【产品使用示例】使用Aquila Insight运维示例(含演示视频)
友情链接:
- AquilaInsight核心功能及角色概览
- Aquila的核心功能介绍
- DBA Service的核心功能介绍
- 刚部署好Aquila Insight,第一次如何使用
- 如何通过AquilaInsight快速查看每天有哪些异常/慢查询?
- 如何通过Aquila Insight快速定位一个查询为什么慢?
- Aquila 添加自定义监控信息和告警的示例
- 当Quark/Inceptor上跑批变慢、不健康,如何借助星环运维工具AquilaInsight进行排查?
场景示例
背景
作为运维人员,Bob每天的工作是确保运行在TDH上的各个组件正常运转。今天是Bob第一天使用Aquila监控应用,他还设定了一系列自动化的规则辅助自己完成未来的运营。
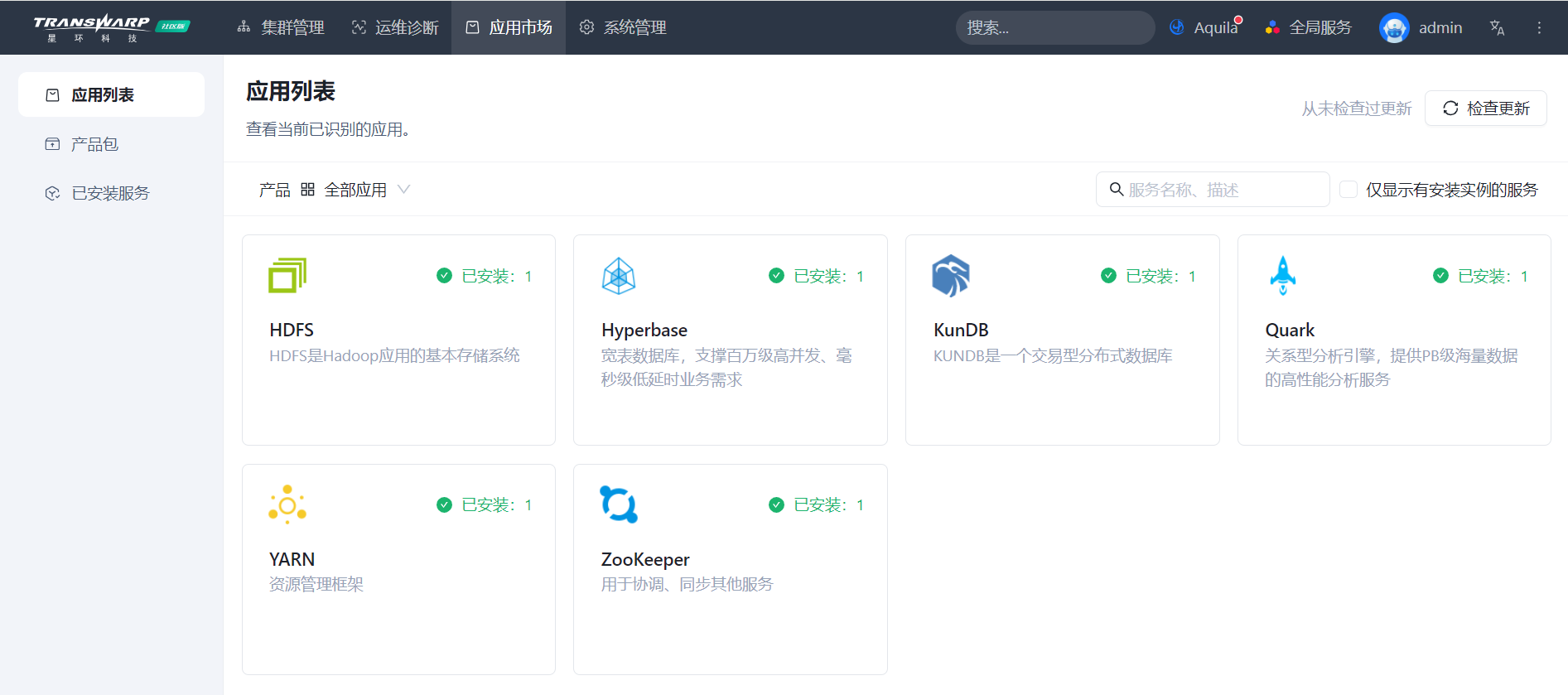
Bob需要对部署了下图中众多应用的集群系统进行运维。
性能监控
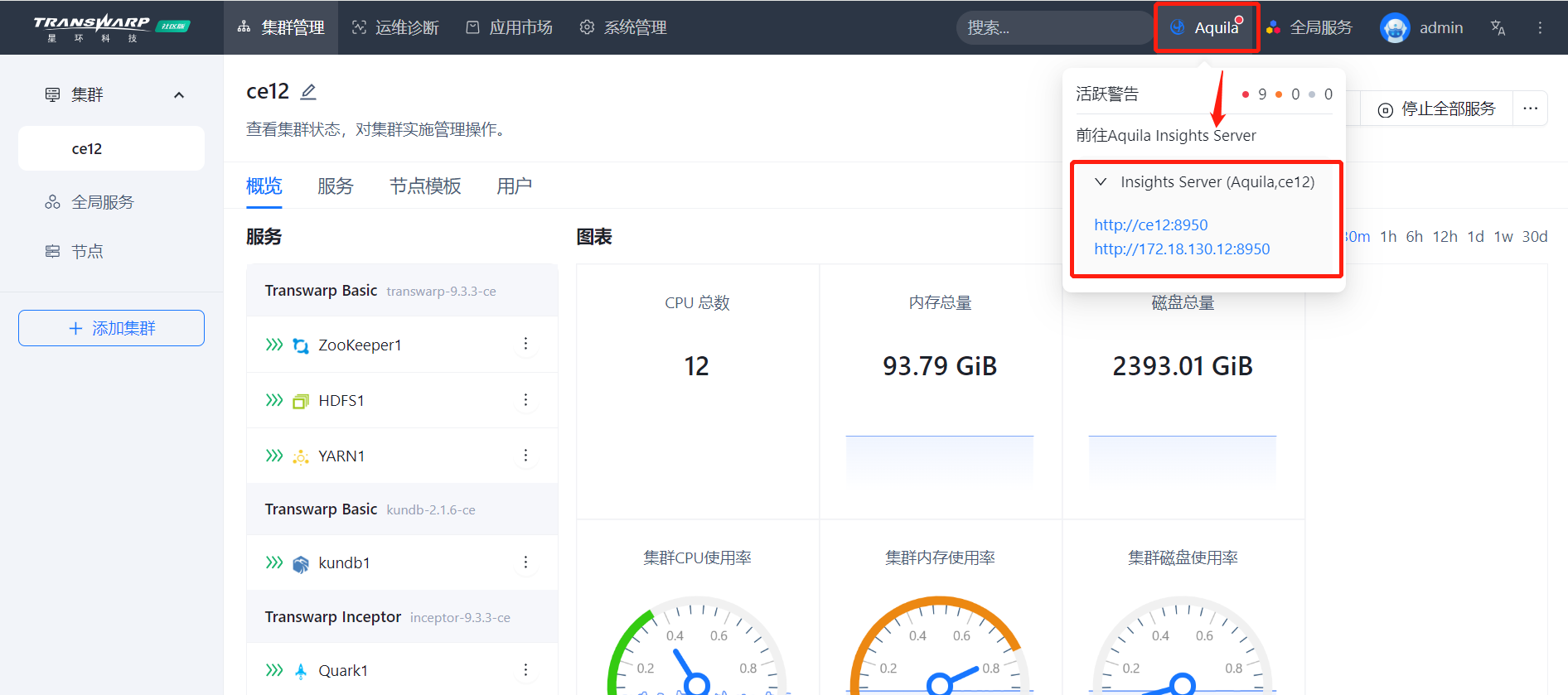
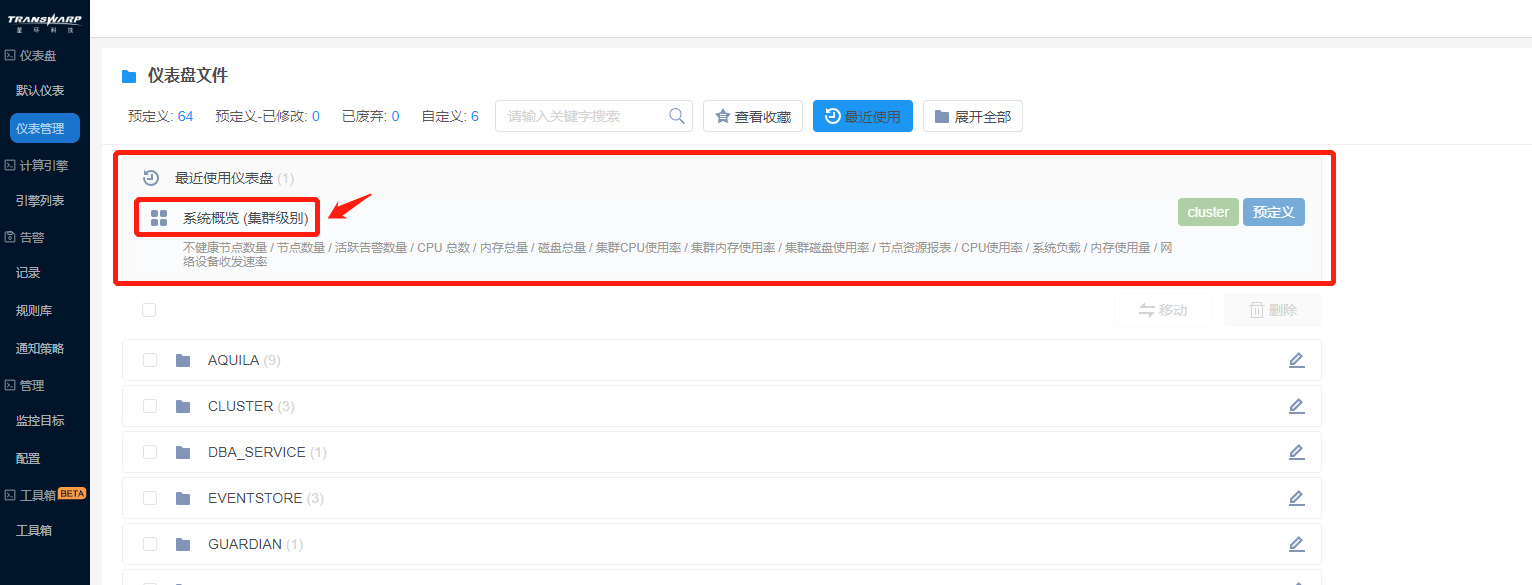
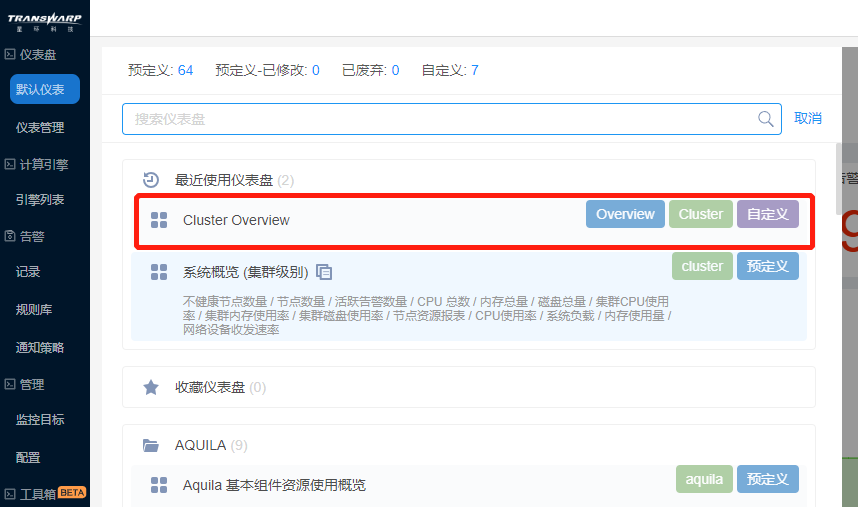
Bob在Manager上点击AquilaInsight的图标进入Aquila的仪表盘文件(仪表盘管理)页面。
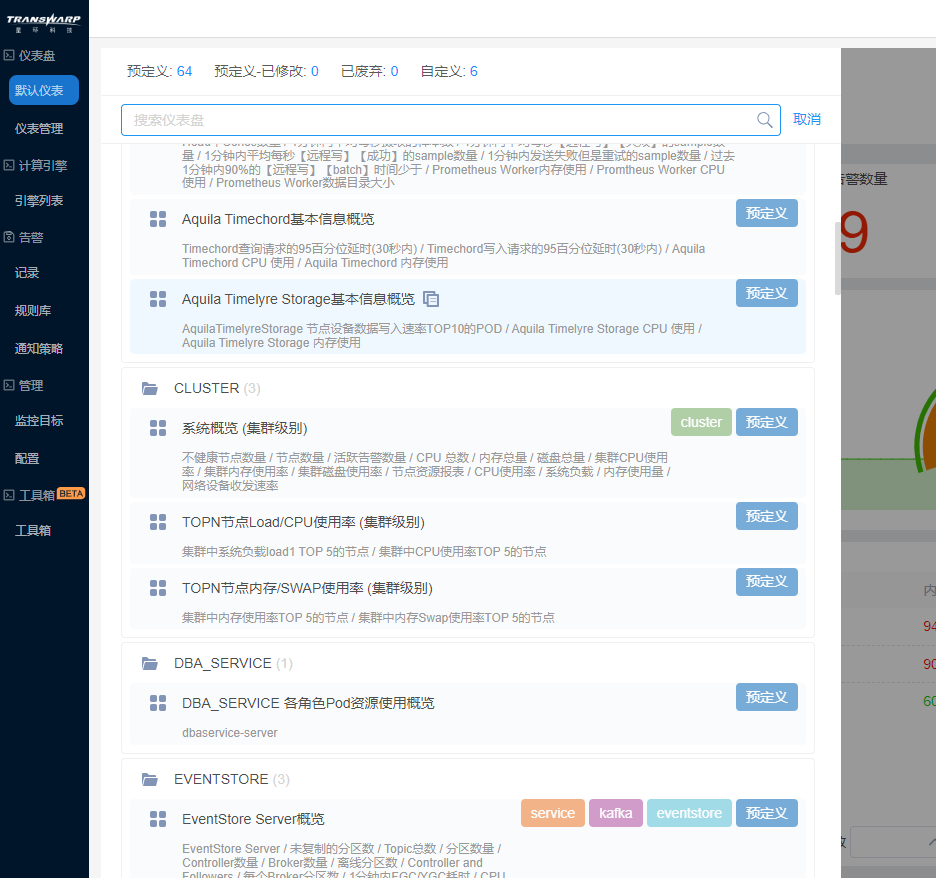
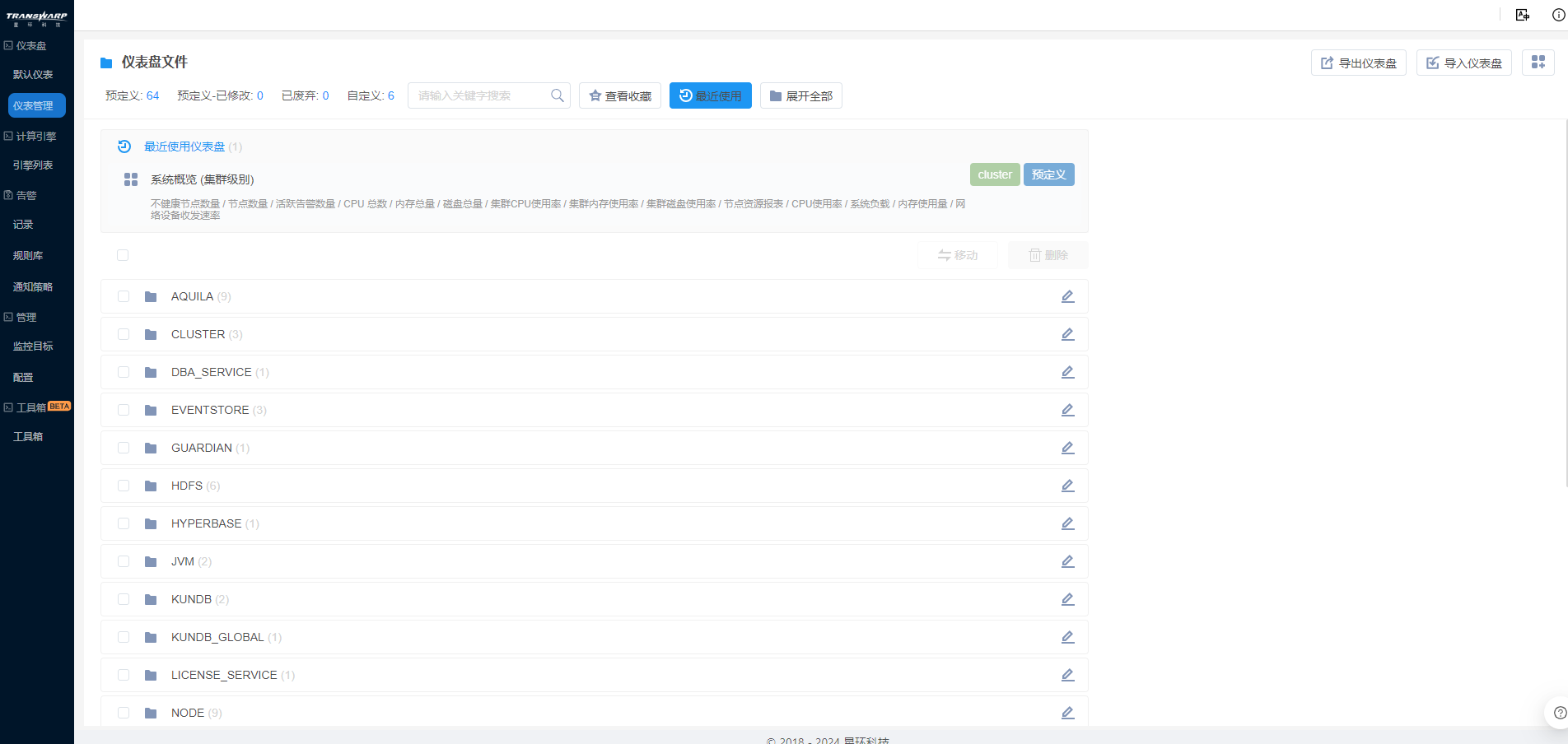
可以看见预设的Cluster文件夹(集群运维)、Kubernetes文件夹(容器运维)、Service文件夹(服务运维)。
查看预置仪表盘
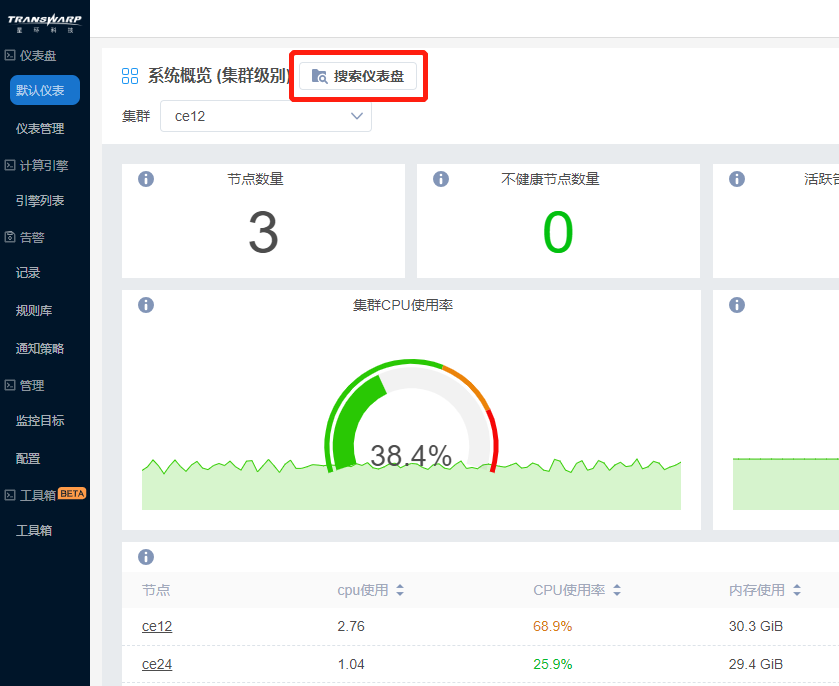
Bob先从概览查看集群、节点的大致情况。
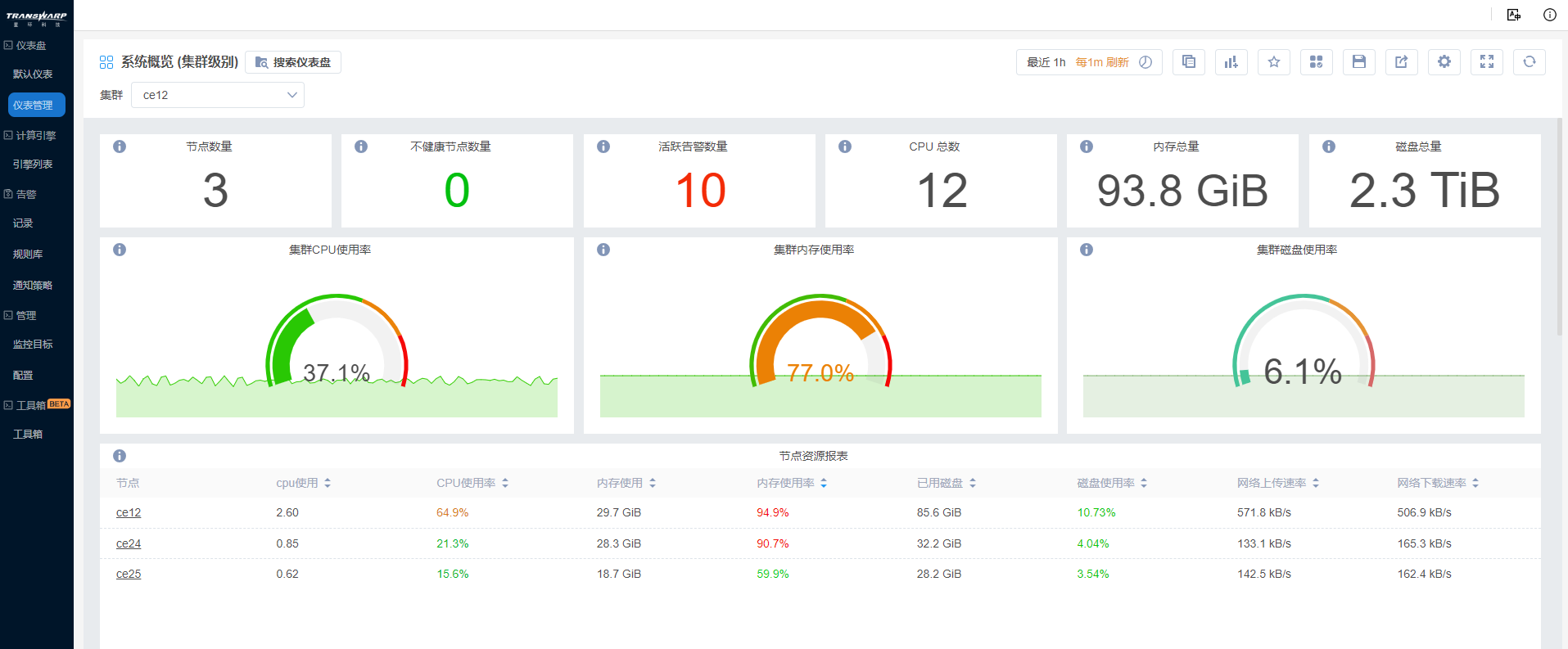
发现该集群已使用77%的内存,内存容量有点紧张健康;CPU、磁盘运转正常。
新建自定义仪表盘
Bob希望定制一款新的仪表盘,能够在一张仪表盘中,分节点展示CPU、网络、负载、存储和其他细节内容。
1. 在仪表盘文件页面点击 dashboard new icon 新建仪表盘,进入空白仪表盘页面:
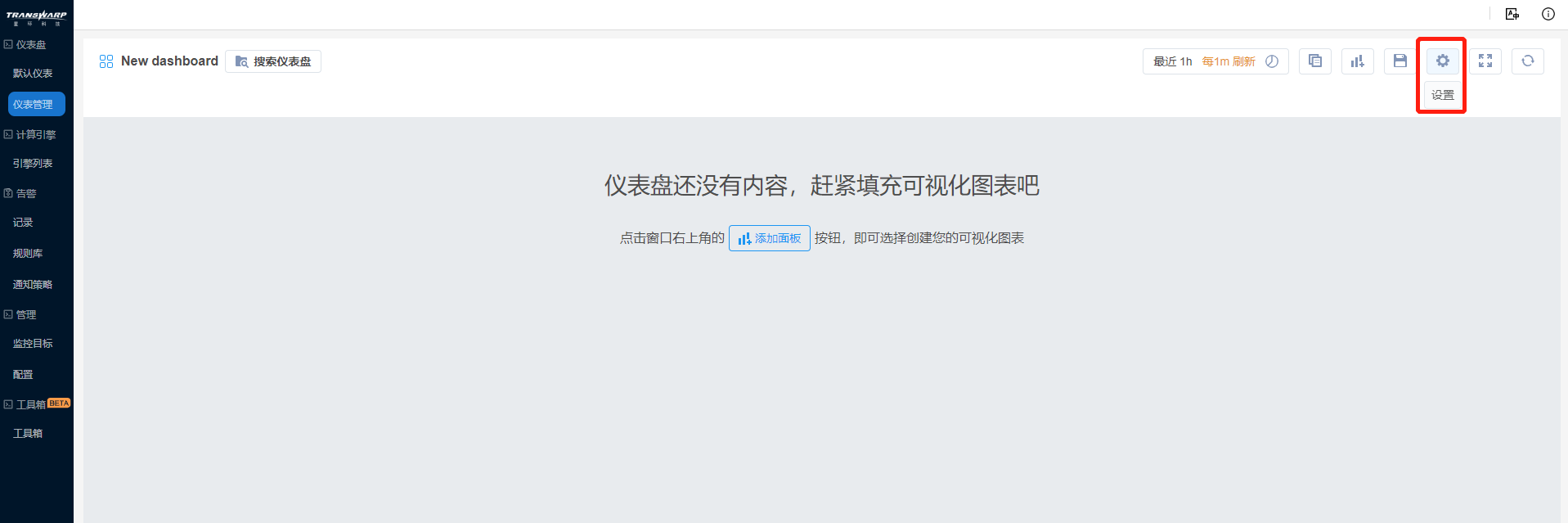
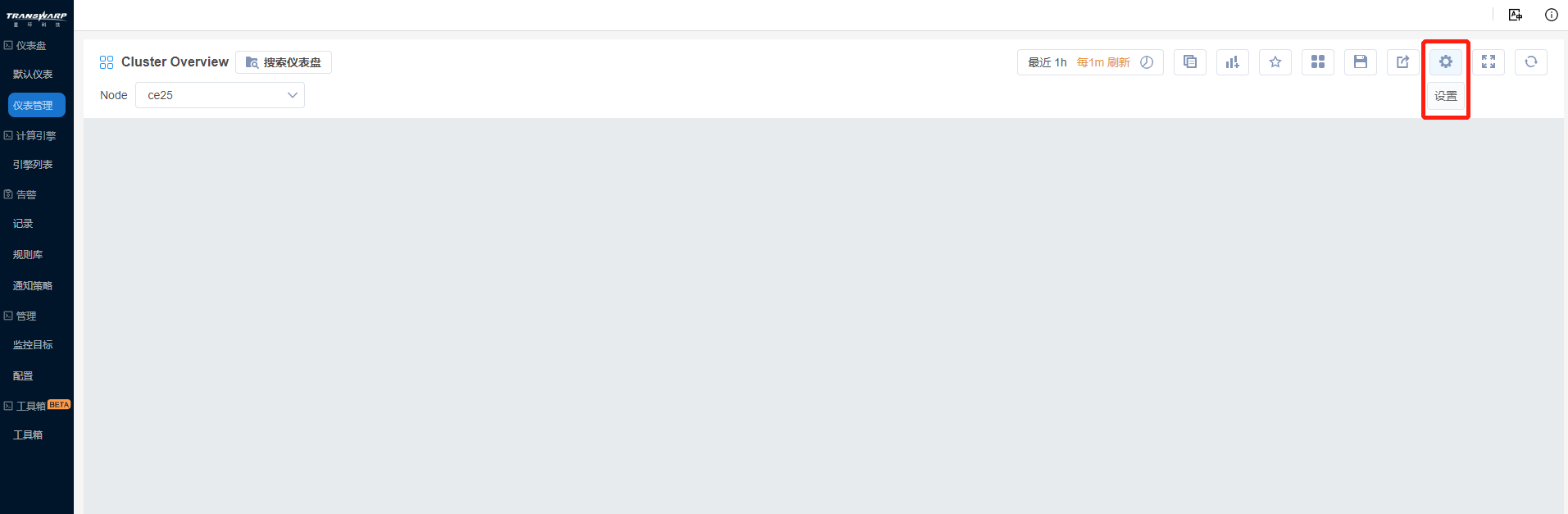
2. 在该页面点击设置按钮 dashboard set icon ,进入仪表盘设置页面,设置仪表盘的基本配置。
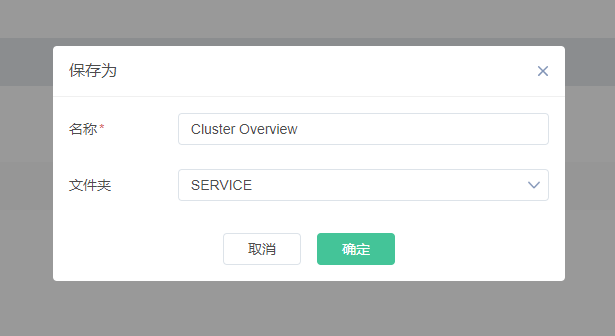
a) 常规设置中,命名为“Cluster Overview”,并添加“Overview”、“Cluster”两个标签,放在“Cluster”文件夹下。
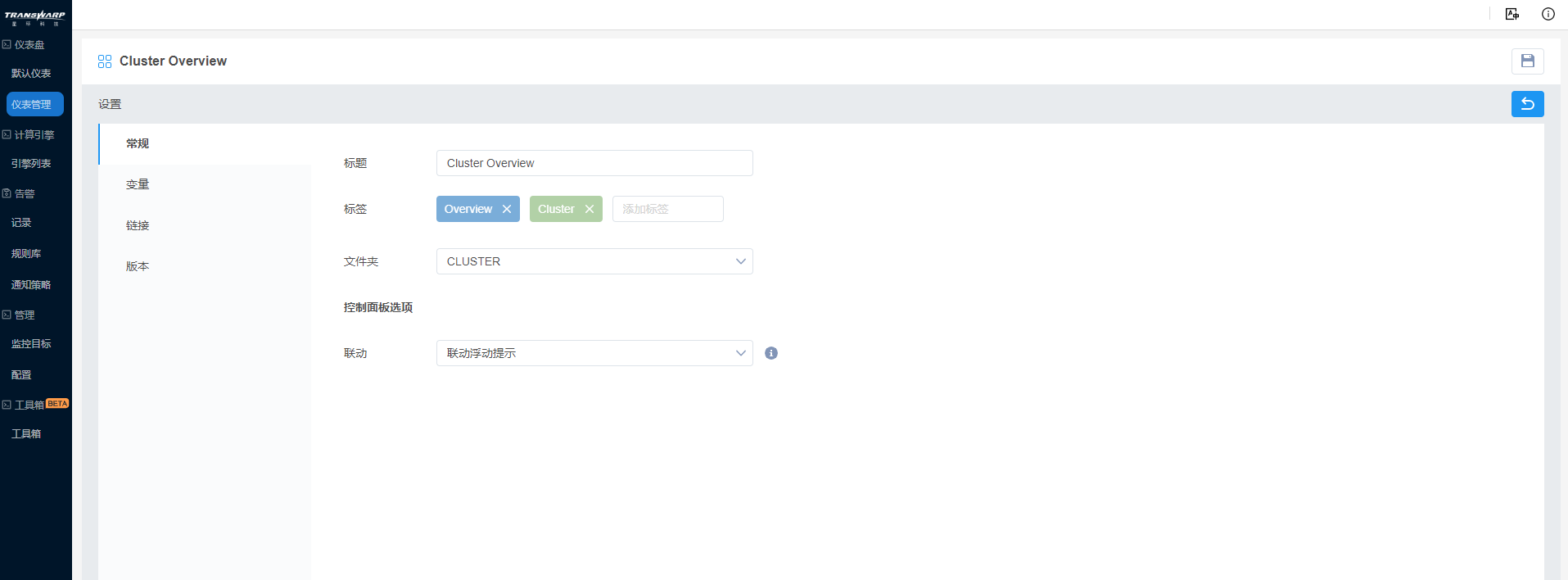
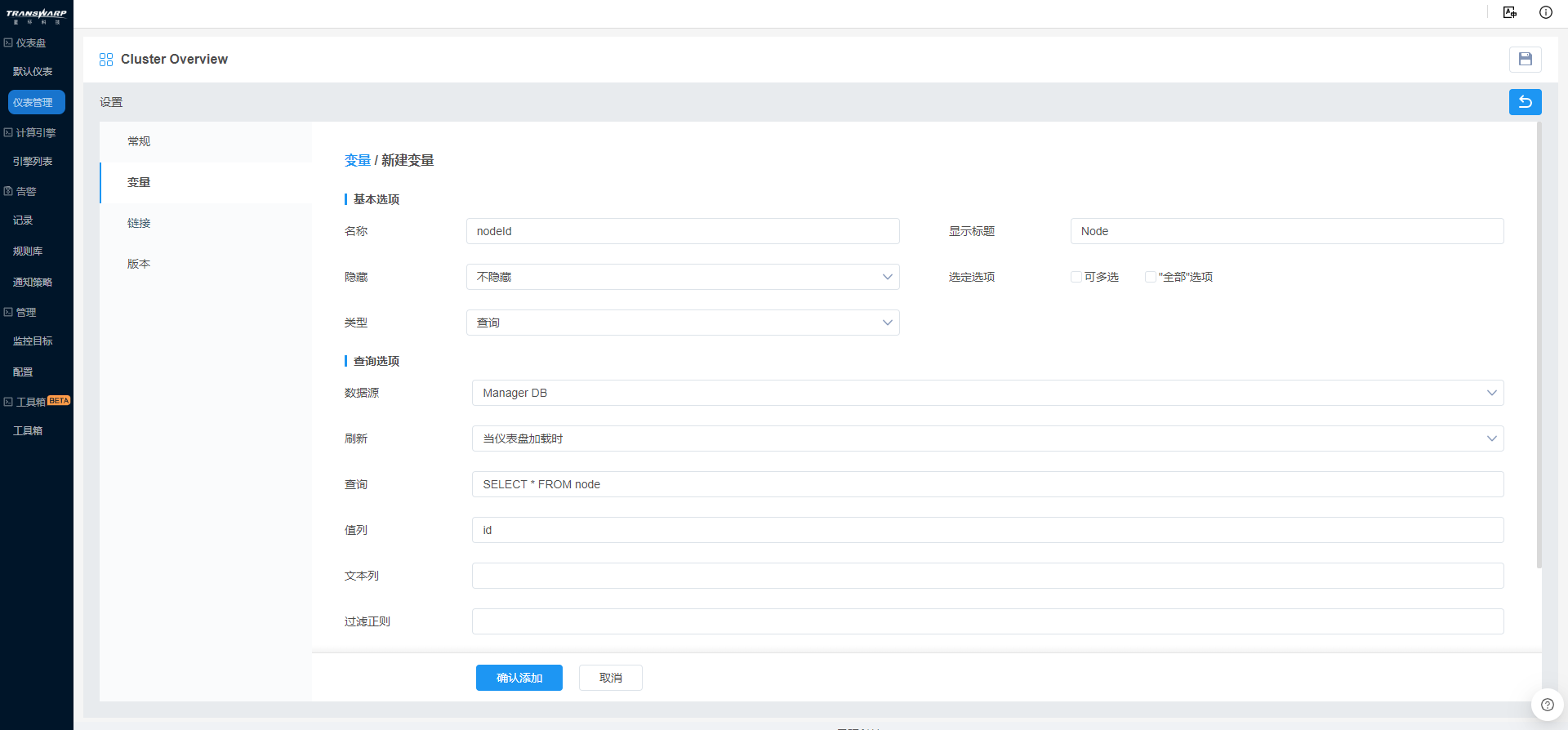
b) 变量设置中,点击 按钮 ,新建变量nodeId,显示标题为Node,不勾选“可多选”和“‘全部’选项”;数据源为Manger DB,从中以“SELECT * FROM node”选取该Manager上的所有节点,值列为id,以跟Prometheus中的变量值对应。
按钮 ,新建变量nodeId,显示标题为Node,不勾选“可多选”和“‘全部’选项”;数据源为Manger DB,从中以“SELECT * FROM node”选取该Manager上的所有节点,值列为id,以跟Prometheus中的变量值对应。
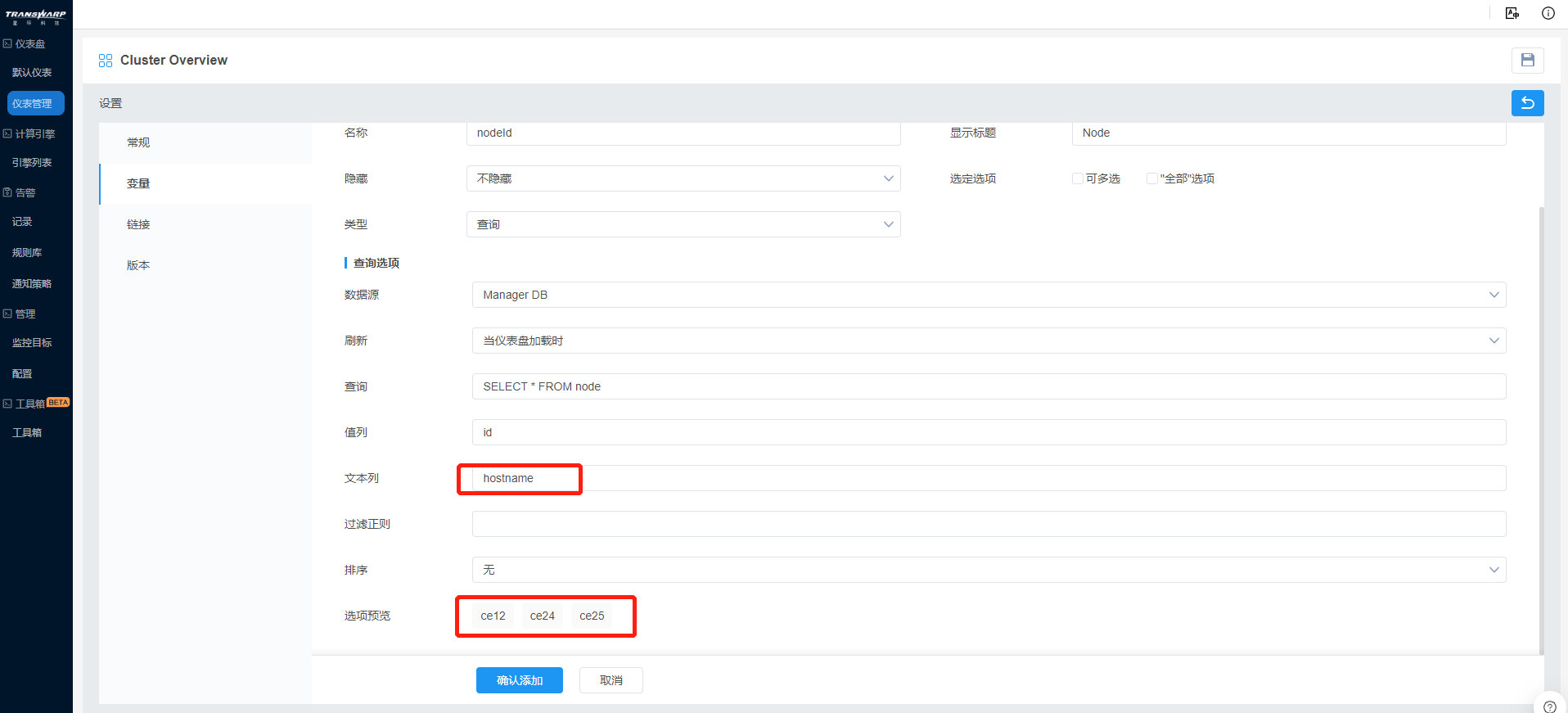
Bob更改文本列的属性名,在此查询模块中使用“hostname”作为文本列,随之选项预览也发生了变化,对比如图:
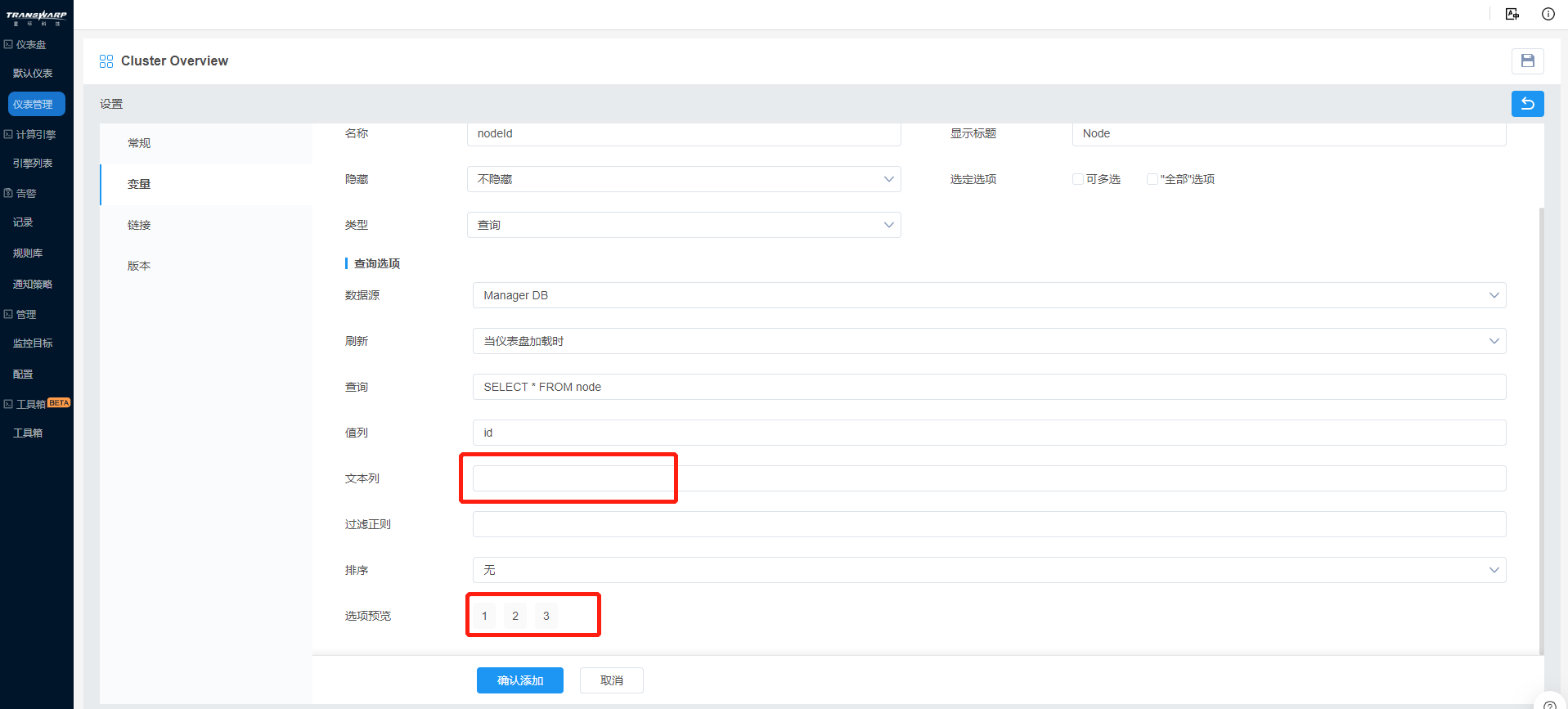
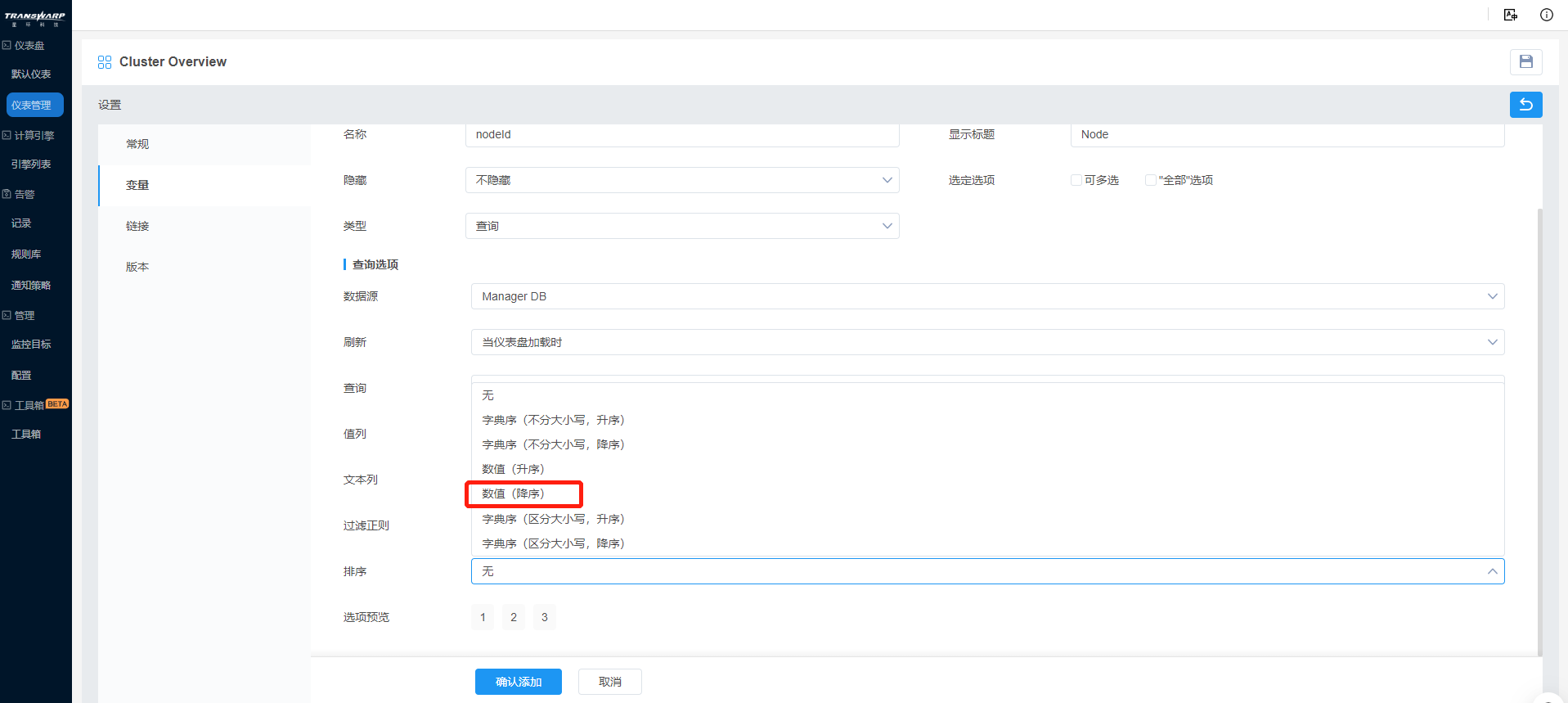
Bob希望默认设置主节点node089为第一个展示的节点,因此在排序中选择了数值(降序)
点击确认添加,回到了变量设置页面,设置完成。
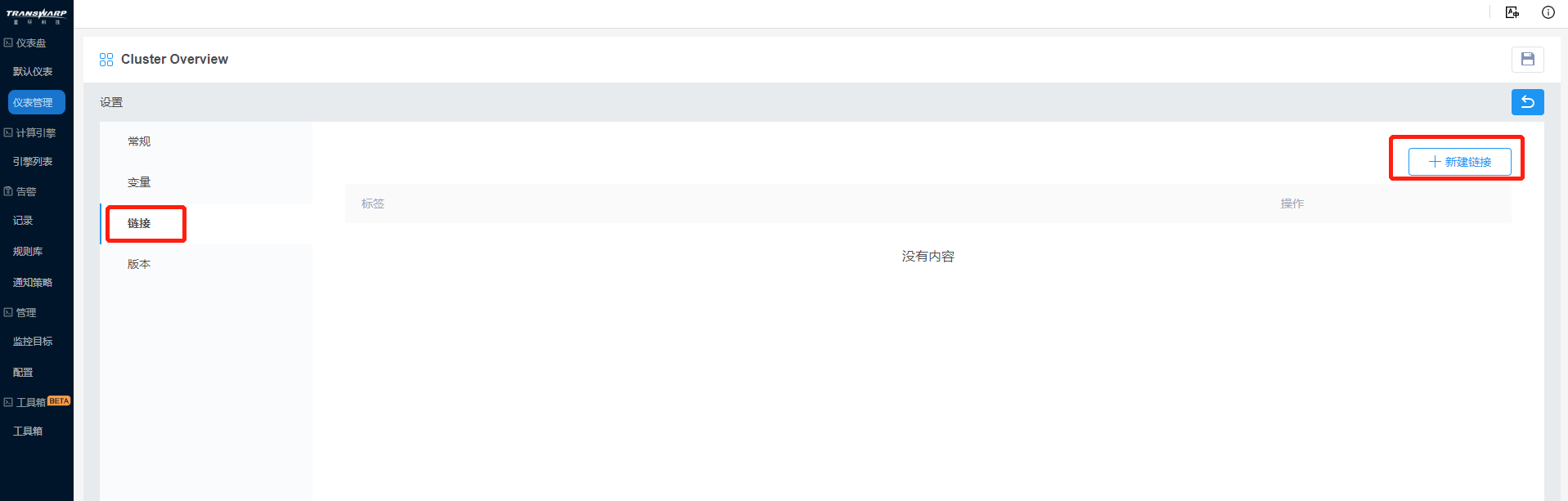
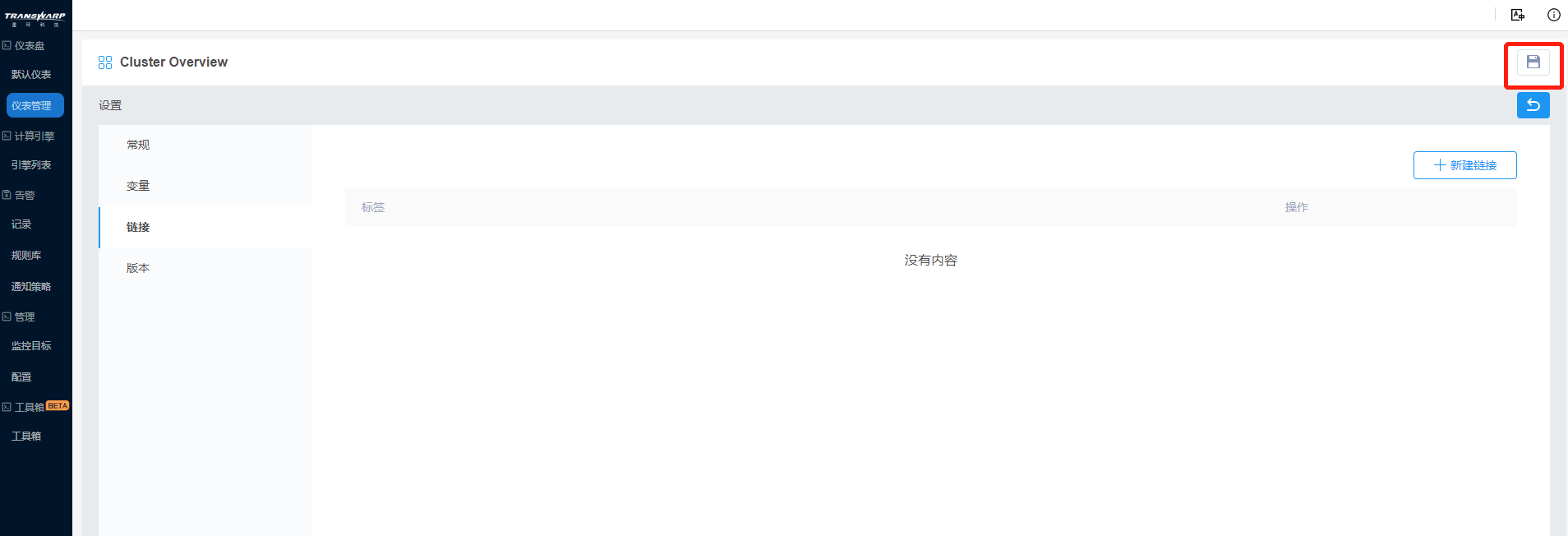
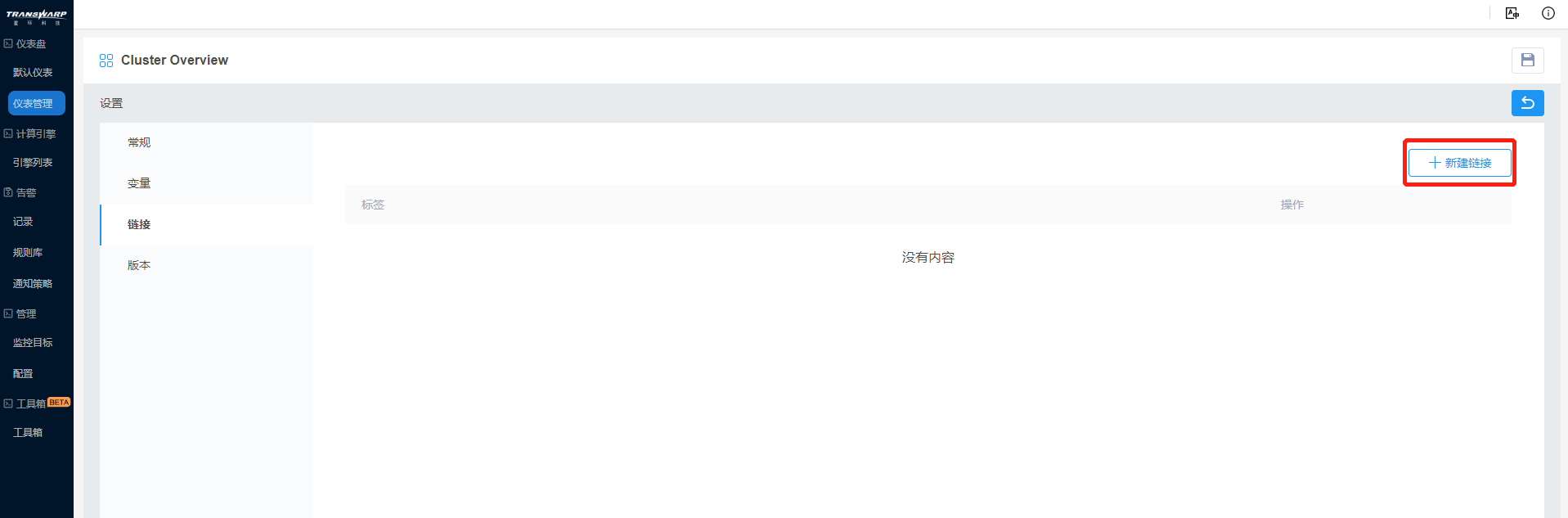
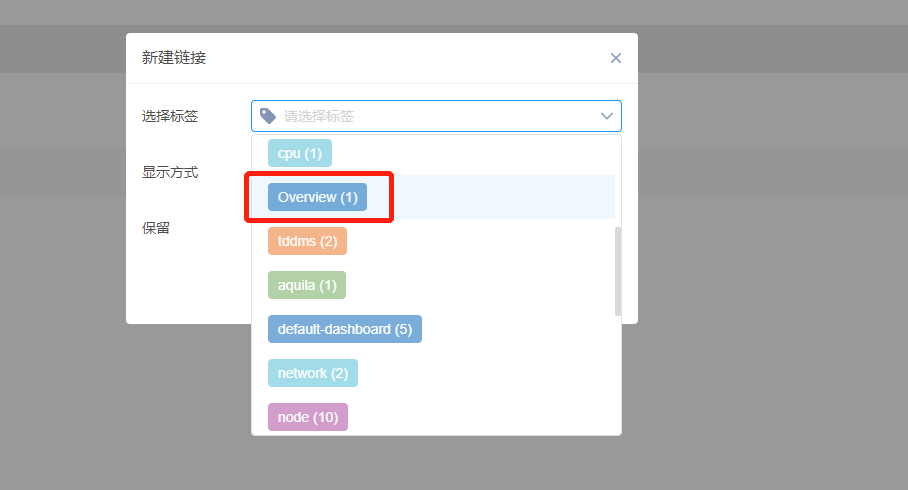
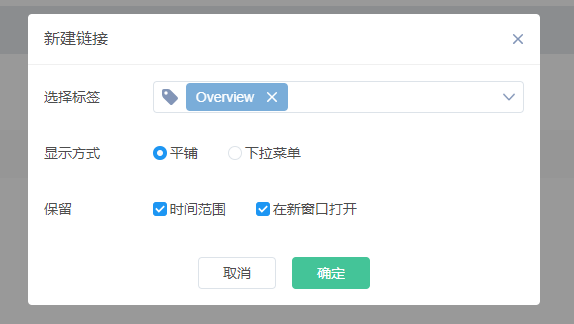
c) 链接设置中,Bob希望能从该仪表盘跳转其他的Overview标签仪表盘,点击新建链接按钮,选择标签为Overview,下拉菜单,保留时间范围,并在新窗口打开。
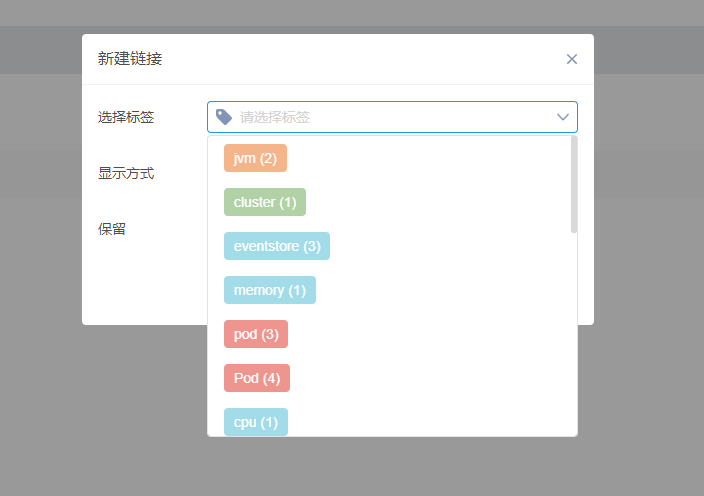
但是点击标签下拉菜单,发现并没有Overview标签选项
这是因为Overview标签是当前仪表盘新建的,还未保存,于是Bob退出这个窗口后点击右上方保存按钮,再重新点击设置按钮,新建链接,配置标签,成功。
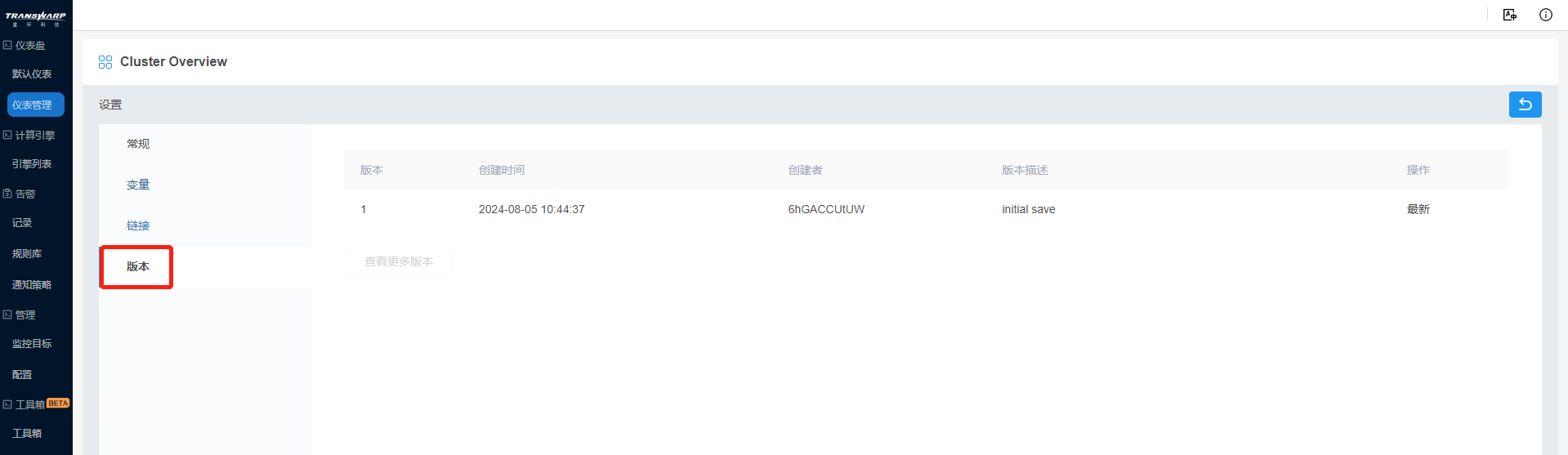
d) 可以在版本设置中,按照个人需求进行回退,目前的最新版是Bob想要的结果,所以暂时不回退,仪表盘设置完成。
3. 回到仪表盘页面,此时仪表盘顶部已经有了左上角的Node菜单和右上角的链接菜单。点击添加面板,选取曲线图,新建第一个新面板。
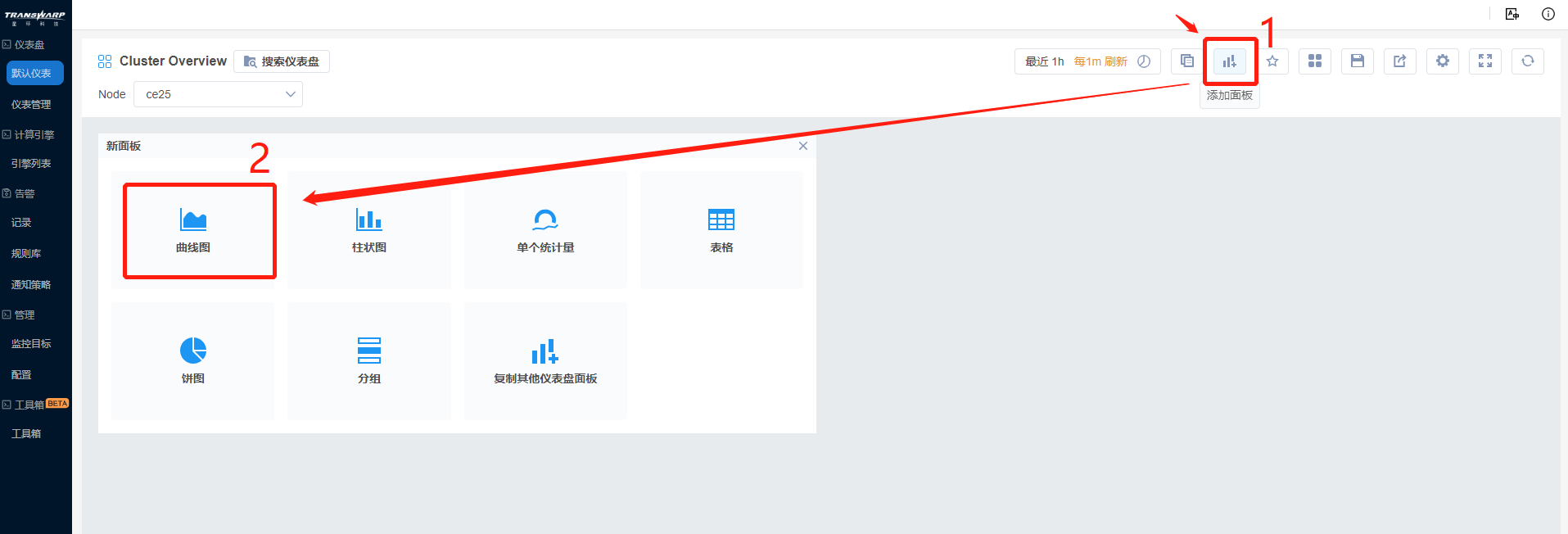
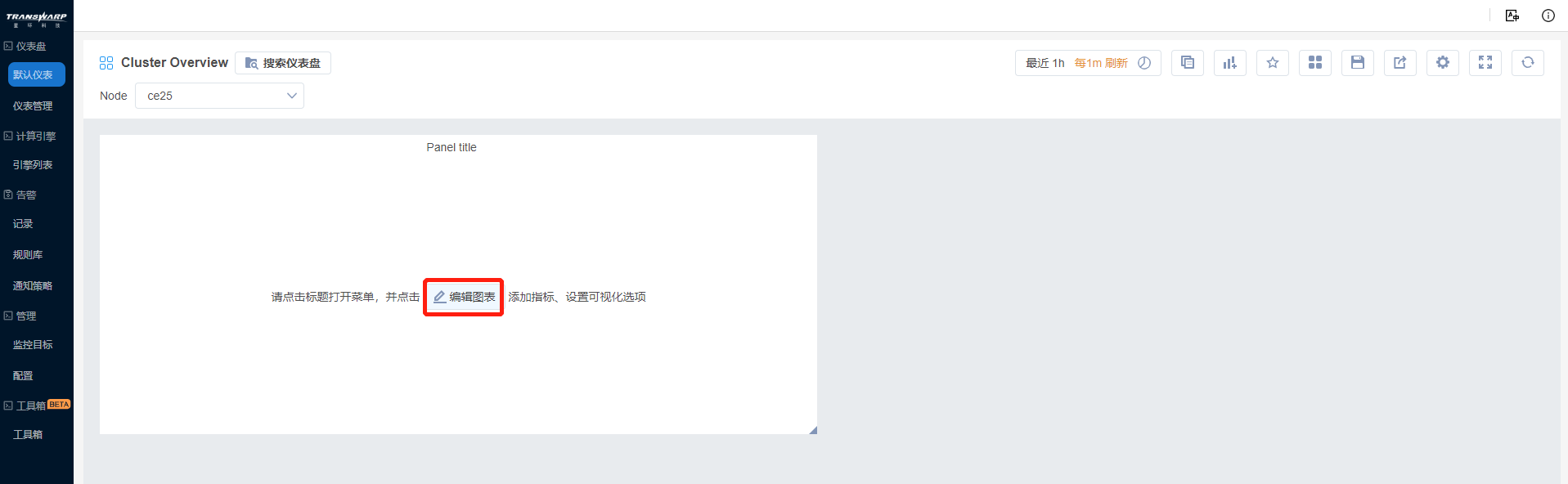
a) 新建后该面板无任何数据内容,点击编辑图表进入编辑页面。
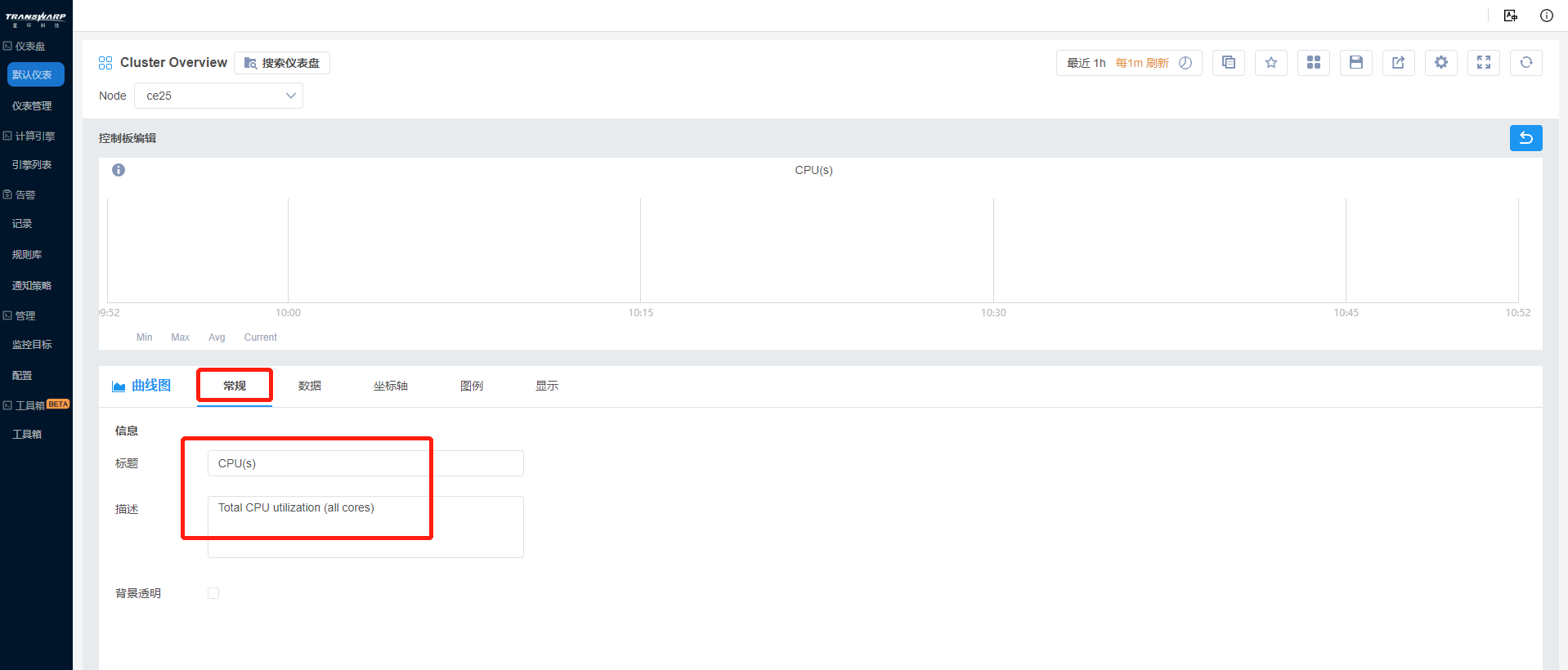
b) 设置面板标题为CPUs,并加以描述,便于他人查看
c) 设置第一个Prometheus指标内容为sum(irate(node_cpu_seconds_total{nodeId="${nodeId}", mode="user"}[1m])) / sum(irate(node_cpu_seconds_total{nodeId="${nodeId}"}[1m])),图例格式为“user”,每序列点数为100。
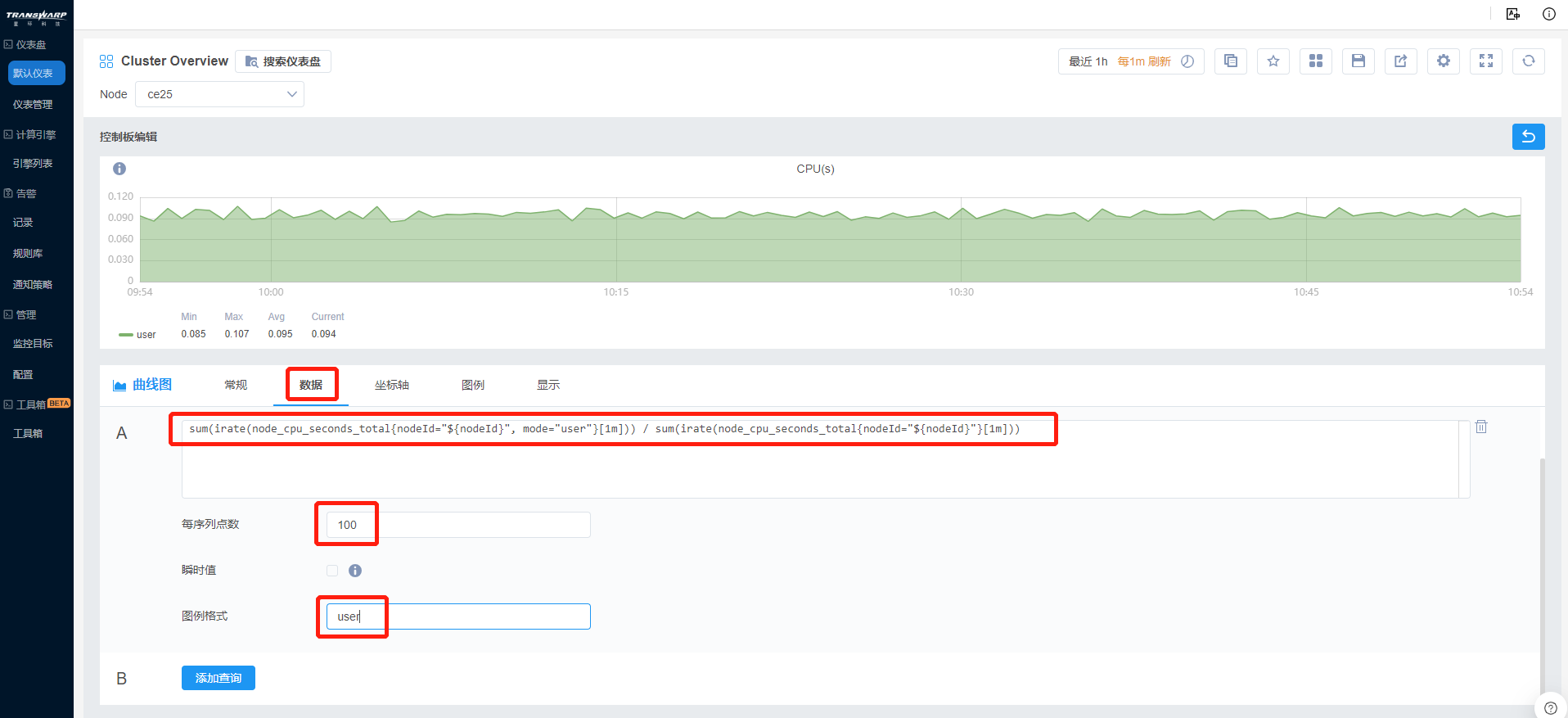
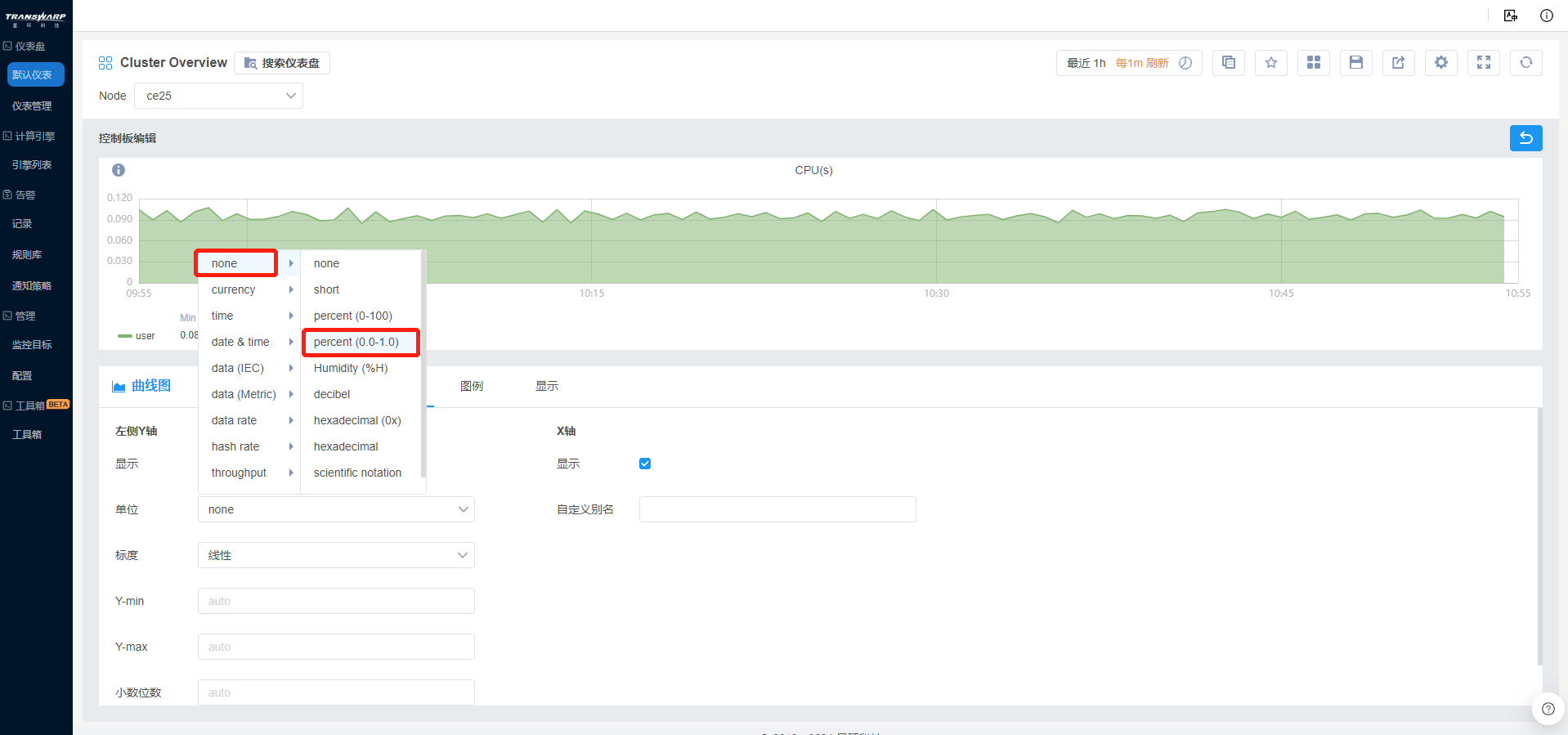
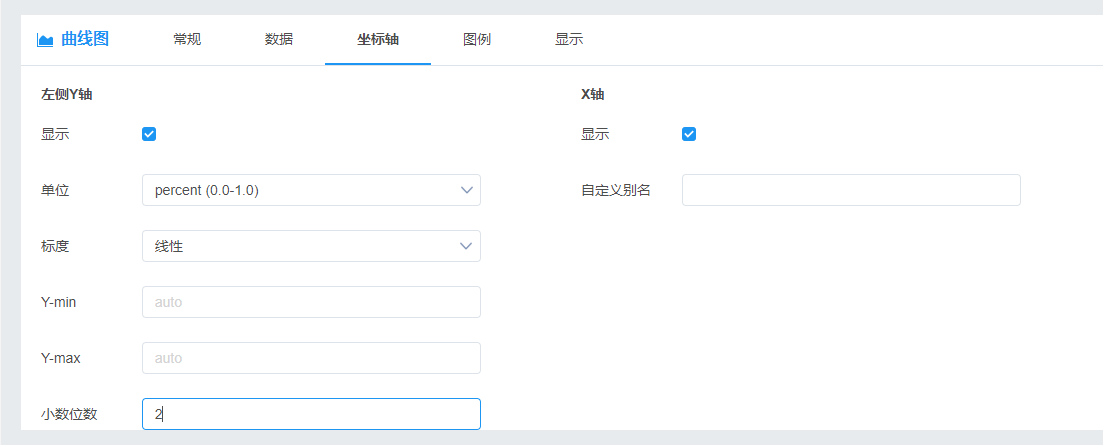
d) 设置坐标轴单位为none(无单位)-percent(0.0-1.0)(百分比形式),小数位数为2位
e) 由于有多条观测值,Bob决定加入图例,并展示多个观测指标的统计值,小数位数为2,将全为0值的数据隐去以更清晰地对比。
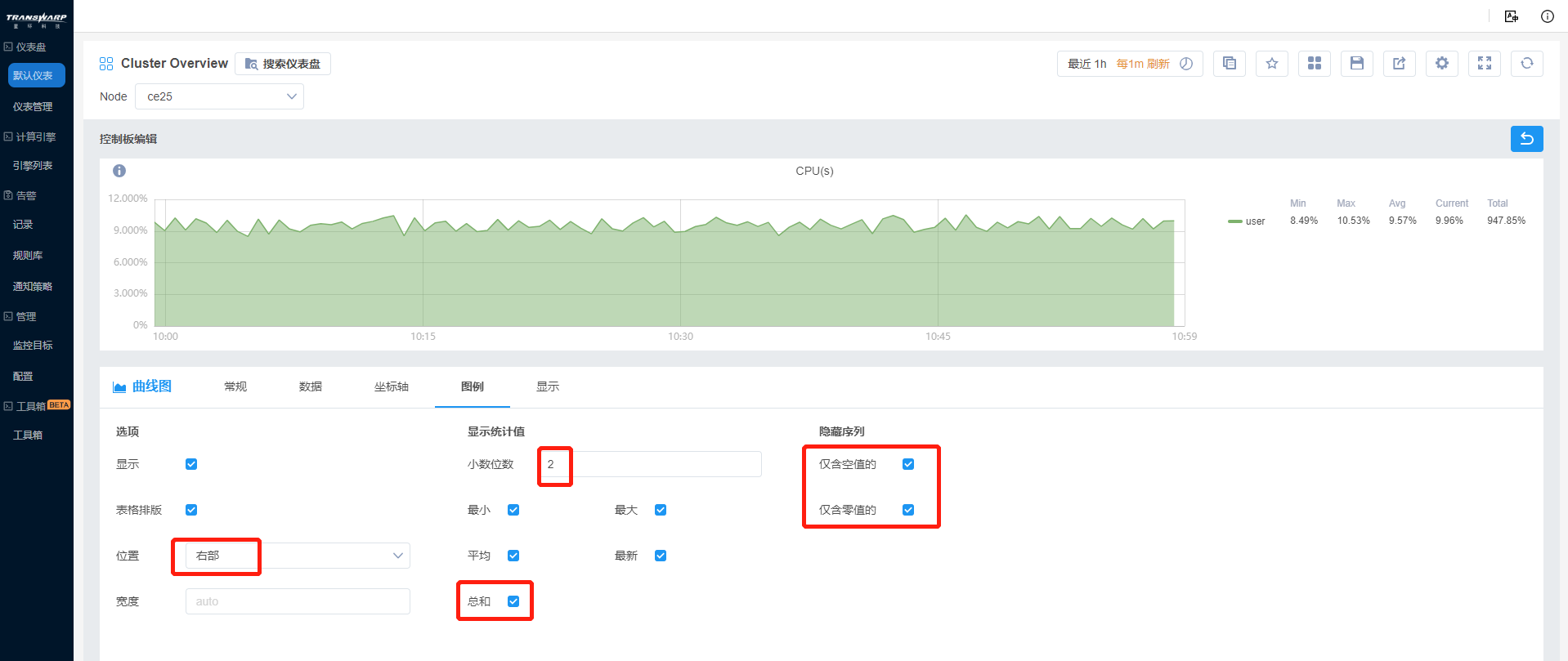
f) 在显示部分,Bob设置线的填充度为0.3,以区分明显地显示各个指标的情况,其余均为默认设置。
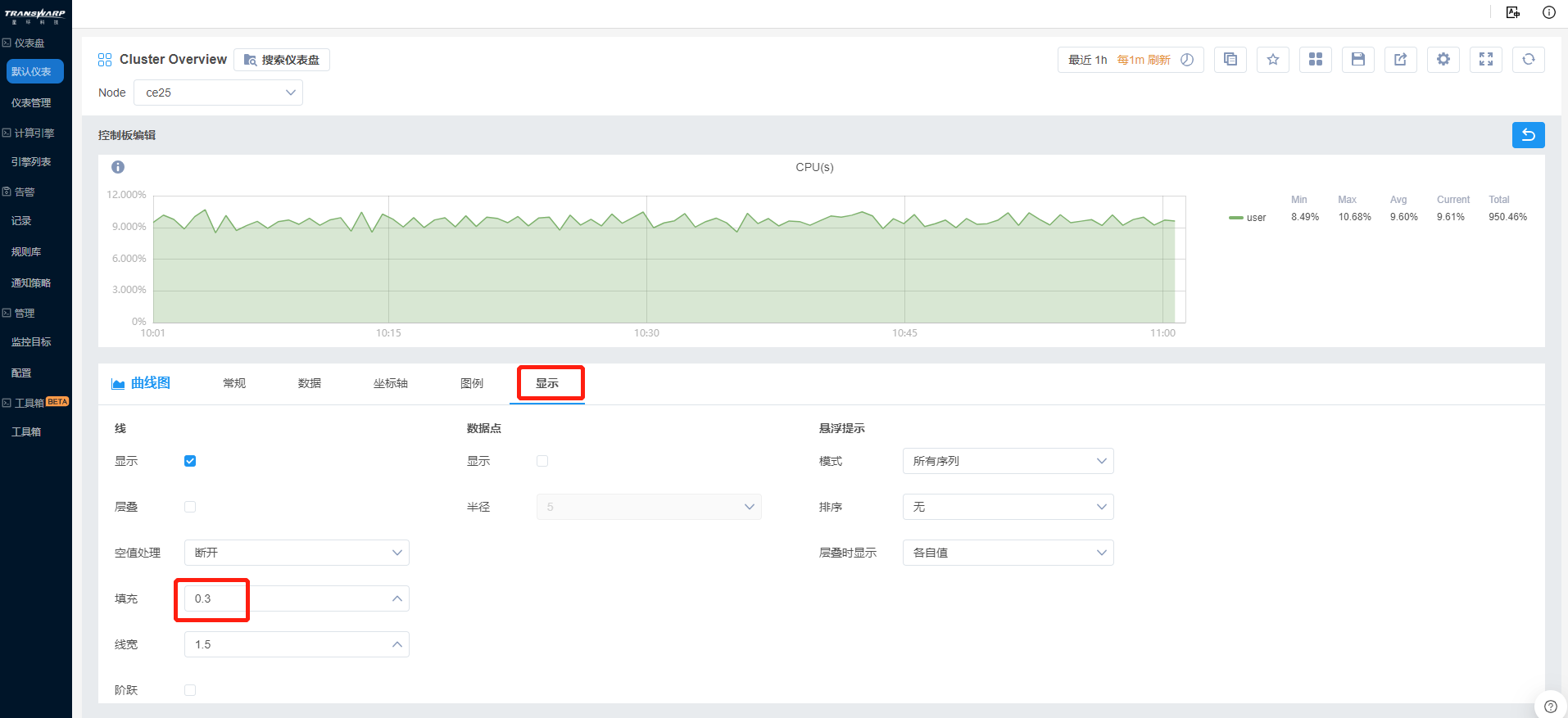
面板设置完成,点击返回,面板设置内容便自动保存,返回到仪表盘页面。
g) Bob发现该面板被图例占了很大篇幅,于是将鼠标置于面板右下角,拖拽面板横向拉伸,使得面板看上去更舒服。
点击保存完成第一个面板的定制。
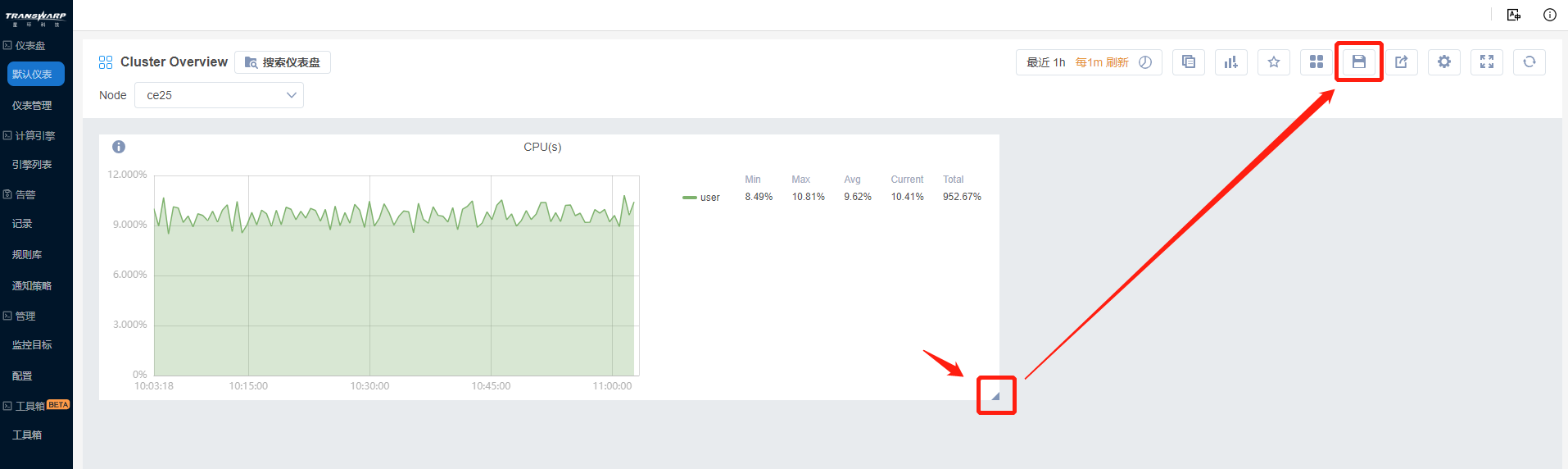
注意:点击标题右侧,可以进行编辑面板等操作
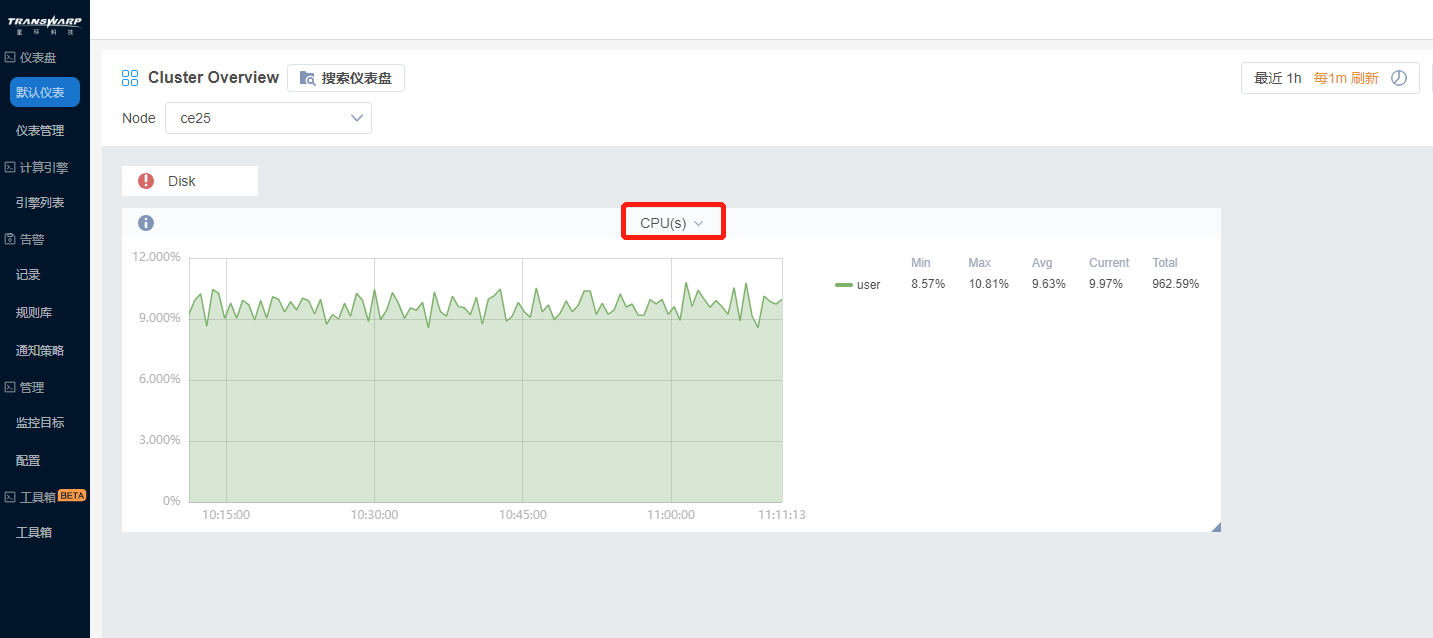
4. 随后,Bob制作了Disk、Memory、Network下多个面板,使用分组管理起来。为了让CPU分组呈现在最上方,Bob将其他分组收至最小,长按分组进行移动。
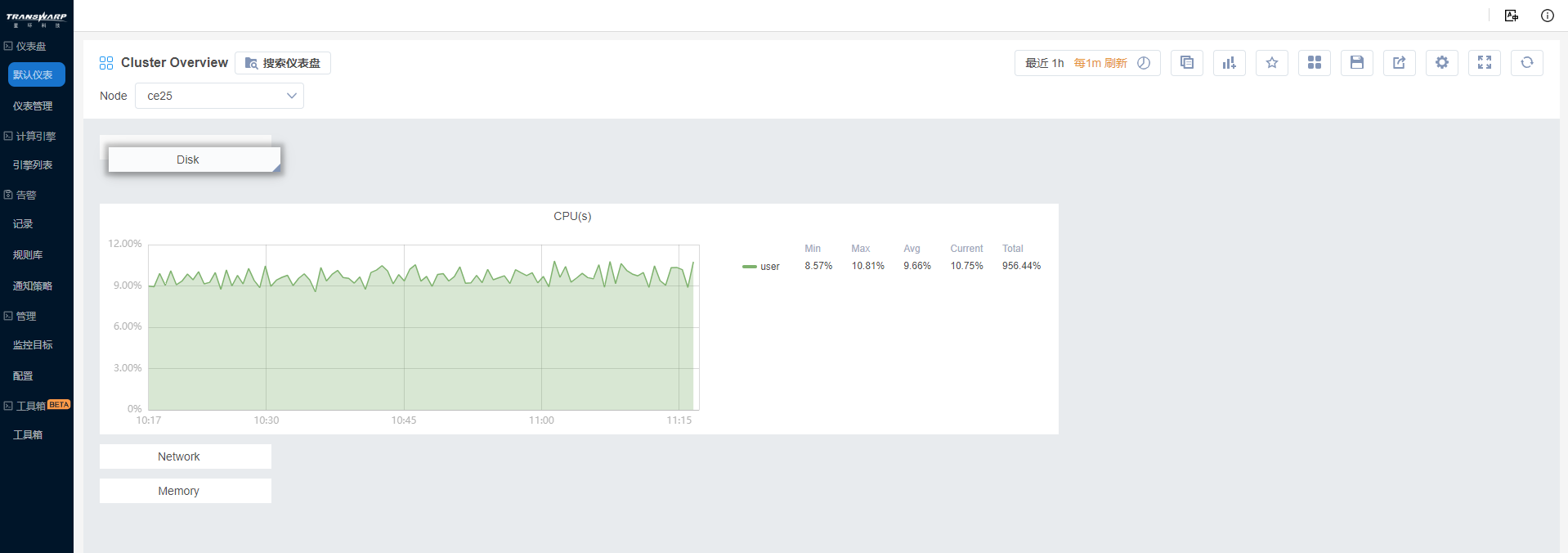
5. Bob最终完成了Cluster Overview仪表盘,以后就可以通过该仪表盘观测所有节点的概况了。
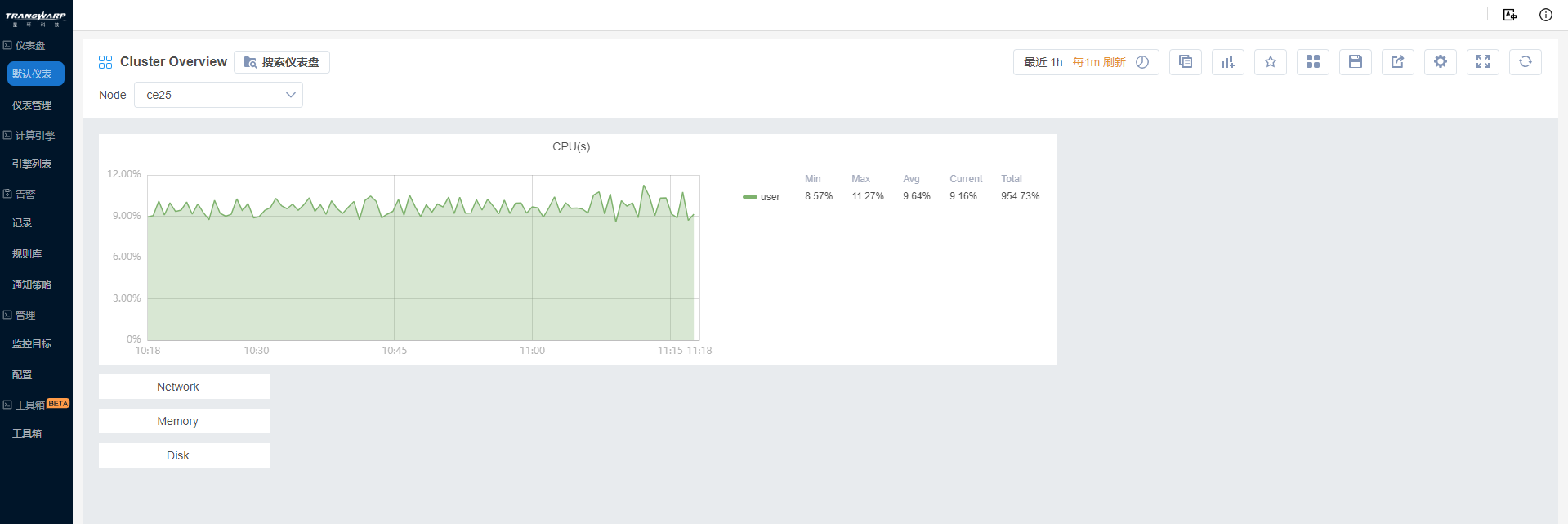
告警预警
有些指标不便于可视化监控,需要精确知道这些指标是否高出或低于某个阈值。因此,Bob还需要使用告警来辅助运维。通过导航栏-告警-规则设置,进入规则管理页面。
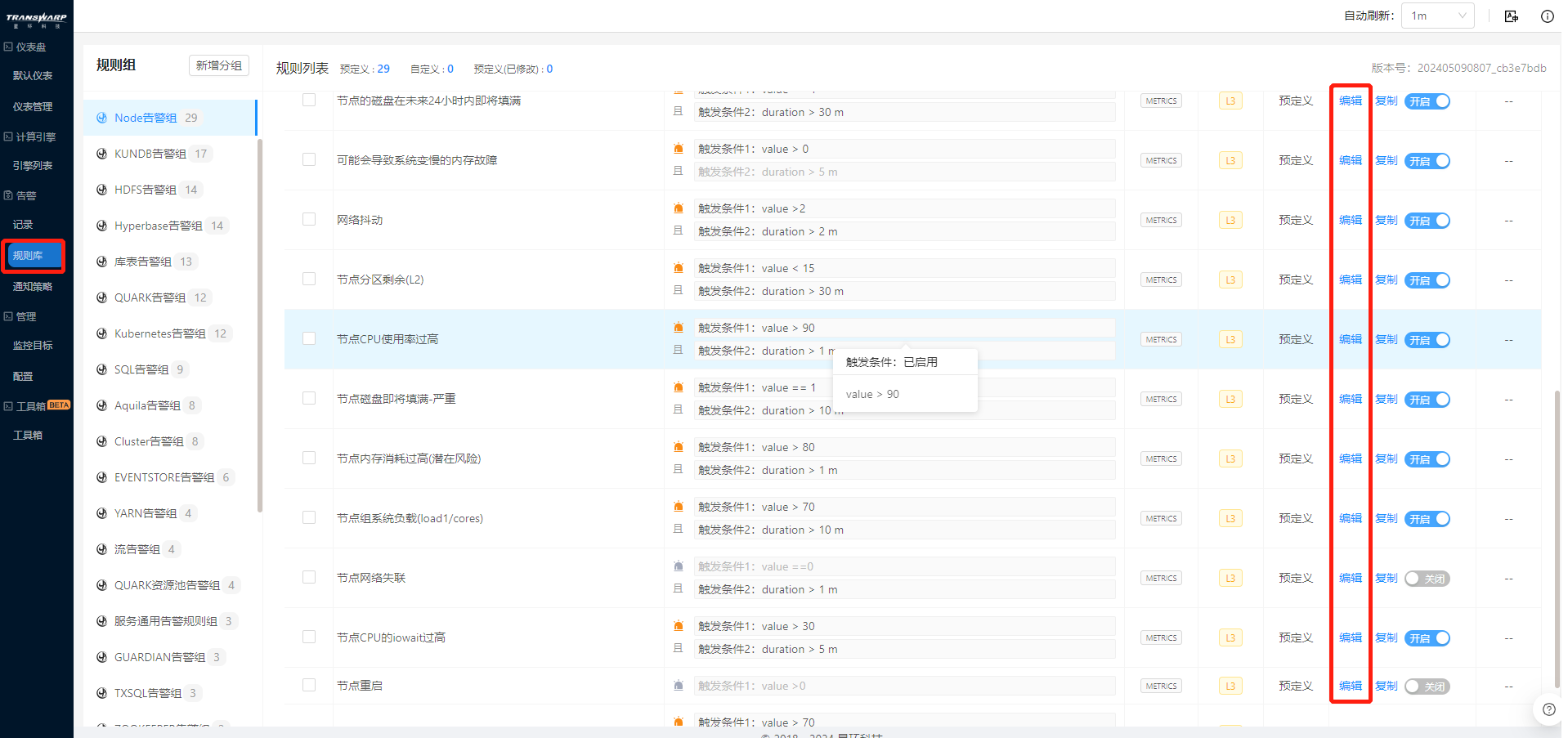
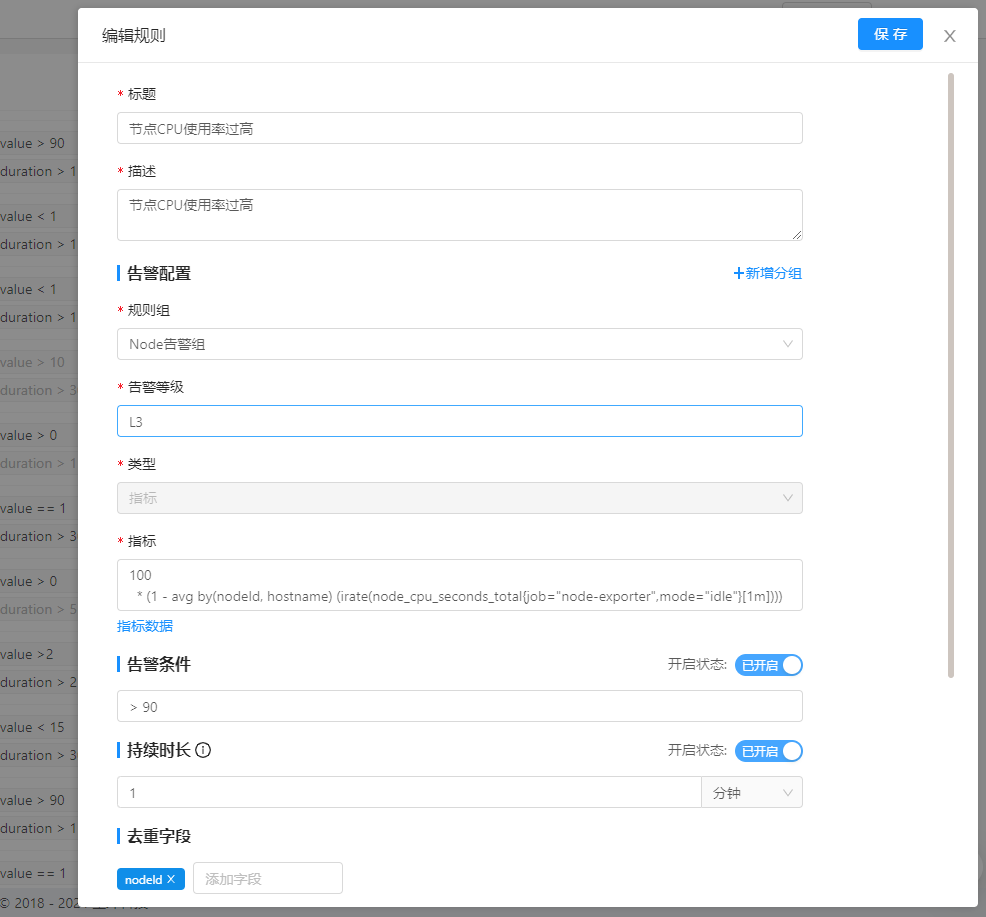
在该页面,Bob看到了预定义的基本告警规则。这里的意思是,通过指标阈值,查询Node节点的CPU使用率,当比例超过90%时开始告警,警告持续1分钟。Bob可以自行根据自身需求设置需要的告警内容。
告警通知
Bob为了能够及时收到告警信息,确保不犯工作上的疏忽,将自己加入通知目标,使用分派策略给自己通知某些指标的告警情况。
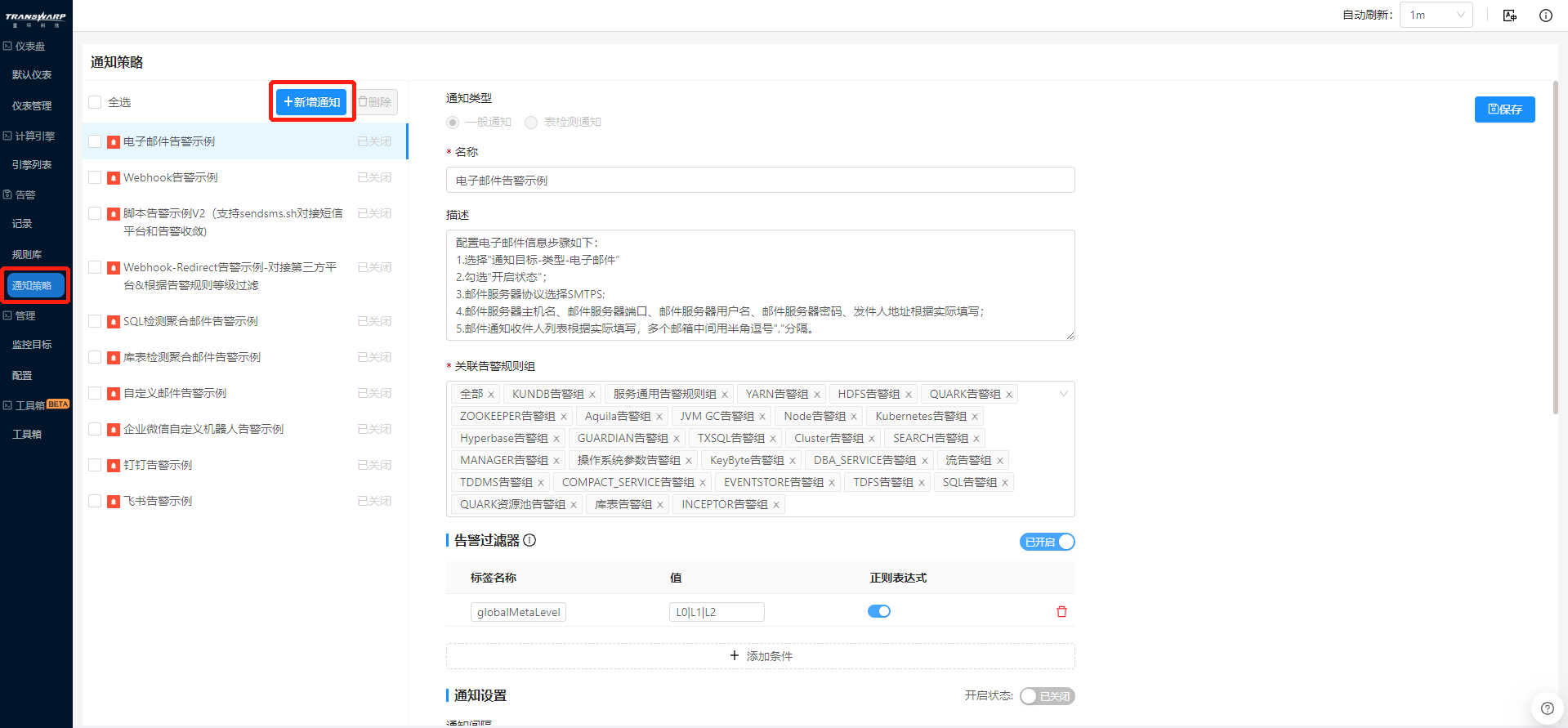
告警的标签名称目前仅支持从Manager页面进行管理和查看,步骤如下:
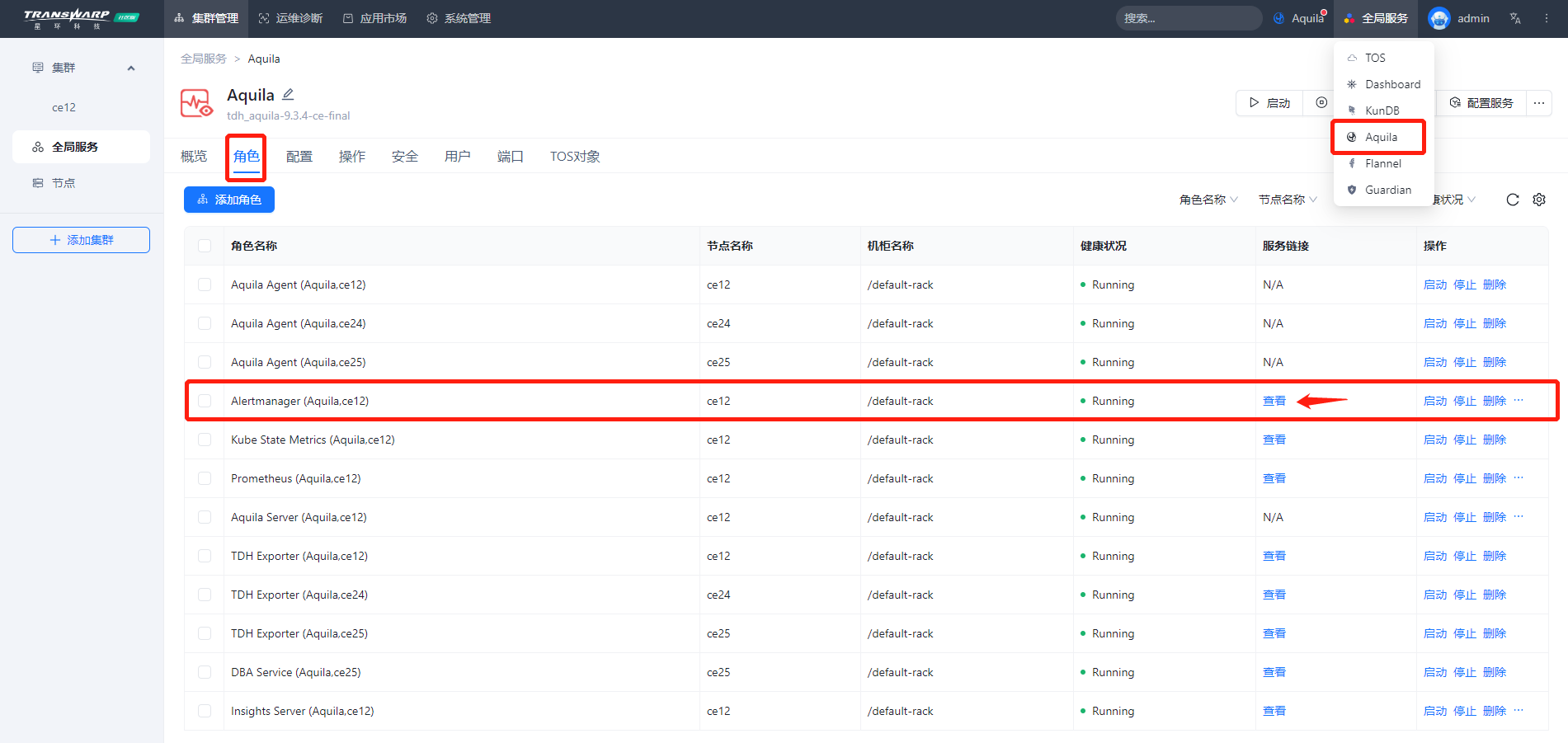
- 进入Manager页面中的Aquila服务详情页,找到Alertmanager服务角色,点击查看,进入对应的link标签页
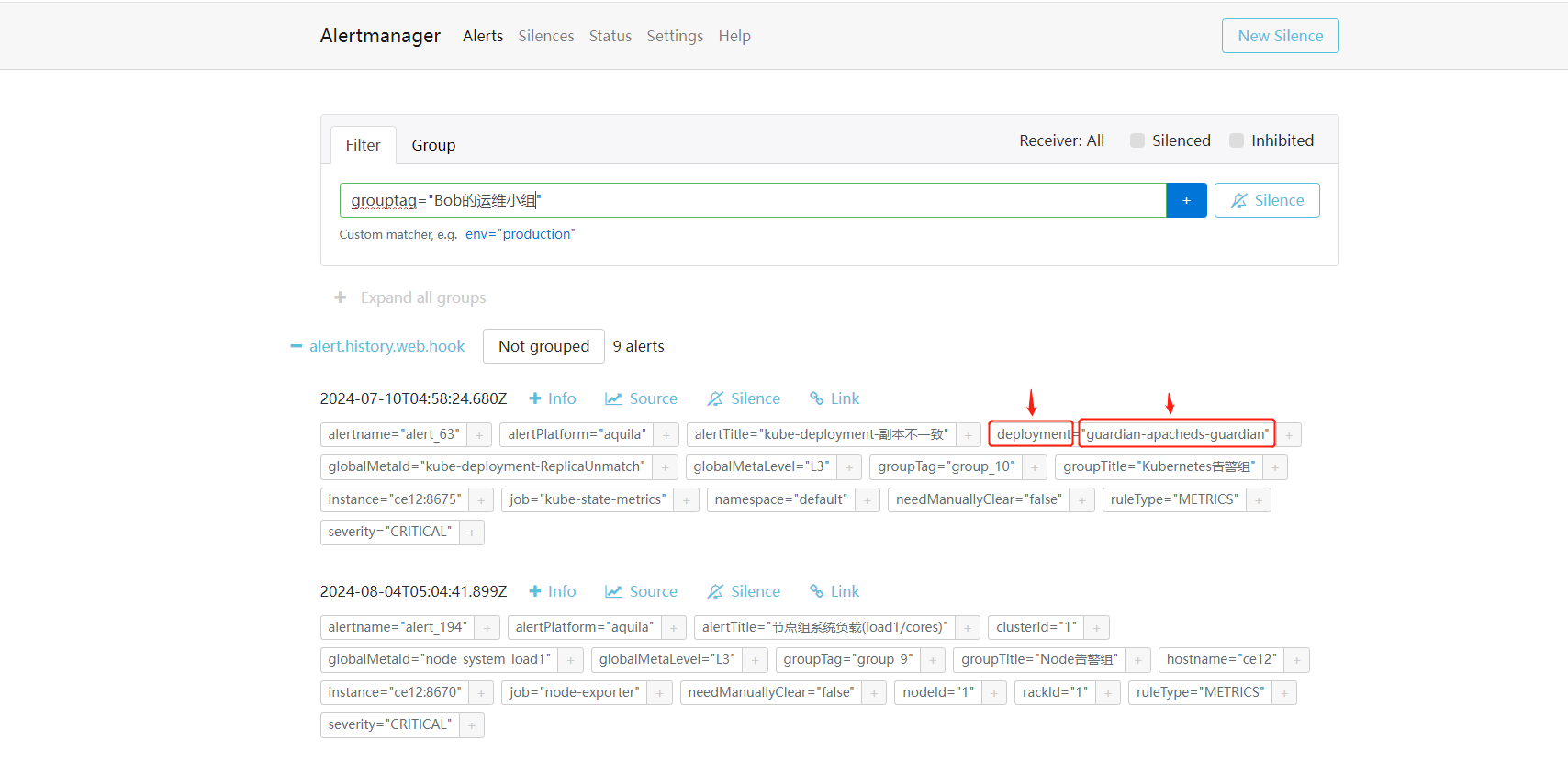
2. 进入Alertmanager管理页面,可以看到设定好的标签和值
更多产品使用内容请参考下方手册
友情链接:
- AquilaInsight核心功能及角色概览
- Aquila的核心功能介绍
- DBA Service的核心功能介绍
- 刚部署好Aquila Insight,第一次如何使用
- 如何通过AquilaInsight快速查看每天有哪些异常/慢查询?
- 如何通过Aquila Insight快速定位一个查询为什么慢?
- Aquila 添加自定义监控信息和告警的示例
- 当Quark/Inceptor上跑批变慢、不健康,如何借助星环运维工具AquilaInsight进行排查?
场景示例
背景
作为运维人员,Bob每天的工作是确保运行在TDH上的各个组件正常运转。今天是Bob第一天使用Aquila监控应用,他还设定了一系列自动化的规则辅助自己完成未来的运营。
Bob需要对部署了下图中众多应用的集群系统进行运维。
性能监控
Bob在Manager上点击AquilaInsight的图标进入Aquila的仪表盘文件(仪表盘管理)页面。
可以看见预设的Cluster文件夹(集群运维)、Kubernetes文件夹(容器运维)、Service文件夹(服务运维)。
查看预置仪表盘
Bob先从概览查看集群、节点的大致情况。
发现该集群已使用77%的内存,内存容量有点紧张健康;CPU、磁盘运转正常。
新建自定义仪表盘
Bob希望定制一款新的仪表盘,能够在一张仪表盘中,分节点展示CPU、网络、负载、存储和其他细节内容。
1. 在仪表盘文件页面点击 dashboard new icon 新建仪表盘,进入空白仪表盘页面:
2. 在该页面点击设置按钮 dashboard set icon ,进入仪表盘设置页面,设置仪表盘的基本配置。
a) 常规设置中,命名为“Cluster Overview”,并添加“Overview”、“Cluster”两个标签,放在“Cluster”文件夹下。
b) 变量设置中,点击按钮 ,新建变量nodeId,显示标题为Node,不勾选“可多选”和“‘全部’选项”;数据源为Manger DB,从中以“SELECT * FROM node”选取该Manager上的所有节点,值列为id,以跟Prometheus中的变量值对应。
Bob更改文本列的属性名,在此查询模块中使用“hostname”作为文本列,随之选项预览也发生了变化,对比如图:
Bob希望默认设置主节点node089为第一个展示的节点,因此在排序中选择了数值(降序)
点击确认添加,回到了变量设置页面,设置完成。
c) 链接设置中,Bob希望能从该仪表盘跳转其他的Overview标签仪表盘,点击新建链接按钮,选择标签为Overview,下拉菜单,保留时间范围,并在新窗口打开。
但是点击标签下拉菜单,发现并没有Overview标签选项
这是因为Overview标签是当前仪表盘新建的,还未保存,于是Bob退出这个窗口后点击右上方保存按钮,再重新点击设置按钮,新建链接,配置标签,成功。
d) 可以在版本设置中,按照个人需求进行回退,目前的最新版是Bob想要的结果,所以暂时不回退,仪表盘设置完成。
3. 回到仪表盘页面,此时仪表盘顶部已经有了左上角的Node菜单和右上角的链接菜单。点击添加面板,选取曲线图,新建第一个新面板。
a) 新建后该面板无任何数据内容,点击编辑图表进入编辑页面。
b) 设置面板标题为CPUs,并加以描述,便于他人查看
c) 设置第一个Prometheus指标内容为sum(irate(node_cpu_seconds_total{nodeId="${nodeId}", mode="user"}[1m])) / sum(irate(node_cpu_seconds_total{nodeId="${nodeId}"}[1m])),图例格式为“user”,每序列点数为100。
d) 设置坐标轴单位为none(无单位)-percent(0.0-1.0)(百分比形式),小数位数为2位
e) 由于有多条观测值,Bob决定加入图例,并展示多个观测指标的统计值,小数位数为2,将全为0值的数据隐去以更清晰地对比。
f) 在显示部分,Bob设置线的填充度为0.3,以区分明显地显示各个指标的情况,其余均为默认设置。
面板设置完成,点击返回,面板设置内容便自动保存,返回到仪表盘页面。
g) Bob发现该面板被图例占了很大篇幅,于是将鼠标置于面板右下角,拖拽面板横向拉伸,使得面板看上去更舒服。
点击保存完成第一个面板的定制。
注意:点击标题右侧,可以进行编辑面板等操作
4. 随后,Bob制作了Disk、Memory、Network下多个面板,使用分组管理起来。为了让CPU分组呈现在最上方,Bob将其他分组收至最小,长按分组进行移动。
5. Bob最终完成了Cluster Overview仪表盘,以后就可以通过该仪表盘观测所有节点的概况了。
告警预警
有些指标不便于可视化监控,需要精确知道这些指标是否高出或低于某个阈值。因此,Bob还需要使用告警来辅助运维。通过导航栏-告警-规则设置,进入规则管理页面。
在该页面,Bob看到了预定义的基本告警规则。这里的意思是,通过指标阈值,查询Node节点的CPU使用率,当比例超过90%时开始告警,警告持续1分钟。Bob可以自行根据自身需求设置需要的告警内容。
告警通知
Bob为了能够及时收到告警信息,确保不犯工作上的疏忽,将自己加入通知目标,使用分派策略给自己通知某些指标的告警情况。
告警的标签名称目前仅支持从Manager页面进行管理和查看,步骤如下:
- 进入Manager页面中的Aquila服务详情页,找到Alertmanager服务角色,点击查看,进入对应的link标签页
2. 进入Alertmanager管理页面,可以看到设定好的标签和值
更多产品使用内容请参考下方手册
 登录后可评论
登录后可评论








.jpg)



