聊聊细粒度索引
什么是细粒度索引?
ArgoDB 中的细粒度索引是基于 KV(key-value)的索引,提供高速的 KV 服务,索引文件的 Key 存储索引键,Value 存储相同索引键的值。它类似于一种聚簇索引,可以把大量相似的数据细分成更小的边界,从而使文件的查找变得更快更有效率。
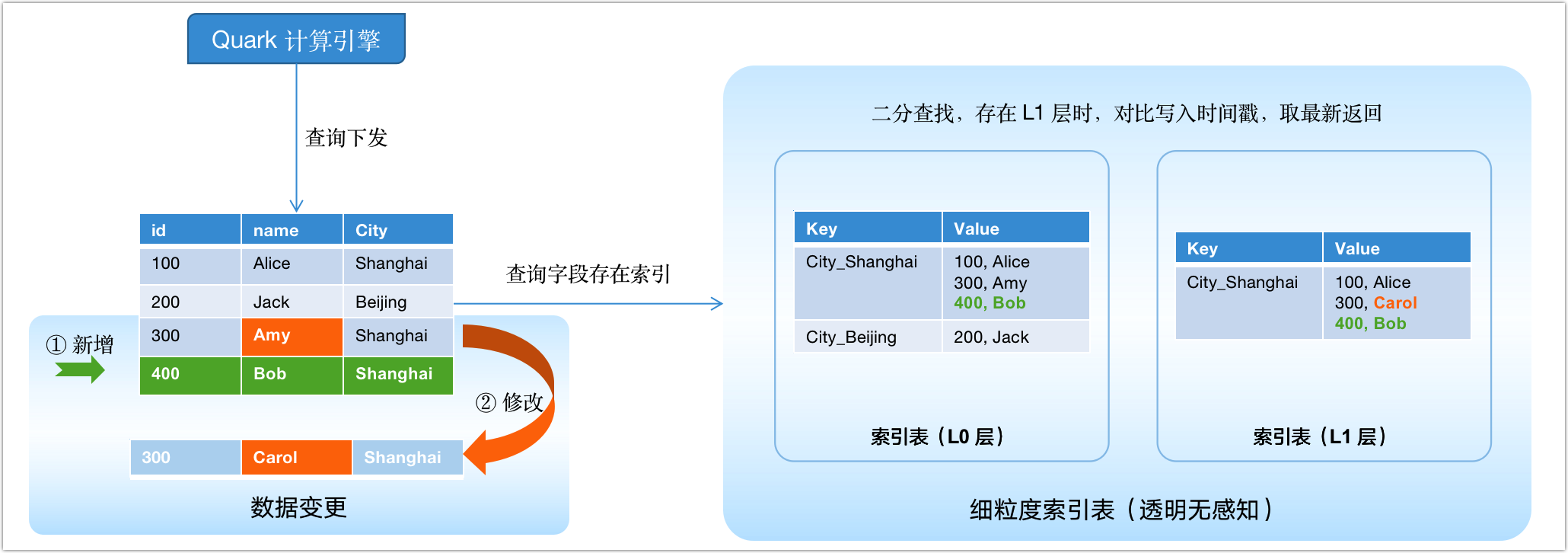
图 40. 细粒度索引实现逻辑
适用场景
因此在 ArgoDB 中使用细粒度索引,可以支持实时数仓场景下的多种诉求:
- 支持高 QPS(Queries Per Second 每秒查询数)的基于细粒度索引点查。与全表扫描相比,点查通过扫描小批量数据实现高效数据检索,例如等值查询、范围查询。
- 提高查询效率,减少查询时间,提高查询性能。细粒度索引可以把数据库中的数据分割成更小的单元,以便更快地查找和检索数据。
- 提高搜索的准确性。利用基于 KV 结构可以更精确地检索出文档中的信息。
使用说明
- 暂不支持对细粒度索引列的名称/数据类型/类型长度进行修改。
- 在源表执行数据写入、更新、删除操作时,索引表也需要进行同步的更新,所以使用索引会降低“增、删、改”的效率。
源表更新数据,同步细粒度索引的更新或重建功能,请参考后续章节中更新细粒度索引的部分。
- 索引的并发控制与源表一致,也是采用的 mvcc(multiversion concurrency control),INSERT 操作写 base 文件,DELETE/UPDATE 写 delta 文件
- 细粒度索引的分区、分片、分桶与源表有如下规律:
- 细粒度索引的分区,分片同索引对应源表的分区,分片相同;
- 但索引分桶与源表分桶无关,是按索引列分桶(目前分桶数默认 163)。
- 当源表为列存表且更新数据超过 100 万行时,会自动重建细粒度索引,如需手动重建索引可以用 DROP + ADD 命令。
操作教程
添加细粒度索引
功能描述
- 当要提高对源表中某一列或某几列的查询效率时,可以使用 ALTER TABLE ADD FINE-GRAINED INDEX INTO 向该表中添加指定列的细粒度索引。
- 细粒度索引支持对单列字段构建,如多个字段需要构建索引,可分别创建索引。
- 支持对 Holodesk Performance表(但源表中的字段不支持 blob 或 clob 类型)添加细粒度索引。
注意事项
- 添加索引的字段,应该选择基于 WHERE 子句频繁点查的字段,具体查询子句请参考 SQL 语句命中细粒度索引。
- 尚不支持创建表的同时创建细粒度索引。
- 对于频繁进行改动的字段或使用频率极低的字段,不适合添加索引。
语法格式
ALTER TABLE <table_name> ADD FINE-GRAINED INDEX (<column_name>);参数说明
- <table_name>:表名称。
- <column_name>:列名称。
示例_创建源表 single_fgindex_t 并插入数据
CREATE TABLE single_fgindex_t(trans_id INT,acc_num INT,trans_time DATE,trans_type STRING,stock_id STRING,price decimal,amount INT)
STORED AS HOLODESK;
BATCHINSERT INTO single_fgindex_t BATCHVALUES (
VALUES (1, 1, '2023-2-28', 'discount', 'NO20140201', 10.00,99),
VALUES(1, 2, '2023-3-1', 'online', 'NO20140201', 12.11,10),
VALUES (1, 1, '2019-10-1', 'wholesale', 'NO20191001', 8.99,1010),
VALUES (2, 4, '2019-8-21', 'discount', 'NO20191001', 8.99,10000),
VALUES (2, 5, '2015-5-6', 'wholesale', 'NO20191001', 8.99,5000),
VALUES (2, 6, '2008-5-12', 'wholesale', 'NO20191001', 8.99,10000),
VALUES (3, 7, '2024-1-31', 'online', 'NO20191001', 8.99,100000),
VALUES (3, 8, '2022-6-1', 'discount', 'NO20191001', 8.99,50000),
VALUES (4, 9, '2022-7-29', 'online', 'NO20191001', 8.99,80000),
VALUES (5, 10, '2019-10-1', 'wholesale', 'NO20140201', 8.99,1000));基于 trans_id 字段添加单值细粒度索引
ALTER TABLE single_fgindex_t ADD FINE-GRAINED INDEX (trans_id);查看索引
功能描述
使用 SELECT HOLO_INDEX 查看指定数据库表中的索引信息。
语法格式
SELECT HOLO_INDEX ("<database_name>", "<table_name>");参数说明
- <database_name>:数据库名称。
- <table_name>:表名称。
示例_查看表 single_fgindex_t 中的索引
SELECT HOLO_INDEX ("demodata", "single_fgindex_t");查询结果如下:
+--------------+----------------+----------------+-------------+
| column_name | table_name | database_name | index_type |
+--------------+----------------+----------------+-------------+
| TRANS_ID | single_fgindex_t | demodata | global |
+--------------+----------------+----------------+-------------+使用细粒度索引
功能描述
- 支持过滤条件为 = 或 in 时命中。
- 以索引 alter table t add fine-grained index(a); 为例,以下过滤子句都可以命中单列细粒度索引:
where a = 1;
where a in (1, 2, 3);
where a in (1, 2, 3) and a > 2;
where 1 < b < 10 and a = 1;注意事项
查询语句中包含 or 的过滤组合,无法命中细粒度索引。
语法格式
您可以通过 EXPLAIN 查询语句,查看是否命中了细粒度索引
[Explain] SELECT FROM <table_name> WHERE <index_column> = <value> and <filter_statement>;当结果中出现 ArgoDB Index Scan: 字样,则表示本查询成功命中细粒度索引加速。
参数说明
- <table_name>:表名称。
- <index_column>:建有细粒度索引的列名。
- <values>:过滤条件中细粒度索引列对应的值。
- <filter_statement>:其余非细粒度索引列的过滤语句。
- <index_inform>:TDDMS 中存储的细粒度索引表信息。
示例
explain select * from single_fgindex_t where trans_id = 2;
explain select * from single_fgindex_t where trans_id in (1,2,3);
explain select * from single_fgindex_t where trans_id in (1,2,3) and trans_id > 3;
explain select * from single_fgindex_t where trans_id in (1,2,3) and trans_id > 3;结果中均会出现如下信息:
TableScan
alias: fgindex_table
ArgoDB Index Scan: demodata.single_fgindex_t_07541918-7069-46f1-843f-06edcd468047_holodeskgi_TRANS_ID_fine_grained删除细粒度索引
功能描述
使用 ALTER TABLE DROP FINE-GRAINED INDEX 删除索引,会直接删除指定索引文件,但不会删除源表信息。
注意事项
- 使用 DROP TABLE <table_name>, 指定源表及其相关索引会进入回收站。
- 使用 TRUNCATE TABLE <table_name>,会清空源表及其相关索引中的数据,但不会删除索引。
- 使用 ALTER TABLE <table_name> DROP PARTITION 删除源表及其相关索引中的指定分区。
- 使用 TRUNCATE TABLE PARTITION,清空源表以及相关索引中的指定分区下的数据,保留分区以及索引。
语法格式
ALTER TABLE <table_name> DROP FINE-GRAINED INDEX (<column_name1>,<column_name2>,...);参数说明
- <table_name>:表名称。
- <column_name>:列名称。
示例_删除细粒度索引
ALTER TABLE single_fgindex_t DROP FINE-GRAINED INDEX (trans_id);更新细粒度索引
细粒度索引只支持在源表发生 INSERT 操作时,在索引表中写入增量数据。当源表发生 UPDATE 或 DELETE 操作时,由于只涉及小部分数据的修改,若重建细粒度索引表,由于读取全表数据浪费大量资源。因此我们支持索引表随主表更新的功能,只对此次源表更新过程中涉及到的索引表数据部分进行重构,降低细粒度索引表的维护难度。
原理介绍
我们通过将细粒度索引表分为 L0 层与 L1 层实现细粒度索引的更新功能:
- L0 层:源表每次 INSERT 写入的增量数据写入细粒度索引表的 L0 层。
- L1 层:当源表数据发生 UPDATE 或 DELETE 时,通过内部比对找到更新数据对应的索引列 key 值,然后将更新数据写入 L1 层
- L1 层数据用于划分 L0 层中对应数据是否过期。
当一个索引 key 同时存在于 L0 和 L1 层时,若 L0 层写入时间先于 L1 层,即该 key 对应的源表数据在 INSERT 之后进行了 UPDATE/DELETE 操作,该条数据无法读取。
当一个索引 key 同时存在于 L0 和 L1 层时,若 L1 层写入时间先于 L0 层,即该 key 对应的源表数据在 UPDATE/DELETE 之后又重新 INSERT 写入,则该条新插入的数据能够被读取。
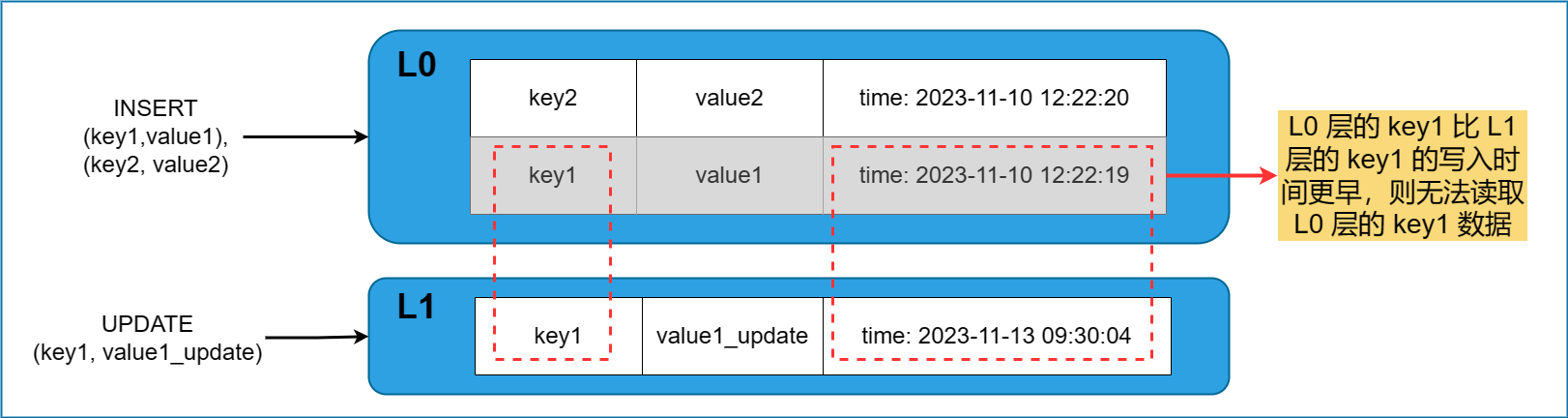
图 41. 细粒度索引分层更新
使用方式
- 通过在 Manager 或会话中设置 Quark 参数,控制细粒度索引的更新功能总开关(默认为 true,开启更新功能):
set argodb.fine.grained.index.update.enabled = true;- 用户还可以通过设置 Quark 参数,控制细粒度索引重建的阈值,即当源表数据的 UPDATE 或 DELETE 操作超过该值时,则自动重建对应的细粒度索引,避免占用过多内存:
set argodb.fine.grained.index.update.rows.limit = 1000000; -- 默认为 100 万行什么是细粒度索引?
ArgoDB 中的细粒度索引是基于 KV(key-value)的索引,提供高速的 KV 服务,索引文件的 Key 存储索引键,Value 存储相同索引键的值。它类似于一种聚簇索引,可以把大量相似的数据细分成更小的边界,从而使文件的查找变得更快更有效率。
图 40. 细粒度索引实现逻辑
适用场景
因此在 ArgoDB 中使用细粒度索引,可以支持实时数仓场景下的多种诉求:
- 支持高 QPS(Queries Per Second 每秒查询数)的基于细粒度索引点查。与全表扫描相比,点查通过扫描小批量数据实现高效数据检索,例如等值查询、范围查询。
- 提高查询效率,减少查询时间,提高查询性能。细粒度索引可以把数据库中的数据分割成更小的单元,以便更快地查找和检索数据。
- 提高搜索的准确性。利用基于 KV 结构可以更精确地检索出文档中的信息。
使用说明
- 暂不支持对细粒度索引列的名称/数据类型/类型长度进行修改。
- 在源表执行数据写入、更新、删除操作时,索引表也需要进行同步的更新,所以使用索引会降低“增、删、改”的效率。
源表更新数据,同步细粒度索引的更新或重建功能,请参考后续章节中更新细粒度索引的部分。
- 索引的并发控制与源表一致,也是采用的 mvcc(multiversion concurrency control),INSERT 操作写 base 文件,DELETE/UPDATE 写 delta 文件
- 细粒度索引的分区、分片、分桶与源表有如下规律:
- 细粒度索引的分区,分片同索引对应源表的分区,分片相同;
- 但索引分桶与源表分桶无关,是按索引列分桶(目前分桶数默认 163)。
- 当源表为列存表且更新数据超过 100 万行时,会自动重建细粒度索引,如需手动重建索引可以用 DROP + ADD 命令。
操作教程
添加细粒度索引
功能描述
- 当要提高对源表中某一列或某几列的查询效率时,可以使用 ALTER TABLE ADD FINE-GRAINED INDEX INTO 向该表中添加指定列的细粒度索引。
- 细粒度索引支持对单列字段构建,如多个字段需要构建索引,可分别创建索引。
- 支持对 Holodesk Performance表(但源表中的字段不支持 blob 或 clob 类型)添加细粒度索引。
注意事项
- 添加索引的字段,应该选择基于 WHERE 子句频繁点查的字段,具体查询子句请参考 SQL 语句命中细粒度索引。
- 尚不支持创建表的同时创建细粒度索引。
- 对于频繁进行改动的字段或使用频率极低的字段,不适合添加索引。
语法格式
ALTER TABLE <table_name> ADD FINE-GRAINED INDEX (<column_name>);参数说明
- <table_name>:表名称。
- <column_name>:列名称。
示例_创建源表 single_fgindex_t 并插入数据
CREATE TABLE single_fgindex_t(trans_id INT,acc_num INT,trans_time DATE,trans_type STRING,stock_id STRING,price decimal,amount INT)
STORED AS HOLODESK;
BATCHINSERT INTO single_fgindex_t BATCHVALUES (
VALUES (1, 1, '2023-2-28', 'discount', 'NO20140201', 10.00,99),
VALUES(1, 2, '2023-3-1', 'online', 'NO20140201', 12.11,10),
VALUES (1, 1, '2019-10-1', 'wholesale', 'NO20191001', 8.99,1010),
VALUES (2, 4, '2019-8-21', 'discount', 'NO20191001', 8.99,10000),
VALUES (2, 5, '2015-5-6', 'wholesale', 'NO20191001', 8.99,5000),
VALUES (2, 6, '2008-5-12', 'wholesale', 'NO20191001', 8.99,10000),
VALUES (3, 7, '2024-1-31', 'online', 'NO20191001', 8.99,100000),
VALUES (3, 8, '2022-6-1', 'discount', 'NO20191001', 8.99,50000),
VALUES (4, 9, '2022-7-29', 'online', 'NO20191001', 8.99,80000),
VALUES (5, 10, '2019-10-1', 'wholesale', 'NO20140201', 8.99,1000));基于 trans_id 字段添加单值细粒度索引
ALTER TABLE single_fgindex_t ADD FINE-GRAINED INDEX (trans_id);查看索引
功能描述
使用 SELECT HOLO_INDEX 查看指定数据库表中的索引信息。
语法格式
SELECT HOLO_INDEX ("<database_name>", "<table_name>");参数说明
- <database_name>:数据库名称。
- <table_name>:表名称。
示例_查看表 single_fgindex_t 中的索引
SELECT HOLO_INDEX ("demodata", "single_fgindex_t");查询结果如下:
+--------------+----------------+----------------+-------------+
| column_name | table_name | database_name | index_type |
+--------------+----------------+----------------+-------------+
| TRANS_ID | single_fgindex_t | demodata | global |
+--------------+----------------+----------------+-------------+使用细粒度索引
功能描述
- 支持过滤条件为 = 或 in 时命中。
- 以索引 alter table t add fine-grained index(a); 为例,以下过滤子句都可以命中单列细粒度索引:
where a = 1;
where a in (1, 2, 3);
where a in (1, 2, 3) and a > 2;
where 1 < b < 10 and a = 1;注意事项
查询语句中包含 or 的过滤组合,无法命中细粒度索引。
语法格式
您可以通过 EXPLAIN 查询语句,查看是否命中了细粒度索引
[Explain] SELECT FROM <table_name> WHERE <index_column> = <value> and <filter_statement>;当结果中出现 ArgoDB Index Scan: 字样,则表示本查询成功命中细粒度索引加速。
参数说明
- <table_name>:表名称。
- <index_column>:建有细粒度索引的列名。
- <values>:过滤条件中细粒度索引列对应的值。
- <filter_statement>:其余非细粒度索引列的过滤语句。
- <index_inform>:TDDMS 中存储的细粒度索引表信息。
示例
explain select * from single_fgindex_t where trans_id = 2;
explain select * from single_fgindex_t where trans_id in (1,2,3);
explain select * from single_fgindex_t where trans_id in (1,2,3) and trans_id > 3;
explain select * from single_fgindex_t where trans_id in (1,2,3) and trans_id > 3;结果中均会出现如下信息:
TableScan
alias: fgindex_table
ArgoDB Index Scan: demodata.single_fgindex_t_07541918-7069-46f1-843f-06edcd468047_holodeskgi_TRANS_ID_fine_grained删除细粒度索引
功能描述
使用 ALTER TABLE DROP FINE-GRAINED INDEX 删除索引,会直接删除指定索引文件,但不会删除源表信息。
注意事项
- 使用 DROP TABLE <table_name>, 指定源表及其相关索引会进入回收站。
- 使用 TRUNCATE TABLE <table_name>,会清空源表及其相关索引中的数据,但不会删除索引。
- 使用 ALTER TABLE <table_name> DROP PARTITION 删除源表及其相关索引中的指定分区。
- 使用 TRUNCATE TABLE PARTITION,清空源表以及相关索引中的指定分区下的数据,保留分区以及索引。
语法格式
ALTER TABLE <table_name> DROP FINE-GRAINED INDEX (<column_name1>,<column_name2>,...);参数说明
- <table_name>:表名称。
- <column_name>:列名称。
示例_删除细粒度索引
ALTER TABLE single_fgindex_t DROP FINE-GRAINED INDEX (trans_id);更新细粒度索引
细粒度索引只支持在源表发生 INSERT 操作时,在索引表中写入增量数据。当源表发生 UPDATE 或 DELETE 操作时,由于只涉及小部分数据的修改,若重建细粒度索引表,由于读取全表数据浪费大量资源。因此我们支持索引表随主表更新的功能,只对此次源表更新过程中涉及到的索引表数据部分进行重构,降低细粒度索引表的维护难度。
原理介绍
我们通过将细粒度索引表分为 L0 层与 L1 层实现细粒度索引的更新功能:
- L0 层:源表每次 INSERT 写入的增量数据写入细粒度索引表的 L0 层。
- L1 层:当源表数据发生 UPDATE 或 DELETE 时,通过内部比对找到更新数据对应的索引列 key 值,然后将更新数据写入 L1 层
- L1 层数据用于划分 L0 层中对应数据是否过期。
当一个索引 key 同时存在于 L0 和 L1 层时,若 L0 层写入时间先于 L1 层,即该 key 对应的源表数据在 INSERT 之后进行了 UPDATE/DELETE 操作,该条数据无法读取。
当一个索引 key 同时存在于 L0 和 L1 层时,若 L1 层写入时间先于 L0 层,即该 key 对应的源表数据在 UPDATE/DELETE 之后又重新 INSERT 写入,则该条新插入的数据能够被读取。
图 41. 细粒度索引分层更新
使用方式
- 通过在 Manager 或会话中设置 Quark 参数,控制细粒度索引的更新功能总开关(默认为 true,开启更新功能):
set argodb.fine.grained.index.update.enabled = true;- 用户还可以通过设置 Quark 参数,控制细粒度索引重建的阈值,即当源表数据的 UPDATE 或 DELETE 操作超过该值时,则自动重建对应的细粒度索引,避免占用过多内存:
set argodb.fine.grained.index.update.rows.limit = 1000000; -- 默认为 100 万行 登录后可评论
登录后可评论








.jpg)



