搜索引擎数据库系列(三)——Scope技术优势详解及案例展示
系列文章链接:
概述
Scope作为星环科技自主研发的企业级分布式搜索引擎,为实现拓展性、高性能、安全与高可用、易用性、自主可控5个方面的技术优势,不断优化完善产品架构与产品能力,致力于为用户打造一款集性能、易用、安全为一体的搜索引擎数据库。下文将详细讲解Scope为实现这一目标所采用的技术优化。
1. 架构优化
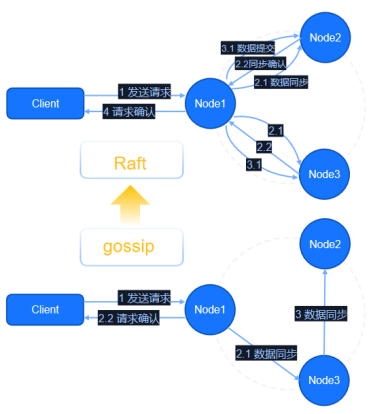
为实现更好的集群稳定性,Scope在分布式层对原有架构进行重构,将共识算法传统的流言传播模式goosip转变为Raft的架构。通过架构的优化,数据的同步逻辑也从过去的最终一致性转变为强一致性。从上图可以看出两类算法的差异。
Raft协议详解: 一致性协议Raft的工作原理及介绍--Raft协议背景及算法剖析
原有goosip架构更偏向于主节点数据写入完成后,返回请求成功的响应,然后在内部做数据同步,最终达到所有节点数据一致的情况,即最终一致性。在该模型下,对于常规的日志等低价值信息比较友好,若存储高价值或不允许丢失的信息,将存在一定风险。例如,当集群中node1节点与集群网络连接断开,其他节点会重新组成集群,选举主节点。但是若node1节点数据并未及时同步,客户层面感知将会是数据丢失,因为其新写入数据在未同步的节点中不存在。同时,当node1恢复连接后加入集群,会因其不是主节点而反向同步其他节点,最终数据彻底丢失。
Scope选择升级Raft架构作为一致性协议,其对于数据同步、写入成功等请求,是在多数节点写入后返回。即使集群中某一节点出现上述失联问题,数据依旧可以被检索到,杜绝数据完全丢失。对于Scope的管理节点,同样采用Raft模式,可以有效地规避集群脑裂,也降低了大规模集群稳定性问题的出现。
2. 全新读写方式与读写分离
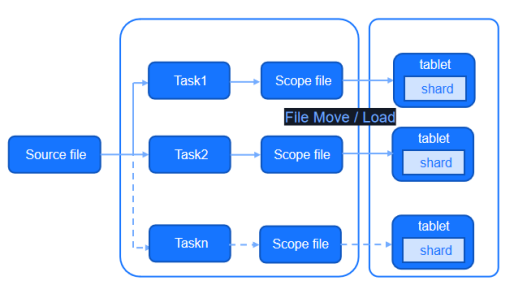
Scope采用类bulkload的写入模式,有效降低读写混合场景对产品带来的压力。在bulkload的写入模式下,写入操作被拆分成两个步骤:首先是数据加工,生成数据库所需的数据格式;其次为数据加载,将生成的文件置于存储目录,使得检索引擎可以读取加载到该数据。一般来说,前者在cpu、内存中开销占比更大,它涉及索引的生成、数据的加工等一系列逻辑;而后者,则以数据传输过程的网络/磁盘开销为主并夹带少量的cpu开销,这部分网络/磁盘的开销对比当前主流的集群配置是可控和低占比的。
根据上述逻辑,将两步骤别放于不同集群或不同的服务器中执行,可以有效降低Scope集群的写入压力,提供更多的资源用于检索,实现一套读写分离的架构。同时,bulkload的写入模式同样适配实时流处理引擎slipstream中。在实时的写入时,实现降低Scope集群开销的效果。
3. 存储优化 资源高效利用
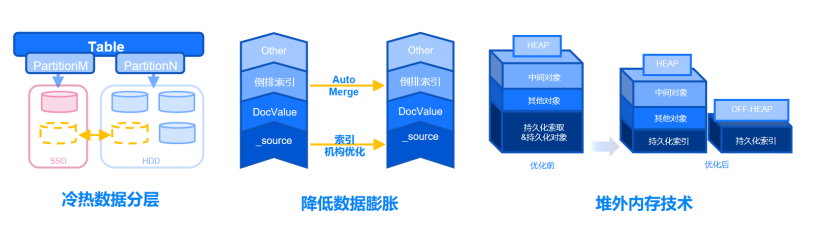
Scope在存储方面做了大量的优化工作,在此着重描述3个典型优化点,分别为冷热数据分层、降低数据膨胀与堆外内存技术。
首先,Scope提供数据标签机制,并以此实现冷热数据分层。支持对节点/磁盘/以及索引数据进行标签化处理。对于分区表或者使用频率不同的表,可以通过标签机制加以区分和存储,实现热数据热存储,冷数据冷存储的效果。同时支持标签的随时更改,实现数据冷热的高效切换。
其次,Scope通过AutoMerge与索引机构优化实现降低数据膨胀。多数搜索引擎为提升检索的性能,选择牺牲存储能力或生成大量索引数据的方式。对比传统数据库或hdfs类大数据存储产品,存储开销会变得很大。Scope提供索引的AutoMerge机制,对于琐碎的索引文件进行自动合并,也进一步对原始的数据文件进行存储结构上的压缩和优化,可以有效降低数据的膨胀系数。
同时,Scope使用Search的off-heap机制,并对该机制进行持续性的优化,将原本堆内存储的部分索引的持久化内容放于堆外。一方面降低堆的使用开销,留出更多资源满足读写需求,另一方面,单机数据量---生成的索引数据数据量---内存可加载的索引数据,三者为正相关的关系,任何一者达到上限意味着节点容量达到上限,而内存往往是最先掣肘的一个因素。对此,Scope将持久化部分放到堆外,意味着可以有更多的数据被加载进来,从而有效地提升了产品的单机容量。
通过上述三个及其他种种技术优化,使得Scope在实际的生产环境中,索引数据的磁盘开销同比降低13%,单机存储规模从ES的5-20TB到达现有的50TB,在部分场景中甚至可以到达100+TB。
4. 完备数据流转
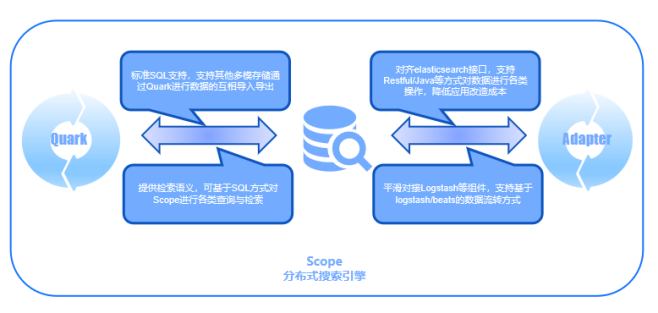
Scope借助星环SQL处理引擎Quark,以及自身的生态适配器Adapter,可以实现完备的数据流转方案。一方面,Scope通过Adapter实现了ES接口的对齐,确保用户可以像使用ES⼀样操作Scope产品。在ES的替换和迁移时,降低用户学习新的数据库接口和重新开发的工作压力。Scope通过Adapter可以很好规避这⼀问题,同时对于分词器之类的插件,以及logstash/beats类组件,Scope同样支持和兼容。
另一方面,Scope依赖Quark搜索引擎,基于标准SQL执行检索语义,可以覆盖大部分检索和入库请求,实现跨存储的数据流通。此外,用户可以将TDH跑批加工的数据,入库到Scope中提供检索业务。Scope基于Quark还支持外表映射的操作,实现一份数据可以通过SQL或API的方式进行处理,以满足不同业务需求和使用者的习惯。
5. 数据安全与保护
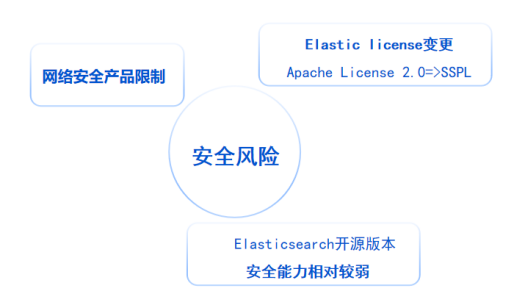

国内用户在使用开源搜索引擎产品时会存有诸多顾虑。首先,美国BIS对于安全产品、漏洞的管制限制,用户所使用的开源产品安全性存疑;其次,用户在使用开源ES时,涉及协议变更问题。协议从apache2.0到SSPL,导致ES在⼀些公有云的使用上受到限制;最后,ES本身安全能力较弱。近年诸多起ES安全导致的数据泄露问题,对用户来说是巨大的潜在风险。
Scope提供的企业级安全保障,从三个维度保护用户的数据安全。第一点,用户认证。Scope基于SASL提供plain 与GSSAPI的认证方式;第二点,数据传输加密。Scope支持基于SSL/TLS的加密方式;第三点,用户权限。Scope提供表/索引级别的权限控制。通过以上三个维度有效保障用户集群数据。
6. 自主可控,多架构适配
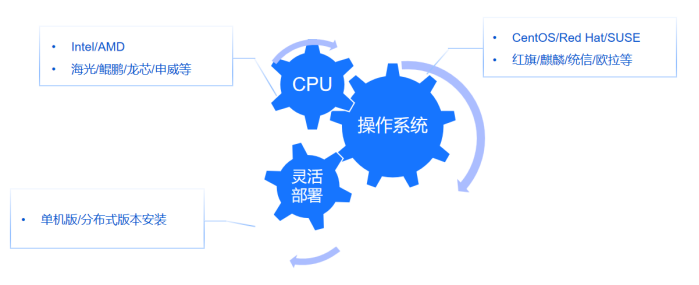
Scope致力于实现对国内主流服务器架构的深度适配,包括长城飞腾、华为泰山和龙芯等系列处理器,以及支持以麒麟操作系统(如中标麒麟、银河麒麟)及统一操作系统UOS为底层运行环境,确保在国家信息技术应用创新(简称信创)要求下满足自主可控的需求。
此外,Scope支持混合架构的部署,允许不同配置、不同架构、不同操作系统的机器在同⼀集群中部署和使用,有效利用集群资源。用户可以通过TDH或TDC部署,并可自主选择单机版本和分布式版本,来应对不同数据体量部署需求。
案例展示:低成本实现Elasticsearch国产化替代和升级
Transwarp Scope聚焦于Elasticsearch检索场景平替,高度兼容Elasticsearch接口,可实现Elasticsearch业务的平滑迁移,如日志检索、全文检索以及数据智能等场景,并在产品稳定性、扩展性、高性能、高可用、成本等方面具有明显的优势。
客户痛点
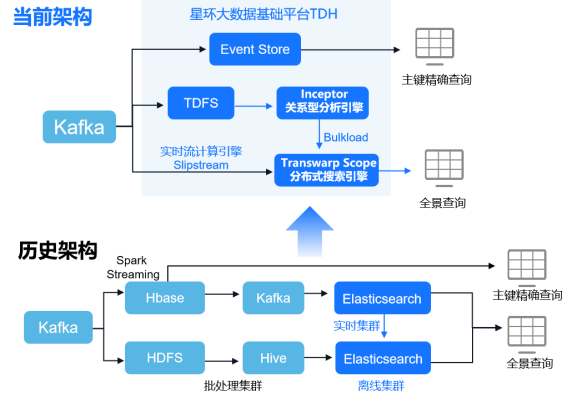
某运营商有基于Hbase的主键精确查询和基于Elasticsearch的全景查询2套业务。在全景查询场景中,客户采用实时和离线2套集群,数据流转复杂,并且随着数据量的高速增长,系统稳定性经常出现问题。当集群出现问题时,Elasticsearch重启需要小时级别,集群恢复速度慢。在性能问题方面,读写资源无法隔离,拖累查询性能。
解决方案
因此,该用户利用星环科技分布式搜索引擎Transwarp Scope替换掉了Elasticsearch,实现了实时和离线业务的统一,通过bulkload和实时流计算引擎Slipstream实现了数据的统一存储和查询。

落地效果
入库方面,过去15+TB的日增离线数据可以快速加载到Scope当中,省去了两套Elasticsearch集群的快照同步环节,入库性能提升4倍。过去T+1模式入库逻辑直接通过微批的方式实现了分钟级延迟,集群的重启时间从6-10小时压缩到了分钟级,大幅度降低了业务中断时间。集群规模上,将过去两套Elasticsearch集群整合成统一的大集群,并且保障100+节点稳定运行,系统架构更加简单,运维成本更低。
如果上述内容对您有帮助,欢迎多多点赞支持~😎


系列文章链接:
概述
Scope作为星环科技自主研发的企业级分布式搜索引擎,为实现拓展性、高性能、安全与高可用、易用性、自主可控5个方面的技术优势,不断优化完善产品架构与产品能力,致力于为用户打造一款集性能、易用、安全为一体的搜索引擎数据库。下文将详细讲解Scope为实现这一目标所采用的技术优化。
1. 架构优化
为实现更好的集群稳定性,Scope在分布式层对原有架构进行重构,将共识算法传统的流言传播模式goosip转变为Raft的架构。通过架构的优化,数据的同步逻辑也从过去的最终一致性转变为强一致性。从上图可以看出两类算法的差异。
Raft协议详解: 一致性协议Raft的工作原理及介绍--Raft协议背景及算法剖析
原有goosip架构更偏向于主节点数据写入完成后,返回请求成功的响应,然后在内部做数据同步,最终达到所有节点数据一致的情况,即最终一致性。在该模型下,对于常规的日志等低价值信息比较友好,若存储高价值或不允许丢失的信息,将存在一定风险。例如,当集群中node1节点与集群网络连接断开,其他节点会重新组成集群,选举主节点。但是若node1节点数据并未及时同步,客户层面感知将会是数据丢失,因为其新写入数据在未同步的节点中不存在。同时,当node1恢复连接后加入集群,会因其不是主节点而反向同步其他节点,最终数据彻底丢失。
Scope选择升级Raft架构作为一致性协议,其对于数据同步、写入成功等请求,是在多数节点写入后返回。即使集群中某一节点出现上述失联问题,数据依旧可以被检索到,杜绝数据完全丢失。对于Scope的管理节点,同样采用Raft模式,可以有效地规避集群脑裂,也降低了大规模集群稳定性问题的出现。
2. 全新读写方式与读写分离
Scope采用类bulkload的写入模式,有效降低读写混合场景对产品带来的压力。在bulkload的写入模式下,写入操作被拆分成两个步骤:首先是数据加工,生成数据库所需的数据格式;其次为数据加载,将生成的文件置于存储目录,使得检索引擎可以读取加载到该数据。一般来说,前者在cpu、内存中开销占比更大,它涉及索引的生成、数据的加工等一系列逻辑;而后者,则以数据传输过程的网络/磁盘开销为主并夹带少量的cpu开销,这部分网络/磁盘的开销对比当前主流的集群配置是可控和低占比的。
根据上述逻辑,将两步骤别放于不同集群或不同的服务器中执行,可以有效降低Scope集群的写入压力,提供更多的资源用于检索,实现一套读写分离的架构。同时,bulkload的写入模式同样适配实时流处理引擎slipstream中。在实时的写入时,实现降低Scope集群开销的效果。
3. 存储优化 资源高效利用
Scope在存储方面做了大量的优化工作,在此着重描述3个典型优化点,分别为冷热数据分层、降低数据膨胀与堆外内存技术。
首先,Scope提供数据标签机制,并以此实现冷热数据分层。支持对节点/磁盘/以及索引数据进行标签化处理。对于分区表或者使用频率不同的表,可以通过标签机制加以区分和存储,实现热数据热存储,冷数据冷存储的效果。同时支持标签的随时更改,实现数据冷热的高效切换。
其次,Scope通过AutoMerge与索引机构优化实现降低数据膨胀。多数搜索引擎为提升检索的性能,选择牺牲存储能力或生成大量索引数据的方式。对比传统数据库或hdfs类大数据存储产品,存储开销会变得很大。Scope提供索引的AutoMerge机制,对于琐碎的索引文件进行自动合并,也进一步对原始的数据文件进行存储结构上的压缩和优化,可以有效降低数据的膨胀系数。
同时,Scope使用Search的off-heap机制,并对该机制进行持续性的优化,将原本堆内存储的部分索引的持久化内容放于堆外。一方面降低堆的使用开销,留出更多资源满足读写需求,另一方面,单机数据量---生成的索引数据数据量---内存可加载的索引数据,三者为正相关的关系,任何一者达到上限意味着节点容量达到上限,而内存往往是最先掣肘的一个因素。对此,Scope将持久化部分放到堆外,意味着可以有更多的数据被加载进来,从而有效地提升了产品的单机容量。
通过上述三个及其他种种技术优化,使得Scope在实际的生产环境中,索引数据的磁盘开销同比降低13%,单机存储规模从ES的5-20TB到达现有的50TB,在部分场景中甚至可以到达100+TB。
4. 完备数据流转
Scope借助星环SQL处理引擎Quark,以及自身的生态适配器Adapter,可以实现完备的数据流转方案。一方面,Scope通过Adapter实现了ES接口的对齐,确保用户可以像使用ES⼀样操作Scope产品。在ES的替换和迁移时,降低用户学习新的数据库接口和重新开发的工作压力。Scope通过Adapter可以很好规避这⼀问题,同时对于分词器之类的插件,以及logstash/beats类组件,Scope同样支持和兼容。
另一方面,Scope依赖Quark搜索引擎,基于标准SQL执行检索语义,可以覆盖大部分检索和入库请求,实现跨存储的数据流通。此外,用户可以将TDH跑批加工的数据,入库到Scope中提供检索业务。Scope基于Quark还支持外表映射的操作,实现一份数据可以通过SQL或API的方式进行处理,以满足不同业务需求和使用者的习惯。
5. 数据安全与保护
国内用户在使用开源搜索引擎产品时会存有诸多顾虑。首先,美国BIS对于安全产品、漏洞的管制限制,用户所使用的开源产品安全性存疑;其次,用户在使用开源ES时,涉及协议变更问题。协议从apache2.0到SSPL,导致ES在⼀些公有云的使用上受到限制;最后,ES本身安全能力较弱。近年诸多起ES安全导致的数据泄露问题,对用户来说是巨大的潜在风险。
Scope提供的企业级安全保障,从三个维度保护用户的数据安全。第一点,用户认证。Scope基于SASL提供plain 与GSSAPI的认证方式;第二点,数据传输加密。Scope支持基于SSL/TLS的加密方式;第三点,用户权限。Scope提供表/索引级别的权限控制。通过以上三个维度有效保障用户集群数据。
6. 自主可控,多架构适配
Scope致力于实现对国内主流服务器架构的深度适配,包括长城飞腾、华为泰山和龙芯等系列处理器,以及支持以麒麟操作系统(如中标麒麟、银河麒麟)及统一操作系统UOS为底层运行环境,确保在国家信息技术应用创新(简称信创)要求下满足自主可控的需求。
此外,Scope支持混合架构的部署,允许不同配置、不同架构、不同操作系统的机器在同⼀集群中部署和使用,有效利用集群资源。用户可以通过TDH或TDC部署,并可自主选择单机版本和分布式版本,来应对不同数据体量部署需求。
案例展示:低成本实现Elasticsearch国产化替代和升级
Transwarp Scope聚焦于Elasticsearch检索场景平替,高度兼容Elasticsearch接口,可实现Elasticsearch业务的平滑迁移,如日志检索、全文检索以及数据智能等场景,并在产品稳定性、扩展性、高性能、高可用、成本等方面具有明显的优势。
客户痛点
某运营商有基于Hbase的主键精确查询和基于Elasticsearch的全景查询2套业务。在全景查询场景中,客户采用实时和离线2套集群,数据流转复杂,并且随着数据量的高速增长,系统稳定性经常出现问题。当集群出现问题时,Elasticsearch重启需要小时级别,集群恢复速度慢。在性能问题方面,读写资源无法隔离,拖累查询性能。
解决方案
因此,该用户利用星环科技分布式搜索引擎Transwarp Scope替换掉了Elasticsearch,实现了实时和离线业务的统一,通过bulkload和实时流计算引擎Slipstream实现了数据的统一存储和查询。
落地效果
入库方面,过去15+TB的日增离线数据可以快速加载到Scope当中,省去了两套Elasticsearch集群的快照同步环节,入库性能提升4倍。过去T+1模式入库逻辑直接通过微批的方式实现了分钟级延迟,集群的重启时间从6-10小时压缩到了分钟级,大幅度降低了业务中断时间。集群规模上,将过去两套Elasticsearch集群整合成统一的大集群,并且保障100+节点稳定运行,系统架构更加简单,运维成本更低。
如果上述内容对您有帮助,欢迎多多点赞支持~😎
 登录后可评论
登录后可评论








.jpg)



