关联子查询调优系列 | 如何利用窗口函数、及JOIN优化查询性能
前言
在数据库管理和开发过程中,面对海量数据集时,如何高效地执行复杂的查询操作一直是开发者关注的核心问题之一。关联子查询(Correlated Subquery)是指子查询中引用了外部查询的列,它的特别之处在于,其本身是不完整的,它的闭包中包含一些外层查询提供的参数。所以关联子查询的执行顺序为先执行外层查询,然后对所有通过过滤条件的记录执行内层查询。关联子查询作为实现基于主查询条件动态过滤逻辑的一种常见手段,虽然直观易用,但在处理大规模数据时往往面临性能挑战。未经过优化的关联子查询可能导致重复计算和不必要的资源消耗,成为系统性能的瓶颈。
在《关联子查询调优系列 | 如何使用通用表表达式(CTE)》一文中,我们提到了通过 CTE 提升查询可读性和执行效率的方法,介绍了如何将嵌套的子查询逻辑提取为中间结果以避免重复计算。然而,CTE 并非唯一的解决方案,也不是所有场景下的最优选择。为了更全面地应对各类关联子查询带来的性能问题,本文将继续深入该主题,介绍另外两种行之有效的优化策略:使用窗口函数进行复杂分析计算的重构、通过 JOIN 实现高效的表间连接以及替代传统子查询以减少执行次数。
这两种方法各自具有不同的作用机制和适用场景:
- 窗口函数能够在一次扫描中完成聚合与比较操作,非常适合用于替代需要多次执行的子查询逻辑,尤其适用于涉及排名、分组统计等分析型查询;
- JOIN 操作则更适合处理大数据集下多表关联的场景,能够有效避免子查询的反复执行,同时提升数据筛选和连接效率。
改写为窗口函数
作用原理
使用窗口函数来替代子查询,从而在主查询中执行聚合计算,从而减少了子查询的执行次数,提高了查询性能。
1、使用窗口函数替换子查询中原有的聚合函数,子查询中的相关列作为 Partition Key,新增临时列用于存储结果。
2、进行去关联化,将外部查询和子查询的相关表下推到子查询中,进行 Join,根据相关列是否唯一分为两种情况
- 唯一:直接下推不会导致数据增加(内层每一行,最多 Join 上外层一行),由于外层中也有这个内层表以及表上的过滤条件(包含关系)。内层过滤掉的数据外层也一样过滤掉了,数据内外是一致的,这时窗口函数分区列是 "[内层相关列]"
- 不唯一:外层相关列不是主键/唯一列,拉入内层后,内层表数据量会由于 Join 而变多(重复的外层相关列)。此时仍需要保证“对外表每一行,内表做一次聚集”的语义,因此窗口函数分区列是 "[外表主键, 内层相关列]"
3、此时子查询包含了所有共同相关表,因此可以去掉外部查询的相关表,剩余与子查询无关的非相关表,再与子查询经过窗口函数计算过的表进行 Join,从而去除相关查询
适用场景
窗口函数通常用于执行分析型计算,例如排名、累积和分组比较。窗口函数通常用于类似以下情况的查询,其中需要在结果集中执行分析操作:
- 执行窗口操作:窗口函数是执行窗口操作的理想工具。例如,计算排名、累积总和、移动平均等窗口操作,通常比使用关联子查询更有效。
- 分析数据分布:窗口函数可用于分析数据分布,例如查找每个分组内的最大值、最小值、中位数等。这些操作通常需要多次查询,而窗口函数可以一次性完成。
- 减少重复计算:关联子查询可能会导致相同的子查询多次执行,浪费计算资源。窗口函数可以在一次查询中执行计算,减少了冗余的工作,提高了性能。
- 简化复杂查询:当关联子查询嵌套层次较深或具有多个子查询时,查询语句会变得复杂难以理解。使用窗口函数可以将复杂查询重构为更简单的形式,提高可维护性。
改写前提
使用窗口函数改写关联子查询时,需要注意满足以下前提:
1、检查外部查询:
- 需要包含一个带有聚合函数的子查询。
- 不存在任何会破坏主查询的条件,如带有副作用的函数(Rank、Rand 等)。
2、检查子查询:
- 子查询中不存在 odd 函数(将正(负)数向上(下)舍入到最接近的奇数)。
- 子查询中不存在 ORDER BY 或 TopN 子句。
- 子查询没有作为公共子表达式使用。
3、检查聚合函数:
- 存在等价的窗口聚合函数
- 聚合函数内没有 DISTINCT 关键字。
4、使用子查询匹配外部查询,生成一个带有外部查询也包含共同表的临时的查询 Block。 这样做是为了可以复用物化视图构建的函数,也就是使用物化视图将这个临时的 Query block 进行保存,作为中间的结果供后续使用,此时就可以删除这个临时的 Query Block 了。
5、外层在 join table/condition 上包含内层时,内层如果有其他非相关表,必须是无损连接(lesslose join),这样才能确保内层相关表的数据在 Join 过程中不会丢失或增加。 内层相关表可以添加更多的单表限定条件,转换时,需要在窗口聚合过程中借助于像 CASE WHEN 这样的条件判断,以确保数据能够按照原来的语义进行过滤。
优化示例
原始关联子查询 查找销售金额高于平均销售金额的客户,并返回前 10 位符合条件的客户:
WITH tmp AS (
SLEECT c_customer_id, s.ss_sales_price
FROM customer, store_sales s
WHERE s.ss_customer_sk = c_customer_sk
)
SELECT c_customer_id, ss_sales_price
FROM tmp a
WHERE ss_sales_price > (SELECT 0.2 * AVG(ss_sales_price) FROM tmp b WHERE a.c_customer_id = b.c_customer_id)
LIMIT 10进入 DBA Service 查看性能如下:该关联子查询用时 1.6m。
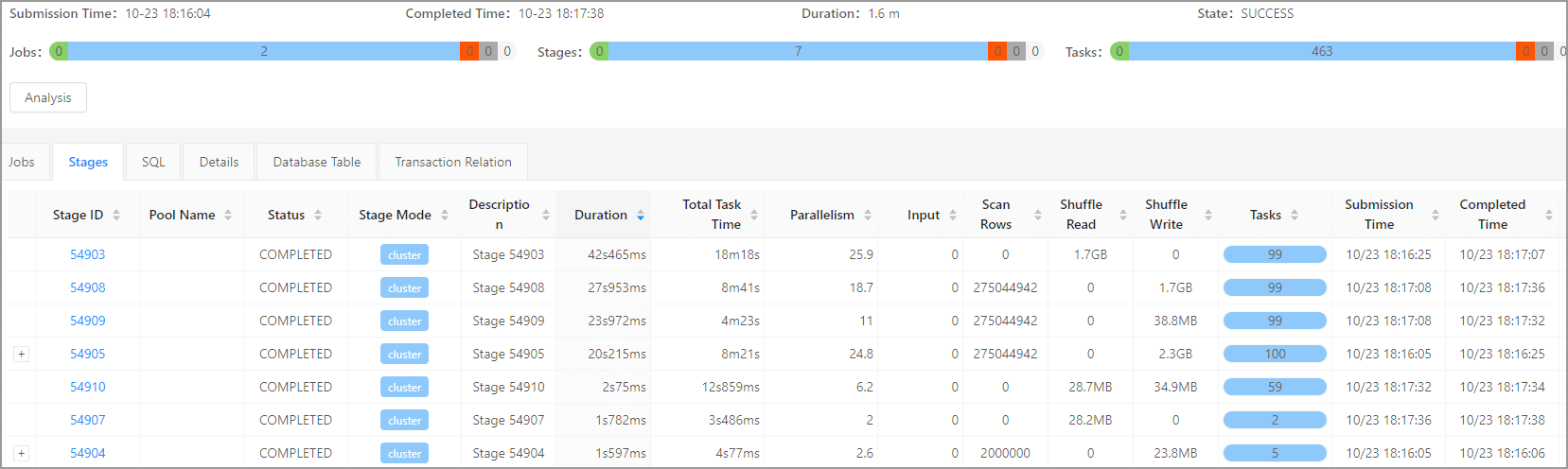
使用窗口函数进行改写
WITH tmp AS (
SELECT c.c_customer_id, s.ss_sales_price, AVG(s.ss_sales_price) OVER (PARTITION BY c.c_customer_sk ) AS avg_sales
FROM customer c, store_sales s
WHERE c.c_customer_sk = s.ss_customer_sk
)
SELECT c_customer_id, ss_sales_price
FROM tmp
WHERE ss_sales_price > 0.2 * avg_sales
LIMIT 10可以发现运行时长为 30.9s,对比使用关联子查询的运行时间上优化了 2 倍。
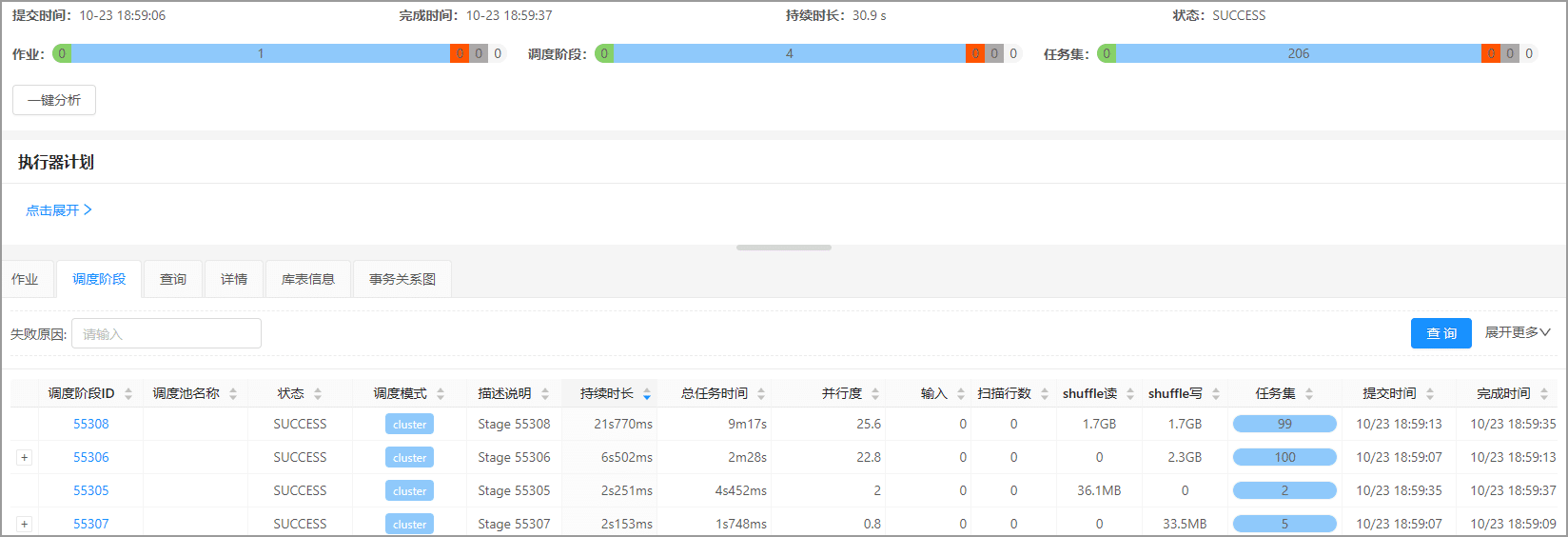
改写为 JOIN
作用原理
将关联子查询改写为 INNER JOIN 操作,以避免多次执行子查询。INNER JOIN 会将两个表关联在一起,根据连接条件过滤不匹配的行,从而减少数据的处理量。
适用场景
通常情况下,当出现以下类型的关联子查询时,考虑将其改写为 JOIN 操作是一个有效的优化手段:
- 存在大数据集的情况:当查询的表很大且关联子查询的计算较为复杂时,关联子查询的性能可能较差。在这种情况下,INNER JOIN 可以更有效地筛选和连接数据,从而提高查询性能。
- 多次引用子查询结果:如果子查询的结果需要在主查询中多次引用,多次执行相同的子查询会导致性能下降。INNER JOIN 可以将子查询的结果与主查询表进行关联,避免多次执行相同的子查询。
- 需要比较多个相关列:如果关联子查询需要比较多个相关列的值,INNER JOIN 可以更清晰地表示这些关系,提高查询的可读性和维护性。
- 需要在关联条件中进行复杂的逻辑操作:INNER JOIN 允许您在关联条件中执行更复杂的逻辑操作,而不受关联子查询的限制。
优化示例
关联子查询 SQL 示例 假设我们有两个表,分别为 store_sales 和 customer,其中 store_sales 表包含销售数据,customer 表包含客户信息。我们想查找购买产品 '98377' 的累计销售金额大于 10000 的客户。
首先给出原始关联子查询 SQL 语句如下:
SELECT c.c_customer_id
FROM customer c
WHERE (
SELECT SUM(ss.ss_ext_sales_price)
FROM store_sales ss
WHERE ss.ss_customer_sk = c.c_customer_sk
) > 500000
AND LEFT(c.c_first_name, 1) = 'M'
ORDER BY c.c_customer_id DESC;进入 DBAService 界面查看该查询的性能:总耗时为 27s,Shuffle 读为 384.559MB 读速度为 606.76KB/s、Shuffle 写为 523.755MB 写速度为 826.39KB/s。
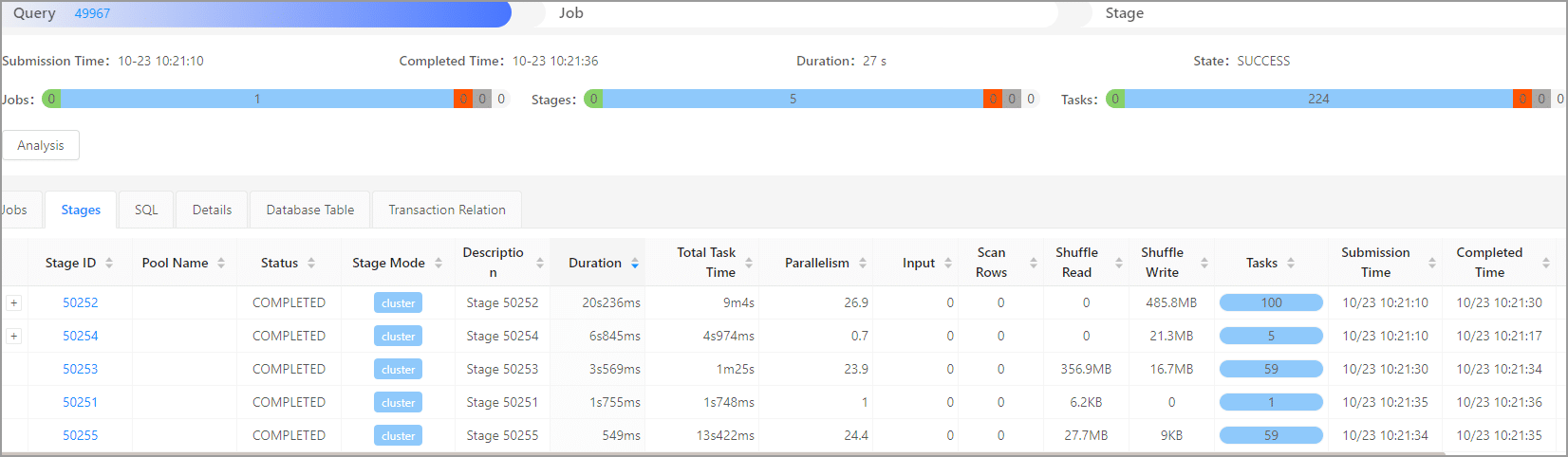
使用JOIN进行改写
可以将子查询的功能合并到主查询中,使用连接操作,以减少子查询的执行次数:
SELECT c.c_customer_id
FROM customer c
JOIN (
SELECT ss_customer_sk, SUM(ss_ext_sales_price) AS total_sales
FROM store_sales
GROUP BY ss_customer_sk
HAVING total_sales > 10000
) AS sales_summary
ON CONCAT(c.c_customer_sk, '') = CONCAT(sales_summary.ss_customer_sk, '')
ORDER BY c.c_customer_id
LIMIT 10;使用连接(JOIN)来代替子查询的过滤条件,经过改写之后的 SQL 语句的执行时间为 7.2s,对于原始关联子查询语句优化了约 2.8 倍。另外 shuffle 读速度为 1.81MB/s,shuffle 写速度为 2.45MB/s,较原始关联子查询均加快了 2 倍。
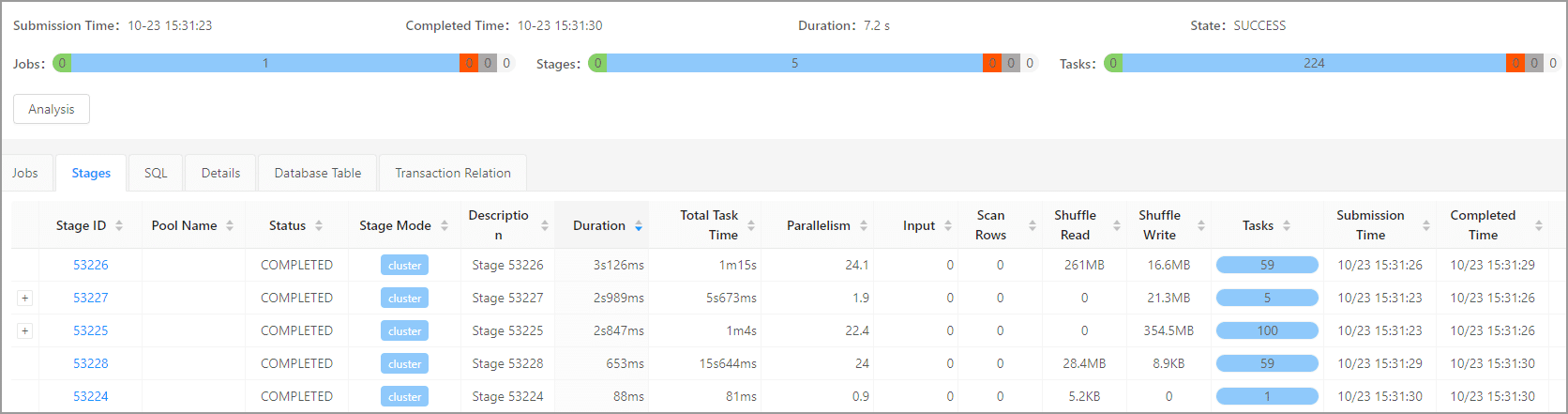
前言
在数据库管理和开发过程中,面对海量数据集时,如何高效地执行复杂的查询操作一直是开发者关注的核心问题之一。关联子查询(Correlated Subquery)是指子查询中引用了外部查询的列,它的特别之处在于,其本身是不完整的,它的闭包中包含一些外层查询提供的参数。所以关联子查询的执行顺序为先执行外层查询,然后对所有通过过滤条件的记录执行内层查询。关联子查询作为实现基于主查询条件动态过滤逻辑的一种常见手段,虽然直观易用,但在处理大规模数据时往往面临性能挑战。未经过优化的关联子查询可能导致重复计算和不必要的资源消耗,成为系统性能的瓶颈。
在《关联子查询调优系列 | 如何使用通用表表达式(CTE)》一文中,我们提到了通过 CTE 提升查询可读性和执行效率的方法,介绍了如何将嵌套的子查询逻辑提取为中间结果以避免重复计算。然而,CTE 并非唯一的解决方案,也不是所有场景下的最优选择。为了更全面地应对各类关联子查询带来的性能问题,本文将继续深入该主题,介绍另外两种行之有效的优化策略:使用窗口函数进行复杂分析计算的重构、通过 JOIN 实现高效的表间连接以及替代传统子查询以减少执行次数。
这两种方法各自具有不同的作用机制和适用场景:
- 窗口函数能够在一次扫描中完成聚合与比较操作,非常适合用于替代需要多次执行的子查询逻辑,尤其适用于涉及排名、分组统计等分析型查询;
- JOIN 操作则更适合处理大数据集下多表关联的场景,能够有效避免子查询的反复执行,同时提升数据筛选和连接效率。
改写为窗口函数
作用原理
使用窗口函数来替代子查询,从而在主查询中执行聚合计算,从而减少了子查询的执行次数,提高了查询性能。
1、使用窗口函数替换子查询中原有的聚合函数,子查询中的相关列作为 Partition Key,新增临时列用于存储结果。
2、进行去关联化,将外部查询和子查询的相关表下推到子查询中,进行 Join,根据相关列是否唯一分为两种情况
- 唯一:直接下推不会导致数据增加(内层每一行,最多 Join 上外层一行),由于外层中也有这个内层表以及表上的过滤条件(包含关系)。内层过滤掉的数据外层也一样过滤掉了,数据内外是一致的,这时窗口函数分区列是 "[内层相关列]"
- 不唯一:外层相关列不是主键/唯一列,拉入内层后,内层表数据量会由于 Join 而变多(重复的外层相关列)。此时仍需要保证“对外表每一行,内表做一次聚集”的语义,因此窗口函数分区列是 "[外表主键, 内层相关列]"
3、此时子查询包含了所有共同相关表,因此可以去掉外部查询的相关表,剩余与子查询无关的非相关表,再与子查询经过窗口函数计算过的表进行 Join,从而去除相关查询
适用场景
窗口函数通常用于执行分析型计算,例如排名、累积和分组比较。窗口函数通常用于类似以下情况的查询,其中需要在结果集中执行分析操作:
- 执行窗口操作:窗口函数是执行窗口操作的理想工具。例如,计算排名、累积总和、移动平均等窗口操作,通常比使用关联子查询更有效。
- 分析数据分布:窗口函数可用于分析数据分布,例如查找每个分组内的最大值、最小值、中位数等。这些操作通常需要多次查询,而窗口函数可以一次性完成。
- 减少重复计算:关联子查询可能会导致相同的子查询多次执行,浪费计算资源。窗口函数可以在一次查询中执行计算,减少了冗余的工作,提高了性能。
- 简化复杂查询:当关联子查询嵌套层次较深或具有多个子查询时,查询语句会变得复杂难以理解。使用窗口函数可以将复杂查询重构为更简单的形式,提高可维护性。
改写前提
使用窗口函数改写关联子查询时,需要注意满足以下前提:
1、检查外部查询:
- 需要包含一个带有聚合函数的子查询。
- 不存在任何会破坏主查询的条件,如带有副作用的函数(Rank、Rand 等)。
2、检查子查询:
- 子查询中不存在 odd 函数(将正(负)数向上(下)舍入到最接近的奇数)。
- 子查询中不存在 ORDER BY 或 TopN 子句。
- 子查询没有作为公共子表达式使用。
3、检查聚合函数:
- 存在等价的窗口聚合函数
- 聚合函数内没有 DISTINCT 关键字。
4、使用子查询匹配外部查询,生成一个带有外部查询也包含共同表的临时的查询 Block。 这样做是为了可以复用物化视图构建的函数,也就是使用物化视图将这个临时的 Query block 进行保存,作为中间的结果供后续使用,此时就可以删除这个临时的 Query Block 了。
5、外层在 join table/condition 上包含内层时,内层如果有其他非相关表,必须是无损连接(lesslose join),这样才能确保内层相关表的数据在 Join 过程中不会丢失或增加。 内层相关表可以添加更多的单表限定条件,转换时,需要在窗口聚合过程中借助于像 CASE WHEN 这样的条件判断,以确保数据能够按照原来的语义进行过滤。
优化示例
原始关联子查询 查找销售金额高于平均销售金额的客户,并返回前 10 位符合条件的客户:
WITH tmp AS (
SLEECT c_customer_id, s.ss_sales_price
FROM customer, store_sales s
WHERE s.ss_customer_sk = c_customer_sk
)
SELECT c_customer_id, ss_sales_price
FROM tmp a
WHERE ss_sales_price > (SELECT 0.2 * AVG(ss_sales_price) FROM tmp b WHERE a.c_customer_id = b.c_customer_id)
LIMIT 10进入 DBA Service 查看性能如下:该关联子查询用时 1.6m。
使用窗口函数进行改写
WITH tmp AS (
SELECT c.c_customer_id, s.ss_sales_price, AVG(s.ss_sales_price) OVER (PARTITION BY c.c_customer_sk ) AS avg_sales
FROM customer c, store_sales s
WHERE c.c_customer_sk = s.ss_customer_sk
)
SELECT c_customer_id, ss_sales_price
FROM tmp
WHERE ss_sales_price > 0.2 * avg_sales
LIMIT 10可以发现运行时长为 30.9s,对比使用关联子查询的运行时间上优化了 2 倍。
改写为 JOIN
作用原理
将关联子查询改写为 INNER JOIN 操作,以避免多次执行子查询。INNER JOIN 会将两个表关联在一起,根据连接条件过滤不匹配的行,从而减少数据的处理量。
适用场景
通常情况下,当出现以下类型的关联子查询时,考虑将其改写为 JOIN 操作是一个有效的优化手段:
- 存在大数据集的情况:当查询的表很大且关联子查询的计算较为复杂时,关联子查询的性能可能较差。在这种情况下,INNER JOIN 可以更有效地筛选和连接数据,从而提高查询性能。
- 多次引用子查询结果:如果子查询的结果需要在主查询中多次引用,多次执行相同的子查询会导致性能下降。INNER JOIN 可以将子查询的结果与主查询表进行关联,避免多次执行相同的子查询。
- 需要比较多个相关列:如果关联子查询需要比较多个相关列的值,INNER JOIN 可以更清晰地表示这些关系,提高查询的可读性和维护性。
- 需要在关联条件中进行复杂的逻辑操作:INNER JOIN 允许您在关联条件中执行更复杂的逻辑操作,而不受关联子查询的限制。
优化示例
关联子查询 SQL 示例 假设我们有两个表,分别为 store_sales 和 customer,其中 store_sales 表包含销售数据,customer 表包含客户信息。我们想查找购买产品 '98377' 的累计销售金额大于 10000 的客户。
首先给出原始关联子查询 SQL 语句如下:
SELECT c.c_customer_id
FROM customer c
WHERE (
SELECT SUM(ss.ss_ext_sales_price)
FROM store_sales ss
WHERE ss.ss_customer_sk = c.c_customer_sk
) > 500000
AND LEFT(c.c_first_name, 1) = 'M'
ORDER BY c.c_customer_id DESC;进入 DBAService 界面查看该查询的性能:总耗时为 27s,Shuffle 读为 384.559MB 读速度为 606.76KB/s、Shuffle 写为 523.755MB 写速度为 826.39KB/s。
使用JOIN进行改写
可以将子查询的功能合并到主查询中,使用连接操作,以减少子查询的执行次数:
SELECT c.c_customer_id
FROM customer c
JOIN (
SELECT ss_customer_sk, SUM(ss_ext_sales_price) AS total_sales
FROM store_sales
GROUP BY ss_customer_sk
HAVING total_sales > 10000
) AS sales_summary
ON CONCAT(c.c_customer_sk, '') = CONCAT(sales_summary.ss_customer_sk, '')
ORDER BY c.c_customer_id
LIMIT 10;使用连接(JOIN)来代替子查询的过滤条件,经过改写之后的 SQL 语句的执行时间为 7.2s,对于原始关联子查询语句优化了约 2.8 倍。另外 shuffle 读速度为 1.81MB/s,shuffle 写速度为 2.45MB/s,较原始关联子查询均加快了 2 倍。
 登录后可评论
登录后可评论








.jpg)



