Quark 基础参数大全系列一 | 基础篇及执行相关参数
前言
参数概览
Quark 服务是 ArgoDB 的 SQL 查询引擎,服务的配置参数一般存放于节点 /etc/quark1/conf/hive-site.xml 中,主要包含以下常用参数:
a) 执行相关参数
- Map/Reduce 任务数量控制
- 动态分区
- 执行优化
- 数据稽查
- JOIN 相关
- Stargate 相关
- PL/SQL 相关
- TDDMS 相关
b) 运维管理相关参数
c) 编译相关参数
d) 存储相关参数
e) 分布式事务相关参数
f) 资源调度相关参数
由于篇幅原因,本篇主要为读者介绍执行相关参数,有关运维管理、编译、存储、分布式事务以及资源调度相关参数请参考系列文章。
配置方式
Quark 服务的参数配置及查看,分别有以下两种方式:
- Manager 平台对服务 Quark 进行界面化的配置:作用于整个 Quark Server。
- 通过 Beeline 连接 Quark 后通过命令行进行配置:只作用于当前 session。
命令行会话级配置
1. 选择任意连接方式连接 Quark,此处以 Beeline 方式为例(更多连接方法请参考《Transwarp ArgoDB 开发者指南》的连接数据库章节):
beeline -u jdbc:hive2://<ip>:<port> -n admin -p admin- <ip>:Quark Server 所在节点的 IP 地址。
- <port>:Quark 服务中参数 hive.server2.thrift.port 的值,默认为 10000。
2. 修改参数配置:
set <para_name> = <para_value>;- <para_name>:参数名称。
- <para_value>:配置的参数值。
界面化全局配置
1. 登录 Tranwarp Manager,进入 Quark 服务配置界面。
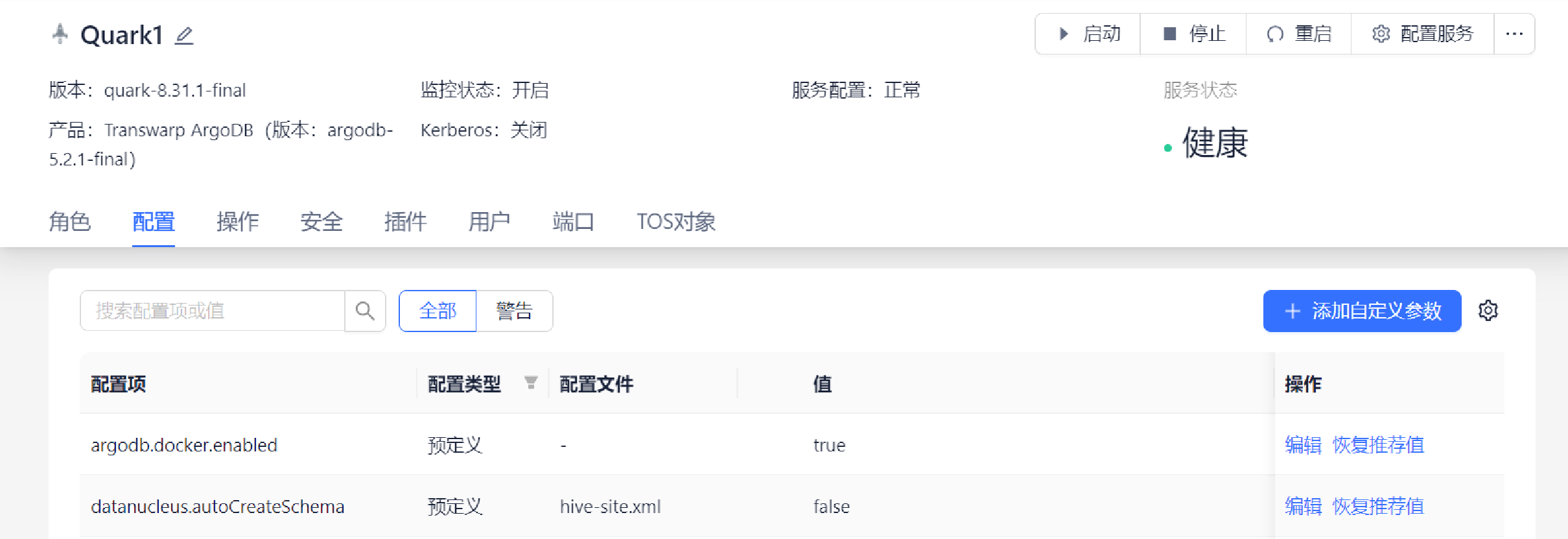
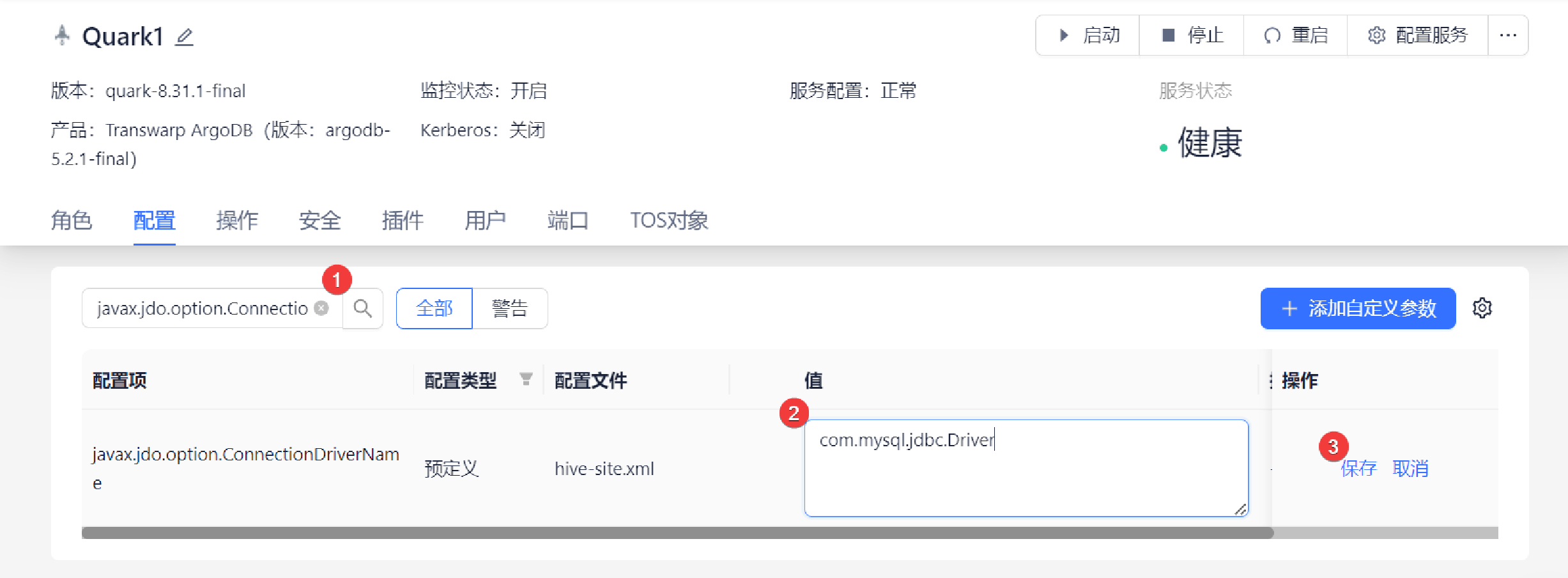
2. 配置相关参数:搜索框中搜索需要配置的参数,点击右侧编辑,在编辑狂中进行修改,完成后点击保存。
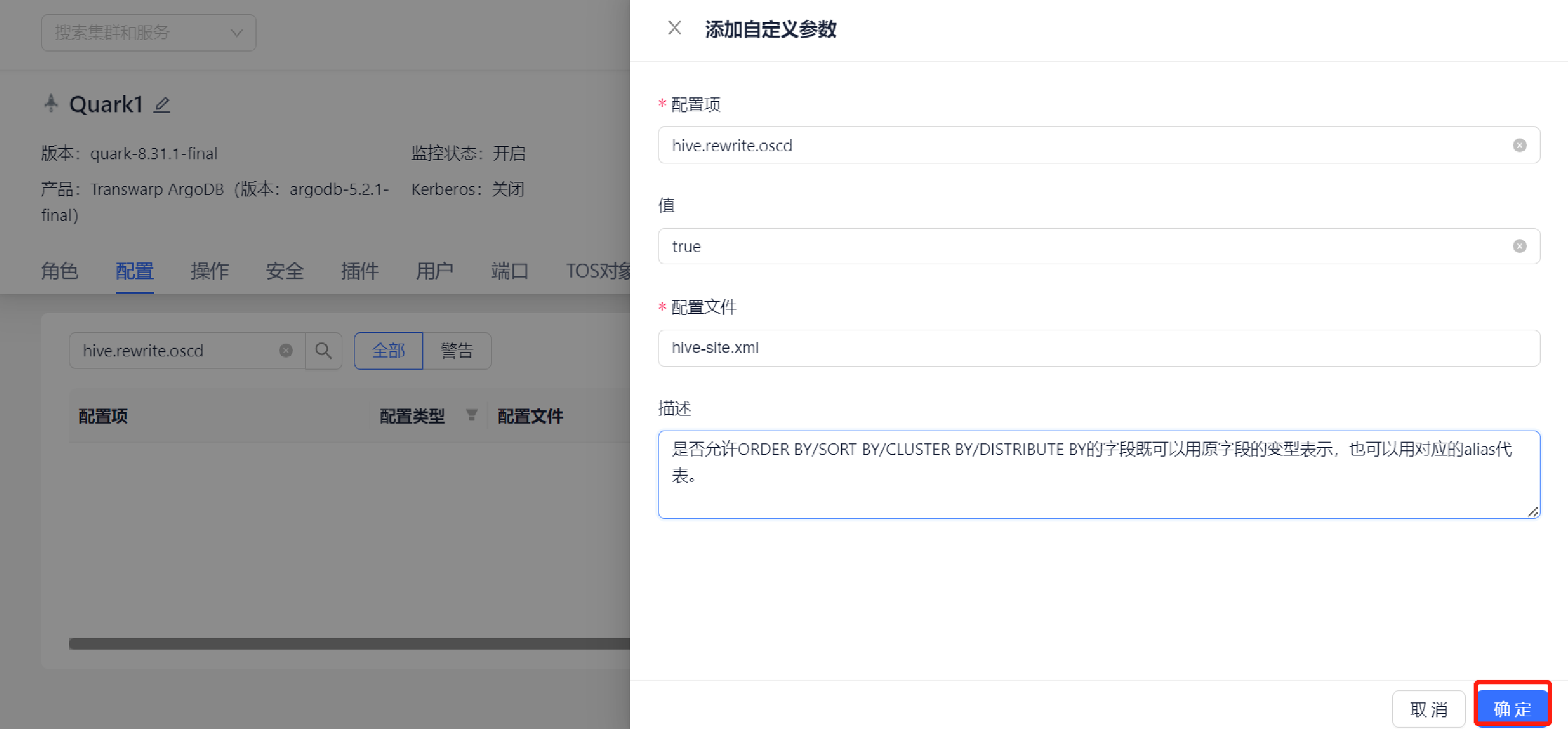
3. 自定义参数:若需要配置的参数不存在,可以点击 + 添加自定义参数,在弹出页面中输入参数名称、取值、配置文件及参数说明,其中 ***** 表示必填字段。
4. 点击服务菜单右上角配置服务下发配置,然后重启该服务使配置生效。

Hint Query 级配置
ArgoDB 6.0 提供语法,支持在执行 SQL 语句时,通过添加 Hint 的方式进行 Query 级别的参数配置
配置语法
INSERT/CREATE/SELECT/UPDATE/DELETE/MERGE /*+ env_set(<para_name>=<para_value>,<para_name>=<para_value>,...) , <other_hint>() */
- 当需要同时设置多个参数时,在 env_set() 中使用英文逗号 , 隔开,如:/*+env_set(a=1, b=2, c=3)*/
- 当需要添加其他 Hint 时,如 MAPJOIN,则在 Hint 内使用英文逗号 , 隔开,如:/*+env_set(a=1, b=2, c=3), mapjoin(table_A)*/
或使用两个 Hint 分来来写,如:/*+env_set(a=1, b=2, c=3)*/ /*+mapjoin(table_A)*/
查看参数信息
在使用 Beeline 连接 ArgoDB 数据库后,我们提供以下 SQL 命令查看参数基本信息:
- 查看参数信息,包括默认值、数据类型、描述
show conf '<para_name>';- 查看参数当前值:
set <para_name>;其中 <para_name> 表示参数名称。
执行相关参数
Quark 服务中执行相关的参数主要包含以下方面:
- Map/Reduce 任务数量控制
- 动态分区
- 执行优化
- 数据稽查
- JOIN 相关
- Stargate 相关
- PL/SQL 相关
- TDDMS 相关
Map/Reduce 任务数量控制
mapred.reduce.tasks
参数说明:
- 设置 Reduce Tasks 的数量,该参数对性能调优有极大帮助。
- 通常情况下,没有涉及分桶时,Reduce 的数量推荐根据业务的数据量分配,启动和初始化 Rreduce 会消耗资源,且数量太多可能会导致小文件过多。
默认值: -1
取值范围: 自定义 INT 型的质数,且不等于 31 及其倍数。
ngmr.partition.automerge
参数说明:
- Automerge 的控制开关,用于减少小文件数量从而控制 Map Tasks 的数量。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
ngmr.partition.mergesize
参数说明:
- 当 Automerge 开关 ngmr.partition.automerge=true 后,此参数用于控制将多少 Partitions Merge 在一起。
默认值: 3
取值范围: 自定义 INT 型。
注意事项: 高危参数,请用户尽量不要改变默认设置。
ngmr.partition.mergesize.mb
参数说明:
- 当 Automerge 开关 ngmr.partition.automerge=true 后,此参数用于控制 Merge 的数据量总和的上限(单位:MBytes)。为 -1 时表示忽略此限制。
默认值: 8
取值范围: 自定义 INT 型。
注意事项: 高危参数,请用户尽量不要改变默认设置。
动态分区
hive.exec.dynamic.partition
参数说明:
- 是否允许不指定分区,动态插入分区数据。
默认值: true
取值范围: true、false
hive.exec.dynamic.partition.mode
参数说明:
- 选择动态分区的处理模式。
- 在 strict 模式下,用户必须至少指定一个静态分区以防止无意间 overwrite 所有分区。
- 在 nonstrict 模式下,所有分区都可以为动态。
默认值: nonstrict
取值范围: strict、nonstrict
argodb.dynamic.create.partition.enabled
参数说明:
- 动态插入分区数据,而分区列对应的分区不存在时,是否自动创新新的分区。
默认值: false
取值范围: true、false
argodb.max.partition.size
参数说明:
- 最多允许动态创建多少分区。
默认值: 100
取值范围: 自定义 INT 型。
hive.crud.dynamic.partition
参数说明:
- 是否对单值分区表支持基于动态分区的 crud。
- 为 true 时,可以以单值分区表整表为单位作为 insert/update/delete/merge into 的目标。
- 为 false 时,仅能以单值分区表的指定分区为 crud 的目标。
默认值: false
取值范围: true、false
hive.optimize.dynamic.partition.insert
参数说明:
控制是否自动对动态分区插入语句进行优化改写。默认为 true,表示开启此功能。
默认值: true
取值范围: true、false
注意事项: 使用此开关的前提,需要设置以下参数:
- hive.enforce.bucketing=true
- hive.crud.dynamic.partition=true
- hive.exec.dynamic.partition.mode=nonstrict
hive.optimize.dynamic.partition.insert.cluster.by.random
参数说明:
- 设置对分区非分桶表进行动态分区插入时,是否使用随机个数的 reduce task。
- 默认为 false,表示最后会用 1 个 reduce task 进行插入。
默认值: false
取值范围: true、false
执行优化
hive.window.spill.size
参数说明:
- 一个窗口计算聚合函数时最多允许内存存放多少条记录。如果超出该数值,多余记录会spill至磁盘。如果窗口数量比较多,需要把这个参数设小来降低内存压力以提高稳定性。如果窗口数量少,可以调大这个参数提高性能。
默认值: 10000
取值范围: 自定义 INT 型。
hive.winfunc.predicate.pushdown
参数说明:
- 是否对窗口函数采用谓词前推的优化。
默认值: true
取值范围: true、false
hive.enforce.sorting
参数说明:
- 分桶内部是否默认强制排序。
默认值: false
取值范围: true、false
inceptor.optimizer.on
参数说明:
- 顶级的优化开关,包含常用的开关如向量化优化、最大最小值优化等。
默认值: false
取值范围: true、false
ngmr.reader.minmaxfilter
参数说明:
- 适用于列式存储的表,如果查询有过滤条件并且数据块具有最大最小值的统计信息,每次带过滤条件的扫描首先会计算该过滤条件是否满足数据块的最大最小值范围,若不满足就跳过该块,从而节省 IO 成本。本参数为 inceptor.optimizer.on 的子开关。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
ngmr.reader.rowfilter
参数说明:
- 优化开关 inceptor.optimizer.on=true 后如果表有过滤条件,就先读取过滤条件的字段并计算 filter,若满足条件就去读取其他字段,否则检查下一行。适用于超宽表扫描。本参数为 inceptor.optimizer.on 的子开关。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
hive.udf.codegen
参数说明:
- 作用于 UDF 代码生成过程的优化开关,可用于加速表达式求值。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
inceptor.throw.zero.divisor.exception
参数说明:
- 控制当 UDF 发生除零计算时是否报错,为 true 表示报错。
默认值: false
取值范围: true、false
inceptor.select.distinct.group.by.enabled
参数说明:
- 是否支持 select distinct + UDAF 语句。
默认值: true
取值范围: true、false
inceptor.skip.optimizer
参数说明:
- 是否放弃使用 SQL 优化器。
- 适用于 Hyperbase 中工作负载存在大量并发执行的简单 SQL 语句,降低编译成本。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
hive.optimize.readcolumn
参数说明:
- 是否采用优化方法访问字段。
- 当在 Hyperbase 中执行形如 “select count(*) where xx is null” 的语句时,请关闭该开关。
默认值: true
取值范围: true、false
hive.window.iterator.directly
参数说明:
- 是否对窗口函数迭代器的性能进行优化。目前支持优化 ROW_NUMBER、RANK、CSUM 这三种窗口函数。
默认值: false
取值范围: true、false
ngmr.dd.local.mode.auto
参数说明:
- 是否自动使用 local mode 来查询数据字典表(system中的所有表)。默认使用 local mode。
默认值: true
取值范围: true、false
hive.decimal.wrdecimal.enabled
参数说明:
- 是否使用星环科技自身的 WRDecimal 实现 Decimal 类型。
- WRDecimal 是基于 HiveDecimal 的 Decimal 实现方式,解决了 HiveDecimal 在处理 Decimal 类型时的一些问题的限制。
默认值: true
取值范围: true、false
注意事项: 如果需要修改本参数,请在所有**节点的配置文件 hive-site.xml 中配置,并且重启 Quark 后才会生效。
hive.max.partition.locks.per.table
参数说明:
- 用于控制 SELECT \* FROM table WHERE <condition> 这类 SQL 语句在执行时是否对全表加锁。
- 当 condition 中涉及到的分区数小于等于此阈值时,仅对分区加锁,不影响其他分区的事务操作,以优化系统性能;超过此阈值时,对全表加锁。
- 当此参数设置为 0 时,表示 SELECT \* FROM table WHERE condition 这类查询均对全表加锁。
默认值: 3
取值范围: 自定义 INT 型。
注意事项: 此参数不建议设置过大。
partition.crud.validate.check.and.cast
参数说明:
- 用于控制 TRUNCATE TABLE table_name PARTITION (<partition_key> = <partition_value>,...) 这类语句是否对 <partition_value> 的格式进行检查并转换。
- 默认为 true,表示会自动检查 <partition_value> 的格式,如果为非标准格式,则会自动转换为标准格式,再进行查找和执行。
默认值: true
取值范围: true、false
数据稽查
inceptor.data.audit
参数说明:
- 当前 session 是否开启数据稽查功能。
- 如果设置为 true,则会做脏数据和 NOT NULL 检查,并把它们放入 error 表中。
默认值: false
取值范围: true、false
注意事项: 该开关是参数 inceptor.data.audit.statement、inceptor.strict.evaluate 和 inceptor.notnull.audit 的 Top Level 控制。
inceptor.data.audit.statement
参数说明:
- 如果设置为 true 时,在 SQL 执行结束时会输出:“N rows were wrong during query, please check the error table for details.”。
默认值: false
取值范围: true、false
注意事项: 本参数随参数 inceptor.data.audit 设为 true 时默认自动打开(值为 true)。
inceptor.strict.evaluate
参数说明:
用来控制是否在遇到脏数据时报 Exception。如果已知 Table 中有脏数据建议关闭该开关(值为 false)。
默认值: false
取值范围: true、false
注意事项: 本参数随参数 inceptor.data.audit 设为 true 时默认自动打开(值为 true)。
inceptor.notnull.audit
参数说明:
- 是否对 NOT NULL constraint 进行检查。
- 本参数设为 true 后,对于有 NOT NULL 限制的字段,如果发现有 NULL 值则该记录写入 Error Table。
默认值: false
取值范围: true、false
注意事项: 本参数随参数 inceptor.data.audit 设为 true 时默认自动打开(值为 true)。
inceptor.insert.type.conversion
参数说明:
- 在 INSERT 数据时,是否依照 TableSchema 定义的字段类型自动进行类型转换。
默认值: true
取值范围: true、false
JOIN 相关
ngmr.mapjoin.autoconvert
参数说明:
- 是否将满足 MapJoin 条件的 JOIN 自动按 MapJoin 的方式处理。
默认值: true
取值范围: true、false
inceptor.mapjoin.filter
参数说明:
- 是否启用 MapJoin Filter 优化。
优化效果:实现 MapJoin 时,可根据维度表的运行结果在运行时动态生成事实表的过滤条件。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
inceptor.mapjoin.filter.autogen
参数说明:
- 是否对自动转化的 MapJoin 使用 mapjoin.filter 优化。
- 配合 inceptor.mapjoin.filter 开关,可以适用于 MapJoin 小表有最大值/最小值过滤机会的场景。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
hive.ignore.mapjoin.hint
参数说明:
- 是否忽略 MapJoin Hint。为 true 时表示忽略。
默认值: false
取值范围: true、false
inceptor.filterjoin.enabled
参数说明:
- 控制是否开启 FilterJoin 优化。
- FilterJoin 是基于 MapJoin 的优化,适用于语句中有多个级联 MapJoin 的场景,加快这类语句的执行速度。
默认值: true
取值范围: true、false
inceptor.filterjoin.pushdown.filter.enabled
参数说明:
- 是否在级联 Join 中下推小表过滤条件作为 filter。
默认值: true
取值范围: true、false
ngmr.broadcast.join
参数说明:
- Broadcast Join 的优化开关。
默认值: true
取值范围: true、false
ngmr.broadcast.parallel.smalltable.collect
参数说明:
- 执行 Broadcast Join 时是否使用并发方式广播小表。
默认值: true
取值范围: true、false
ngmr.broadcast.join.smalltable.size
参数说明:
- 允许参与 Broadcast Join 的小表的行数上限。
默认值: 100000
取值范围: 自定义 INT 型。
inceptor.maxjoincount.threshold
参数说明:
- 允许 SQL 语句中存在的最大 JOIN 个数。
默认值: 100
取值范围: 自定义 INT 型。
Stargate 相关
stargate.debug.log
参数说明:
- 是否把对 Stargate 进行 Debug 时的信息写入日志。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
stargate.advance.filter.generator
参数说明:
- 在 Stargate 中是否启用高级 Filter 生成器。
默认值: true
取值范围: true、false
stargate.dimension.enabled
参数说明:
- 是否启用 Stargate 中的 dimension 下推。
默认值: true
取值范围: true、false
stargate.orderby.pushdown
参数说明:
- Stargate 是否将能正常解析的 OrderBy 的信息下推到 Stargate 数据源表中,默认下推。
默认值: true
取值范围: true、false
stargate.limit.pushdown
参数说明:
- Stargate 是否将能正常解析的 Limit 的信息下推到 Stargate 数据源表中,默认下推。
默认值: true
取值范围: true、false
stargate.andor.filter.convert
参数说明:
- Stargate Filter 默认不解析 OR 在 AND 之下的过滤条件,例如:
WHERE col1 > 1 AND (col2 < 2 OR col3 > 3)- 本参数默认开启(true)后,Stargate 将会对该 Filter 条件进行转换并解析后下推到 Stargate 数据源表中。
默认值: true
取值范围: true、false
ngmr.stargate.filter.equal.pushdown
参数说明:
- 是否下推等值的过滤条件,如:
WHERE a=x默认值: true
取值范围: true、false
ngmr.stargate.filter.notequal.pushdown
参数说明:
- 是否下推非等值的过滤条件,如:
WHERE a != x默认值: true
取值范围: true、false
ngmr.stargate.filter.in.pushdown
参数说明:
- 是否下推 IN 条件过滤,如:
WHERE a IN (x,y)默认值: true
取值范围: true、false
ngmr.stargate.filter.notin.pushdown
参数说明:
- 是否下推 NOT IN 条件查询,如:
WHERE a NOT IN (x,y)默认值: true
取值范围: true、false
ngmr.stargate.filter.like.pushdown
参数说明:
- 是否下推 LIKE 及 RLIKE 条件查询,如:
WHERE a LIKE "x_"
WHERE a RLIKE "x*"默认值: true
取值范围: true、false
ngmr.stargate.filter.notlike.pushdown
参数说明:
- 是否下推 NOT LIKE 及 NOT RLIKE 条件查询,如:
- WHERE a not LIKE "x_"
- WHERE a not RLIKE "x*"
默认值: true
取值范围: true、false
ngmr.stargate.filter.isnull.pushdown
参数说明:
是否下推 IS NULL 条件查询,如:
WHERE a IS NULL
默认值: true
取值范围: true、false
ngmr.stargate.filter.isnotnull.pushdown
参数说明:
- 是否下推 IS NOT NULL 条件查询,如:
WHERE a IS NOT NULL默认值: true
取值范围: true、false
ngmr.stargate.filter.between.pushdown
参数说明:
- 是否下推 BETWEEN 条件查询,如:
WHERE a BETWEEN 1 AND 10默认值: true
取值范围: true、false
ngmr.stargate.filter.greaterthan.pushdown
参数说明:
- 是否下推 ">" 条件查询,如:
WHERE a > 10默认值: true
取值范围: true、false
ngmr.stargate.filter.equalorgreaterthan.pushdown
参数说明:
- 是否下推 ">=" 条件查询,如:
WHERE a >= 10默认值: true
取值范围: true、false
ngmr.stargate.filter.lessthan.pushdown
参数说明:
- 是否下推 "<" 条件查询,如:
WHERE a < 10默认值: true
取值范围: true、false
ngmr.stargate.filter.equalorlessthan.pushdown
参数说明:
- 是否下推 "<=" 条件查询,如:
WHERE a <= 10默认值: true
取值范围: true、false
ngmr.stargate.filter.range.pushdown
参数说明:
- 是否下推范围过滤相关条件查询,如:
WHERE a > 10
WHERE a >= 10
WHERE a < 10
WHERE a <= 10
WHERE a BETWEEN 10 AND 20默认值: true
取值范围: true、false
PL/SQL 相关
plsql.client.dialect
参数说明:
- 客户端采用的 PL/SQL 方言。
默认值: oracle
取值范围: oracle、db2、td
plsql.server.dialect
参数说明:
- 服务器端采用的 PL/SQL 方言。
默认值: oracle
取值范围: oracle、db2、td
plsql.show.sqlresults
参数说明:
- 在 PL/SQL 中执行 SELECT 操作时,是否打印查询结果。
默认值: false
取值范围: true、false
plsql.use.slash
参数说明:
- 是否在 PL/SQL 中支持 "/" 操作符。
默认值: false
取值范围: true、false
plsql.cache.output
参数说明:
- PL/SQL 中 PUT_LINE 有如下行为:
- 如果程序正常结束,会统一打印到终端。
- 如果程序中出现了未被处理的异常,默认在终端只打印异常栈,PUT_LINE 内容需要去 hive.log 中查看。
- 考虑到对于异常的处理方式给调试带来的不便,提供此参数,当设为 true 时可将 PUT_LINE 内容连同异常栈一起打印到终端帮助调试。
默认值: false
取值范围: true、false
注意事项: 建议仅在调试时开启,否则会带来资源压力。
plsql.catch.hive.exception
参数说明:
- 是否在 PL/SQL 中捕捉 Hive 异常。
默认值: false
取值范围: true、false
注意事项: 该变量需要在真正运行存储过程而不是创建存储过程的时候设置。
plsql.optimize.dml.precompile
参数说明:
- 是否对 PL/SQL 中的 DML 开启预编译。
默认值: false
取值范围: true、false
plsql.optimize.dml.precompile.deopt
参数说明:
- 当参数 plsql.optimize.dml.precompile=true 时,是否在预编译失败时进行退优化,即是否采用每次运行都编译的执行方式。
默认值: true
取值范围: true、false
plsql.compile.dml.check.semantic
参数说明:
- 是否在编译期对 SQL 进行语义检查,如果确认 DML 语句是正确的且遇到了编译报错,可设置为 false 临时跳过编译检查。
默认值: true
取值范围: true、false
hive.server2.idle.plsql.operation.timeout
参数说明:
- PLSQL 语句的 timeout 控制,单位毫秒。
- PL/SQL 作为控制流,可能会包含多个执行时间较长的 SQL,因此用该参数单独控制 PL/SQL 控制流的 timeout。
默认值: 0
取值范围: 自定义 STRING(TIME) 型(默认单位:毫秒),支持指定单位:d/day、h/hour、m/min、s/sec、ms/msec、us/usec, ns/nsec。
plsql.check.driver.env
参数说明:
- 是否检查 PL/SQL 有没有正运行在非 driver 环境中。
默认值: true
取值范围: true、false
注意事项: 请谨慎设为 false。
plsql.runtime.profile
参数说明:
- 是否对 PL/SQL 运行时性能进行检查。
默认值: false
取值范围: true、false
plsql.cursor.local.job.record.timeout.weight
参数说明:
- 控制 local mode 下游标的执行时间限制。
- 设置该参数后(例如 100),local mode 模式下游标的执行时间限制为参数 plsql.cursor.local.job.record.timeout.weight 和 ngmr.local.job.record.timeout.ms 的乘积,如果游标执行时间超过该乘积,那么将会被 kill 掉。
默认值: 100
取值范围: 自定义 INT 型。
TDDMS 相关
shiva.web.url
参数说明:
- TDDMS Webserver 访问地址。
默认值: http://node1:4567
取值范围:
- http://<tddms_webserver>:<port>
- <tddms_webserver>:TDDMS Webserver 角色所在节点 IP 地址
- <port>:TDDMS 服务参数 http.port 的取值,默认为 4567.
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.enabled
参数说明:
- 是否启用 shiva2,此处指使用 TDDMS 管理数据,用于替换旧版本的 Shiva 组件。
默认值: true
取值范围: true、false
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.default.nameservice
参数说明:
- Quark 服务默认使用的 TDDMS 服务名称标识。
默认值: tddms1
取值范围: TDDMS 服务 ID 名称
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.mastergroup
参数说明:
- Quark 依赖的 TDDMS 服务对应的 MasterGroup 信息,用英文逗号“,”隔开。MasterGroup 信息可以进入对应各 TDDMS 的 TDDMS Webserver 中的 Master 界面中进行查看,如 tx-node8:19630,tx-node7:19630,tx-node5:19630。
默认值: 无
取值范围: [MasterGroup]
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.nameservices
参数说明:
- Quark 依赖的 TDDMS 服务名称标识。开启多 TDDMS 模式后,多个 TDDMS 名称用英文逗号“,”间隔。
默认值: 无
取值范围: TDDMS 服务 ID 名称
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
quark.multiple.tddms.mode.enable
参数说明:
- 是否启用多 TDDMS 模式。启用后才能配置依赖多个 TDDMS,否则报错。
默认值: false
取值范围: true、false
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.mastergroup.XXX
参数说明:
- “XXX”是在参数 ngmr.tddms2.nameservices 中自定义的 TDDMS 服务名称。
- 当开启多 TDDMS 模式时,可以有多个不同取值的参数,如 ngmr.tddms2.mastergroup.tddms1、ngmr.tddms2.mastergroup.tddms2 等。
- 当关闭多 TDDMS 模式时,本参数默认为 ngmr.tddms2.mastergroup.tddms1,且取值与 ngmr.tddms2.mastergroup 保持一致。
- 本参数为 Quark 对接的 TDDMS 服务“XXX”对应的 MasterGroup 信息,用英文逗号“,”隔开。MasterGroup 信息可以进入对应各 TDDMS 的 TDDMS Webserver 中的 Master 界面中进行查看,如 tx-node8:19630,tx-node7:19630,tx-node5:19630。
默认值: 无
取值范围: [MasterGroup]
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.user.XXX
参数说明:
- TDDMS 服务“XXX”对应的客户端的请求的用户名。
默认值: shiva
取值范围: 字符串
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.password.XXX
参数说明:
- TDDMS 服务“XXX”对应的客户端的请求的密码
默认值: shiva
取值范围: 字符串
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
前言
参数概览
Quark 服务是 ArgoDB 的 SQL 查询引擎,服务的配置参数一般存放于节点 /etc/quark1/conf/hive-site.xml 中,主要包含以下常用参数:
a) 执行相关参数
- Map/Reduce 任务数量控制
- 动态分区
- 执行优化
- 数据稽查
- JOIN 相关
- Stargate 相关
- PL/SQL 相关
- TDDMS 相关
b) 运维管理相关参数
c) 编译相关参数
d) 存储相关参数
e) 分布式事务相关参数
f) 资源调度相关参数
由于篇幅原因,本篇主要为读者介绍执行相关参数,有关运维管理、编译、存储、分布式事务以及资源调度相关参数请参考系列文章。
配置方式
Quark 服务的参数配置及查看,分别有以下两种方式:
- Manager 平台对服务 Quark 进行界面化的配置:作用于整个 Quark Server。
- 通过 Beeline 连接 Quark 后通过命令行进行配置:只作用于当前 session。
命令行会话级配置
1. 选择任意连接方式连接 Quark,此处以 Beeline 方式为例(更多连接方法请参考《Transwarp ArgoDB 开发者指南》的连接数据库章节):
beeline -u jdbc:hive2://<ip>:<port> -n admin -p admin- <ip>:Quark Server 所在节点的 IP 地址。
- <port>:Quark 服务中参数 hive.server2.thrift.port 的值,默认为 10000。
2. 修改参数配置:
set <para_name> = <para_value>;- <para_name>:参数名称。
- <para_value>:配置的参数值。
界面化全局配置
1. 登录 Tranwarp Manager,进入 Quark 服务配置界面。
2. 配置相关参数:搜索框中搜索需要配置的参数,点击右侧编辑,在编辑狂中进行修改,完成后点击保存。
3. 自定义参数:若需要配置的参数不存在,可以点击 + 添加自定义参数,在弹出页面中输入参数名称、取值、配置文件及参数说明,其中 ***** 表示必填字段。
4. 点击服务菜单右上角配置服务下发配置,然后重启该服务使配置生效。
Hint Query 级配置
ArgoDB 6.0 提供语法,支持在执行 SQL 语句时,通过添加 Hint 的方式进行 Query 级别的参数配置
配置语法
INSERT/CREATE/SELECT/UPDATE/DELETE/MERGE /*+ env_set(<para_name>=<para_value>,<para_name>=<para_value>,...) , <other_hint>() */
- 当需要同时设置多个参数时,在 env_set() 中使用英文逗号 , 隔开,如:/*+env_set(a=1, b=2, c=3)*/
- 当需要添加其他 Hint 时,如 MAPJOIN,则在 Hint 内使用英文逗号 , 隔开,如:/*+env_set(a=1, b=2, c=3), mapjoin(table_A)*/
或使用两个 Hint 分来来写,如:/*+env_set(a=1, b=2, c=3)*/ /*+mapjoin(table_A)*/
查看参数信息
在使用 Beeline 连接 ArgoDB 数据库后,我们提供以下 SQL 命令查看参数基本信息:
- 查看参数信息,包括默认值、数据类型、描述
show conf '<para_name>';- 查看参数当前值:
set <para_name>;其中 <para_name> 表示参数名称。
执行相关参数
Quark 服务中执行相关的参数主要包含以下方面:
- Map/Reduce 任务数量控制
- 动态分区
- 执行优化
- 数据稽查
- JOIN 相关
- Stargate 相关
- PL/SQL 相关
- TDDMS 相关
Map/Reduce 任务数量控制
mapred.reduce.tasks
参数说明:
- 设置 Reduce Tasks 的数量,该参数对性能调优有极大帮助。
- 通常情况下,没有涉及分桶时,Reduce 的数量推荐根据业务的数据量分配,启动和初始化 Rreduce 会消耗资源,且数量太多可能会导致小文件过多。
默认值: -1
取值范围: 自定义 INT 型的质数,且不等于 31 及其倍数。
ngmr.partition.automerge
参数说明:
- Automerge 的控制开关,用于减少小文件数量从而控制 Map Tasks 的数量。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
ngmr.partition.mergesize
参数说明:
- 当 Automerge 开关 ngmr.partition.automerge=true 后,此参数用于控制将多少 Partitions Merge 在一起。
默认值: 3
取值范围: 自定义 INT 型。
注意事项: 高危参数,请用户尽量不要改变默认设置。
ngmr.partition.mergesize.mb
参数说明:
- 当 Automerge 开关 ngmr.partition.automerge=true 后,此参数用于控制 Merge 的数据量总和的上限(单位:MBytes)。为 -1 时表示忽略此限制。
默认值: 8
取值范围: 自定义 INT 型。
注意事项: 高危参数,请用户尽量不要改变默认设置。
动态分区
hive.exec.dynamic.partition
参数说明:
- 是否允许不指定分区,动态插入分区数据。
默认值: true
取值范围: true、false
hive.exec.dynamic.partition.mode
参数说明:
- 选择动态分区的处理模式。
- 在 strict 模式下,用户必须至少指定一个静态分区以防止无意间 overwrite 所有分区。
- 在 nonstrict 模式下,所有分区都可以为动态。
默认值: nonstrict
取值范围: strict、nonstrict
argodb.dynamic.create.partition.enabled
参数说明:
- 动态插入分区数据,而分区列对应的分区不存在时,是否自动创新新的分区。
默认值: false
取值范围: true、false
argodb.max.partition.size
参数说明:
- 最多允许动态创建多少分区。
默认值: 100
取值范围: 自定义 INT 型。
hive.crud.dynamic.partition
参数说明:
- 是否对单值分区表支持基于动态分区的 crud。
- 为 true 时,可以以单值分区表整表为单位作为 insert/update/delete/merge into 的目标。
- 为 false 时,仅能以单值分区表的指定分区为 crud 的目标。
默认值: false
取值范围: true、false
hive.optimize.dynamic.partition.insert
参数说明:
控制是否自动对动态分区插入语句进行优化改写。默认为 true,表示开启此功能。
默认值: true
取值范围: true、false
注意事项: 使用此开关的前提,需要设置以下参数:
- hive.enforce.bucketing=true
- hive.crud.dynamic.partition=true
- hive.exec.dynamic.partition.mode=nonstrict
hive.optimize.dynamic.partition.insert.cluster.by.random
参数说明:
- 设置对分区非分桶表进行动态分区插入时,是否使用随机个数的 reduce task。
- 默认为 false,表示最后会用 1 个 reduce task 进行插入。
默认值: false
取值范围: true、false
执行优化
hive.window.spill.size
参数说明:
- 一个窗口计算聚合函数时最多允许内存存放多少条记录。如果超出该数值,多余记录会spill至磁盘。如果窗口数量比较多,需要把这个参数设小来降低内存压力以提高稳定性。如果窗口数量少,可以调大这个参数提高性能。
默认值: 10000
取值范围: 自定义 INT 型。
hive.winfunc.predicate.pushdown
参数说明:
- 是否对窗口函数采用谓词前推的优化。
默认值: true
取值范围: true、false
hive.enforce.sorting
参数说明:
- 分桶内部是否默认强制排序。
默认值: false
取值范围: true、false
inceptor.optimizer.on
参数说明:
- 顶级的优化开关,包含常用的开关如向量化优化、最大最小值优化等。
默认值: false
取值范围: true、false
ngmr.reader.minmaxfilter
参数说明:
- 适用于列式存储的表,如果查询有过滤条件并且数据块具有最大最小值的统计信息,每次带过滤条件的扫描首先会计算该过滤条件是否满足数据块的最大最小值范围,若不满足就跳过该块,从而节省 IO 成本。本参数为 inceptor.optimizer.on 的子开关。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
ngmr.reader.rowfilter
参数说明:
- 优化开关 inceptor.optimizer.on=true 后如果表有过滤条件,就先读取过滤条件的字段并计算 filter,若满足条件就去读取其他字段,否则检查下一行。适用于超宽表扫描。本参数为 inceptor.optimizer.on 的子开关。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
hive.udf.codegen
参数说明:
- 作用于 UDF 代码生成过程的优化开关,可用于加速表达式求值。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
inceptor.throw.zero.divisor.exception
参数说明:
- 控制当 UDF 发生除零计算时是否报错,为 true 表示报错。
默认值: false
取值范围: true、false
inceptor.select.distinct.group.by.enabled
参数说明:
- 是否支持 select distinct + UDAF 语句。
默认值: true
取值范围: true、false
inceptor.skip.optimizer
参数说明:
- 是否放弃使用 SQL 优化器。
- 适用于 Hyperbase 中工作负载存在大量并发执行的简单 SQL 语句,降低编译成本。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
hive.optimize.readcolumn
参数说明:
- 是否采用优化方法访问字段。
- 当在 Hyperbase 中执行形如 “select count(*) where xx is null” 的语句时,请关闭该开关。
默认值: true
取值范围: true、false
hive.window.iterator.directly
参数说明:
- 是否对窗口函数迭代器的性能进行优化。目前支持优化 ROW_NUMBER、RANK、CSUM 这三种窗口函数。
默认值: false
取值范围: true、false
ngmr.dd.local.mode.auto
参数说明:
- 是否自动使用 local mode 来查询数据字典表(system中的所有表)。默认使用 local mode。
默认值: true
取值范围: true、false
hive.decimal.wrdecimal.enabled
参数说明:
- 是否使用星环科技自身的 WRDecimal 实现 Decimal 类型。
- WRDecimal 是基于 HiveDecimal 的 Decimal 实现方式,解决了 HiveDecimal 在处理 Decimal 类型时的一些问题的限制。
默认值: true
取值范围: true、false
注意事项: 如果需要修改本参数,请在所有**节点的配置文件 hive-site.xml 中配置,并且重启 Quark 后才会生效。
hive.max.partition.locks.per.table
参数说明:
- 用于控制 SELECT \* FROM table WHERE <condition> 这类 SQL 语句在执行时是否对全表加锁。
- 当 condition 中涉及到的分区数小于等于此阈值时,仅对分区加锁,不影响其他分区的事务操作,以优化系统性能;超过此阈值时,对全表加锁。
- 当此参数设置为 0 时,表示 SELECT \* FROM table WHERE condition 这类查询均对全表加锁。
默认值: 3
取值范围: 自定义 INT 型。
注意事项: 此参数不建议设置过大。
partition.crud.validate.check.and.cast
参数说明:
- 用于控制 TRUNCATE TABLE table_name PARTITION (<partition_key> = <partition_value>,...) 这类语句是否对 <partition_value> 的格式进行检查并转换。
- 默认为 true,表示会自动检查 <partition_value> 的格式,如果为非标准格式,则会自动转换为标准格式,再进行查找和执行。
默认值: true
取值范围: true、false
数据稽查
inceptor.data.audit
参数说明:
- 当前 session 是否开启数据稽查功能。
- 如果设置为 true,则会做脏数据和 NOT NULL 检查,并把它们放入 error 表中。
默认值: false
取值范围: true、false
注意事项: 该开关是参数 inceptor.data.audit.statement、inceptor.strict.evaluate 和 inceptor.notnull.audit 的 Top Level 控制。
inceptor.data.audit.statement
参数说明:
- 如果设置为 true 时,在 SQL 执行结束时会输出:“N rows were wrong during query, please check the error table for details.”。
默认值: false
取值范围: true、false
注意事项: 本参数随参数 inceptor.data.audit 设为 true 时默认自动打开(值为 true)。
inceptor.strict.evaluate
参数说明:
用来控制是否在遇到脏数据时报 Exception。如果已知 Table 中有脏数据建议关闭该开关(值为 false)。
默认值: false
取值范围: true、false
注意事项: 本参数随参数 inceptor.data.audit 设为 true 时默认自动打开(值为 true)。
inceptor.notnull.audit
参数说明:
- 是否对 NOT NULL constraint 进行检查。
- 本参数设为 true 后,对于有 NOT NULL 限制的字段,如果发现有 NULL 值则该记录写入 Error Table。
默认值: false
取值范围: true、false
注意事项: 本参数随参数 inceptor.data.audit 设为 true 时默认自动打开(值为 true)。
inceptor.insert.type.conversion
参数说明:
- 在 INSERT 数据时,是否依照 TableSchema 定义的字段类型自动进行类型转换。
默认值: true
取值范围: true、false
JOIN 相关
ngmr.mapjoin.autoconvert
参数说明:
- 是否将满足 MapJoin 条件的 JOIN 自动按 MapJoin 的方式处理。
默认值: true
取值范围: true、false
inceptor.mapjoin.filter
参数说明:
- 是否启用 MapJoin Filter 优化。
优化效果:实现 MapJoin 时,可根据维度表的运行结果在运行时动态生成事实表的过滤条件。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
inceptor.mapjoin.filter.autogen
参数说明:
- 是否对自动转化的 MapJoin 使用 mapjoin.filter 优化。
- 配合 inceptor.mapjoin.filter 开关,可以适用于 MapJoin 小表有最大值/最小值过滤机会的场景。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
hive.ignore.mapjoin.hint
参数说明:
- 是否忽略 MapJoin Hint。为 true 时表示忽略。
默认值: false
取值范围: true、false
inceptor.filterjoin.enabled
参数说明:
- 控制是否开启 FilterJoin 优化。
- FilterJoin 是基于 MapJoin 的优化,适用于语句中有多个级联 MapJoin 的场景,加快这类语句的执行速度。
默认值: true
取值范围: true、false
inceptor.filterjoin.pushdown.filter.enabled
参数说明:
- 是否在级联 Join 中下推小表过滤条件作为 filter。
默认值: true
取值范围: true、false
ngmr.broadcast.join
参数说明:
- Broadcast Join 的优化开关。
默认值: true
取值范围: true、false
ngmr.broadcast.parallel.smalltable.collect
参数说明:
- 执行 Broadcast Join 时是否使用并发方式广播小表。
默认值: true
取值范围: true、false
ngmr.broadcast.join.smalltable.size
参数说明:
- 允许参与 Broadcast Join 的小表的行数上限。
默认值: 100000
取值范围: 自定义 INT 型。
inceptor.maxjoincount.threshold
参数说明:
- 允许 SQL 语句中存在的最大 JOIN 个数。
默认值: 100
取值范围: 自定义 INT 型。
Stargate 相关
stargate.debug.log
参数说明:
- 是否把对 Stargate 进行 Debug 时的信息写入日志。
默认值: false
取值范围: true、false
注意事项: 高危参数,请用户尽量不要改变默认设置。
stargate.advance.filter.generator
参数说明:
- 在 Stargate 中是否启用高级 Filter 生成器。
默认值: true
取值范围: true、false
stargate.dimension.enabled
参数说明:
- 是否启用 Stargate 中的 dimension 下推。
默认值: true
取值范围: true、false
stargate.orderby.pushdown
参数说明:
- Stargate 是否将能正常解析的 OrderBy 的信息下推到 Stargate 数据源表中,默认下推。
默认值: true
取值范围: true、false
stargate.limit.pushdown
参数说明:
- Stargate 是否将能正常解析的 Limit 的信息下推到 Stargate 数据源表中,默认下推。
默认值: true
取值范围: true、false
stargate.andor.filter.convert
参数说明:
- Stargate Filter 默认不解析 OR 在 AND 之下的过滤条件,例如:
WHERE col1 > 1 AND (col2 < 2 OR col3 > 3)- 本参数默认开启(true)后,Stargate 将会对该 Filter 条件进行转换并解析后下推到 Stargate 数据源表中。
默认值: true
取值范围: true、false
ngmr.stargate.filter.equal.pushdown
参数说明:
- 是否下推等值的过滤条件,如:
WHERE a=x默认值: true
取值范围: true、false
ngmr.stargate.filter.notequal.pushdown
参数说明:
- 是否下推非等值的过滤条件,如:
WHERE a != x默认值: true
取值范围: true、false
ngmr.stargate.filter.in.pushdown
参数说明:
- 是否下推 IN 条件过滤,如:
WHERE a IN (x,y)默认值: true
取值范围: true、false
ngmr.stargate.filter.notin.pushdown
参数说明:
- 是否下推 NOT IN 条件查询,如:
WHERE a NOT IN (x,y)默认值: true
取值范围: true、false
ngmr.stargate.filter.like.pushdown
参数说明:
- 是否下推 LIKE 及 RLIKE 条件查询,如:
WHERE a LIKE "x_"
WHERE a RLIKE "x*"默认值: true
取值范围: true、false
ngmr.stargate.filter.notlike.pushdown
参数说明:
- 是否下推 NOT LIKE 及 NOT RLIKE 条件查询,如:
- WHERE a not LIKE "x_"
- WHERE a not RLIKE "x*"
默认值: true
取值范围: true、false
ngmr.stargate.filter.isnull.pushdown
参数说明:
是否下推 IS NULL 条件查询,如:
WHERE a IS NULL
默认值: true
取值范围: true、false
ngmr.stargate.filter.isnotnull.pushdown
参数说明:
- 是否下推 IS NOT NULL 条件查询,如:
WHERE a IS NOT NULL默认值: true
取值范围: true、false
ngmr.stargate.filter.between.pushdown
参数说明:
- 是否下推 BETWEEN 条件查询,如:
WHERE a BETWEEN 1 AND 10默认值: true
取值范围: true、false
ngmr.stargate.filter.greaterthan.pushdown
参数说明:
- 是否下推 ">" 条件查询,如:
WHERE a > 10默认值: true
取值范围: true、false
ngmr.stargate.filter.equalorgreaterthan.pushdown
参数说明:
- 是否下推 ">=" 条件查询,如:
WHERE a >= 10默认值: true
取值范围: true、false
ngmr.stargate.filter.lessthan.pushdown
参数说明:
- 是否下推 "<" 条件查询,如:
WHERE a < 10默认值: true
取值范围: true、false
ngmr.stargate.filter.equalorlessthan.pushdown
参数说明:
- 是否下推 "<=" 条件查询,如:
WHERE a <= 10默认值: true
取值范围: true、false
ngmr.stargate.filter.range.pushdown
参数说明:
- 是否下推范围过滤相关条件查询,如:
WHERE a > 10
WHERE a >= 10
WHERE a < 10
WHERE a <= 10
WHERE a BETWEEN 10 AND 20默认值: true
取值范围: true、false
PL/SQL 相关
plsql.client.dialect
参数说明:
- 客户端采用的 PL/SQL 方言。
默认值: oracle
取值范围: oracle、db2、td
plsql.server.dialect
参数说明:
- 服务器端采用的 PL/SQL 方言。
默认值: oracle
取值范围: oracle、db2、td
plsql.show.sqlresults
参数说明:
- 在 PL/SQL 中执行 SELECT 操作时,是否打印查询结果。
默认值: false
取值范围: true、false
plsql.use.slash
参数说明:
- 是否在 PL/SQL 中支持 "/" 操作符。
默认值: false
取值范围: true、false
plsql.cache.output
参数说明:
- PL/SQL 中 PUT_LINE 有如下行为:
- 如果程序正常结束,会统一打印到终端。
- 如果程序中出现了未被处理的异常,默认在终端只打印异常栈,PUT_LINE 内容需要去 hive.log 中查看。
- 考虑到对于异常的处理方式给调试带来的不便,提供此参数,当设为 true 时可将 PUT_LINE 内容连同异常栈一起打印到终端帮助调试。
默认值: false
取值范围: true、false
注意事项: 建议仅在调试时开启,否则会带来资源压力。
plsql.catch.hive.exception
参数说明:
- 是否在 PL/SQL 中捕捉 Hive 异常。
默认值: false
取值范围: true、false
注意事项: 该变量需要在真正运行存储过程而不是创建存储过程的时候设置。
plsql.optimize.dml.precompile
参数说明:
- 是否对 PL/SQL 中的 DML 开启预编译。
默认值: false
取值范围: true、false
plsql.optimize.dml.precompile.deopt
参数说明:
- 当参数 plsql.optimize.dml.precompile=true 时,是否在预编译失败时进行退优化,即是否采用每次运行都编译的执行方式。
默认值: true
取值范围: true、false
plsql.compile.dml.check.semantic
参数说明:
- 是否在编译期对 SQL 进行语义检查,如果确认 DML 语句是正确的且遇到了编译报错,可设置为 false 临时跳过编译检查。
默认值: true
取值范围: true、false
hive.server2.idle.plsql.operation.timeout
参数说明:
- PLSQL 语句的 timeout 控制,单位毫秒。
- PL/SQL 作为控制流,可能会包含多个执行时间较长的 SQL,因此用该参数单独控制 PL/SQL 控制流的 timeout。
默认值: 0
取值范围: 自定义 STRING(TIME) 型(默认单位:毫秒),支持指定单位:d/day、h/hour、m/min、s/sec、ms/msec、us/usec, ns/nsec。
plsql.check.driver.env
参数说明:
- 是否检查 PL/SQL 有没有正运行在非 driver 环境中。
默认值: true
取值范围: true、false
注意事项: 请谨慎设为 false。
plsql.runtime.profile
参数说明:
- 是否对 PL/SQL 运行时性能进行检查。
默认值: false
取值范围: true、false
plsql.cursor.local.job.record.timeout.weight
参数说明:
- 控制 local mode 下游标的执行时间限制。
- 设置该参数后(例如 100),local mode 模式下游标的执行时间限制为参数 plsql.cursor.local.job.record.timeout.weight 和 ngmr.local.job.record.timeout.ms 的乘积,如果游标执行时间超过该乘积,那么将会被 kill 掉。
默认值: 100
取值范围: 自定义 INT 型。
TDDMS 相关
shiva.web.url
参数说明:
- TDDMS Webserver 访问地址。
默认值: http://node1:4567
取值范围:
- http://<tddms_webserver>:<port>
- <tddms_webserver>:TDDMS Webserver 角色所在节点 IP 地址
- <port>:TDDMS 服务参数 http.port 的取值,默认为 4567.
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.enabled
参数说明:
- 是否启用 shiva2,此处指使用 TDDMS 管理数据,用于替换旧版本的 Shiva 组件。
默认值: true
取值范围: true、false
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.default.nameservice
参数说明:
- Quark 服务默认使用的 TDDMS 服务名称标识。
默认值: tddms1
取值范围: TDDMS 服务 ID 名称
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.mastergroup
参数说明:
- Quark 依赖的 TDDMS 服务对应的 MasterGroup 信息,用英文逗号“,”隔开。MasterGroup 信息可以进入对应各 TDDMS 的 TDDMS Webserver 中的 Master 界面中进行查看,如 tx-node8:19630,tx-node7:19630,tx-node5:19630。
默认值: 无
取值范围: [MasterGroup]
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.nameservices
参数说明:
- Quark 依赖的 TDDMS 服务名称标识。开启多 TDDMS 模式后,多个 TDDMS 名称用英文逗号“,”间隔。
默认值: 无
取值范围: TDDMS 服务 ID 名称
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
quark.multiple.tddms.mode.enable
参数说明:
- 是否启用多 TDDMS 模式。启用后才能配置依赖多个 TDDMS,否则报错。
默认值: false
取值范围: true、false
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.mastergroup.XXX
参数说明:
- “XXX”是在参数 ngmr.tddms2.nameservices 中自定义的 TDDMS 服务名称。
- 当开启多 TDDMS 模式时,可以有多个不同取值的参数,如 ngmr.tddms2.mastergroup.tddms1、ngmr.tddms2.mastergroup.tddms2 等。
- 当关闭多 TDDMS 模式时,本参数默认为 ngmr.tddms2.mastergroup.tddms1,且取值与 ngmr.tddms2.mastergroup 保持一致。
- 本参数为 Quark 对接的 TDDMS 服务“XXX”对应的 MasterGroup 信息,用英文逗号“,”隔开。MasterGroup 信息可以进入对应各 TDDMS 的 TDDMS Webserver 中的 Master 界面中进行查看,如 tx-node8:19630,tx-node7:19630,tx-node5:19630。
默认值: 无
取值范围: [MasterGroup]
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.user.XXX
参数说明:
- TDDMS 服务“XXX”对应的客户端的请求的用户名。
默认值: shiva
取值范围: 字符串
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
ngmr.tddms2.password.XXX
参数说明:
- TDDMS 服务“XXX”对应的客户端的请求的密码
默认值: shiva
取值范围: 字符串
注意事项: 本参数为全局参数,只能通过 Manager 平台的 Quark 服务配置界面进行配置。
 登录后可评论
登录后可评论








.jpg)



