TOS日常运维指南
TOS服务简介
TOS架构
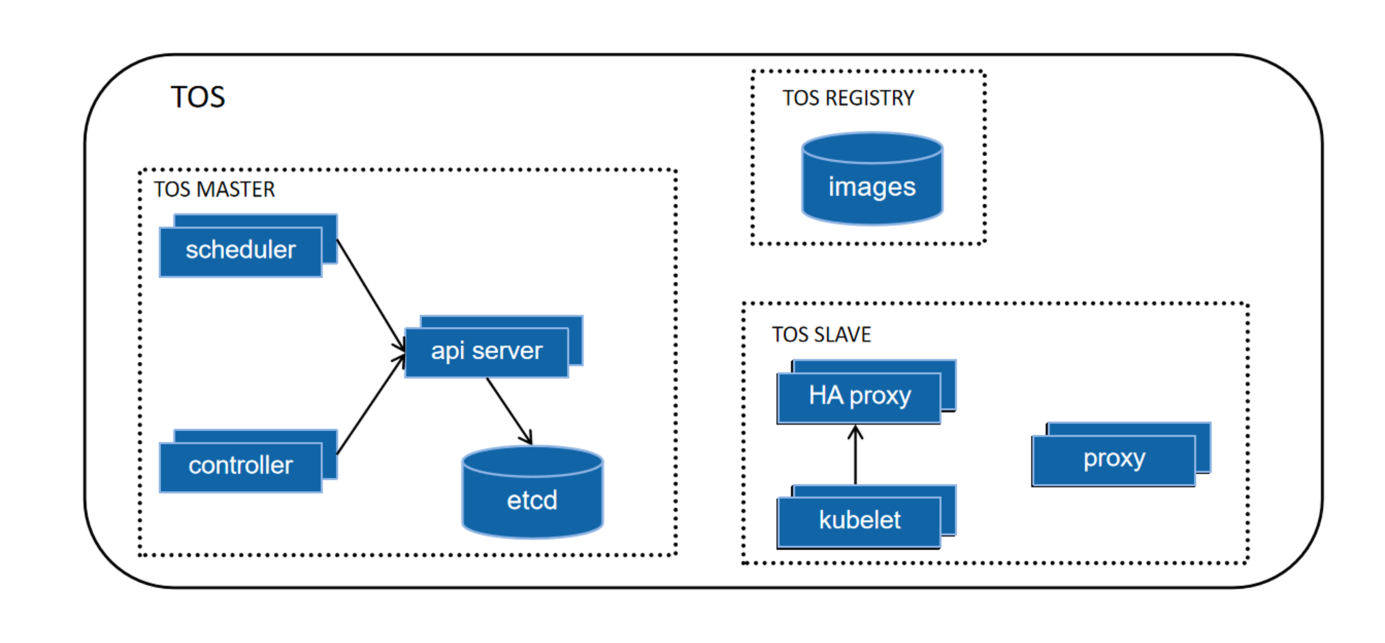
- kubelet:在TOS集群中,在每个节点上都会启动一个kubelet的服务进程,该进程用于处理Master节点下发到本节点的任务;
- proxy:在TOS集群的每个节点的上都会运行一个proxy服务,这个服务可以看作Service的透明代理和负载均衡器(Service服务转发);
- ApiServer:ApiServer的核心功能是提供了TOS各类资源对象(如Pod,Replica Controller,Service等)的增加、删除、修改等的HTTP REST接口,成为集群内各个功能模块之间数据交互和通信(TOS访问接口);
- Etcd:高可用KV数据库(持久化存储);
- ControllerManager:Controller Manager为整个集群内部的管理控制中心,负责集群内的Node,Pod副本,endpoint,namespace,serviceAccount,ResourceQuota等等的管理(管理控制);
- Scheduler:Scheduler的主要作用就是将待调度的Pod(API新创建的Pod、Controller Manager为补足副本而创建的Pod等等)按照特定的调度算法和调度策略绑定(调度);
- TOS Registry:私有镜像库服务容器,提供相关其他服务的镜像下载。
TOS SLAVE的启动方式(Manager上TOS SLAVE不健康的情况下,可以参考快速重启)
\$ systemctl start docker
\$ systemctl start haproxy
\$ systemctl start kubeletManager上TOS SLAVE 不健康的情况下,可以参照下面的方式进行修复
\$ systemctl restart docker
\$ systemctl restart haproxy
\$ systemctl restart kubeletTOS MASTER的启动方式 (Manager上TOS Master不健康的情况下,可以参考快速重启)
TOS Master采用静态pod的方式启动,kubelet会每隔15秒去/opt/kubernetes/manifests-multi目录下扫描新文件。
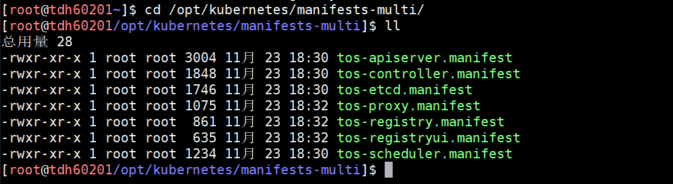
所以TOS MASTER的启动方式是定期只要在/opt/kubernetes/manifests-multi扫描到相对应的manifest文件,就会进行启动。
TOS MASTER的重启操作可以参考:
\$ mv /opt/kubernetes/manifests-multi/tos-* /tmp/隔1分钟
\$ mv /tmp/tos-* /opt/kubernetes/manifests-multi/TOS深度运维
TOS SLAVE 不正常
启动 TOS SLAVE的启动顺序是 docker-->kubelet-->haproxy
参考前述内容“TOS SLAVE的启动方式” 重启一下,如果这三个服务在重启中卡住,可以参考下面的方式查看日志:
先直观检查服务的status,加上-l显示详情:
\$ systemctl status docker -l
\$ systemctl status kubelet -l
\$ systemctl status haproxy -l详细日志:
5.1.2 版本之前,tos master的log目录为/var/log/kubernetes
5.1.2 版本之后日志归journald管理
\$ journalctl -u kubelet -n 1000 查看1000行kubelet的日志
\$ journalctl -u docker -n 100 查看100 行 docker 的日志
\$ journalctl -u haproxy -n 100 查看100行haproxu的日志;其中,docker不健康,无法启动,可以参考文章:docker服务无法启动container的TOS大招
其中,haproxy不健康,无法启动,可以参考文章:haproxy 启动失败问题归纳
其中,kubelet不健康,无法启动,建议检查一下磁盘使用率,以及apiserver是否健康,参考文章:TDH 集群中部分节点的所有 pod 无法查看 log 信息
TOS MASTER 不正常
\$ kubectl get pods -n kube-system -owide查看pod状态,定位一下具体是哪个pod状态不正常
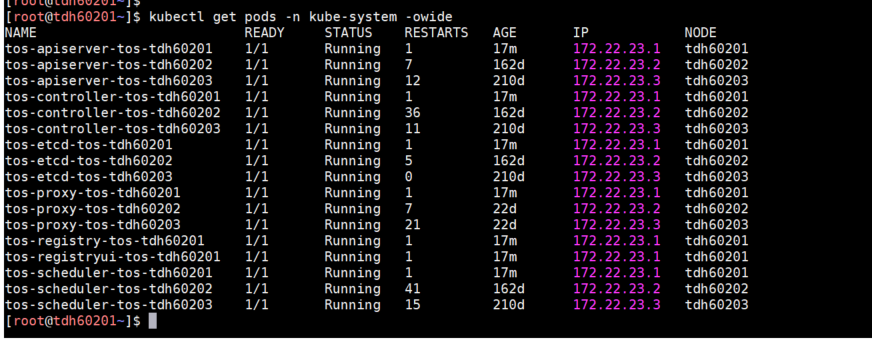
etcd 运维
根据经验判断。如果该节点所有的pod (tos-apiserver-tos-hostname, tos-controller-tos-hostname,tos-etcd-tos-hostname,tos-proxy-tos-hostname,tos-scheduler-tos-hostname 等) 状态如果都异常的话,首先需要判断etcd的状态,etcd就相当于tos的数据库,etcd的数据在/var/etcd/data/路径下;
docker ps -a|grep etcd由于pod此时应当是启动失败的,所以docker ps -a 找到Exited (255) x minutes ago 的类似的一组容器,找到对应的container-id。其中pause容器是每个pod里会起的一个基础容器,运维时可以忽略这个容器,只要查看主容器的日志。

\$ docker logs <containerid>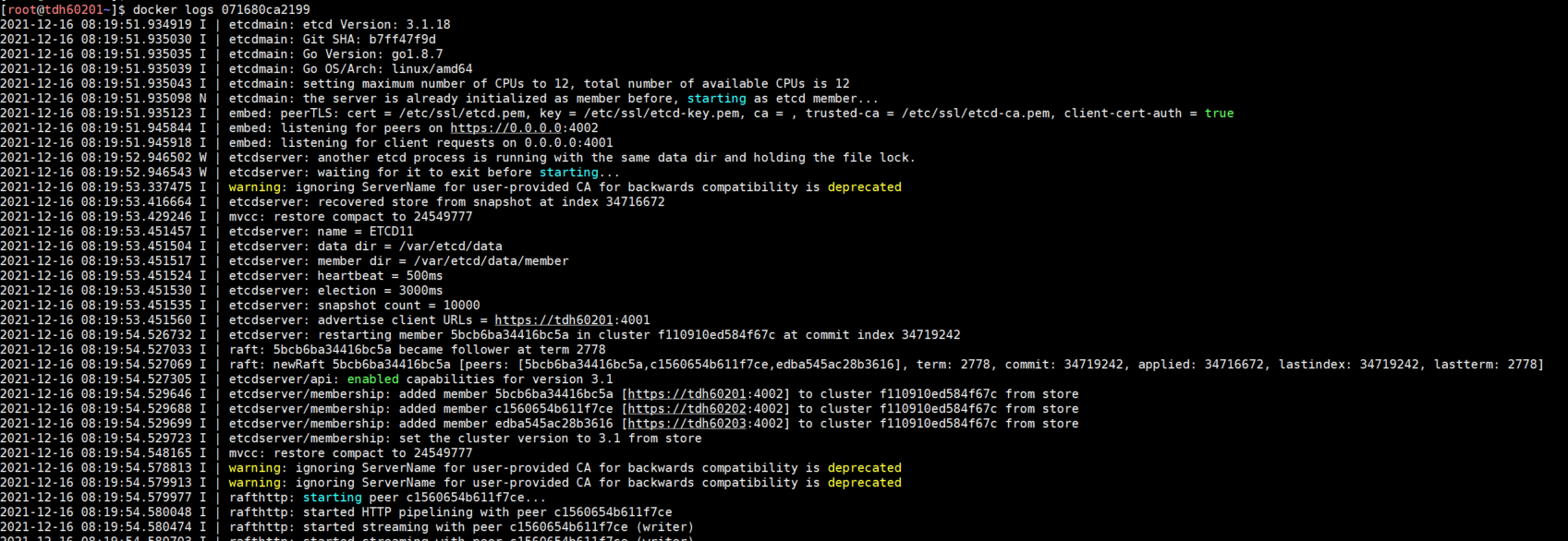
根据经验,etcd的问题可以通过参考以下文章进行修复:
重启etcd的方法:
\$ mv /opt/kubernetes/manifests-multi/tos-etcd.manifest /tmp/
隔1分钟
\$ mv /tmp/tos-etcd.manifest /opt/kubernetes/manifests-multi/apiserver运维
etcd状态正常,再去排查apiserver的状态,一般apiserver的问题大多是etcd不正常导致的,参照前文中etcd的查找日志方法:
\$ docker ps -a|grep apiserver
\$ docker logs <containerid>重启apiserver的方法:
mv /opt/kubernetes/manifests-multi/tos-apiserver.manifest /tmp/
# 隔1分钟
mv /tmp/tos-apiserver.manifest /opt/kubernetes/manifests-multi/controller/scheduler运维
\$ docker ps -a|grep controller
\$ docker ps -a|grep scheduler\$ docker logs <containerid>重启controller和scheduler的方法:
\$ mv /opt/kubernetes/manifests-multi/tos-controller.manifest /tmp/
\$ mv /opt/kubernetes/manifests-multi/tos-scheduler.manifest /tmp/
# 隔1分钟
\$ mv /tmp/tos-controller.manifest /opt/kubernetes/manifests-multi/
\$ mv /tmp/tos-scheduler.manifest /opt/kubernetes/manifests-multi/TOS服务简介
TOS架构
- kubelet:在TOS集群中,在每个节点上都会启动一个kubelet的服务进程,该进程用于处理Master节点下发到本节点的任务;
- proxy:在TOS集群的每个节点的上都会运行一个proxy服务,这个服务可以看作Service的透明代理和负载均衡器(Service服务转发);
- ApiServer:ApiServer的核心功能是提供了TOS各类资源对象(如Pod,Replica Controller,Service等)的增加、删除、修改等的HTTP REST接口,成为集群内各个功能模块之间数据交互和通信(TOS访问接口);
- Etcd:高可用KV数据库(持久化存储);
- ControllerManager:Controller Manager为整个集群内部的管理控制中心,负责集群内的Node,Pod副本,endpoint,namespace,serviceAccount,ResourceQuota等等的管理(管理控制);
- Scheduler:Scheduler的主要作用就是将待调度的Pod(API新创建的Pod、Controller Manager为补足副本而创建的Pod等等)按照特定的调度算法和调度策略绑定(调度);
- TOS Registry:私有镜像库服务容器,提供相关其他服务的镜像下载。
TOS SLAVE的启动方式(Manager上TOS SLAVE不健康的情况下,可以参考快速重启)
\$ systemctl start docker
\$ systemctl start haproxy
\$ systemctl start kubeletManager上TOS SLAVE 不健康的情况下,可以参照下面的方式进行修复
\$ systemctl restart docker
\$ systemctl restart haproxy
\$ systemctl restart kubeletTOS MASTER的启动方式 (Manager上TOS Master不健康的情况下,可以参考快速重启)
TOS Master采用静态pod的方式启动,kubelet会每隔15秒去/opt/kubernetes/manifests-multi目录下扫描新文件。
所以TOS MASTER的启动方式是定期只要在/opt/kubernetes/manifests-multi扫描到相对应的manifest文件,就会进行启动。
TOS MASTER的重启操作可以参考:
\$ mv /opt/kubernetes/manifests-multi/tos-* /tmp/隔1分钟
\$ mv /tmp/tos-* /opt/kubernetes/manifests-multi/TOS深度运维
TOS SLAVE 不正常
启动 TOS SLAVE的启动顺序是 docker-->kubelet-->haproxy
参考前述内容“TOS SLAVE的启动方式” 重启一下,如果这三个服务在重启中卡住,可以参考下面的方式查看日志:
先直观检查服务的status,加上-l显示详情:
\$ systemctl status docker -l
\$ systemctl status kubelet -l
\$ systemctl status haproxy -l详细日志:
5.1.2 版本之前,tos master的log目录为/var/log/kubernetes
5.1.2 版本之后日志归journald管理
\$ journalctl -u kubelet -n 1000 查看1000行kubelet的日志
\$ journalctl -u docker -n 100 查看100 行 docker 的日志
\$ journalctl -u haproxy -n 100 查看100行haproxu的日志;其中,docker不健康,无法启动,可以参考文章:docker服务无法启动container的TOS大招
其中,haproxy不健康,无法启动,可以参考文章:haproxy 启动失败问题归纳
其中,kubelet不健康,无法启动,建议检查一下磁盘使用率,以及apiserver是否健康,参考文章:TDH 集群中部分节点的所有 pod 无法查看 log 信息
TOS MASTER 不正常
\$ kubectl get pods -n kube-system -owide查看pod状态,定位一下具体是哪个pod状态不正常
etcd 运维
根据经验判断。如果该节点所有的pod (tos-apiserver-tos-hostname, tos-controller-tos-hostname,tos-etcd-tos-hostname,tos-proxy-tos-hostname,tos-scheduler-tos-hostname 等) 状态如果都异常的话,首先需要判断etcd的状态,etcd就相当于tos的数据库,etcd的数据在/var/etcd/data/路径下;
docker ps -a|grep etcd由于pod此时应当是启动失败的,所以docker ps -a 找到Exited (255) x minutes ago 的类似的一组容器,找到对应的container-id。其中pause容器是每个pod里会起的一个基础容器,运维时可以忽略这个容器,只要查看主容器的日志。
\$ docker logs <containerid>
根据经验,etcd的问题可以通过参考以下文章进行修复:
重启etcd的方法:
\$ mv /opt/kubernetes/manifests-multi/tos-etcd.manifest /tmp/
隔1分钟
\$ mv /tmp/tos-etcd.manifest /opt/kubernetes/manifests-multi/apiserver运维
etcd状态正常,再去排查apiserver的状态,一般apiserver的问题大多是etcd不正常导致的,参照前文中etcd的查找日志方法:
\$ docker ps -a|grep apiserver
\$ docker logs <containerid>重启apiserver的方法:
mv /opt/kubernetes/manifests-multi/tos-apiserver.manifest /tmp/
# 隔1分钟
mv /tmp/tos-apiserver.manifest /opt/kubernetes/manifests-multi/controller/scheduler运维
\$ docker ps -a|grep controller
\$ docker ps -a|grep scheduler\$ docker logs <containerid>重启controller和scheduler的方法:
\$ mv /opt/kubernetes/manifests-multi/tos-controller.manifest /tmp/
\$ mv /opt/kubernetes/manifests-multi/tos-scheduler.manifest /tmp/
# 隔1分钟
\$ mv /tmp/tos-controller.manifest /opt/kubernetes/manifests-multi/
\$ mv /tmp/tos-scheduler.manifest /opt/kubernetes/manifests-multi/ 登录后可评论
登录后可评论








.jpg)



