Inceptor 层次化查询介绍及示例
数据准备
本案例中的基本数据可通过如下 SQL 来创建。
DROP TABLE IF EXISTS no_loop_employee;
CREATE TABLE no_loop_employee(
employee_id INT,
name STRING,
manager_id INT
)
CLUSTERED BY (employee_id) INTO 3 BUCKETS
STORED AS ORC
TBLPROPERTIES ("transactional"="true");
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (1, 'kochhr', NULL);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (2, 'greenberg', 1);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (3, 'faviet', 1);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (4, 'chen', 2);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (5, 'sciarra', 2);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (6, 'urman', 3);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (7, 'popp', 2);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (8, 'whlen', 6);
DROP TABLE IF EXISTS loop_employee;
CREATE TABLE loop_employee(
employee_id INT,
name STRING,
manager_id INT
)
CLUSTERED BY (employee_id) INTO 3 BUCKETS
STORED AS ORC
TBLPROPERTIES ("transactional"="true");
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (1, 'kochhr', NULL);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (2, 'greenberg', 1);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (3, 'faviet', 8);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (4, 'chen', 2);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (5, 'sciarra', 2);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (6, 'urman', 3);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (7, 'popp', 2);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (8, 'whlen', 6);根据组织关系,no_loop_employee这张表形成了如下的树形结构。
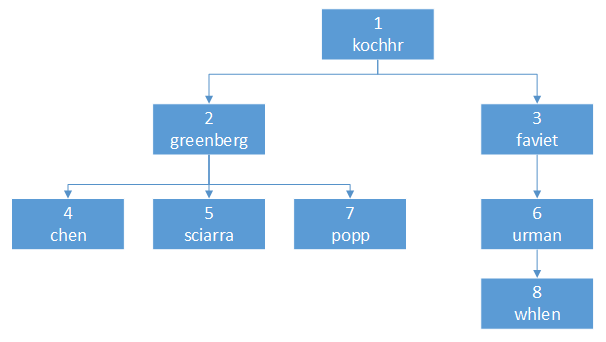
基本用法
层次化查询的核心是用CONNECT BY字句指定父行和子行的对应关系,从而建立树形结构,例如以下的语句。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
CONNECT BY manager_id = PRIOR employee_id;注意其中的hq__level是一个伪列,指明行在树中的层次,从1开始。CONNECT BY中的PRIOR表明后面的这个列是父行的列,所以这个例子中字句的意思是父行的employee_id和当前行的manager_id相等,通过这个建立树形关系。
输出大致如下图。
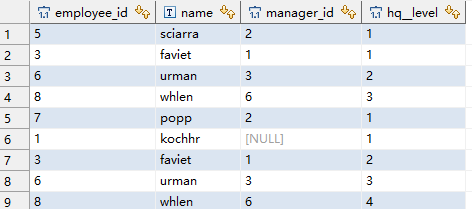
这里会列出以表中的所有行作为根节点形成的树。
指定根节点
可以用START WITH子句指定树的根节点,例如以老板作为根节点。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
START WITH name='kochhr'
CONNECT BY manager_id = PRIOR employee_id;这样就输出了整个组织的架构:
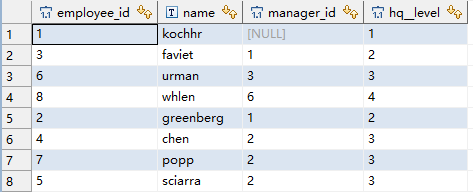
注意这里我们是可以指定多个根节点的。
交换树的顺序
前面的例子里面,树都是以上司为根节点或父节点,下属为子节点,也可以让下属成为根和父节点,只要调整PRIOR的位置。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
START WITH name='whlen'
CONNECT BY employee_id = PRIOR manager_id;这里我们指定父行的manager_id是当前行的employee_id,这样就让下属成为父行,输出如下。

数据过滤
可以通过WHERE字句过滤掉树中的某一个节点,例如。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
WHERE name != 'faviet'
START WITH name='kochhr'
CONNECT BY manager_id = PRIOR employee_id;输出大致如下。
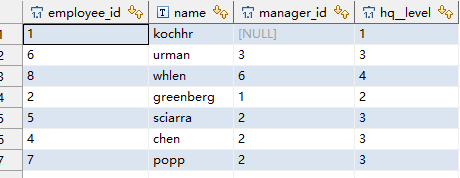
可以看到name是faviet的节点都被过滤掉了。但是这个分支还在,我们可以看到他的下属都在,要过滤掉这个分支,需要在CONNECT BY里过滤,例如。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
START WITH name='kochhr'
CONNECT BY name != 'faviet' AND manager_id = PRIOR employee_id;输出如下。
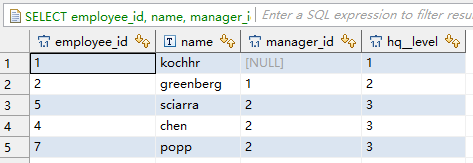
可以看到整个上司是faviet的分支都被过滤掉了。
循环错误
因为层次化查询生成一个树,树是不能有环的,如果有环会报错,例如。
SELECT employee_id, name, manager_id
FROM loop_employee
START WITH employee_id = 3
CONNECT BY PRIOR employee_id = manager_id;会报这样的错误。
EXECUTION FAILED: Task MAPRED-SPARK error SparkException: [Error 1] Job aborted due to stage failure: Task 0 in stage 102550.0 failed 4 times, most recent failure: Lost task 0.3 in stage 102550.0 (TID 389802, baogang1): java.lang.RuntimeException: Loop founded in hierarchical query
本文是一个层次化查询的简单demo,如需要更多的用法和限制信息,请查阅相关Inceptor使用手册。
数据准备
本案例中的基本数据可通过如下 SQL 来创建。
DROP TABLE IF EXISTS no_loop_employee;
CREATE TABLE no_loop_employee(
employee_id INT,
name STRING,
manager_id INT
)
CLUSTERED BY (employee_id) INTO 3 BUCKETS
STORED AS ORC
TBLPROPERTIES ("transactional"="true");
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (1, 'kochhr', NULL);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (2, 'greenberg', 1);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (3, 'faviet', 1);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (4, 'chen', 2);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (5, 'sciarra', 2);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (6, 'urman', 3);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (7, 'popp', 2);
INSERT INTO no_loop_employee(employee_id, name, manager_id) VALUES (8, 'whlen', 6);
DROP TABLE IF EXISTS loop_employee;
CREATE TABLE loop_employee(
employee_id INT,
name STRING,
manager_id INT
)
CLUSTERED BY (employee_id) INTO 3 BUCKETS
STORED AS ORC
TBLPROPERTIES ("transactional"="true");
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (1, 'kochhr', NULL);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (2, 'greenberg', 1);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (3, 'faviet', 8);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (4, 'chen', 2);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (5, 'sciarra', 2);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (6, 'urman', 3);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (7, 'popp', 2);
INSERT INTO loop_employee(employee_id, name, manager_id) VALUES (8, 'whlen', 6);根据组织关系,no_loop_employee这张表形成了如下的树形结构。
基本用法
层次化查询的核心是用CONNECT BY字句指定父行和子行的对应关系,从而建立树形结构,例如以下的语句。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
CONNECT BY manager_id = PRIOR employee_id;注意其中的hq__level是一个伪列,指明行在树中的层次,从1开始。CONNECT BY中的PRIOR表明后面的这个列是父行的列,所以这个例子中字句的意思是父行的employee_id和当前行的manager_id相等,通过这个建立树形关系。
输出大致如下图。
这里会列出以表中的所有行作为根节点形成的树。
指定根节点
可以用START WITH子句指定树的根节点,例如以老板作为根节点。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
START WITH name='kochhr'
CONNECT BY manager_id = PRIOR employee_id;这样就输出了整个组织的架构:
注意这里我们是可以指定多个根节点的。
交换树的顺序
前面的例子里面,树都是以上司为根节点或父节点,下属为子节点,也可以让下属成为根和父节点,只要调整PRIOR的位置。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
START WITH name='whlen'
CONNECT BY employee_id = PRIOR manager_id;这里我们指定父行的manager_id是当前行的employee_id,这样就让下属成为父行,输出如下。
数据过滤
可以通过WHERE字句过滤掉树中的某一个节点,例如。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
WHERE name != 'faviet'
START WITH name='kochhr'
CONNECT BY manager_id = PRIOR employee_id;输出大致如下。
可以看到name是faviet的节点都被过滤掉了。但是这个分支还在,我们可以看到他的下属都在,要过滤掉这个分支,需要在CONNECT BY里过滤,例如。
SELECT employee_id, name, manager_id, hq__level
FROM no_loop_employee
START WITH name='kochhr'
CONNECT BY name != 'faviet' AND manager_id = PRIOR employee_id;输出如下。
可以看到整个上司是faviet的分支都被过滤掉了。
循环错误
因为层次化查询生成一个树,树是不能有环的,如果有环会报错,例如。
SELECT employee_id, name, manager_id
FROM loop_employee
START WITH employee_id = 3
CONNECT BY PRIOR employee_id = manager_id;会报这样的错误。
EXECUTION FAILED: Task MAPRED-SPARK error SparkException: [Error 1] Job aborted due to stage failure: Task 0 in stage 102550.0 failed 4 times, most recent failure: Lost task 0.3 in stage 102550.0 (TID 389802, baogang1): java.lang.RuntimeException: Loop founded in hierarchical query
本文是一个层次化查询的简单demo,如需要更多的用法和限制信息,请查阅相关Inceptor使用手册。
 登录后可评论
登录后可评论








.jpg)



