探索YARN调度器:FIFO、Fair与Capacity Scheduler的深度解析
友情链接:
YARN 资源管理概述
Apache Hadoop YARN (Yet Another Resource Negotiator) 是一个分布式资源管理框架,它负责管理集群中的计算资源并调度用户的应用程序。YARN 的出现标志着 Hadoop 框架从最初的 MapReduce v1 架构向更为灵活和可扩展的架构的重大演进。在 YARN 中,资源管理与作业处理被分离,使得 Hadoop 能够支持更多类型的分布式计算模式,而不仅仅是 MapReduce。YARN 的核心任务是有效地分配和管理集群内的 CPU、内存、磁盘和网络等资源,以确保应用程序能够高效运行。
在 YARN 架构中,有三个关键组件协同工作:ResourceManager (RM)、NodeManager (NM) 和 ApplicationMaster (AM)。ResourceManager 是全局的资源管理器,负责整个系统的资源管理和分配。NodeManager 驻留在集群的每个节点上,负责管理本节点的资源和任务。ApplicationMaster 则负责管理一个应用程序的生命周期内的所有工作,包括与 RM 协商资源、将资源分配给内部的任务以及监控任务的运行状态。
ResourceManager 是 Hadoop YARN 的核心组件。调度器是 ResourceManager 组件的核心。可以使用计划程序来管理集群资源并将资源分配给应用程序。Schedulers 优化集群的资源布局,以最大限度地利用集群资源,并防止热点问题等问题影响应用程序。计划程序还可以协调在集群上运行的各种应用程序,并根据多租户公平性和应用程序优先级等策略解决资源竞争问题。Schedulers 可以满足特定应用程序在节点依赖和放置策略方面的要求。
- FIFO Scheduler 是最简单的 scheduler。它不允许将应用程序提交给多个租户进行调度。这表示所有应用程序都提交到默认队列进行调度,而无需分配集群资源。在这种情况下,应用程序是根据 FIFO 策略进行调度的,没有其他控制和调度配置。FIFO Scheduler 仅适用于简单场景,很少在生产环境中使用。
- Fair Scheduler 是一种提供多租户管理和资源调度能力的调度程序,其功能涵盖了多级队列管理、配额管理、基于访问控制列表(ACL)的控制、资源共享、租户之间的公平调度、租户内的应用程序调度、资源预留和抢占以及异步调度。然而,Fair Scheduler 的开发活跃度相较于 Apache Hadoop 中的 Capacity Scheduler 较低,且它不考虑集群的资源布局,缺乏对节点标签、节点属性、放置约束等高级调度功能的支持。
- Capacity Scheduler 是 Apache Hadoop 使用的默认计划程序。Capacity Scheduler 提供完整的多租户管理和资源调度功能,其中包括 Fair Scheduler 的所有功能。Capacity Scheduler 可以基于全局调度优化集群的资源布局,降低热点问题的风险,最大限度地利用集群资源。Capacity Scheduler 还支持节点标签、节点属性和放置约束等计划功能。
FIFO Scheduler(先进先出调度器)
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最先进入的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。下图展示FIFO的调度模式。
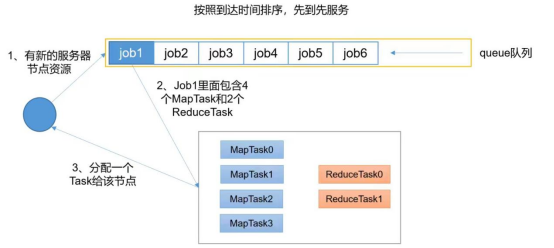
调度策略
整个集群作为单一队列,严格按任务提交顺序执行。FIFO是唯一调度策略。
优点
1、简单易用:无需复杂配置,适合快速部署和测试环境;所有应用按提交顺序分配资源,逻辑直观。
2、低开销:无队列管理、抢占检查等额外计算,调度速度快。
3、适合单任务场景:在单一任务独占集群或小规模环境中表现稳定。
缺点
1、资源利用率低:
- 大任务可能长时间占用资源,导致后续任务阻塞(资源饥饿问题)。
- 小作业在大作业后提交时,响应时间被大幅延长,甚至长期处于饥饿状态,无法平等共享集群资源。
- 无法动态调整分配策略,资源空闲时也无法高效利用。
2、缺乏多租户支持:无队列概念,所有应用共享单一队列,无法隔离不同团队或项目的资源。
3、优先级与抢占机制缺失:
- 不支持优先级抢占:低优先级作业一旦占用资源,即使高优先级作业到达也无法抢占资源,导致关键任务被阻塞。
- 资源分配后无法回收,无法满足动态调整需求(如紧急任务处理)。
4、作业需求差异化处理不足:未考虑作业规模、优先级或 SLA(服务等级协议)差异,导致小作业执行效率低下。
Fair Scheduler(公平调度器)
Fair Scheduler提供了Yarn应用程序公平地共享大型集群中资源的另一种形式。使所有应用在平均情况下随着时间的流式可以获得相等的资源份额。设计目标是为所有的应用分配公平的资源(对公平的定义通过参数来设置)。可以在多个丢列建工作,允许资源共享和抢占。
Fair Scheduler的基本思想是:不需要为组或队列预留一定量的内容。调度器在集群中的所有正在运行的作业之间动态分配可用资源。当大型作业首先启动,并且恰好是运行的唯一作业时,默认情况下将使用所有集群的资源(除非指定了最大资源限制)。随后,当第二个作业启动时,它被分配大约一半的总集群资源(默认情况下),现在两个作业在相同的基础上共享集群资源。
公平调度器的默认配置下:如果目前一个队列中有4个job正在运行,此时来了第5个job,这5个job共同平分整个队列的资源。
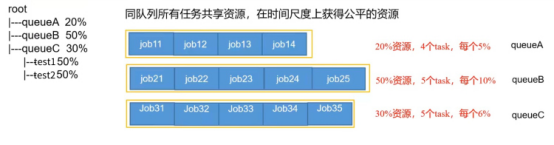
调度策略
- 多队列公平共享:动态平衡资源分配,无需预定义比例,按权重或公平份额分配资源
- 可配置调度策略:FIFO、Fair(默认)、DRF
Fair调度器是在选择队列和应用时都是按照某种公平算法来选择的。一种是最大最小公平算法,衡量的指标是内存资源。另一种是主资源公平算法,基于最大最小公平算法,衡量的指标是最主要的资源,可能是内存可能是 CPU 等。下面分别介绍下这两种算法。
a. Fair策略(最大最小公平算法)
在一个资源分配系统中,有多个用户请求分配资源,普通公平算法的策略是将总资源数除以用户数,每个用户获得一样的平均值数个资源。这样会出现个问题,有的用户资源需求数小于分配到的资源数,多出来的资源会被浪费,从而会使资源未得到满足的用户更加无法被满足,有的用户资源请求可以被满足确没得到满足。最大最小公平算法就是为了解决这个问题,主要目标是最大化未被满足资源需求的用户最小获得的资源数。
示例:有 5 个用户分别有 2,4,6,8,10 的资源需求,分配系统中资源总量为 20。第一轮分配将 20/5 = 4 的资源分配给各个用户,此时各个用户得到的资源数分别为 4,4,4,4,4。第一个用户资源需求为 2,多出了 2 个资源,这时候进行第二轮资源分配,将 2/4=0.5 均分给剩余的用户,此时所有用户拥有资源数为 2,4.5,4.5,4.5,4.5。第二个用户需要 4 个资源,获得的资源量超出了 0.5。此时进行第三轮分配,将 0.5/3=0.1666 均分给最后三个用户,此时分配结果为 2,4,4.666,4.666,4.666。第三个用户的资源需求数为 6,而他分配到的资源数为 4.666,小于需求数,分配结束。最终用户得到资源数分别为 2,4,4.666,4.666,4.666。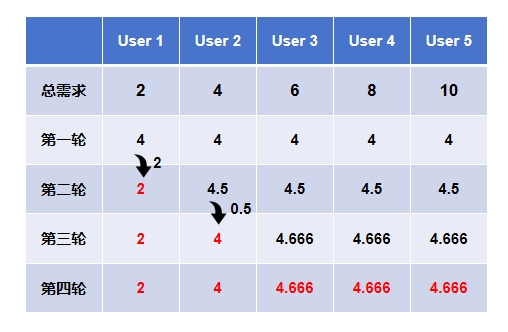
b. DRF策略(主资源公平算法)
在一个资源分配系统中,可能有多种类型的资源,用户一次资源请求中包括多种资源。这个时候需要选择出一个最主要的资源作为衡量标准。可以将用户已拥有的各个资源占分配系统总资源比例值最大的那个资源作为主资源。
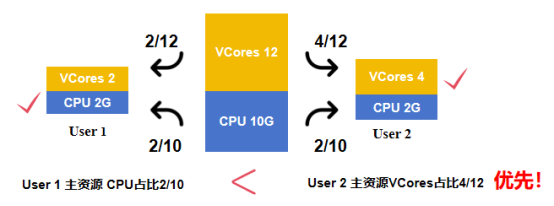
示例:分配系统中总资源为<CPU 10G, VCores 12> ,用户1当前拥有资源为<CPU 2G,VCores 2>,用户2当前拥有的资源为<CPU 2G, VCores 4>。
通过计算可得,用户1的CPU资源占比为2/10 = 1/5,VCores 资源占比为 2/12 = 1/6,所以用户 1 的主资源为 CPU。
用户 2 的 CPU 资源占比为 2/10 = 1/5,用户 2 的 VCores 资源占比为4/12 = 1/3,所以用户2的主资源为VCores。
在下轮资源分配请求中,因为用户1的主资源占比1/5小于用户2的主资源占比1/3,故先进行用户 1 的资源请求分配。
资源抢占
- 触发条件:某队列的资源使用量低于其公平份额(如最小资源保证);高优先级应用需要资源。
- 抢占目标选择:从超出公平份额的队列中抢占资源,优先选择低优先级应用、资源超额最多的应用、短任务(最小化损失)。
优点
1、资源公平共享:在每个队列中,Fair调度器可选择按照 FIFO、Fair 或 DRF 策略为应用程序分配资源,其中 Fair 策略是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。
2、分层队列:队列可以按层次结构排列以划分资源,并可以配置权重以按特定比例共享集群
3、基于用户或组的队列映射:可以根据提交任务的用户名或组来分配队列。如果任务指定了一个队列,则在该队列中提交任务
4、资源抢占:根据应用的配置,抢占和分配资源可以是友好的或者强制的。默认不启用资源抢占
5、保证最小配额:可以设置队列最小资源,允许将保证的最小份额分配给队列,保证用户可以启动任务。当队列不能满足最小资源时,可以从其他队列抢占。当队列资源使用不完时,可以给其他队列使用。这对于确保某些用户、组或者生产应用使用获得足够的资源
6、允许资源共享:即当一个应用运行时,如果其他队列没有任务执行,则可以使用其他队列。当其他队列有应用需要资源时再将占用的队列释放出来。所有的应用都从资源队列中分配资源。
7、任务负载均衡:Fair Scheduler 提供了一个基于任务数目的负载均衡机制,该进制尽可能的将系统中的任务均匀的分配到集群的各个节点上,同时也支持用户根据自身需要设计新的负载均衡机制。
缺点
1、资源隔离较弱:队列间仅通过权重分配资源,无法严格保证最小资源,可能影响关键任务稳定性。
2、配置复杂度中等:需维护策略文件定义队列结构和权重,但比 Capacity Scheduler 简单。
3、不适合严格隔离场景:多租户环境中,若需强隔离(如金融、生产环境),可能不如 Capacity Scheduler 可靠
Capacity Scheduler(容量调度器)
Capacity Scheduler允许多个组织共享整个集群资源,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务。
Capacity Scheduler的基本思想是:使用专用队列分配作业。每个队列具有分配给它的预定量的资源。但是,由于要保证队列资源的容量,因此可以根据集群的资源利用率来对容量进行设置。目标是使组织的多个租户(用户)以可预测的方式共享Hadoop集群的资源,Hadoop使用作业队列来实现这一目标。客户端通过将作业分配到特定的命名队列来调度作业,队列是一个Hadoop作业的有序列表,一个接一个地顺序执行。
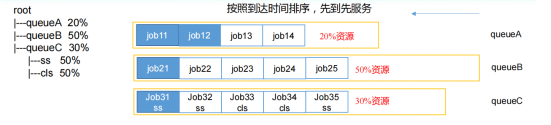
调度策略
- 多队列资源预留:通过预定义容量比例保证队列的资源下限,预先为每个队列设定容量比例,支持多租户资源隔离。
- 可配置的调度策略:FIFO(默认)、DRF
资源抢占
- 触发条件:某队列的资源使用量低于其保证容量;集群无空闲资源,且其他队列资源使用超出其容量上限。
- 抢占目标选择:从超出容量上限的队列中抢占资源,优先选择低优先级应用的容器、运行时间较长的任务(减少短任务被抢占的损失)。
优点
1、层次化的队列设计:所有子队列可以使用父队列的全部资源,每个子队列又可以设置单独的资源限制,通过这种层次化队列结构,更能合理利用限制集群资源。
2、容量保证:每个队列都会设置一个资源容量百分比值,这个比值的资源是队列可以保证得到的资源。这样通过每个队列资源占比,能够限制资源不会被独占。
3、安全:每个队列有严格的访问控制。用户只能向自己的队列里提交任务,而且不能修改或访问其他队列的任务
4、资源弹性分配:空闲的资源可以被分配给任何队列;当多个队列出现争用的时候,则按照权重比例进行平衡
5、多用户共享:多个用户通过队列共享整个集群资源,同时每个用户都能占有一定受保证的资源,尽最大可能满足所有用户需求,充分发挥集群能力,提高资源利用率。
缺点
1、配置复杂:需定义队列层级、容量、抢占策略等参数,管理成本高。
2、资源分配不够灵活:依赖静态队列配置,动态调整队列容量需手动干预,不适合频繁变化的负载。
3、公平性有限:在同一队列内默认使用FIFO策略,但跨队列资源分配仍以容量为核心,可能无法满足全局公平性需求。
对比总结
| 特性 | FIFO 调度器 | Fair 调度器 | Capacity 调度器 |
| 核心目标 | 简单任务顺序执行 | 资源公平共享与动态平衡 | 多租户资源隔离与容量保证 |
| 资源分配策略 | 整个集群作为单一队列,严格按任务提交顺序分配资源 | 集群资源按队列权重动态分配 | 集群划分为多个队列,预定义容量比例 |
| 多队列支持 | 仅单队列 | 支持多级队列,队列间资源按权重共享 | 支持多级队列,队列间资源隔离 |
| 资源隔离性 | 无隔离,大任务可能阻塞所有后续任务 | 弱隔离,队列间资源弹性共享,仅通过权重和最大资源限制约束 | 强隔离,队列资源上限防止超额占用 |
| 任务执行顺序 | 严格按提交顺序(FIFO) | 队列内默认Fair | 队列内默认FIFO |
| 抢占机制 | 不支持 | 队列间/队列内抢占:基于公平份额或优先级回收资源 | 队列间抢占:回收超容量队列的资源,保证容量下限 |
| 资源利用率 | 低:大任务独占资源时,小任务需长时间等待 | 高:资源按需动态分配,空闲资源按权重抢占。 | 中等:队列空闲资源可被其他队列借用,但容量上限限制弹性。 |
| 配置复杂度 | 极简(无需配置队列或策略) | 中等(需定义队列权重和公平性规则) | 较高(需预定义队列容量比例和层级结构) |
| 适用场景 | 测试环境、小规模集群或无需资源隔离的场景 | 混合负载环境需灵活资源共享的场景(如临时任务与长任务共存) | 生产环境需严格资源隔离的场景(如多部门/项目独立队列) |
友情链接:
YARN 资源管理概述
Apache Hadoop YARN (Yet Another Resource Negotiator) 是一个分布式资源管理框架,它负责管理集群中的计算资源并调度用户的应用程序。YARN 的出现标志着 Hadoop 框架从最初的 MapReduce v1 架构向更为灵活和可扩展的架构的重大演进。在 YARN 中,资源管理与作业处理被分离,使得 Hadoop 能够支持更多类型的分布式计算模式,而不仅仅是 MapReduce。YARN 的核心任务是有效地分配和管理集群内的 CPU、内存、磁盘和网络等资源,以确保应用程序能够高效运行。
在 YARN 架构中,有三个关键组件协同工作:ResourceManager (RM)、NodeManager (NM) 和 ApplicationMaster (AM)。ResourceManager 是全局的资源管理器,负责整个系统的资源管理和分配。NodeManager 驻留在集群的每个节点上,负责管理本节点的资源和任务。ApplicationMaster 则负责管理一个应用程序的生命周期内的所有工作,包括与 RM 协商资源、将资源分配给内部的任务以及监控任务的运行状态。
ResourceManager 是 Hadoop YARN 的核心组件。调度器是 ResourceManager 组件的核心。可以使用计划程序来管理集群资源并将资源分配给应用程序。Schedulers 优化集群的资源布局,以最大限度地利用集群资源,并防止热点问题等问题影响应用程序。计划程序还可以协调在集群上运行的各种应用程序,并根据多租户公平性和应用程序优先级等策略解决资源竞争问题。Schedulers 可以满足特定应用程序在节点依赖和放置策略方面的要求。
- FIFO Scheduler 是最简单的 scheduler。它不允许将应用程序提交给多个租户进行调度。这表示所有应用程序都提交到默认队列进行调度,而无需分配集群资源。在这种情况下,应用程序是根据 FIFO 策略进行调度的,没有其他控制和调度配置。FIFO Scheduler 仅适用于简单场景,很少在生产环境中使用。
- Fair Scheduler 是一种提供多租户管理和资源调度能力的调度程序,其功能涵盖了多级队列管理、配额管理、基于访问控制列表(ACL)的控制、资源共享、租户之间的公平调度、租户内的应用程序调度、资源预留和抢占以及异步调度。然而,Fair Scheduler 的开发活跃度相较于 Apache Hadoop 中的 Capacity Scheduler 较低,且它不考虑集群的资源布局,缺乏对节点标签、节点属性、放置约束等高级调度功能的支持。
- Capacity Scheduler 是 Apache Hadoop 使用的默认计划程序。Capacity Scheduler 提供完整的多租户管理和资源调度功能,其中包括 Fair Scheduler 的所有功能。Capacity Scheduler 可以基于全局调度优化集群的资源布局,降低热点问题的风险,最大限度地利用集群资源。Capacity Scheduler 还支持节点标签、节点属性和放置约束等计划功能。
FIFO Scheduler(先进先出调度器)
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最先进入的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。下图展示FIFO的调度模式。
调度策略
整个集群作为单一队列,严格按任务提交顺序执行。FIFO是唯一调度策略。
优点
1、简单易用:无需复杂配置,适合快速部署和测试环境;所有应用按提交顺序分配资源,逻辑直观。
2、低开销:无队列管理、抢占检查等额外计算,调度速度快。
3、适合单任务场景:在单一任务独占集群或小规模环境中表现稳定。
缺点
1、资源利用率低:
- 大任务可能长时间占用资源,导致后续任务阻塞(资源饥饿问题)。
- 小作业在大作业后提交时,响应时间被大幅延长,甚至长期处于饥饿状态,无法平等共享集群资源。
- 无法动态调整分配策略,资源空闲时也无法高效利用。
2、缺乏多租户支持:无队列概念,所有应用共享单一队列,无法隔离不同团队或项目的资源。
3、优先级与抢占机制缺失:
- 不支持优先级抢占:低优先级作业一旦占用资源,即使高优先级作业到达也无法抢占资源,导致关键任务被阻塞。
- 资源分配后无法回收,无法满足动态调整需求(如紧急任务处理)。
4、作业需求差异化处理不足:未考虑作业规模、优先级或 SLA(服务等级协议)差异,导致小作业执行效率低下。
Fair Scheduler(公平调度器)
Fair Scheduler提供了Yarn应用程序公平地共享大型集群中资源的另一种形式。使所有应用在平均情况下随着时间的流式可以获得相等的资源份额。设计目标是为所有的应用分配公平的资源(对公平的定义通过参数来设置)。可以在多个丢列建工作,允许资源共享和抢占。
Fair Scheduler的基本思想是:不需要为组或队列预留一定量的内容。调度器在集群中的所有正在运行的作业之间动态分配可用资源。当大型作业首先启动,并且恰好是运行的唯一作业时,默认情况下将使用所有集群的资源(除非指定了最大资源限制)。随后,当第二个作业启动时,它被分配大约一半的总集群资源(默认情况下),现在两个作业在相同的基础上共享集群资源。
公平调度器的默认配置下:如果目前一个队列中有4个job正在运行,此时来了第5个job,这5个job共同平分整个队列的资源。
调度策略
- 多队列公平共享:动态平衡资源分配,无需预定义比例,按权重或公平份额分配资源
- 可配置调度策略:FIFO、Fair(默认)、DRF
Fair调度器是在选择队列和应用时都是按照某种公平算法来选择的。一种是最大最小公平算法,衡量的指标是内存资源。另一种是主资源公平算法,基于最大最小公平算法,衡量的指标是最主要的资源,可能是内存可能是 CPU 等。下面分别介绍下这两种算法。
a. Fair策略(最大最小公平算法)
在一个资源分配系统中,有多个用户请求分配资源,普通公平算法的策略是将总资源数除以用户数,每个用户获得一样的平均值数个资源。这样会出现个问题,有的用户资源需求数小于分配到的资源数,多出来的资源会被浪费,从而会使资源未得到满足的用户更加无法被满足,有的用户资源请求可以被满足确没得到满足。最大最小公平算法就是为了解决这个问题,主要目标是最大化未被满足资源需求的用户最小获得的资源数。
示例:有 5 个用户分别有 2,4,6,8,10 的资源需求,分配系统中资源总量为 20。第一轮分配将 20/5 = 4 的资源分配给各个用户,此时各个用户得到的资源数分别为 4,4,4,4,4。第一个用户资源需求为 2,多出了 2 个资源,这时候进行第二轮资源分配,将 2/4=0.5 均分给剩余的用户,此时所有用户拥有资源数为 2,4.5,4.5,4.5,4.5。第二个用户需要 4 个资源,获得的资源量超出了 0.5。此时进行第三轮分配,将 0.5/3=0.1666 均分给最后三个用户,此时分配结果为 2,4,4.666,4.666,4.666。第三个用户的资源需求数为 6,而他分配到的资源数为 4.666,小于需求数,分配结束。最终用户得到资源数分别为 2,4,4.666,4.666,4.666。
b. DRF策略(主资源公平算法)
在一个资源分配系统中,可能有多种类型的资源,用户一次资源请求中包括多种资源。这个时候需要选择出一个最主要的资源作为衡量标准。可以将用户已拥有的各个资源占分配系统总资源比例值最大的那个资源作为主资源。
示例:分配系统中总资源为<CPU 10G, VCores 12> ,用户1当前拥有资源为<CPU 2G,VCores 2>,用户2当前拥有的资源为<CPU 2G, VCores 4>。
通过计算可得,用户1的CPU资源占比为2/10 = 1/5,VCores 资源占比为 2/12 = 1/6,所以用户 1 的主资源为 CPU。
用户 2 的 CPU 资源占比为 2/10 = 1/5,用户 2 的 VCores 资源占比为4/12 = 1/3,所以用户2的主资源为VCores。
在下轮资源分配请求中,因为用户1的主资源占比1/5小于用户2的主资源占比1/3,故先进行用户 1 的资源请求分配。
资源抢占
- 触发条件:某队列的资源使用量低于其公平份额(如最小资源保证);高优先级应用需要资源。
- 抢占目标选择:从超出公平份额的队列中抢占资源,优先选择低优先级应用、资源超额最多的应用、短任务(最小化损失)。
优点
1、资源公平共享:在每个队列中,Fair调度器可选择按照 FIFO、Fair 或 DRF 策略为应用程序分配资源,其中 Fair 策略是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。
2、分层队列:队列可以按层次结构排列以划分资源,并可以配置权重以按特定比例共享集群
3、基于用户或组的队列映射:可以根据提交任务的用户名或组来分配队列。如果任务指定了一个队列,则在该队列中提交任务
4、资源抢占:根据应用的配置,抢占和分配资源可以是友好的或者强制的。默认不启用资源抢占
5、保证最小配额:可以设置队列最小资源,允许将保证的最小份额分配给队列,保证用户可以启动任务。当队列不能满足最小资源时,可以从其他队列抢占。当队列资源使用不完时,可以给其他队列使用。这对于确保某些用户、组或者生产应用使用获得足够的资源
6、允许资源共享:即当一个应用运行时,如果其他队列没有任务执行,则可以使用其他队列。当其他队列有应用需要资源时再将占用的队列释放出来。所有的应用都从资源队列中分配资源。
7、任务负载均衡:Fair Scheduler 提供了一个基于任务数目的负载均衡机制,该进制尽可能的将系统中的任务均匀的分配到集群的各个节点上,同时也支持用户根据自身需要设计新的负载均衡机制。
缺点
1、资源隔离较弱:队列间仅通过权重分配资源,无法严格保证最小资源,可能影响关键任务稳定性。
2、配置复杂度中等:需维护策略文件定义队列结构和权重,但比 Capacity Scheduler 简单。
3、不适合严格隔离场景:多租户环境中,若需强隔离(如金融、生产环境),可能不如 Capacity Scheduler 可靠
Capacity Scheduler(容量调度器)
Capacity Scheduler允许多个组织共享整个集群资源,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务。
Capacity Scheduler的基本思想是:使用专用队列分配作业。每个队列具有分配给它的预定量的资源。但是,由于要保证队列资源的容量,因此可以根据集群的资源利用率来对容量进行设置。目标是使组织的多个租户(用户)以可预测的方式共享Hadoop集群的资源,Hadoop使用作业队列来实现这一目标。客户端通过将作业分配到特定的命名队列来调度作业,队列是一个Hadoop作业的有序列表,一个接一个地顺序执行。
调度策略
- 多队列资源预留:通过预定义容量比例保证队列的资源下限,预先为每个队列设定容量比例,支持多租户资源隔离。
- 可配置的调度策略:FIFO(默认)、DRF
资源抢占
- 触发条件:某队列的资源使用量低于其保证容量;集群无空闲资源,且其他队列资源使用超出其容量上限。
- 抢占目标选择:从超出容量上限的队列中抢占资源,优先选择低优先级应用的容器、运行时间较长的任务(减少短任务被抢占的损失)。
优点
1、层次化的队列设计:所有子队列可以使用父队列的全部资源,每个子队列又可以设置单独的资源限制,通过这种层次化队列结构,更能合理利用限制集群资源。
2、容量保证:每个队列都会设置一个资源容量百分比值,这个比值的资源是队列可以保证得到的资源。这样通过每个队列资源占比,能够限制资源不会被独占。
3、安全:每个队列有严格的访问控制。用户只能向自己的队列里提交任务,而且不能修改或访问其他队列的任务
4、资源弹性分配:空闲的资源可以被分配给任何队列;当多个队列出现争用的时候,则按照权重比例进行平衡
5、多用户共享:多个用户通过队列共享整个集群资源,同时每个用户都能占有一定受保证的资源,尽最大可能满足所有用户需求,充分发挥集群能力,提高资源利用率。
缺点
1、配置复杂:需定义队列层级、容量、抢占策略等参数,管理成本高。
2、资源分配不够灵活:依赖静态队列配置,动态调整队列容量需手动干预,不适合频繁变化的负载。
3、公平性有限:在同一队列内默认使用FIFO策略,但跨队列资源分配仍以容量为核心,可能无法满足全局公平性需求。
对比总结
| 特性 | FIFO 调度器 | Fair 调度器 | Capacity 调度器 |
| 核心目标 | 简单任务顺序执行 | 资源公平共享与动态平衡 | 多租户资源隔离与容量保证 |
| 资源分配策略 | 整个集群作为单一队列,严格按任务提交顺序分配资源 | 集群资源按队列权重动态分配 | 集群划分为多个队列,预定义容量比例 |
| 多队列支持 | 仅单队列 | 支持多级队列,队列间资源按权重共享 | 支持多级队列,队列间资源隔离 |
| 资源隔离性 | 无隔离,大任务可能阻塞所有后续任务 | 弱隔离,队列间资源弹性共享,仅通过权重和最大资源限制约束 | 强隔离,队列资源上限防止超额占用 |
| 任务执行顺序 | 严格按提交顺序(FIFO) | 队列内默认Fair | 队列内默认FIFO |
| 抢占机制 | 不支持 | 队列间/队列内抢占:基于公平份额或优先级回收资源 | 队列间抢占:回收超容量队列的资源,保证容量下限 |
| 资源利用率 | 低:大任务独占资源时,小任务需长时间等待 | 高:资源按需动态分配,空闲资源按权重抢占。 | 中等:队列空闲资源可被其他队列借用,但容量上限限制弹性。 |
| 配置复杂度 | 极简(无需配置队列或策略) | 中等(需定义队列权重和公平性规则) | 较高(需预定义队列容量比例和层级结构) |
| 适用场景 | 测试环境、小规模集群或无需资源隔离的场景 | 混合负载环境需灵活资源共享的场景(如临时任务与长任务共存) | 生产环境需严格资源隔离的场景(如多部门/项目独立队列) |
 登录后可评论
登录后可评论








.jpg)



