Spark计算框架
随着大量的企业开始通过Hadoop来构建企业应用,MapReduce的性能慢的问题逐渐成为瓶颈,只能用于离线的数据处理,而不能用于对性能要求高的计算场景,如在线交互式分析、实时分析等。在此背景下,Spark计算模型诞生了。虽然本质上Spark仍然是一个MapReduce的计算模式,但是有几个核心的创新使得Spark的性能比MapReduce快一个数量级以上。第一是数据尽量通过内存进行交互,相比较基于磁盘的交换,能够避免IO带来的性能问题;第二采用Lazy evaluation的计算模型和基于DAG(Directed Acyclic Graph, 有向无环图)的执行模式,可以生成更好的执行计划。此外,通过有效的check pointing机制可以实现良好的容错,避免内存失效带来的计算问题。
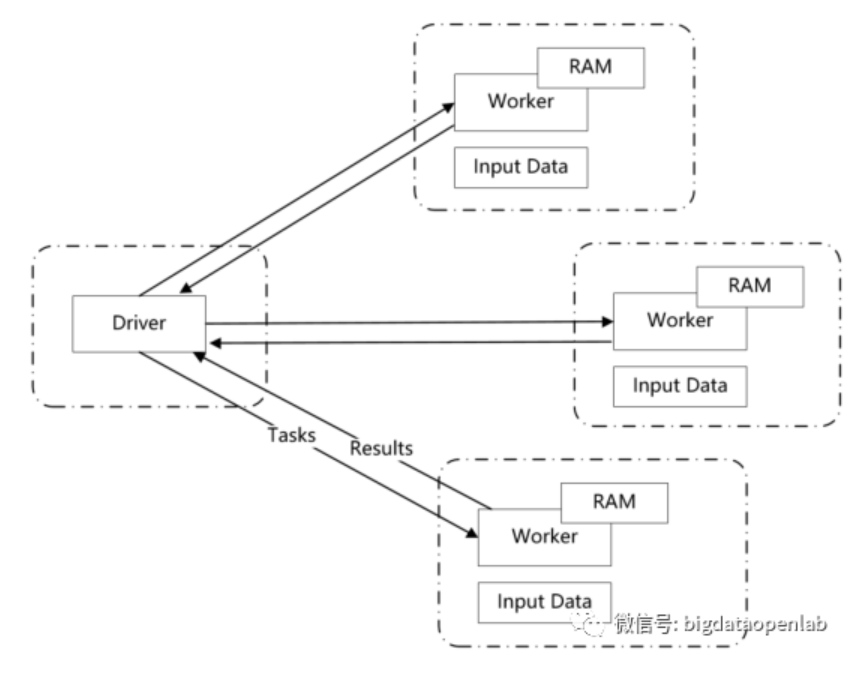
Spark 实现了一种分布式的内存抽象,称为弹性分布式数据集(RDD,Resilient Distributed Datasets)。它支持基于工作集的应用,同时具有数据流模型的特点 自动容错、位置感知调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和 groupBy) 而创建,然而这些限制使得实现容错的开销很低。与分布式共享内存系统需要付出高昂代价的检查点和回滚机制不同,RDD通过Lineage来重建丢失的分区一个RDD中包含了如何从其他 RDD衍生所必需的相关信息,从而不需要检查点操作就可以重构丢失的数据分区。
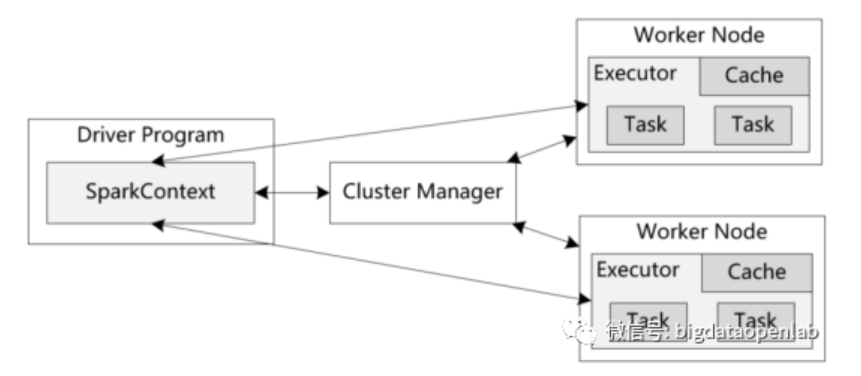
除了Spark Core API以外,Spark还包含几个主要的组件来提供大数据分析和数据挖掘的能力,主要包括Spark SQL、Spark Streaming、Spark MLLib。
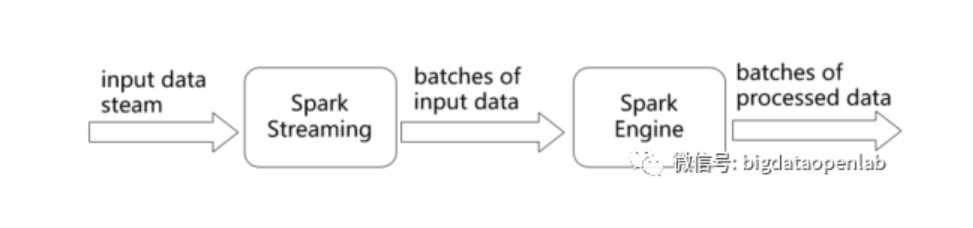
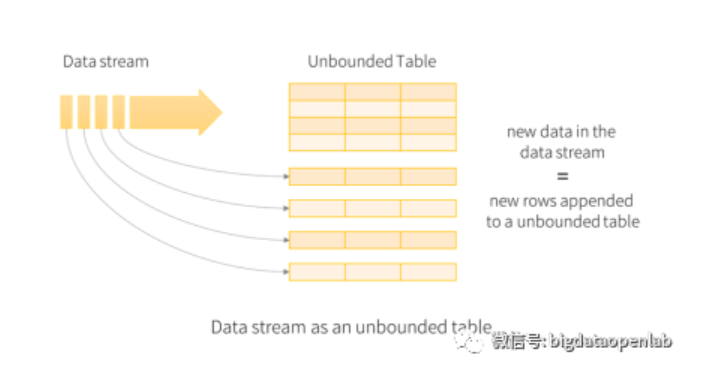
由于Spark Streaming采用了微批的处理方式,系统本身的吞吐量比较高,但是从应用的视角来看,数据从发生到计算结构的延时在500毫秒甚至以上,如果一个复杂逻辑涉及到多个流上的复杂运算,这个延时将会进一步放大,因此对一些延时敏感度比较高的应用,Spark Streaming的延时过高问题是非常严重的架构问题。Spark社区也在积极的解决相关的问题,从Spark 2.x版本开始推出了Structured Streaming,最本质的区别是不再将数据按照batch来处理,而是每个接收到的数据都会触发计算操作并追加到Data Stream中,紧接着新追加的记录就会被相应的流应用处理并更新到结果表中,如下图所示。
由于Structured Streaming有效地降低了实时计算的延时,此外又是直接基于Dataframe和Dataset API进行了封装,从而方便与Spark SQL以及MLlib对接,因此很快便取代了Spark Streaming成为Spark主要的实时计算方案。此后,社区很快增加了对数据乱序问题的处理、通过checkpoint机制保证At least once语义等关键的流计算功能要求,逐步贴近了生产需求。
Spark 实现了一种分布式的内存抽象,称为弹性分布式数据集(RDD,Resilient Distributed Datasets)。它支持基于工作集的应用,同时具有数据流模型的特点 自动容错、位置感知调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和 groupBy) 而创建,然而这些限制使得实现容错的开销很低。与分布式共享内存系统需要付出高昂代价的检查点和回滚机制不同,RDD通过Lineage来重建丢失的分区一个RDD中包含了如何从其他 RDD衍生所必需的相关信息,从而不需要检查点操作就可以重构丢失的数据分区。
除了Spark Core API以外,Spark还包含几个主要的组件来提供大数据分析和数据挖掘的能力,主要包括Spark SQL、Spark Streaming、Spark MLLib。
- Spark SQL
- Spark Streaming
由于Spark Streaming采用了微批的处理方式,系统本身的吞吐量比较高,但是从应用的视角来看,数据从发生到计算结构的延时在500毫秒甚至以上,如果一个复杂逻辑涉及到多个流上的复杂运算,这个延时将会进一步放大,因此对一些延时敏感度比较高的应用,Spark Streaming的延时过高问题是非常严重的架构问题。Spark社区也在积极的解决相关的问题,从Spark 2.x版本开始推出了Structured Streaming,最本质的区别是不再将数据按照batch来处理,而是每个接收到的数据都会触发计算操作并追加到Data Stream中,紧接着新追加的记录就会被相应的流应用处理并更新到结果表中,如下图所示。
由于Structured Streaming有效地降低了实时计算的延时,此外又是直接基于Dataframe和Dataset API进行了封装,从而方便与Spark SQL以及MLlib对接,因此很快便取代了Spark Streaming成为Spark主要的实时计算方案。此后,社区很快增加了对数据乱序问题的处理、通过checkpoint机制保证At least once语义等关键的流计算功能要求,逐步贴近了生产需求。
- Spark MLLib
随着大量的企业开始通过Hadoop来构建企业应用,MapReduce的性能慢的问题逐渐成为瓶颈,只能用于离线的数据处理,而不能用于对性能要求高的计算场景,如在线交互式分析、实时分析等。在此背景下,Spark计算模型诞生了。虽然本质上Spark仍然是一个MapReduce的计算模式,但是有几个核心的创新使得Spark的性能比MapReduce快一个数量级以上。第一是数据尽量通过内存进行交互,相比较基于磁盘的交换,能够避免IO带来的性能问题;第二采用Lazy evaluation的计算模型和基于DAG(Directed Acyclic Graph, 有向无环图)的执行模式,可以生成更好的执行计划。此外,通过有效的check pointing机制可以实现良好的容错,避免内存失效带来的计算问题。
Spark 实现了一种分布式的内存抽象,称为弹性分布式数据集(RDD,Resilient Distributed Datasets)。它支持基于工作集的应用,同时具有数据流模型的特点 自动容错、位置感知调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和 groupBy) 而创建,然而这些限制使得实现容错的开销很低。与分布式共享内存系统需要付出高昂代价的检查点和回滚机制不同,RDD通过Lineage来重建丢失的分区一个RDD中包含了如何从其他 RDD衍生所必需的相关信息,从而不需要检查点操作就可以重构丢失的数据分区。
除了Spark Core API以外,Spark还包含几个主要的组件来提供大数据分析和数据挖掘的能力,主要包括Spark SQL、Spark Streaming、Spark MLLib。
由于Spark Streaming采用了微批的处理方式,系统本身的吞吐量比较高,但是从应用的视角来看,数据从发生到计算结构的延时在500毫秒甚至以上,如果一个复杂逻辑涉及到多个流上的复杂运算,这个延时将会进一步放大,因此对一些延时敏感度比较高的应用,Spark Streaming的延时过高问题是非常严重的架构问题。Spark社区也在积极的解决相关的问题,从Spark 2.x版本开始推出了Structured Streaming,最本质的区别是不再将数据按照batch来处理,而是每个接收到的数据都会触发计算操作并追加到Data Stream中,紧接着新追加的记录就会被相应的流应用处理并更新到结果表中,如下图所示。
由于Structured Streaming有效地降低了实时计算的延时,此外又是直接基于Dataframe和Dataset API进行了封装,从而方便与Spark SQL以及MLlib对接,因此很快便取代了Spark Streaming成为Spark主要的实时计算方案。此后,社区很快增加了对数据乱序问题的处理、通过checkpoint机制保证At least once语义等关键的流计算功能要求,逐步贴近了生产需求。
Spark 实现了一种分布式的内存抽象,称为弹性分布式数据集(RDD,Resilient Distributed Datasets)。它支持基于工作集的应用,同时具有数据流模型的特点 自动容错、位置感知调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和 groupBy) 而创建,然而这些限制使得实现容错的开销很低。与分布式共享内存系统需要付出高昂代价的检查点和回滚机制不同,RDD通过Lineage来重建丢失的分区一个RDD中包含了如何从其他 RDD衍生所必需的相关信息,从而不需要检查点操作就可以重构丢失的数据分区。
除了Spark Core API以外,Spark还包含几个主要的组件来提供大数据分析和数据挖掘的能力,主要包括Spark SQL、Spark Streaming、Spark MLLib。
- Spark SQL
- Spark Streaming
由于Spark Streaming采用了微批的处理方式,系统本身的吞吐量比较高,但是从应用的视角来看,数据从发生到计算结构的延时在500毫秒甚至以上,如果一个复杂逻辑涉及到多个流上的复杂运算,这个延时将会进一步放大,因此对一些延时敏感度比较高的应用,Spark Streaming的延时过高问题是非常严重的架构问题。Spark社区也在积极的解决相关的问题,从Spark 2.x版本开始推出了Structured Streaming,最本质的区别是不再将数据按照batch来处理,而是每个接收到的数据都会触发计算操作并追加到Data Stream中,紧接着新追加的记录就会被相应的流应用处理并更新到结果表中,如下图所示。
由于Structured Streaming有效地降低了实时计算的延时,此外又是直接基于Dataframe和Dataset API进行了封装,从而方便与Spark SQL以及MLlib对接,因此很快便取代了Spark Streaming成为Spark主要的实时计算方案。此后,社区很快增加了对数据乱序问题的处理、通过checkpoint机制保证At least once语义等关键的流计算功能要求,逐步贴近了生产需求。
- Spark MLLib
评论
 登录后可评论
登录后可评论发布者

LilJ
文章
14
问答
231
关注者
17
热门问答









.jpg)


关注星环科技
获取最新活动资讯

