搜索引擎数据库系列(二)——搜索引擎相关技术点:全文检索、倒排索引、分片
系列文章链接:
搜索引擎数据库系列(三)——Scope技术优势详解及案例展示
概述
在了解完搜索引擎数据库的逻辑、应用场景、优势以及未来发展趋势之后,我们来深入探究一下搜索引擎的核心技术点:全文检索。除此之外,为了增强索引对文档查询速度的提升作用,搜索引擎数据库采用了一种新的索引方法,这种索引方法就是倒排索引。
Scope作为国产化替代ES的搜索引擎数据库,具备以下所涉及的技术点,与此同时,Scope具备5个方面的技术优势,分别为:拓展性、高性能、安全与高可用、易用性、自主可控。本文将分别说明5个方面的内容,并在下一篇文章中更加详细地阐述产品在架构、功能、产品策略等方面的技术优势,这些优势将与前文中提及的发展趋势息息相关。
全文检索
在了解全文检索之前,我们先来讨论下其主要分析的数据是什么?生活中的数据总体分为两种结构:结构化数据(指具有固定格式或有限长度的数据,如数据库、元数据等)和非结构化数据(指不定长度或无固定格式的数据,如:邮件、word文档等)。
对于结构化数据的搜索,通常使用顺序扫描,例如使用SQL查询语句对数据库的搜索、利用windows搜索对文件名,类型,修改时间进行搜索等。对于非结构化数据,可以使用顺序扫描,但是顺序扫描在查询包含某字符串的文件时,需要与一个文档一个文档的检索,从头看到尾,如果此文档中包含目标字符串,则文档为查询目标,接着查询下一个文档,直到所有文档扫描完成。该查询方式效率非常慢,在面对大规模的非结构化数据时,其查询对资源要求很高,因此出现了另一种更适合于文本、音频、视频等非结构化数据查询的检索方式——全文检索。
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。全文检索首先将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对有一定结构的数据进行搜索,从而达到搜索相对较快的目的。从非结构化数据中提取出的然后重新组织的信息,我们称之索引。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
核心名词概念解释
搜索引擎核心术语包括:index 索引、Type分类、Document文档、Fields字段等
- Index(索引)
以index为单位组织数据(Document),一个index中的数据通常具有相似的特征。例如:为员工信息创建一个index,或者为商品信息创建一个index。与宽表数据库中的索引(全局索引)不是一个概念,这里指的是搜索引擎中的数据对象。
- Type(分类)
Type是index的逻辑分类,如何分类由用户决定,一个index可以定义一个或多个type。例如:员工信息index可按部门分类,包括财务部type、销售部type、研发部type等。
- Document(文档)
搜索引擎中最基础的数据单元,以JSON格式存储。例如:员工的基本信息{"name":"zhangsan","age":30,"on_board_data":"2016-10-01",...}可作为一个Document,保存到员工信息Index中。
- Field(字段)
Document 中的数据存储在field中。字段是搜索引擎中最小的独立单元数据,每个字段都有自己的数据类型,并可对字段设置是否分析、分词器等。核心的数据类型有string、Numeric、DateDate、Boolean、Binary、Range等等,复杂类型有Object、Nested。
- 分词
通过分词器,将文档拆分成一系列单词(term/token)的过程称之为分词,搜索引擎根据分词后的关键词,建立倒排索引,并将原文档中的词转换为标准形式,以提高查全率,如:“电脑”转换成“计算机”。
分词器种类举例
(1) 标准分词器(Standard analyzer):根据Unicode Consortium的定义的单词边界(word boundaries)来切分文本,然后去掉大部分标点符号。最后,把所有词转为小写。
(2) 简单分词器(Simple analyzer):当simple分析器遇到非字母的字符时,它会将文本划分为多个术语,它小写所有术语,对于中文和亚洲很多国家的语言来说是无用的。
(3) 空格分词器(Whitespace analyzer):空格分词器依据空格切分文本。它不转换小写。
(4) 电子邮件分词器(UAX URL Email analyzer):针对email和url地址进行关键内容的标记。
(5) 经典分词器(Classic analyzer):可对首字母缩写词,公司名称,电子邮件地址和互联网主机名进行特殊处理,但是,这些规则并不总是有效,并且此关键词生成器不适用于英语以外的大多数其他语言。
(6)语言分词器(Language analyzer):特定语言分词器适用于很多语言。它们能够考虑到特定语言的特性。例如, english 分词器自带一套英语停用词库——像 and 或 the 这些与语义无关的通用词。这些词被移除后,因为语法规则的存在,英语单词的主体含义依旧能被理解。
不同的分词器会产生不同的分词结果,产生不同的索引,所以相同的查询条件会产生不同的结果。
举例说明生活中全文检索的应用实例:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
全文检索就是把文本中的内容拆分成若干个关键词,然后根据关键词创建索引。查询时,根据关键词查询索引,最终找到包含关键词的文章。整个过程类似于查字典的过程。如下图是对文件搜索的索引:
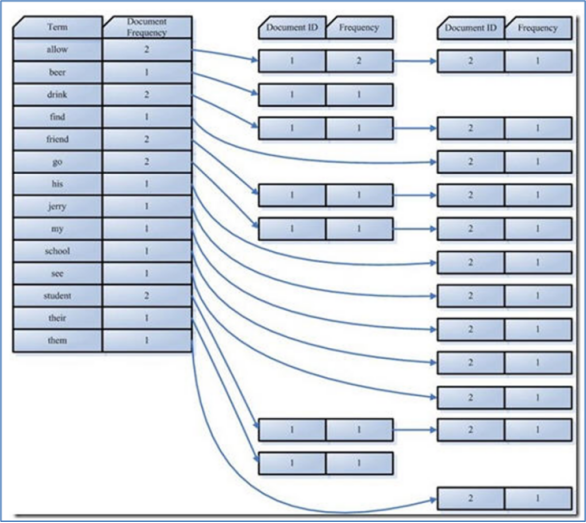
上图中,Term是从目标数据源中提取出来的词,在进行全文检索时是通过搜索索引(搜索索引中的词)从而找到索引对应的文件即目标数据源。 经过几年的发展,全文检索从最初的字符串匹配程序已经演进到能对超大文本、语音、图像、活动影像等非结构化数据进行综合管理的大型软件。
倒排索引
搜索引擎对文档进行全文检索时,通常使用的是倒排索引(inverted index)来实现。倒排索引同B+树索引一样,也是一种索引结构。倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。它存储了单词与单词自身在一个或多个文档中所在的位置之间的映射。通常利用关联数组实现,其具体有两种表现形式:
- Inverted file index,其表现形式为{单词,单词所在文档的ID}
- Full inverted index,其表现形式为{单词,(单词所在文档的ID,在具体文档中的具体位置)}
下面将举例说明,表a存储的内容如下所示:
| DocumentId | Text |
| 1 | Transwarp is a technology innovation company. |
| 2 | Where there is a will, there is a way. |
| 3 | Young is the author of the article. |
| 4 | Tom is an author. |
DocumentId表示正在进行全文检索的文档ID,Text表示文档中的内容,用户需要对以上文档进行全文检索。例如,查询其中某个词出现的文档位置,或者同时出现两个there的文档。
Inverted file index的关联数组,其存储内容如下:
| Number | Text | Documents | Number | Text | Documents |
| 1 | transwarp | 1 | 10 | way | 2 |
| 2 | is | 1,2,3,4, | 11 | young | 3 |
| 3 | a | 1,2 | 12 | the | 3 |
| 4 | technology | 1 | 13 | author | 3,4 |
| 5 | innovation | 1 | 14 | of | 3 |
| 6 | company | 1 | 15 | article | 3 |
| 7 | where | 2 | 16 | tom | 4 |
| 8 | there | 2 | 17 | an | 4 |
| 9 | will | 2 |
可以看到单词author出现在文档3和文档4中,单词company出现在文档1中,之后再进行全文查询就简单很多,可以根据Documents得到包含查询关键字的文档。对于Inverted file index,其仅存取文档id,而full inverted index存储的是对(pair),即(DocumentId,Position),其倒排索引如下:
| Number | Text | Documents | Number | Text | Documents |
| 1 | transwarp | (1:1) | 10 | way | (2:9) |
| 2 | is | (1:2),(2:3),(2:7),(3:2),(4:2) | 11 | young | (3:1) |
| 3 | a | (1:3),(2:4),(2:8) | 12 | the | (3:3),(3:6) |
| 4 | technology | (1:4) | 13 | author | (3:4),(4:4) |
| 5 | innovation | (1:5) | 14 | of | (3:5) |
| 6 | company | (1:6) | 15 | article | (3:7) |
| 7 | where | (2:1) | 16 | tom | (4:1) |
| 8 | there | (2:2),(2:6) | 17 | an | (4:3) |
| 9 | will | (2:5) |
Full inverted index还存储了单词所在的位置信息,如technology这个单词出现在(1:4),即文档1的4个单词为technology。相比之下,Full inverted index占用更多的空间,但是能更好地定位数据的位置,并扩充其他的搜索特性。
分片(Shards)
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切分可以称之为数据的垂直(纵向)切分。另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
分片相关概念
(1)逻辑库:数据库中间件可视为一个或多个数据库集群构成的逻辑库。
(2)逻辑表:在分布式数据库中,应用程序操作的表即逻辑表。逻辑表可以基于数据切分存在于多个分片库,或非切分、单一表形式。
(3)分片表:存储大量数据,需切分存储于多个数据库的表。所有分片构成完整数据集。
(4)非分片表:无需切分,其数据完整存储于单一数据库中的表。
(5)分片节点:分片表切分后,各分片所在的数据库即分片节点。
(6)节点主机:一个或多个分片节点可位于同一机器,称节点主机。为平衡负载,高读写节点应分布在不同主机。
(7)分片规则:数据切分需遵循规则,决定表如何分配至各分片。合适的分片规则可降低后续处理难度。
分片在搜索引擎中的应用为每个分片都是一个Lucene索引实例,可以将其视作一个独立的搜索引擎,它能够对搜索引擎集群中的数据子集进行索引并处理相关查询。分片分为两种:主分片(Primary Shard)、副本分片(Replica Shard)。
主分片:主分片是用于存储所有数据的部分,决定了文档存储数量的上限。一旦在创建索引时指定了主分片数量,就无法更改。这是因为文档通过其主键(默认)被哈希到对应的主分片上,类似于RDBMS的分库分表路由策略。如果更改主分片数量,将无法定位到具体的主分片。在映射时,可以设置number_of_shards值,最大默认为1024。
副本分片:可以为每个主分片指定任意数量的副本分片,根据实际硬件资源而定。每个分片都可以处理查询,因此可以通过增加副本分片的资源来提升系统的处理能力。在映射时,可以通过number_of_replicas参数来设置每个主分片的副本分片数量。请注意,为了容错(防止节点主机宕机导致数据丢失),主分片和副本分片不能位于同一节点上,以防止因节点宕机而导致部分数据丢失。
Scope技术优势
1. 高拓展
Scope2.5支持集群和服务的在线水平拓展,扩容时保障当前集群业务正常运作,支持百节点+大规模集群的部署。同时,得益于产品本身的容器化技术,实现了资源的灵活调度和隔离以及弹性扩缩容能力。
2. 高性能
在性能上,Scope延续了搜索引擎的传统核心需求,即毫秒级检索。同时提供了多进程的架构机制以及实时接入能力,实现每个节点的Scope服务可以更加充分地利用系统资源来响应各类读写请求,最终提升产品任务处理的效率与并发度。此外,Scope支持与TDH中的实时流处理引擎Slipstream进行无缝衔接,已完成数据实时接入,并提供实时、微批等多种入库方式。在对接开源产品方面,Scope支持Flink、Kafka等开源产品通过标准化接口的形式将数据实时写入Scope中。
3. 安全可靠
Scope具有企业级安全保证,提供用户认证、权限管理、传输加密等功能,保障集群数据安全。同时,基于Raft一致性协议的存储引擎,Scope同样具备自动的故障迁移能力及数据自动修复能力,有效简化运维成本。
4. 易用性
Scope支持对接Elasticsearch的相关生态,不仅是接口、访问方式,也包括插件以及其他配套生态组件,例如logstash等。同时,Scope提供标准SQL语法的支持与检索语义,有助于提升易用性,并连通TDH多类型数据存储间的数据流转,可以跨存储端实现数据导入导出以及查询。
5. 自主可控
Scope为国产化自研产品,做到代码自主可控。同时适配各类型国产CPU、操作系统等底层生态,确保兼容国产硬件层面兼容性。
以上为Scope的主要技术优势说明,在满足搜索引擎数据库通用能力的同时,实现了独有的符合发展趋势的优势点,具备极强的市场竞争力。在接下来的文章中,将着重阐述Scope在实现架构升级、读写分离、存储优化、数据流转、数据安全、自主可控等方面的技术实现逻辑。此外,下一篇文章中还展示Scope低成本实现Elasticsearch国产化替代和升级的客户案例,满足Elasticsearch各类检索需求的同时,提供更好的产品和服务。
系列文章链接:
搜索引擎数据库系列(三)——Scope技术优势详解及案例展示
概述
在了解完搜索引擎数据库的逻辑、应用场景、优势以及未来发展趋势之后,我们来深入探究一下搜索引擎的核心技术点:全文检索。除此之外,为了增强索引对文档查询速度的提升作用,搜索引擎数据库采用了一种新的索引方法,这种索引方法就是倒排索引。
Scope作为国产化替代ES的搜索引擎数据库,具备以下所涉及的技术点,与此同时,Scope具备5个方面的技术优势,分别为:拓展性、高性能、安全与高可用、易用性、自主可控。本文将分别说明5个方面的内容,并在下一篇文章中更加详细地阐述产品在架构、功能、产品策略等方面的技术优势,这些优势将与前文中提及的发展趋势息息相关。
全文检索
在了解全文检索之前,我们先来讨论下其主要分析的数据是什么?生活中的数据总体分为两种结构:结构化数据(指具有固定格式或有限长度的数据,如数据库、元数据等)和非结构化数据(指不定长度或无固定格式的数据,如:邮件、word文档等)。
对于结构化数据的搜索,通常使用顺序扫描,例如使用SQL查询语句对数据库的搜索、利用windows搜索对文件名,类型,修改时间进行搜索等。对于非结构化数据,可以使用顺序扫描,但是顺序扫描在查询包含某字符串的文件时,需要与一个文档一个文档的检索,从头看到尾,如果此文档中包含目标字符串,则文档为查询目标,接着查询下一个文档,直到所有文档扫描完成。该查询方式效率非常慢,在面对大规模的非结构化数据时,其查询对资源要求很高,因此出现了另一种更适合于文本、音频、视频等非结构化数据查询的检索方式——全文检索。
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。全文检索首先将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对有一定结构的数据进行搜索,从而达到搜索相对较快的目的。从非结构化数据中提取出的然后重新组织的信息,我们称之索引。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
核心名词概念解释
搜索引擎核心术语包括:index 索引、Type分类、Document文档、Fields字段等
- Index(索引)
以index为单位组织数据(Document),一个index中的数据通常具有相似的特征。例如:为员工信息创建一个index,或者为商品信息创建一个index。与宽表数据库中的索引(全局索引)不是一个概念,这里指的是搜索引擎中的数据对象。
- Type(分类)
Type是index的逻辑分类,如何分类由用户决定,一个index可以定义一个或多个type。例如:员工信息index可按部门分类,包括财务部type、销售部type、研发部type等。
- Document(文档)
搜索引擎中最基础的数据单元,以JSON格式存储。例如:员工的基本信息{"name":"zhangsan","age":30,"on_board_data":"2016-10-01",...}可作为一个Document,保存到员工信息Index中。
- Field(字段)
Document 中的数据存储在field中。字段是搜索引擎中最小的独立单元数据,每个字段都有自己的数据类型,并可对字段设置是否分析、分词器等。核心的数据类型有string、Numeric、DateDate、Boolean、Binary、Range等等,复杂类型有Object、Nested。
- 分词
通过分词器,将文档拆分成一系列单词(term/token)的过程称之为分词,搜索引擎根据分词后的关键词,建立倒排索引,并将原文档中的词转换为标准形式,以提高查全率,如:“电脑”转换成“计算机”。
分词器种类举例
(1) 标准分词器(Standard analyzer):根据Unicode Consortium的定义的单词边界(word boundaries)来切分文本,然后去掉大部分标点符号。最后,把所有词转为小写。
(2) 简单分词器(Simple analyzer):当simple分析器遇到非字母的字符时,它会将文本划分为多个术语,它小写所有术语,对于中文和亚洲很多国家的语言来说是无用的。
(3) 空格分词器(Whitespace analyzer):空格分词器依据空格切分文本。它不转换小写。
(4) 电子邮件分词器(UAX URL Email analyzer):针对email和url地址进行关键内容的标记。
(5) 经典分词器(Classic analyzer):可对首字母缩写词,公司名称,电子邮件地址和互联网主机名进行特殊处理,但是,这些规则并不总是有效,并且此关键词生成器不适用于英语以外的大多数其他语言。
(6)语言分词器(Language analyzer):特定语言分词器适用于很多语言。它们能够考虑到特定语言的特性。例如, english 分词器自带一套英语停用词库——像 and 或 the 这些与语义无关的通用词。这些词被移除后,因为语法规则的存在,英语单词的主体含义依旧能被理解。
不同的分词器会产生不同的分词结果,产生不同的索引,所以相同的查询条件会产生不同的结果。
举例说明生活中全文检索的应用实例:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
全文检索就是把文本中的内容拆分成若干个关键词,然后根据关键词创建索引。查询时,根据关键词查询索引,最终找到包含关键词的文章。整个过程类似于查字典的过程。如下图是对文件搜索的索引:
上图中,Term是从目标数据源中提取出来的词,在进行全文检索时是通过搜索索引(搜索索引中的词)从而找到索引对应的文件即目标数据源。 经过几年的发展,全文检索从最初的字符串匹配程序已经演进到能对超大文本、语音、图像、活动影像等非结构化数据进行综合管理的大型软件。
倒排索引
搜索引擎对文档进行全文检索时,通常使用的是倒排索引(inverted index)来实现。倒排索引同B+树索引一样,也是一种索引结构。倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。它存储了单词与单词自身在一个或多个文档中所在的位置之间的映射。通常利用关联数组实现,其具体有两种表现形式:
- Inverted file index,其表现形式为{单词,单词所在文档的ID}
- Full inverted index,其表现形式为{单词,(单词所在文档的ID,在具体文档中的具体位置)}
下面将举例说明,表a存储的内容如下所示:
| DocumentId | Text |
| 1 | Transwarp is a technology innovation company. |
| 2 | Where there is a will, there is a way. |
| 3 | Young is the author of the article. |
| 4 | Tom is an author. |
DocumentId表示正在进行全文检索的文档ID,Text表示文档中的内容,用户需要对以上文档进行全文检索。例如,查询其中某个词出现的文档位置,或者同时出现两个there的文档。
Inverted file index的关联数组,其存储内容如下:
| Number | Text | Documents | Number | Text | Documents |
| 1 | transwarp | 1 | 10 | way | 2 |
| 2 | is | 1,2,3,4, | 11 | young | 3 |
| 3 | a | 1,2 | 12 | the | 3 |
| 4 | technology | 1 | 13 | author | 3,4 |
| 5 | innovation | 1 | 14 | of | 3 |
| 6 | company | 1 | 15 | article | 3 |
| 7 | where | 2 | 16 | tom | 4 |
| 8 | there | 2 | 17 | an | 4 |
| 9 | will | 2 |
可以看到单词author出现在文档3和文档4中,单词company出现在文档1中,之后再进行全文查询就简单很多,可以根据Documents得到包含查询关键字的文档。对于Inverted file index,其仅存取文档id,而full inverted index存储的是对(pair),即(DocumentId,Position),其倒排索引如下:
| Number | Text | Documents | Number | Text | Documents |
| 1 | transwarp | (1:1) | 10 | way | (2:9) |
| 2 | is | (1:2),(2:3),(2:7),(3:2),(4:2) | 11 | young | (3:1) |
| 3 | a | (1:3),(2:4),(2:8) | 12 | the | (3:3),(3:6) |
| 4 | technology | (1:4) | 13 | author | (3:4),(4:4) |
| 5 | innovation | (1:5) | 14 | of | (3:5) |
| 6 | company | (1:6) | 15 | article | (3:7) |
| 7 | where | (2:1) | 16 | tom | (4:1) |
| 8 | there | (2:2),(2:6) | 17 | an | (4:3) |
| 9 | will | (2:5) |
Full inverted index还存储了单词所在的位置信息,如technology这个单词出现在(1:4),即文档1的4个单词为technology。相比之下,Full inverted index占用更多的空间,但是能更好地定位数据的位置,并扩充其他的搜索特性。
分片(Shards)
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切分可以称之为数据的垂直(纵向)切分。另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
分片相关概念
(1)逻辑库:数据库中间件可视为一个或多个数据库集群构成的逻辑库。
(2)逻辑表:在分布式数据库中,应用程序操作的表即逻辑表。逻辑表可以基于数据切分存在于多个分片库,或非切分、单一表形式。
(3)分片表:存储大量数据,需切分存储于多个数据库的表。所有分片构成完整数据集。
(4)非分片表:无需切分,其数据完整存储于单一数据库中的表。
(5)分片节点:分片表切分后,各分片所在的数据库即分片节点。
(6)节点主机:一个或多个分片节点可位于同一机器,称节点主机。为平衡负载,高读写节点应分布在不同主机。
(7)分片规则:数据切分需遵循规则,决定表如何分配至各分片。合适的分片规则可降低后续处理难度。
分片在搜索引擎中的应用为每个分片都是一个Lucene索引实例,可以将其视作一个独立的搜索引擎,它能够对搜索引擎集群中的数据子集进行索引并处理相关查询。分片分为两种:主分片(Primary Shard)、副本分片(Replica Shard)。
主分片:主分片是用于存储所有数据的部分,决定了文档存储数量的上限。一旦在创建索引时指定了主分片数量,就无法更改。这是因为文档通过其主键(默认)被哈希到对应的主分片上,类似于RDBMS的分库分表路由策略。如果更改主分片数量,将无法定位到具体的主分片。在映射时,可以设置number_of_shards值,最大默认为1024。
副本分片:可以为每个主分片指定任意数量的副本分片,根据实际硬件资源而定。每个分片都可以处理查询,因此可以通过增加副本分片的资源来提升系统的处理能力。在映射时,可以通过number_of_replicas参数来设置每个主分片的副本分片数量。请注意,为了容错(防止节点主机宕机导致数据丢失),主分片和副本分片不能位于同一节点上,以防止因节点宕机而导致部分数据丢失。
Scope技术优势
1. 高拓展
Scope2.5支持集群和服务的在线水平拓展,扩容时保障当前集群业务正常运作,支持百节点+大规模集群的部署。同时,得益于产品本身的容器化技术,实现了资源的灵活调度和隔离以及弹性扩缩容能力。
2. 高性能
在性能上,Scope延续了搜索引擎的传统核心需求,即毫秒级检索。同时提供了多进程的架构机制以及实时接入能力,实现每个节点的Scope服务可以更加充分地利用系统资源来响应各类读写请求,最终提升产品任务处理的效率与并发度。此外,Scope支持与TDH中的实时流处理引擎Slipstream进行无缝衔接,已完成数据实时接入,并提供实时、微批等多种入库方式。在对接开源产品方面,Scope支持Flink、Kafka等开源产品通过标准化接口的形式将数据实时写入Scope中。
3. 安全可靠
Scope具有企业级安全保证,提供用户认证、权限管理、传输加密等功能,保障集群数据安全。同时,基于Raft一致性协议的存储引擎,Scope同样具备自动的故障迁移能力及数据自动修复能力,有效简化运维成本。
4. 易用性
Scope支持对接Elasticsearch的相关生态,不仅是接口、访问方式,也包括插件以及其他配套生态组件,例如logstash等。同时,Scope提供标准SQL语法的支持与检索语义,有助于提升易用性,并连通TDH多类型数据存储间的数据流转,可以跨存储端实现数据导入导出以及查询。
5. 自主可控
Scope为国产化自研产品,做到代码自主可控。同时适配各类型国产CPU、操作系统等底层生态,确保兼容国产硬件层面兼容性。
以上为Scope的主要技术优势说明,在满足搜索引擎数据库通用能力的同时,实现了独有的符合发展趋势的优势点,具备极强的市场竞争力。在接下来的文章中,将着重阐述Scope在实现架构升级、读写分离、存储优化、数据流转、数据安全、自主可控等方面的技术实现逻辑。此外,下一篇文章中还展示Scope低成本实现Elasticsearch国产化替代和升级的客户案例,满足Elasticsearch各类检索需求的同时,提供更好的产品和服务。
 登录后可评论
登录后可评论








.jpg)



