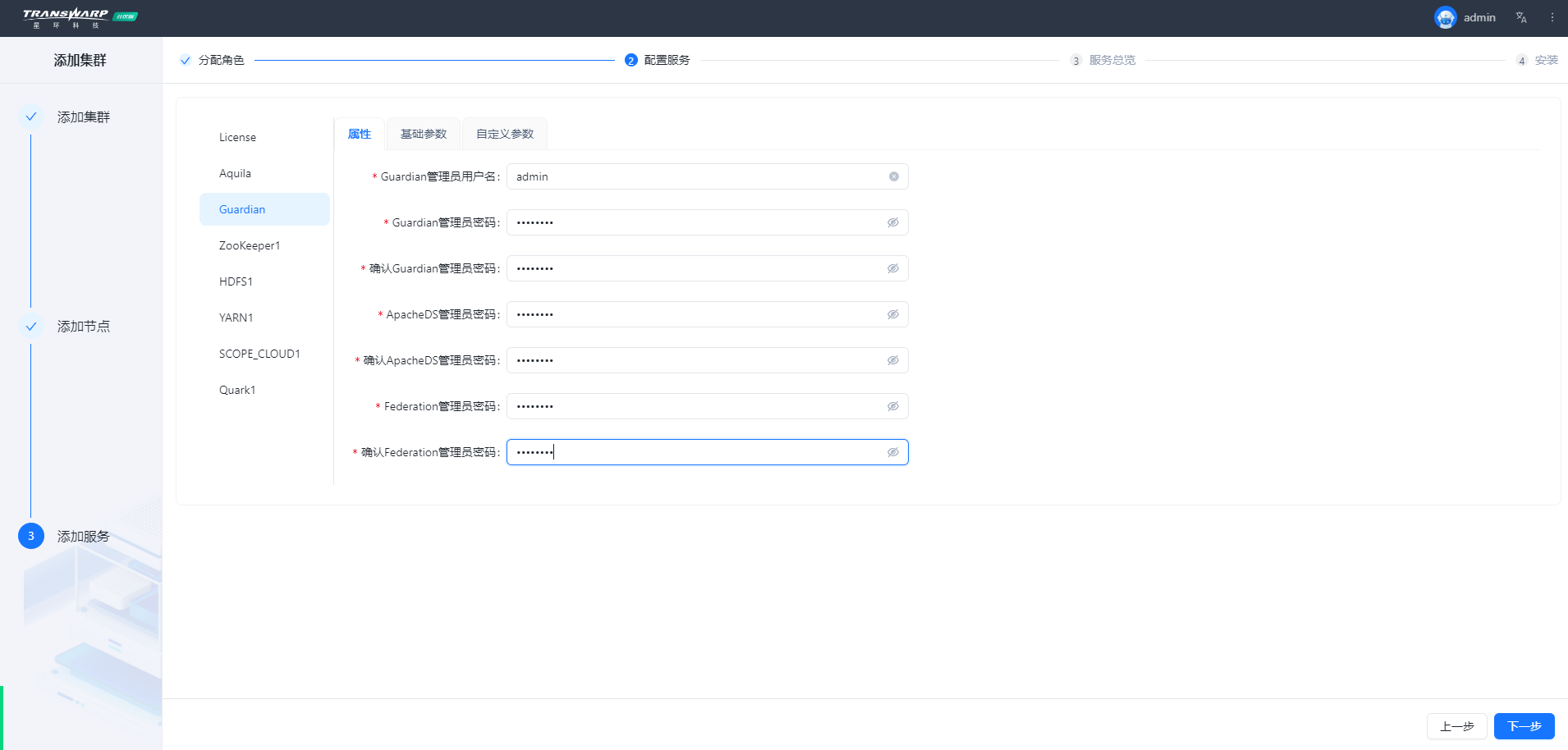
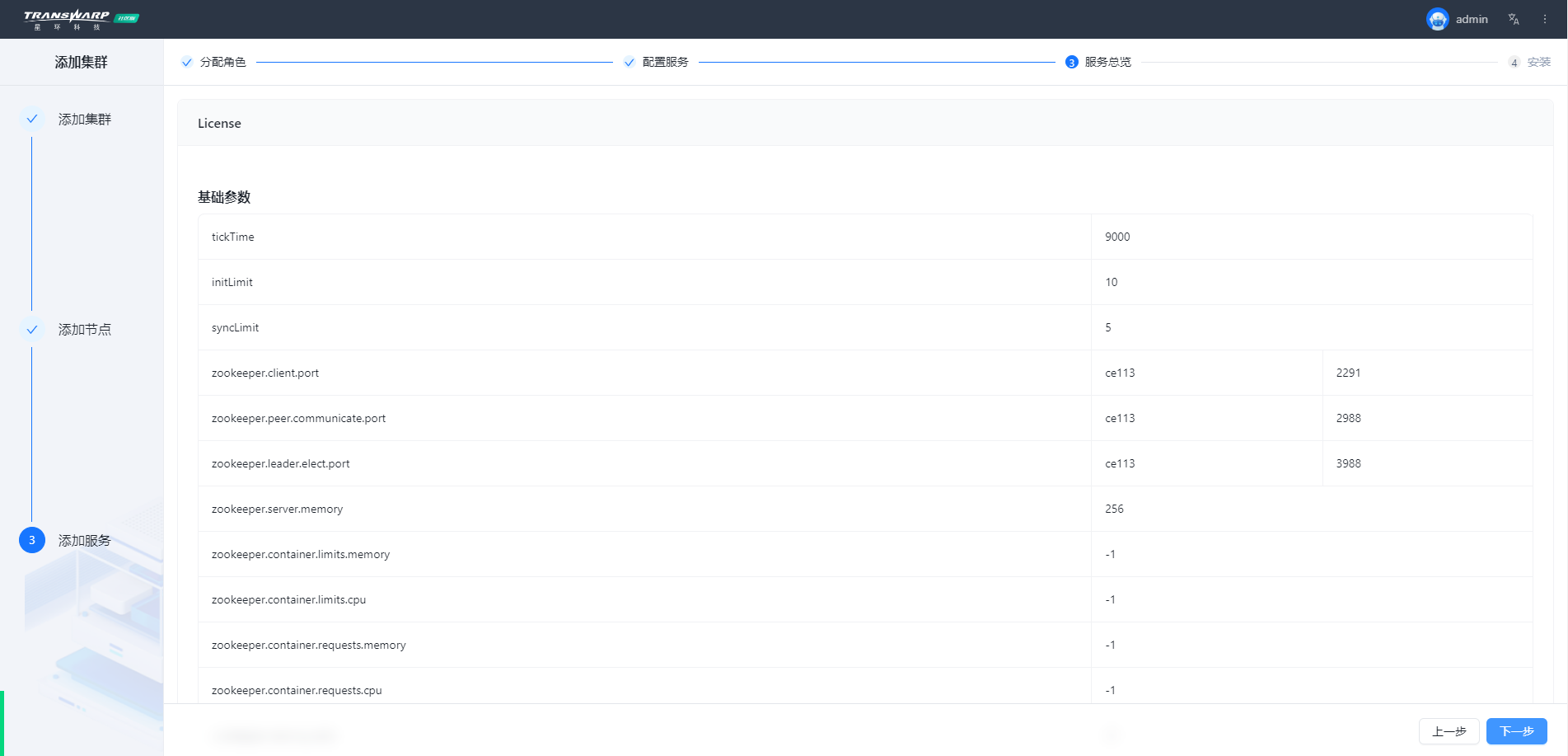
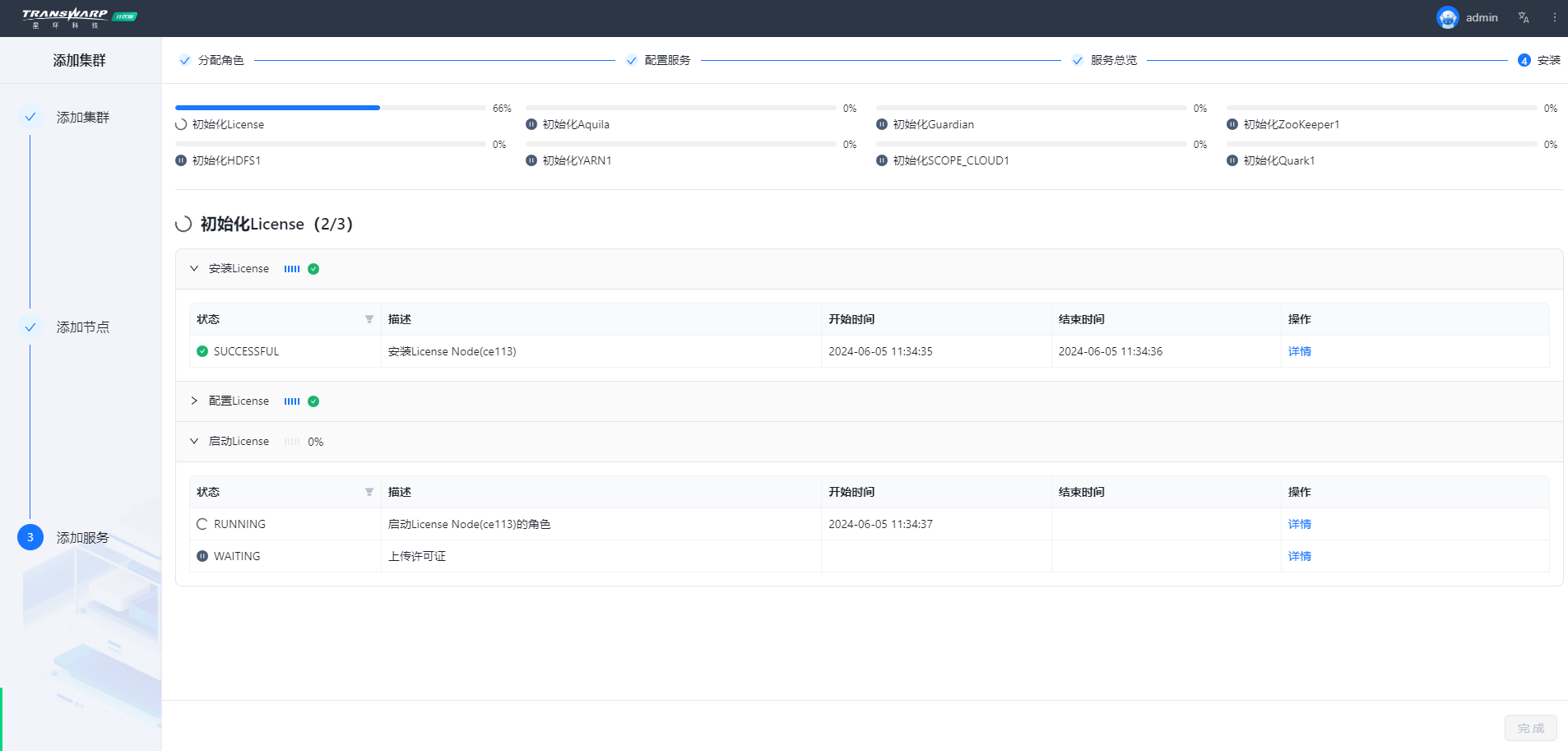
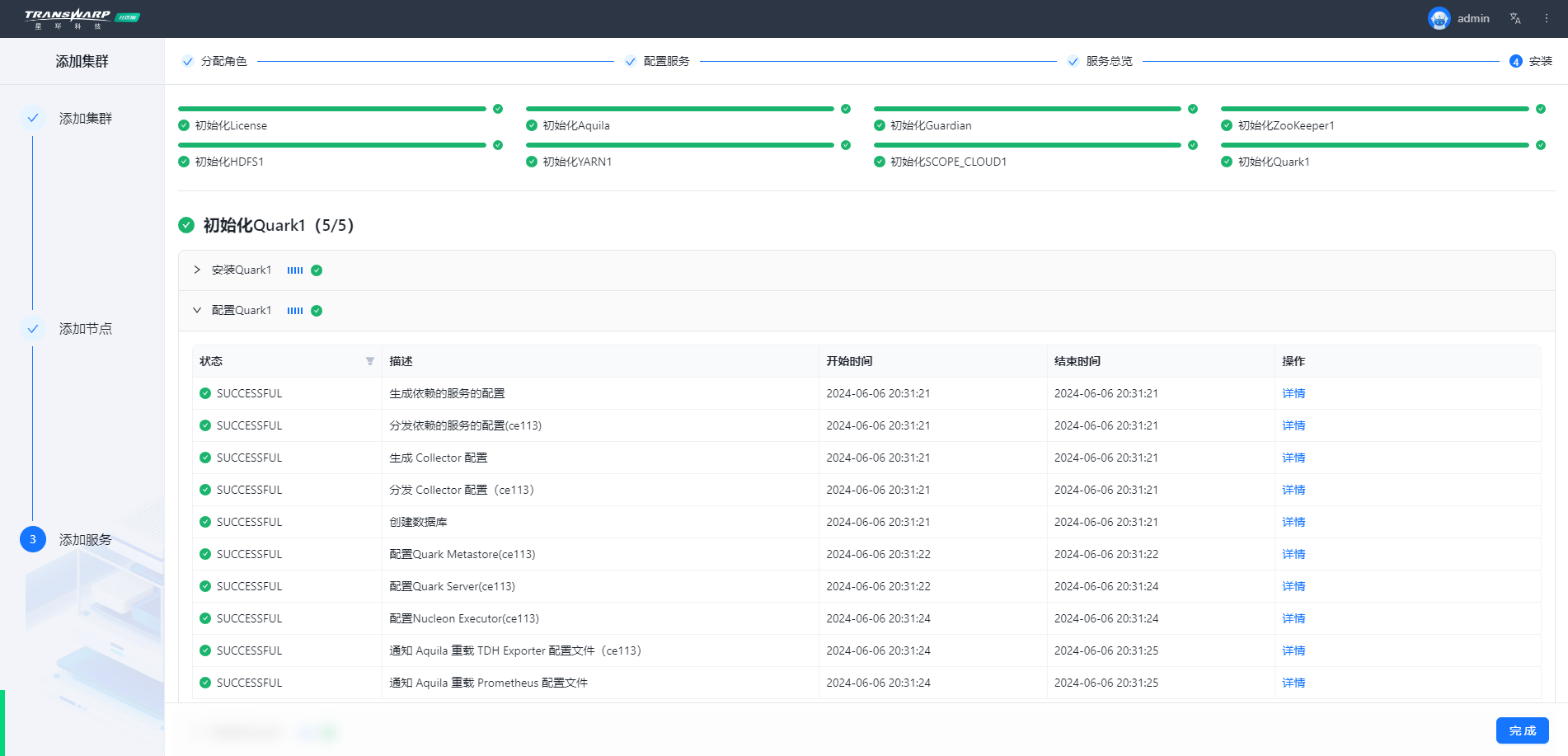
安装完成自助申请许可证即可使用,教程请参考:手册
使用示例
演示示例1. Scope多态语法之rest 语法
创建/删除索引
创建索引
curl -X PUT "localhost:9200/my_index?pretty" -H 'Content-Type: application/json' -d'{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 3
},
"mappings": {
"default_type_": {
"properties": {
"id": { "type": "integer" },
"title": { "type": "text" },
"body": { "type": "text" },
"date": { "type": "date" },
"views": { "type": "integer" },
"tags": { "type": "keyword" }
}
}
}
}
';删除索引
curl -X DELETE "localhost:9200/my_index?pretty";数据插入
单条插入
curl -X PUT "localhost:9200/my_index/default_type_/1?pretty" -H 'Content-Type: application/json' -d'
{
"id": 1,
"title": "Scope for Beginners",
"body": "Learn how to use Scope to search and analyze your data",
"date": "2022-05-09",
"views": 1000,
"tags": ["Scope", "search"]
}
';
curl -X POST "localhost:9200/my_index/default_type_/?pretty" -H 'Content-Type: application/json' -d'
{
"id": 2,
"title": "Advanced Scope",
"body": "Take your Scope skills to the next level",
"date": "2022-05-10",
"views": 500,
"tags": ["Scope", "advanced"]
}
';批量插入
curl -X POST "localhost:9200/my_index/_bulk?pretty" -H 'Content-Type: application/x-ndjson' --data-binary '
{ "index" : {"_index" : "my_index","_type" : "default_type_", "_id" : "bulk_1" } }
{ "id": 3, "title": "Scope Performance Tuning", "body": "Optimize your Scope cluster for better performance", "date": "2022-05-11","views": 750, "tags": ["Scope", "performance"]}
{ "index" : {"_index" : "my_index","_type" : "default_type_", "_id" : "bulk_2" } }
{ "id": 4, "title": "Scope Security", "body": "Learn how to secure your Scope cluster", "date": "2022-05-12", "views": 250, "tags": ["Scope", "security"]}
{ "index" : {"_index" : "my_index","_type" : "default_type_", "_id" : "bulk_3" } }
{"id": 5, "title": "Scope Monitoring", "body": "Monitor your Scope cluster with the Elastic Stack", "date": "2022-05-13", "views": 100, "tags": ["Scope", "monitoring"]}
';数据查询
Case1
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"body": "Scope"
}
},
"sort": {
"date": { "order": "desc" }
}
}
';Case2
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"range": {
"date": {
"gte": "2022-05-11"
}
}
},
"sort": {
"views": { "order": "asc" }
}
}
';基础运维指令
查看集群状态
curl -X GET "localhost:9200/_cluster/health?pretty";查看索引状态
curl -X GET "localhost:9200/_cat/indices/my_index?v";查看节点状态
curl -X GET "localhost:9200/_cat/nodes?v";查看分片状态
curl -X GET "localhost:9200/_cat/shards/my_index?v";演示示例2. Scope多态语法之sql语法
创建/删除索引
删除/创建数据库(非必要)
drop database if exists DDL_Scope_DB CASCADE;
create database if not exists DDL_Scope_DB;
use DDL_Scope_DB;删除索引
drop table if exists sql_demo;创建索引
create table sql_demo(
id string,
title string has analyzer 'standard',
author string,
price double,
description string has analyzer 'mmseg'
)stored as scope
with shard number 5 replication 3
tblproperties('scope.key.column'='id');数据插入
单条插入
insert into sql_demo select '1', '百年孤独', '加西亚·马尔克斯', 39.80, '一部代表魔幻现实主义文学巅峰的经典小说。' from system.dual;
insert into sql_demo values('2', '围城', '钱钟书', 29.80, '一部中国现代文学经典,讽刺了旧中国知识分子的冷嘲热讽和无可奈何。');批量插入
batchinsert into sql_demo batchvalues(
values('3', '骆驼祥子', '老舍', 22.80, '一部反映旧中国社会底层生活的文学作品,展现了社会底层人民的生活和奋斗。'),
values('4', '茶花女', '小仲马', 18.80, '一部法国浪漫主义文学代表作,描绘了一个上层社会女性的生活和爱情。')
);数据查询
数据查询
select * from sql_demo;
select * from sql_demo order by price;
select * from sql_demo where contains(description,'中国');和 rest 一致性
curl -ushiva:shiva -X GET "localhost:9200/ddl_scope_db.sql_demo/_mapping?pretty";
curl -ushiva:shiva -X GET "local:9200/ddl_scope_db.sql_demo/_settings/?pretty&filter_path=**.number_of_shards,**.number_of_replicas";
curl -ushiva:shiva -X GET "local:9200/ddl_scope_db.sql_demo/_search?pretty";演示示例3. Scope多态语法之JAVA语法
创建索引
CreateIndexRequest request = new CreateIndexRequest("create_index_demo");
request.settings(Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 1)
);
CreateIndexRequest indexRequest = request.mapping(
" {\n" +
" \"" + "default_type_" + "\": {\n" +
" \"properties\": {\n" +
" \"c_text\": {\n" +
" \"type\": \"text\"\n" +
" },\n" +
" \"c_string_mf\": {\n" +
" \"type\": \"keyword\"\n" +
" }\n" +
" }\n" +
" }\n" +
" }",
XContentType.JSON);
CreateIndexResponse createIndexResponse = highLevelClient.indices().create(indexRequest,RequestOptions.DEFAULT);删除索引
DeleteIndexRequest request = new DeleteIndexRequest("create_index_demo");
AcknowledgedResponse deleteIndexResponse = highLevelClient.indices().delete(request,RequestOptions.DEFAULT);数据插入
单条插入
IndexRequest request = new IndexRequest(
"my_index",
"default_type_",
"6");
String jsonString = "{\n" +
" \"id\": 6,\n" +
" \"title\": \"Scope for Beginners\",\n" +
" \"body\": \"Learn how to use Scope to search and analyze your data\",\n" +
" \"date\": \"2022-05-09\",\n" +
" \"views\": 1000,\n" +
" \"tags\": [\"Scope\", \"search\"]\n" +
"}";
IndexRequest source = request.source(jsonString, XContentType.JSON);
IndexResponse index = highLevelClient.index(source, RequestOptions.DEFAULT);批量插入
String jsonString1 = "{\"id\": 3, \"title\": \"Scope Performance Tuning\", \"body\": \"Optimize your Scope cluster for better performance\", \"date\": \"2022-05-11\",\"views\": 750, \"tags\": [\"Scope\", \"performance\"]}";
String jsonString2 = "{\"id\": 4, \"title\": \"Scope Security\", \"body\": \"Learn how to secure your Scope cluster\", \"date\": \"2022-05-12\", \"views\": 250, \"tags\": [\"Scope\", \"security\"]}";
String jsonString3 = "{\"id\": 5, \"title\": \"Scope Monitoring\", \"body\": \"Monitor your Scope cluster with the Elastic Stack\", \"date\": \"2022-05-13\", \"views\": 100, \"tags\": [\"Scope\", \"monitoring\"]}";
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("my_index", "default_type_", "3").source(jsonString1,XContentType.JSON));
request.add(new IndexRequest("my_index", "default_type_", "4").source(jsonString2,XContentType.JSON));
request.add(new IndexRequest("my_index", "default_type_", "5").source(jsonString3,XContentType.JSON));
BulkResponse bulkResponses = highLevelClient.bulk(request,RequestOptions.DEFAULT);数据查询
term查询
SearchRequest searchRequest = new SearchRequest().indices("my_index").types("default_type_");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("body", "how"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);match查询(对查询条件进行分词)
SearchRequest searchRequest = new SearchRequest().indices("my_index").types("default_type_");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("body","Monitor Optimize"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);boolean查询(多条件查询)
SearchRequest searchRequest = new SearchRequest().indices("my_index").types("default_type_");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SearchSourceBuilder mustQuery = searchSourceBuilder.query(QueryBuilders.boolQuery());
mustQuery.query(QueryBuilders.termQuery("body","cluster"));
mustQuery.query(QueryBuilders.termQuery("date","2022-05-13"));
searchRequest.source(mustQuery);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);演示示例4. 索引与分词机制
在使用搜索引擎的过程中,通常会涉及诸多属于,如segment/doc/term/token/shard/index等等,其中,segment/doc/term/token都是lucene中的概念。理解这些术语有助于更深入的了解和使用搜索引擎。
- document:索引和搜索的主要数据载体,对应写入scope中的一个doc。通常以JSON格式存储;
- field:document中的各个字段,每个字段都有自己的数据类型,使用者可以针对字段内容设置是否对其分词或使用分析器进行分词;
- term词项:搜索时的一个单位,代表文本中的某个词;
- token词条:词项(term)在字段(field)中的一次出现,包括词项的文本、开始和结束的位移、类型等信息;
- index索引:以index为单位组织数据(document),一个index中的数据通常具有相似的特征。需要注意这里的index与宽表数据库中的索引(全局索引)不是一个概念,这里指的是搜索引擎中的数据对象。
lucene内部使用的是倒排索引的数据结构,将词项(term)映射到文档(document)。例如下图的3个document,进行分词后可以搜索引擎可以很快速的返回的下方问题的答案
- 查询document id为 2的document?
- 查询包含choice的document?
- 查询有choice又有is的document?
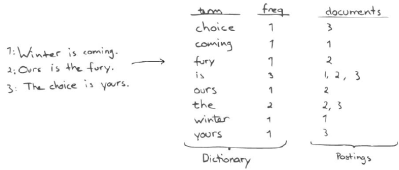
那么是如何实现这一能力的?
分词器介绍
将文档切分成一系列有意义的单词(term/token)的过程称之为分词,其中,分词器则负责这一过程,以建立索引进行高效的搜索和分析。
选择一个合适的分词器可以很大程度上提高检索效率,当前比较常见的分词器有以下几种:
英文分词器
- 标准分词器(Standard Tokenizer)标准分词器类型是standard,用于大多数欧洲语言,使用Unicode文本分割算法对文档进行分词;
- 空格分词器(Whitespace Tokenizer)空格分词类型是whitespace,在空格处分割文本;
- 小写分词器(Lowercase Tokenizer)小写分词器类型是lowercase,在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务;
- 经典分词器(Classic Tokenizer)经典分词器类型是classic,基于语法规则对文本进行分词,对英语文档分词非常有用,在处理首字母缩写,公司名称,邮件地址和Internet主机名上效果非常好;
- ...
中文分词器
- IK:普及率最广。IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和最大词长两种切分模式;支持英文字母、数字、中文词汇等分词处理。支持用户词典扩展定义。
- Pinyin 分词器:pinyin分词器可以让用户输入拼音,就能查找到相关的关键词。比如在某个商城搜索中,输入yonghui,就能匹配到永辉。这样的体验还是非常好的。
- ...
不同的分词器会产生不同的分词结果,产生不同的索引,所以相同的查询条件会产生不同的结果。
举例说明生活中全文检索的应用实例:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
全文检索就是把文本中的内容拆分成若干个关键词,然后根据关键词创建索引。查询时,根据关键词查询索引,最终找到包含关键词的文章。整个过程类似于查字典的过程。
Scope分词器-Standard
创建索引
curl -X DELETE "localhost:19200/blog_index1?pretty";
curl -X PUT "localhost:19200/blog_index1?pretty" -H 'Content-Type: application/json' -d'{
"mappings": {
"default_type_": {
"properties": {
"id": {
"type": "integer"
},
"blog_name": {
"type": "text",
"analyzer": "standard"
},
"blog_name_english": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}
';数据写入
curl -X POST "localhost:19200/blog_index1/_bulk?pretty" -H 'Content-Type: application/x-ndjson' --data-binary '
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_1" } }
{ "id": 1, "blog_name": "Scope 介绍", "blog_name_english": "Introduction to Scope"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_2" } }
{ "id": 2, "blog_name": "Scope 高级搜索", "blog_name_english": "Advanced Searching in Scope"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_3" } }
{ "id": 3, "blog_name": "全文检索技术比较", "blog_name_english": "Comparison of Full-Text Search Technologies"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 4, "blog_name": "Scope 数据聚合", "blog_name_english": "Scope Data Aggregation"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 5, "blog_name": "分布式数据库架构", "blog_name_english": "Introduction to NoSQL Databases"}
';英文检索
curl -XGET "localhost:19200/blog_index1/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_name_english": "search"
}
}
}';中文检索
curl -XGET "localhost:19200/blog_index1/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_name": "搜索"
}
}
}';Scope分词器-ik_max_word
创建索引
curl -X DELETE "localhost:9200/blog_index2?pretty";
curl -X PUT "localhost:9200/blog_index2?pretty" -H 'Content-Type: application/json' -d'{
"mappings": {
"default_type_": {
"properties": {
"id": {
"type": "integer"
},
"blog_name": {
"type": "text",
"analyzer": "ik_max_word"
},
"blog_name_english": {
"type": "text",
"analyzer": "standard"
},
"blog_summary": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
';数据写入
curl -X POST "localhost:9200/blog_index2/_bulk?pretty" -H 'Content-Type: application/x-ndjson' --data-binary '
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_1" } }
{ "id": 1, "blog_name": "Scope 介绍", "blog_name_english": "Introduction to Scope", "blog_summary": "Scope 是一个分布式搜索引擎,用于快速和可扩展地搜索和分析大量数据。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_2" } }
{ "id": 2, "blog_name": "Scope 高级搜索", "blog_name_english": "Advanced Searching in Scope", "blog_summary": "学习如何使用 Scope 进行高级搜索和优化查询性能的技巧。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_3" } }
{ "id": 3, "blog_name": "全文检索技术比较", "blog_name_english": "Comparison of Full-Text Search Technologies", "blog_summary": "比较不同全文检索技术之间的性能和功能,了解它们在搜索算法和评估方面的优缺点。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 4, "blog_name": "Scope 数据聚合", "blog_name_english": "Scope Data Aggregation", "blog_summary": "使用 Scope 进行数据聚合和分析,了解如何从大量数据中提取有价值的信息。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 5, "blog_name": "分布式数据库架构", "blog_name_english": "Introduction to NoSQL Databases", "blog_summary": "探索分布式数据库架构的原理和设计,了解如何在分布式环境中实现数据一致性和高可用性。"}
';英文检索
curl -XGET "localhost:9200/blog_index2/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_name_english": "search"
}
}
}';中文检索
curl -XGET "localhost:9200/blog_index2/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_name": "搜索"
}
}
}';
curl -XGET "localhost:9200/blog_index2/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_summary": "搜索"
}
}
}';
更多使用教程可以参考 Scope使用手册 ,欢迎体验开发版Scope。
友情链接:
前言
近日,社区版家族正式发布V2024.5版本,其中,社区开发版系列重磅发布Scope开发版以及StellarDB开发版。
为了可以让大家更进一步了解产品,本系列文章从背景概念开始介绍,深入浅出的为读者介绍Scope的优势以及能力,在上一篇文章中为读者介绍了基础知识、Scope的技术优势以及能力,本篇文章将继续为读者介绍如何安装部署以及使用。
安装与部署
企业版
社区开发版
安装教程
友情提示:安装前请仔细查看安装手册注意事项章节,下方内容仅供参考
步骤一 将从官网下载下来的产品包解压后上传至安装环境
- 产品包名称:TDH-Scope-Standalone-Community-Transwarp-2024.5-X86_64-final.tar.gz
步骤二 执行下述命令进行解压,解压后将出现一个镜像tar包
tar -zxf TDH-Scope-Standalone-Community-Transwarp-2024.5-X86_64-final.tar.gz
步骤三 执行下述命令加载镜像
docker load -i scope-2024.5.tar
步骤四 执行下方指令启动容器并运行镜像,运行格式为:
docker run -d --network host -v <本地目录路径>:/opt/transwarp --privileged <镜像名>
-v参数配置了TDH挂载的本地磁盘路径。该路径下会保存产品运行过程中产生的配置conf、数据data、日志log。再次提醒请不要随意改动做好备份,以及确保该路径下没有历史版本的数据文件。
操作示例图
步骤五 容器启动后需等待30s至2分钟
步骤六 浏览器访问管理节点8180端口
打开客户端浏览器(推荐使用Google Chrome浏览器),访问http://host:8180,比如http://172.16.3.108:8180/。访问这个地址,您会看到下面的登录页面。
初次登录以admin的身份登录,密码也是admin。
步骤七 按照向导提示进行集群部署与配置即可
安装完成自助申请许可证即可使用,教程请参考:手册
使用示例
演示示例1. Scope多态语法之rest 语法
创建/删除索引
创建索引
curl -X PUT "localhost:9200/my_index?pretty" -H 'Content-Type: application/json' -d'{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 3
},
"mappings": {
"default_type_": {
"properties": {
"id": { "type": "integer" },
"title": { "type": "text" },
"body": { "type": "text" },
"date": { "type": "date" },
"views": { "type": "integer" },
"tags": { "type": "keyword" }
}
}
}
}
';删除索引
curl -X DELETE "localhost:9200/my_index?pretty";数据插入
单条插入
curl -X PUT "localhost:9200/my_index/default_type_/1?pretty" -H 'Content-Type: application/json' -d'
{
"id": 1,
"title": "Scope for Beginners",
"body": "Learn how to use Scope to search and analyze your data",
"date": "2022-05-09",
"views": 1000,
"tags": ["Scope", "search"]
}
';
curl -X POST "localhost:9200/my_index/default_type_/?pretty" -H 'Content-Type: application/json' -d'
{
"id": 2,
"title": "Advanced Scope",
"body": "Take your Scope skills to the next level",
"date": "2022-05-10",
"views": 500,
"tags": ["Scope", "advanced"]
}
';批量插入
curl -X POST "localhost:9200/my_index/_bulk?pretty" -H 'Content-Type: application/x-ndjson' --data-binary '
{ "index" : {"_index" : "my_index","_type" : "default_type_", "_id" : "bulk_1" } }
{ "id": 3, "title": "Scope Performance Tuning", "body": "Optimize your Scope cluster for better performance", "date": "2022-05-11","views": 750, "tags": ["Scope", "performance"]}
{ "index" : {"_index" : "my_index","_type" : "default_type_", "_id" : "bulk_2" } }
{ "id": 4, "title": "Scope Security", "body": "Learn how to secure your Scope cluster", "date": "2022-05-12", "views": 250, "tags": ["Scope", "security"]}
{ "index" : {"_index" : "my_index","_type" : "default_type_", "_id" : "bulk_3" } }
{"id": 5, "title": "Scope Monitoring", "body": "Monitor your Scope cluster with the Elastic Stack", "date": "2022-05-13", "views": 100, "tags": ["Scope", "monitoring"]}
';数据查询
Case1
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"body": "Scope"
}
},
"sort": {
"date": { "order": "desc" }
}
}
';Case2
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"range": {
"date": {
"gte": "2022-05-11"
}
}
},
"sort": {
"views": { "order": "asc" }
}
}
';基础运维指令
查看集群状态
curl -X GET "localhost:9200/_cluster/health?pretty";查看索引状态
curl -X GET "localhost:9200/_cat/indices/my_index?v";查看节点状态
curl -X GET "localhost:9200/_cat/nodes?v";查看分片状态
curl -X GET "localhost:9200/_cat/shards/my_index?v";演示示例2. Scope多态语法之sql语法
创建/删除索引
删除/创建数据库(非必要)
drop database if exists DDL_Scope_DB CASCADE;
create database if not exists DDL_Scope_DB;
use DDL_Scope_DB;删除索引
drop table if exists sql_demo;创建索引
create table sql_demo(
id string,
title string has analyzer 'standard',
author string,
price double,
description string has analyzer 'mmseg'
)stored as scope
with shard number 5 replication 3
tblproperties('scope.key.column'='id');数据插入
单条插入
insert into sql_demo select '1', '百年孤独', '加西亚·马尔克斯', 39.80, '一部代表魔幻现实主义文学巅峰的经典小说。' from system.dual;
insert into sql_demo values('2', '围城', '钱钟书', 29.80, '一部中国现代文学经典,讽刺了旧中国知识分子的冷嘲热讽和无可奈何。');批量插入
batchinsert into sql_demo batchvalues(
values('3', '骆驼祥子', '老舍', 22.80, '一部反映旧中国社会底层生活的文学作品,展现了社会底层人民的生活和奋斗。'),
values('4', '茶花女', '小仲马', 18.80, '一部法国浪漫主义文学代表作,描绘了一个上层社会女性的生活和爱情。')
);数据查询
数据查询
select * from sql_demo;
select * from sql_demo order by price;
select * from sql_demo where contains(description,'中国');和 rest 一致性
curl -ushiva:shiva -X GET "localhost:9200/ddl_scope_db.sql_demo/_mapping?pretty";
curl -ushiva:shiva -X GET "local:9200/ddl_scope_db.sql_demo/_settings/?pretty&filter_path=**.number_of_shards,**.number_of_replicas";
curl -ushiva:shiva -X GET "local:9200/ddl_scope_db.sql_demo/_search?pretty";演示示例3. Scope多态语法之JAVA语法
创建索引
CreateIndexRequest request = new CreateIndexRequest("create_index_demo");
request.settings(Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 1)
);
CreateIndexRequest indexRequest = request.mapping(
" {\n" +
" \"" + "default_type_" + "\": {\n" +
" \"properties\": {\n" +
" \"c_text\": {\n" +
" \"type\": \"text\"\n" +
" },\n" +
" \"c_string_mf\": {\n" +
" \"type\": \"keyword\"\n" +
" }\n" +
" }\n" +
" }\n" +
" }",
XContentType.JSON);
CreateIndexResponse createIndexResponse = highLevelClient.indices().create(indexRequest,RequestOptions.DEFAULT);删除索引
DeleteIndexRequest request = new DeleteIndexRequest("create_index_demo");
AcknowledgedResponse deleteIndexResponse = highLevelClient.indices().delete(request,RequestOptions.DEFAULT);数据插入
单条插入
IndexRequest request = new IndexRequest(
"my_index",
"default_type_",
"6");
String jsonString = "{\n" +
" \"id\": 6,\n" +
" \"title\": \"Scope for Beginners\",\n" +
" \"body\": \"Learn how to use Scope to search and analyze your data\",\n" +
" \"date\": \"2022-05-09\",\n" +
" \"views\": 1000,\n" +
" \"tags\": [\"Scope\", \"search\"]\n" +
"}";
IndexRequest source = request.source(jsonString, XContentType.JSON);
IndexResponse index = highLevelClient.index(source, RequestOptions.DEFAULT);批量插入
String jsonString1 = "{\"id\": 3, \"title\": \"Scope Performance Tuning\", \"body\": \"Optimize your Scope cluster for better performance\", \"date\": \"2022-05-11\",\"views\": 750, \"tags\": [\"Scope\", \"performance\"]}";
String jsonString2 = "{\"id\": 4, \"title\": \"Scope Security\", \"body\": \"Learn how to secure your Scope cluster\", \"date\": \"2022-05-12\", \"views\": 250, \"tags\": [\"Scope\", \"security\"]}";
String jsonString3 = "{\"id\": 5, \"title\": \"Scope Monitoring\", \"body\": \"Monitor your Scope cluster with the Elastic Stack\", \"date\": \"2022-05-13\", \"views\": 100, \"tags\": [\"Scope\", \"monitoring\"]}";
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("my_index", "default_type_", "3").source(jsonString1,XContentType.JSON));
request.add(new IndexRequest("my_index", "default_type_", "4").source(jsonString2,XContentType.JSON));
request.add(new IndexRequest("my_index", "default_type_", "5").source(jsonString3,XContentType.JSON));
BulkResponse bulkResponses = highLevelClient.bulk(request,RequestOptions.DEFAULT);数据查询
term查询
SearchRequest searchRequest = new SearchRequest().indices("my_index").types("default_type_");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("body", "how"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);match查询(对查询条件进行分词)
SearchRequest searchRequest = new SearchRequest().indices("my_index").types("default_type_");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("body","Monitor Optimize"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);boolean查询(多条件查询)
SearchRequest searchRequest = new SearchRequest().indices("my_index").types("default_type_");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SearchSourceBuilder mustQuery = searchSourceBuilder.query(QueryBuilders.boolQuery());
mustQuery.query(QueryBuilders.termQuery("body","cluster"));
mustQuery.query(QueryBuilders.termQuery("date","2022-05-13"));
searchRequest.source(mustQuery);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);演示示例4. 索引与分词机制
在使用搜索引擎的过程中,通常会涉及诸多属于,如segment/doc/term/token/shard/index等等,其中,segment/doc/term/token都是lucene中的概念。理解这些术语有助于更深入的了解和使用搜索引擎。
- document:索引和搜索的主要数据载体,对应写入scope中的一个doc。通常以JSON格式存储;
- field:document中的各个字段,每个字段都有自己的数据类型,使用者可以针对字段内容设置是否对其分词或使用分析器进行分词;
- term词项:搜索时的一个单位,代表文本中的某个词;
- token词条:词项(term)在字段(field)中的一次出现,包括词项的文本、开始和结束的位移、类型等信息;
- index索引:以index为单位组织数据(document),一个index中的数据通常具有相似的特征。需要注意这里的index与宽表数据库中的索引(全局索引)不是一个概念,这里指的是搜索引擎中的数据对象。
lucene内部使用的是倒排索引的数据结构,将词项(term)映射到文档(document)。例如下图的3个document,进行分词后可以搜索引擎可以很快速的返回的下方问题的答案
- 查询document id为 2的document?
- 查询包含choice的document?
- 查询有choice又有is的document?
那么是如何实现这一能力的?
分词器介绍
将文档切分成一系列有意义的单词(term/token)的过程称之为分词,其中,分词器则负责这一过程,以建立索引进行高效的搜索和分析。
选择一个合适的分词器可以很大程度上提高检索效率,当前比较常见的分词器有以下几种:
英文分词器
- 标准分词器(Standard Tokenizer)标准分词器类型是standard,用于大多数欧洲语言,使用Unicode文本分割算法对文档进行分词;
- 空格分词器(Whitespace Tokenizer)空格分词类型是whitespace,在空格处分割文本;
- 小写分词器(Lowercase Tokenizer)小写分词器类型是lowercase,在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务;
- 经典分词器(Classic Tokenizer)经典分词器类型是classic,基于语法规则对文本进行分词,对英语文档分词非常有用,在处理首字母缩写,公司名称,邮件地址和Internet主机名上效果非常好;
- ...
中文分词器
- IK:普及率最广。IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和最大词长两种切分模式;支持英文字母、数字、中文词汇等分词处理。支持用户词典扩展定义。
- Pinyin 分词器:pinyin分词器可以让用户输入拼音,就能查找到相关的关键词。比如在某个商城搜索中,输入yonghui,就能匹配到永辉。这样的体验还是非常好的。
- ...
不同的分词器会产生不同的分词结果,产生不同的索引,所以相同的查询条件会产生不同的结果。
举例说明生活中全文检索的应用实例:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
全文检索就是把文本中的内容拆分成若干个关键词,然后根据关键词创建索引。查询时,根据关键词查询索引,最终找到包含关键词的文章。整个过程类似于查字典的过程。
Scope分词器-Standard
创建索引
curl -X DELETE "localhost:19200/blog_index1?pretty";
curl -X PUT "localhost:19200/blog_index1?pretty" -H 'Content-Type: application/json' -d'{
"mappings": {
"default_type_": {
"properties": {
"id": {
"type": "integer"
},
"blog_name": {
"type": "text",
"analyzer": "standard"
},
"blog_name_english": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}
';数据写入
curl -X POST "localhost:19200/blog_index1/_bulk?pretty" -H 'Content-Type: application/x-ndjson' --data-binary '
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_1" } }
{ "id": 1, "blog_name": "Scope 介绍", "blog_name_english": "Introduction to Scope"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_2" } }
{ "id": 2, "blog_name": "Scope 高级搜索", "blog_name_english": "Advanced Searching in Scope"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_3" } }
{ "id": 3, "blog_name": "全文检索技术比较", "blog_name_english": "Comparison of Full-Text Search Technologies"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 4, "blog_name": "Scope 数据聚合", "blog_name_english": "Scope Data Aggregation"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 5, "blog_name": "分布式数据库架构", "blog_name_english": "Introduction to NoSQL Databases"}
';英文检索
curl -XGET "localhost:19200/blog_index1/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_name_english": "search"
}
}
}';中文检索
curl -XGET "localhost:19200/blog_index1/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_name": "搜索"
}
}
}';Scope分词器-ik_max_word
创建索引
curl -X DELETE "localhost:9200/blog_index2?pretty";
curl -X PUT "localhost:9200/blog_index2?pretty" -H 'Content-Type: application/json' -d'{
"mappings": {
"default_type_": {
"properties": {
"id": {
"type": "integer"
},
"blog_name": {
"type": "text",
"analyzer": "ik_max_word"
},
"blog_name_english": {
"type": "text",
"analyzer": "standard"
},
"blog_summary": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
';数据写入
curl -X POST "localhost:9200/blog_index2/_bulk?pretty" -H 'Content-Type: application/x-ndjson' --data-binary '
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_1" } }
{ "id": 1, "blog_name": "Scope 介绍", "blog_name_english": "Introduction to Scope", "blog_summary": "Scope 是一个分布式搜索引擎,用于快速和可扩展地搜索和分析大量数据。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_2" } }
{ "id": 2, "blog_name": "Scope 高级搜索", "blog_name_english": "Advanced Searching in Scope", "blog_summary": "学习如何使用 Scope 进行高级搜索和优化查询性能的技巧。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_3" } }
{ "id": 3, "blog_name": "全文检索技术比较", "blog_name_english": "Comparison of Full-Text Search Technologies", "blog_summary": "比较不同全文检索技术之间的性能和功能,了解它们在搜索算法和评估方面的优缺点。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 4, "blog_name": "Scope 数据聚合", "blog_name_english": "Scope Data Aggregation", "blog_summary": "使用 Scope 进行数据聚合和分析,了解如何从大量数据中提取有价值的信息。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 5, "blog_name": "分布式数据库架构", "blog_name_english": "Introduction to NoSQL Databases", "blog_summary": "探索分布式数据库架构的原理和设计,了解如何在分布式环境中实现数据一致性和高可用性。"}
';英文检索
curl -XGET "localhost:9200/blog_index2/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_name_english": "search"
}
}
}';中文检索
curl -XGET "localhost:9200/blog_index2/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_name": "搜索"
}
}
}';
curl -XGET "localhost:9200/blog_index2/_search?pretty" -H 'Content-Type: application/json' -d'{
"query": {
"term": {
"blog_summary": "搜索"
}
}
}';
更多使用教程可以参考 Scope使用手册 ,欢迎体验开发版Scope。
 登录后可评论
登录后可评论








.jpg)



