KunDB原理解读 | SQL引擎工作原理与核心模块详解
友情链接
前言
星环科技自主研发的分布式交易型数据库KunDB在SQL引擎层面不仅完美兼容MySQL,同时在兼容Oracle方面也处于业内领先的地位:目前KunDB已支持绝大部分Oracle语法,且完全支持PL/SQL。
关于 KunDB PL/SQL 编译器,可以阅读 KunDB 原理解读系列之《完整支持 PL/SQL的编译器实现原理解密》。
本文将详细介绍KunDB SQL引擎及工作流程,并重点解析过程中涉及到的解析器、优化器与执行器三个模块,同时结合案例详细介绍KunDB在逻辑优化与物理优化方面的能力,让各位读者对KunDB的SQL引擎和其中的逻辑、物理优化器的设计与实现有较为深入的理解。
KunDB SQL引擎的工作流程
KunDB SQL引擎的工作流程,如下:
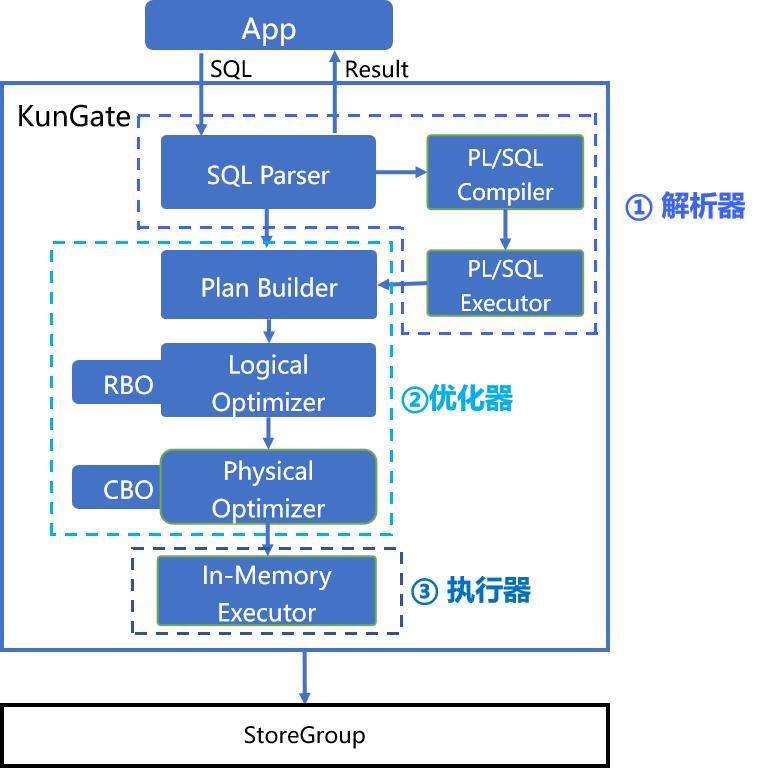
KunDB SQL引擎的工作流程
① 解析器
当KunDB收到一条SQL语句时,首先会进入解析器模块。普通SQL会由SQL Parser处理,而PL/SQL则会被移交PL/SQL编译器负责处理。有关KunDB PL/SQL解析器可以查看《原理解读|KunDB 完整支持 PL/SQL的编译器实现原理解密》,本文主要介绍普通SQL的处理流程。
SQL Parser首先会进行词法和语法分析,并生成一颗抽象语法树(AST)。简单来说,词法与语法分析的目的就是检查SQL语句是否存在语法错误。
接下来会进行语义分析。在语法分析的基础上,对SQL语句进行验证、解析表达式和计算数据类型等操作。语义分析会进一步理解SQL语句的含义和上下文,并在AST上补充这些信息。
② 优化器
解析完成后,AST会被传送到优化器模块。这里首先由Plan Builder模块根据AST生成一个逻辑计划树(LogicalPlanTree),然后Logical Optimizer模块会根据KunDB预设的规则进行逻辑优化,而Physical Optimizer模块则会根据代价模型进行物理优化。
逻辑优化是为了简化和改进执行计划的结构,物理优化是为了选择最快的执行方法和路径。这两类优化都是为了找到更高效的执行计划。这就像是我们在做一件事情前,总要先想好最省时省力的方法。
③ 执行器
最后,优化器将根据执行计划生成的执行算子交给执行器(In-Memory Executor模块)。执行器会按照计划一步步执行任务,并将结果返回给客户端。
KunDB SQL引擎三大模块详解
在了解了KunDB SQL引擎的总体工作流程后,接下来将逐个解析KunDB SQL引擎的三大模块。
1. 解析器
KunDB SQL引擎的解析器由六个子模块组成,它们之间相互协同,共同实现了词法、语法和语义分析。
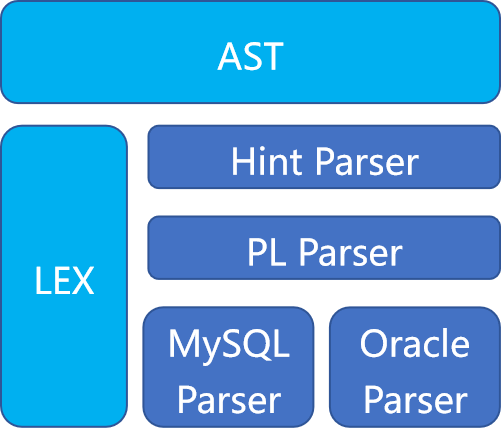
KunDB 解析器模块架构图
- -AST模块是解析器中所有子模块共享的一个模块。所有的解析工作完成后,都会将解析结果以AST的形式进行存储。
- -LEX是KunDB使用Golang编写的词法解析器。在进行语法解析之前,LEX模块会将一个完整的SQL字符串解析成一个个token(词法单元),这些token是进行后续语法匹配的基础。值得一提的是,LEX模块也是所有Parser子模块共用的核心部分。
- -Hint Parser专门用于解析SELECT语句中的Hint(提示)。Hint通常用来给查询优化器提供额外的信息,以便对查询进行优化。
- -PL Parser负责解析PL/SQL语句中的PL语句。而SQL语句将会交由MySQL Parser或Oracle Parser处理。
- -MySQL Parser和Oracle Parser是相互独立的,MySQL Parser兼容MySQL语法,Oracle Parser兼容Oracle语法。通过为sqlmode设置不同的值,可以让KunDB支持两种不同的SQL语法模式(MySQL和Oracle)。
2.优化器
上文提到,优化器通过逻辑优化和物理优化两部分来实现更高效的执行计划。那它们之间的区别在哪里呢?
这里不妨用做菜的过程来打个比方。当我们在厨房里准备大餐时,为了提高效率,首先会规划好步骤,找到最简单、最快的做法。逻辑优化,就像是制定烹饪计划和步骤,这个阶段更多需要考虑的是用什么食材以及大致的烹饪步骤,并不涉及细节。而在物理优化中,会需要决定具体的烹饪方式和器具,以及其他具体的细节问题,比如同样的切菜应该用什么刀切、怎么切会更好等。
基于上面的例子,对于理解KunDB中逻辑优化与物理优化的具体实现会更加清晰。
逻辑优化
KunDB的逻辑计划按照Volcano模型,采用树形结构表示。这棵逻辑计划树上有很多节点(见下图)。如果用做饭来类比,那么树上的每个节点就代表一个操作,比如切菜、搅拌等。(在KunDB中,树上的节点装着projection, aggregation,join,selection,union等逻辑算子)这个树形结构能够帮助我们清晰地看到每一步操作的顺序和关系。
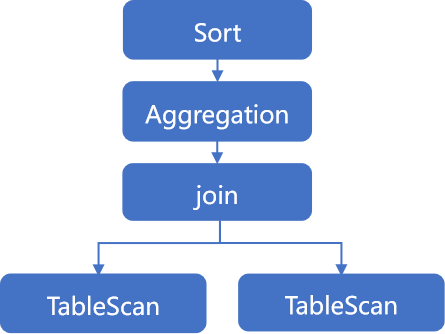
KunDB SQL逻辑计划图
在生成逻辑计划树时,KunDB会处理子查询和视图。就像在做饭前,先把所有的菜谱和步骤整理好,确保每一步都能顺利进行。
逻辑优化的理论基础是关系代数,就像是烹饪规则和技巧的提升,比如先煮饭再炒菜能够节省时间。KunDB也是这样,通过一系列优化规则来简化和加速查询操作。
逻辑优化规则
KunDB内置了众多逻辑优化规则,下面让以几个为例进行深入解析。
- SQL下推
“SQL下推”会根据SQL语句中所包含的信息来判断SQL是否可以被完整地下推到存储层运行。举个例子,我们可以把“煮饭”这个任务交给智能电饭煲,它会根据预设的程序自动完成,无需亲自看管。KunDB的存储层就像这个智能电饭煲,对于被下推的SQL,可以自主地对SQL进行一些计算和优化。这类优化可以大幅度减少数据传输和计算量,提高整体查询效率。
- 谓词下推
“谓词下推”会通过将过滤条件尽可能下推到接近数据源的层次来减少需要处理的数据量。具体而言,谓词下推采用自顶向下的顺序(从树最上方的节点到树最下方的节点),将查询中的过滤条件传递到更底层的操作中,尤其是传递到表扫描(tableScan)阶段。举例来说,对于下面的查询SQL语句:

谓词下推会在扫描customers表时就应用age>30的过滤条件,从而减少后续JOIN需要连接的记录数。因此,谓词下推能够显著减少不必要的数据处理和传输,从而提升查询速度。
- 列裁减
“列裁剪”会以从上到下的顺序,只将父节点需要的列传递到子节点,最终到达tableScan阶段。举例来说,假设有一个表employees,包含以下列:id、name、age、department、salary。
原始查询的SQL是这样的:

通过列裁剪,最后的逻辑计划只会读取name、department和age列,而不会读取id和salary列,从而减少I/O与内存的浪费,提升查询性能。
物理优化
KunDB的物理执行计划结构与逻辑计划的结构相仿,都是树形结构。对于一棵物理执行计划树,每棵子树都有一个计划类型:Local Plan或Scatter Plan。其中Local Plan需要在KunGate执行,而Sactter Plan则表示可以下推执行。最终整个执行计划是否可以下推由所有子节点合并的结果进行判断,具体处理逻辑见下图。
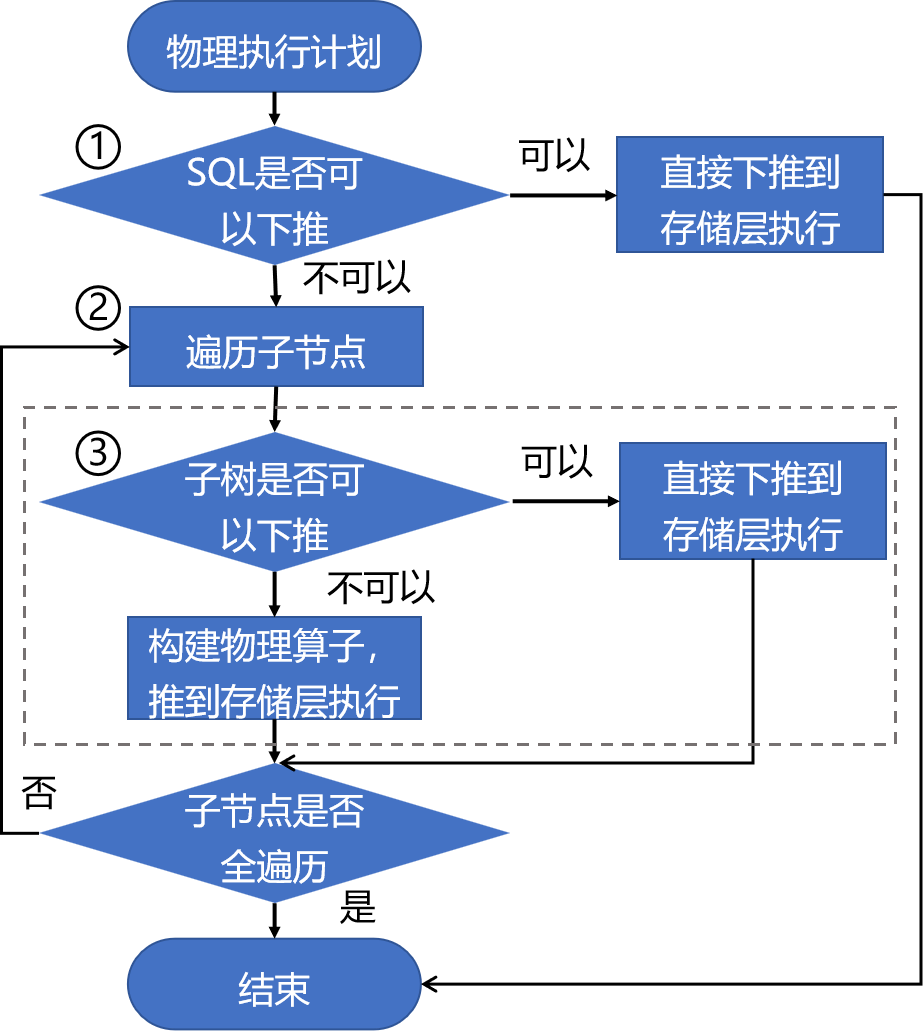
KunDB 执行计划下推判断逻辑图
对于一个物理执行计划:
① 如果SQL能够直接下推到存储层执行,那么直接将SQL下推,无需任何物理计划优化。
② 如果不能下推,即需要开始遍历其子节点。
③ 在遍历的过程中,一方面需要看这棵树的某个子节点能否下推到存储层执行,另一方面需要优化在KunGate执行的物理执行计划。对于前者,可以通过遍历所有子节点的方式确定,如果子节点对应的子树可以下推,那么就会将该子树直接下推到存储层执行。否则会构建物理算子,并在本地执行时先将可以下推的子树下推到存储层拿到结果后,再进行本地计算。
读到这里,有些读者可能会感到好奇,KunDB是以什么规则进行物理优化的呢?
物理优化规则
实际上,KunDB的物理优化通过Cost模型(成本模型)来选择最优的执行计划,通过成本模型计算的结果越低越好。KunDB主要会使用两种计算成本的模型:物理成本与逻辑成本。其中,物理成本包括CPU代价、IO代价、内存代价、网卡情况等,其细粒度会到达缓存未命中。而逻辑成本则会评估每个算子的结果集大小。对其大小的评估是基于输入大小和选择率(selectivity)的乘积,其中选择率通过统计信息(如直方图)评估。
我们都知道,物理执行计划是由大量物理算子组成的。因此,选择最优执行计划的过程,其实就是在面对某一些操作时,从所有可选的物理算子中选择更好的物理算子,并且以最优的方式组合所选的算子。接下来,挑几个关键的物理算子,并讨论其应用场景:
- 聚合操作
KunDB中有两种聚合物理算子,分别是Stream Aggregation与Hash Aggregation。其中Stream Aggregation适用于输入数据已经有序的场景,能够在低内存消耗的情况下保证不错的实时性,但缺陷在于需要输入数据有序。而Hash Aggregation则能够应对无序大数据集,但是需要足够的内存来存储哈希表。
- 连接操作
对于连接操作,KunDB有四类物理算子,分别是Nested-Loop Join、Hash Join、Lookup Join与Sort-Merge Join。其中,Nested-Loop Join的实现较为简单,适用于内表数据量很小,且Join条件中不含等值的情况,其缺点在于面对大数据集时的效率较低。Hash Join适合大数据量的等值链接,且拥有较高的执行效率,缺点在于其需要足够的内存来存储哈希表。Lookup Join则适合连接键上有索引的场景,即使面对较大的内表,其仍然可以拥有不错的性能,其缺点在于需要维护索引,而索引的维护成本是比较高的。最后Sort-Merge Join适用于连接键有序或可以通过排序实现,且数据集很大的情况。它能够很好地处理有序大数据集,但若数据无序,则需要对数据集进行排序,从而导致性能下降。
- 数据读取
KunDB有三种数据读取物理算子,分别是Table-Scan、Index-Table-Scan与Index-Lookup-Scan。Table-Scan适用于小数据量的表或者是没有合适索引的表,其对于大表效率较低,可能会导致大量I/O操作。Index-Table-Scan适用于表中有合适索引情况下的读取,且对于查询中包含order by的场景有很好的表现,缺点在于需要花费成本维护索引。而Index-Lookup-Scan则主要被用于Lookup Join物理算子中,其能够利用索引快速查找匹配的行,缺点也是同样的,需要额外花费成本维护索引。
示例. 整个物理计划的优化过程
对于下面这样一条SQL语句(t1与t2数据量较大):
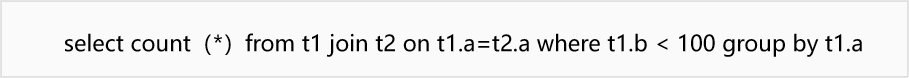
其经过逻辑优化后,逻辑计划树如下图所示:
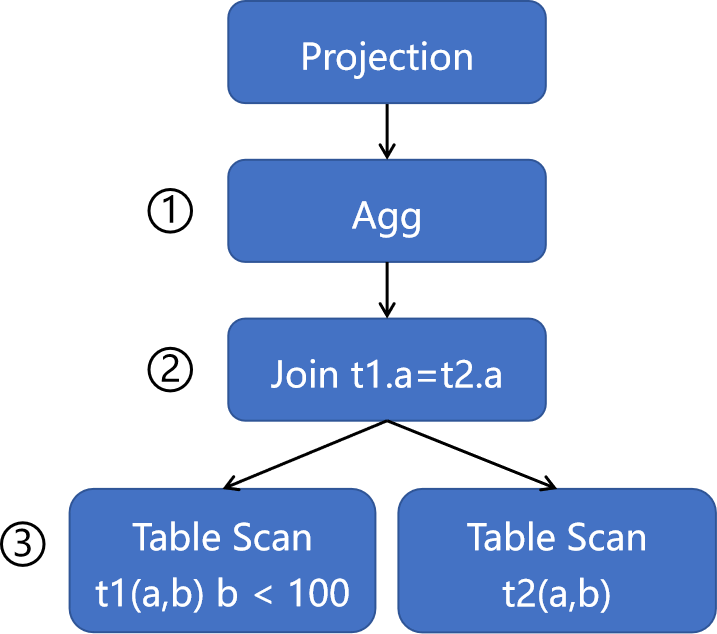
优化后的逻辑计划树
随后,根据这棵逻辑计划树构建物理执行计划树。首先需要遍历每个节点,给出可以使用的物理算子,同时将父节点的需求通过属性传递到子节点。
① 当扫描到Agg节点时,会寻找可用的聚合操作物理算子。对应上面介绍的Stream Aggregation物理算子与Hash Aggregation物理算子。
② 当扫描到Join节点时,则会寻找可用的连接操作物理算子。由于本例中t1与t2数据量较大,因此直接排除Nest-Loop Join物理算子,而留下Sort-Merge Join、Hash Join与Lookup Join三个物理算子。
③ 对于TableScan节点,同样会寻找可用的数据读取物理算子,即上面介绍过的Table-Scan、Index-Table-Scan与Index-Lookup-Scan。
于是就能够得到这样的一棵物理执行计划树:
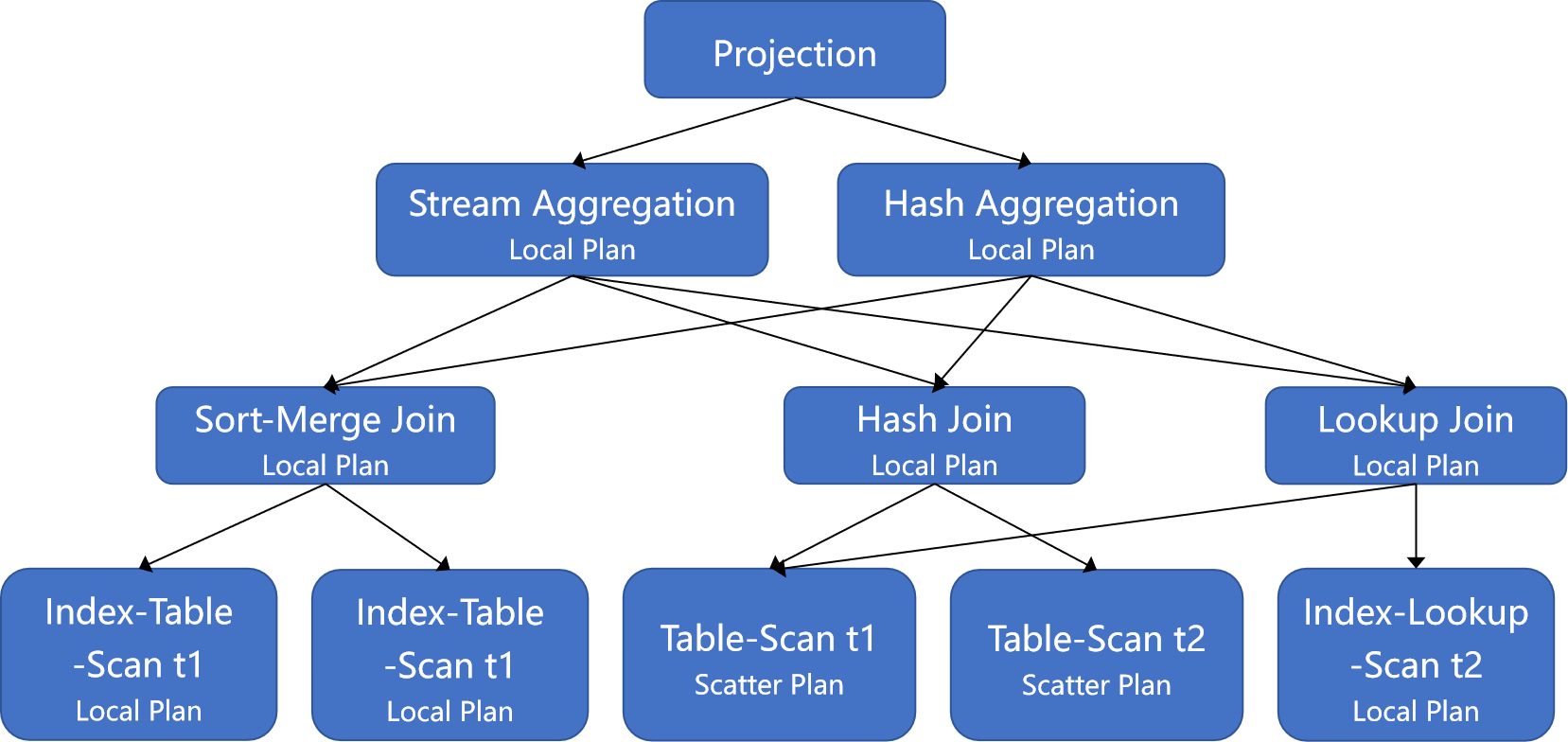
生成的物理执行计划树
可以看到这棵物理执行计划树中,Agg逻辑算子被替换为了Stream Aggregation与Hash Aggregation两个物理算子,每一个都与Projection相连,代表可以选择的两条运行路径,下方散开的节点同样是这个原理。并且可以看到每个节点上还标有Local Plan与Scatter Plan,对应本章节开头时所写的判断是否能够在将子树下推到存储层执行。
最后,通过遍历上面所有可能的物理执行计划树,根据物理成本与逻辑成本,依次计算每一个算子的cost,就能够找到cost最小的树(或者说路径),此时便得到了最终的物理计划。值得一提的是,为了提升计算cost的速度,当某种物理算子的cost被计算过后,就会被存放在缓存中,从而避免重复计算。
3.执行器
KunDB的执行器整体框架如下图所示:
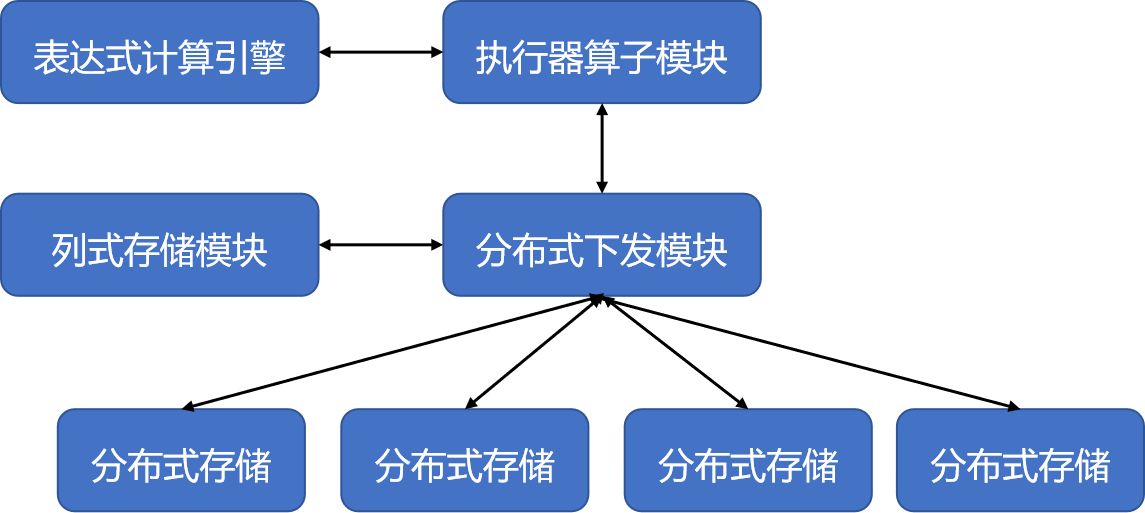
KunDB 执行器整体框架图
其中,
- -表达式计算引擎负责计算表达式,将计算任务传递给执行器算子模块;
- -执行器算子模块会接收表达式计算引擎传递的计算任务,并与分布式下发模块进行交互以执行具体操作;
- -分布式下发模块是执行过程中的枢纽,从执行器算子模块接收指令,并与列式存储模块进行交互,最终将任务下发到各个分布式存储节点;
- -列式存储模块与分布式存储模块负责存储数据或提供数据读取能力。
KunDB执行器按照火山模型执行器的标准接口open-next-close接口实现。open会初始化执行器和资源,next会获取下一批资源,close则会释放资源。其中,next接口通过流模式批量获取数据。
KunDB的执行计划以递归的方式调用executor.next()方法,直到遍历到执行树的叶子节点。各个算子之间通过 channel 进行数据流转。KunDB对数据流转进行了如下优化:
- -首先,为了降低函数调用的开销,KunDB采用chunk而非单行row来处理算子见的数据流动,从而减少函数调用的频率,提高效率。
- -其次,KunDB的chunk内部实现了基于Golang的channle,相较于传统的函数调用,channel提供了一种高效的并发数据传递机制。
- -此外,KunDB采用流模式并发拉取数据。例如,在进行两表 join 操作时,两个表可以并发地分批从存储中拉取数据,从而有效提高数据处理的并发性和效率。
通过这些优化,KunDB的执行器能够更高效地处理大规模数据查询,提升整体系统的性能和响应速度。
扫描下方二维码即可解锁KunDB白皮书

友情链接
前言
星环科技自主研发的分布式交易型数据库KunDB在SQL引擎层面不仅完美兼容MySQL,同时在兼容Oracle方面也处于业内领先的地位:目前KunDB已支持绝大部分Oracle语法,且完全支持PL/SQL。
关于 KunDB PL/SQL 编译器,可以阅读 KunDB 原理解读系列之《完整支持 PL/SQL的编译器实现原理解密》。
本文将详细介绍KunDB SQL引擎及工作流程,并重点解析过程中涉及到的解析器、优化器与执行器三个模块,同时结合案例详细介绍KunDB在逻辑优化与物理优化方面的能力,让各位读者对KunDB的SQL引擎和其中的逻辑、物理优化器的设计与实现有较为深入的理解。
KunDB SQL引擎的工作流程
KunDB SQL引擎的工作流程,如下:
KunDB SQL引擎的工作流程
① 解析器
当KunDB收到一条SQL语句时,首先会进入解析器模块。普通SQL会由SQL Parser处理,而PL/SQL则会被移交PL/SQL编译器负责处理。有关KunDB PL/SQL解析器可以查看《原理解读|KunDB 完整支持 PL/SQL的编译器实现原理解密》,本文主要介绍普通SQL的处理流程。
SQL Parser首先会进行词法和语法分析,并生成一颗抽象语法树(AST)。简单来说,词法与语法分析的目的就是检查SQL语句是否存在语法错误。
接下来会进行语义分析。在语法分析的基础上,对SQL语句进行验证、解析表达式和计算数据类型等操作。语义分析会进一步理解SQL语句的含义和上下文,并在AST上补充这些信息。
② 优化器
解析完成后,AST会被传送到优化器模块。这里首先由Plan Builder模块根据AST生成一个逻辑计划树(LogicalPlanTree),然后Logical Optimizer模块会根据KunDB预设的规则进行逻辑优化,而Physical Optimizer模块则会根据代价模型进行物理优化。
逻辑优化是为了简化和改进执行计划的结构,物理优化是为了选择最快的执行方法和路径。这两类优化都是为了找到更高效的执行计划。这就像是我们在做一件事情前,总要先想好最省时省力的方法。
③ 执行器
最后,优化器将根据执行计划生成的执行算子交给执行器(In-Memory Executor模块)。执行器会按照计划一步步执行任务,并将结果返回给客户端。
KunDB SQL引擎三大模块详解
在了解了KunDB SQL引擎的总体工作流程后,接下来将逐个解析KunDB SQL引擎的三大模块。
1. 解析器
KunDB SQL引擎的解析器由六个子模块组成,它们之间相互协同,共同实现了词法、语法和语义分析。
KunDB 解析器模块架构图
- -AST模块是解析器中所有子模块共享的一个模块。所有的解析工作完成后,都会将解析结果以AST的形式进行存储。
- -LEX是KunDB使用Golang编写的词法解析器。在进行语法解析之前,LEX模块会将一个完整的SQL字符串解析成一个个token(词法单元),这些token是进行后续语法匹配的基础。值得一提的是,LEX模块也是所有Parser子模块共用的核心部分。
- -Hint Parser专门用于解析SELECT语句中的Hint(提示)。Hint通常用来给查询优化器提供额外的信息,以便对查询进行优化。
- -PL Parser负责解析PL/SQL语句中的PL语句。而SQL语句将会交由MySQL Parser或Oracle Parser处理。
- -MySQL Parser和Oracle Parser是相互独立的,MySQL Parser兼容MySQL语法,Oracle Parser兼容Oracle语法。通过为sqlmode设置不同的值,可以让KunDB支持两种不同的SQL语法模式(MySQL和Oracle)。
2.优化器
上文提到,优化器通过逻辑优化和物理优化两部分来实现更高效的执行计划。那它们之间的区别在哪里呢?
这里不妨用做菜的过程来打个比方。当我们在厨房里准备大餐时,为了提高效率,首先会规划好步骤,找到最简单、最快的做法。逻辑优化,就像是制定烹饪计划和步骤,这个阶段更多需要考虑的是用什么食材以及大致的烹饪步骤,并不涉及细节。而在物理优化中,会需要决定具体的烹饪方式和器具,以及其他具体的细节问题,比如同样的切菜应该用什么刀切、怎么切会更好等。
基于上面的例子,对于理解KunDB中逻辑优化与物理优化的具体实现会更加清晰。
逻辑优化
KunDB的逻辑计划按照Volcano模型,采用树形结构表示。这棵逻辑计划树上有很多节点(见下图)。如果用做饭来类比,那么树上的每个节点就代表一个操作,比如切菜、搅拌等。(在KunDB中,树上的节点装着projection, aggregation,join,selection,union等逻辑算子)这个树形结构能够帮助我们清晰地看到每一步操作的顺序和关系。
KunDB SQL逻辑计划图
在生成逻辑计划树时,KunDB会处理子查询和视图。就像在做饭前,先把所有的菜谱和步骤整理好,确保每一步都能顺利进行。
逻辑优化的理论基础是关系代数,就像是烹饪规则和技巧的提升,比如先煮饭再炒菜能够节省时间。KunDB也是这样,通过一系列优化规则来简化和加速查询操作。
逻辑优化规则
KunDB内置了众多逻辑优化规则,下面让以几个为例进行深入解析。
- SQL下推
“SQL下推”会根据SQL语句中所包含的信息来判断SQL是否可以被完整地下推到存储层运行。举个例子,我们可以把“煮饭”这个任务交给智能电饭煲,它会根据预设的程序自动完成,无需亲自看管。KunDB的存储层就像这个智能电饭煲,对于被下推的SQL,可以自主地对SQL进行一些计算和优化。这类优化可以大幅度减少数据传输和计算量,提高整体查询效率。
- 谓词下推
“谓词下推”会通过将过滤条件尽可能下推到接近数据源的层次来减少需要处理的数据量。具体而言,谓词下推采用自顶向下的顺序(从树最上方的节点到树最下方的节点),将查询中的过滤条件传递到更底层的操作中,尤其是传递到表扫描(tableScan)阶段。举例来说,对于下面的查询SQL语句:
谓词下推会在扫描customers表时就应用age>30的过滤条件,从而减少后续JOIN需要连接的记录数。因此,谓词下推能够显著减少不必要的数据处理和传输,从而提升查询速度。
- 列裁减
“列裁剪”会以从上到下的顺序,只将父节点需要的列传递到子节点,最终到达tableScan阶段。举例来说,假设有一个表employees,包含以下列:id、name、age、department、salary。
原始查询的SQL是这样的:
通过列裁剪,最后的逻辑计划只会读取name、department和age列,而不会读取id和salary列,从而减少I/O与内存的浪费,提升查询性能。
物理优化
KunDB的物理执行计划结构与逻辑计划的结构相仿,都是树形结构。对于一棵物理执行计划树,每棵子树都有一个计划类型:Local Plan或Scatter Plan。其中Local Plan需要在KunGate执行,而Sactter Plan则表示可以下推执行。最终整个执行计划是否可以下推由所有子节点合并的结果进行判断,具体处理逻辑见下图。
KunDB 执行计划下推判断逻辑图
对于一个物理执行计划:
① 如果SQL能够直接下推到存储层执行,那么直接将SQL下推,无需任何物理计划优化。
② 如果不能下推,即需要开始遍历其子节点。
③ 在遍历的过程中,一方面需要看这棵树的某个子节点能否下推到存储层执行,另一方面需要优化在KunGate执行的物理执行计划。对于前者,可以通过遍历所有子节点的方式确定,如果子节点对应的子树可以下推,那么就会将该子树直接下推到存储层执行。否则会构建物理算子,并在本地执行时先将可以下推的子树下推到存储层拿到结果后,再进行本地计算。
读到这里,有些读者可能会感到好奇,KunDB是以什么规则进行物理优化的呢?
物理优化规则
实际上,KunDB的物理优化通过Cost模型(成本模型)来选择最优的执行计划,通过成本模型计算的结果越低越好。KunDB主要会使用两种计算成本的模型:物理成本与逻辑成本。其中,物理成本包括CPU代价、IO代价、内存代价、网卡情况等,其细粒度会到达缓存未命中。而逻辑成本则会评估每个算子的结果集大小。对其大小的评估是基于输入大小和选择率(selectivity)的乘积,其中选择率通过统计信息(如直方图)评估。
我们都知道,物理执行计划是由大量物理算子组成的。因此,选择最优执行计划的过程,其实就是在面对某一些操作时,从所有可选的物理算子中选择更好的物理算子,并且以最优的方式组合所选的算子。接下来,挑几个关键的物理算子,并讨论其应用场景:
- 聚合操作
KunDB中有两种聚合物理算子,分别是Stream Aggregation与Hash Aggregation。其中Stream Aggregation适用于输入数据已经有序的场景,能够在低内存消耗的情况下保证不错的实时性,但缺陷在于需要输入数据有序。而Hash Aggregation则能够应对无序大数据集,但是需要足够的内存来存储哈希表。
- 连接操作
对于连接操作,KunDB有四类物理算子,分别是Nested-Loop Join、Hash Join、Lookup Join与Sort-Merge Join。其中,Nested-Loop Join的实现较为简单,适用于内表数据量很小,且Join条件中不含等值的情况,其缺点在于面对大数据集时的效率较低。Hash Join适合大数据量的等值链接,且拥有较高的执行效率,缺点在于其需要足够的内存来存储哈希表。Lookup Join则适合连接键上有索引的场景,即使面对较大的内表,其仍然可以拥有不错的性能,其缺点在于需要维护索引,而索引的维护成本是比较高的。最后Sort-Merge Join适用于连接键有序或可以通过排序实现,且数据集很大的情况。它能够很好地处理有序大数据集,但若数据无序,则需要对数据集进行排序,从而导致性能下降。
- 数据读取
KunDB有三种数据读取物理算子,分别是Table-Scan、Index-Table-Scan与Index-Lookup-Scan。Table-Scan适用于小数据量的表或者是没有合适索引的表,其对于大表效率较低,可能会导致大量I/O操作。Index-Table-Scan适用于表中有合适索引情况下的读取,且对于查询中包含order by的场景有很好的表现,缺点在于需要花费成本维护索引。而Index-Lookup-Scan则主要被用于Lookup Join物理算子中,其能够利用索引快速查找匹配的行,缺点也是同样的,需要额外花费成本维护索引。
示例. 整个物理计划的优化过程
对于下面这样一条SQL语句(t1与t2数据量较大):
其经过逻辑优化后,逻辑计划树如下图所示:
优化后的逻辑计划树
随后,根据这棵逻辑计划树构建物理执行计划树。首先需要遍历每个节点,给出可以使用的物理算子,同时将父节点的需求通过属性传递到子节点。
① 当扫描到Agg节点时,会寻找可用的聚合操作物理算子。对应上面介绍的Stream Aggregation物理算子与Hash Aggregation物理算子。
② 当扫描到Join节点时,则会寻找可用的连接操作物理算子。由于本例中t1与t2数据量较大,因此直接排除Nest-Loop Join物理算子,而留下Sort-Merge Join、Hash Join与Lookup Join三个物理算子。
③ 对于TableScan节点,同样会寻找可用的数据读取物理算子,即上面介绍过的Table-Scan、Index-Table-Scan与Index-Lookup-Scan。
于是就能够得到这样的一棵物理执行计划树:
生成的物理执行计划树
可以看到这棵物理执行计划树中,Agg逻辑算子被替换为了Stream Aggregation与Hash Aggregation两个物理算子,每一个都与Projection相连,代表可以选择的两条运行路径,下方散开的节点同样是这个原理。并且可以看到每个节点上还标有Local Plan与Scatter Plan,对应本章节开头时所写的判断是否能够在将子树下推到存储层执行。
最后,通过遍历上面所有可能的物理执行计划树,根据物理成本与逻辑成本,依次计算每一个算子的cost,就能够找到cost最小的树(或者说路径),此时便得到了最终的物理计划。值得一提的是,为了提升计算cost的速度,当某种物理算子的cost被计算过后,就会被存放在缓存中,从而避免重复计算。
3.执行器
KunDB的执行器整体框架如下图所示:
KunDB 执行器整体框架图
其中,
- -表达式计算引擎负责计算表达式,将计算任务传递给执行器算子模块;
- -执行器算子模块会接收表达式计算引擎传递的计算任务,并与分布式下发模块进行交互以执行具体操作;
- -分布式下发模块是执行过程中的枢纽,从执行器算子模块接收指令,并与列式存储模块进行交互,最终将任务下发到各个分布式存储节点;
- -列式存储模块与分布式存储模块负责存储数据或提供数据读取能力。
KunDB执行器按照火山模型执行器的标准接口open-next-close接口实现。open会初始化执行器和资源,next会获取下一批资源,close则会释放资源。其中,next接口通过流模式批量获取数据。
KunDB的执行计划以递归的方式调用executor.next()方法,直到遍历到执行树的叶子节点。各个算子之间通过 channel 进行数据流转。KunDB对数据流转进行了如下优化:
- -首先,为了降低函数调用的开销,KunDB采用chunk而非单行row来处理算子见的数据流动,从而减少函数调用的频率,提高效率。
- -其次,KunDB的chunk内部实现了基于Golang的channle,相较于传统的函数调用,channel提供了一种高效的并发数据传递机制。
- -此外,KunDB采用流模式并发拉取数据。例如,在进行两表 join 操作时,两个表可以并发地分批从存储中拉取数据,从而有效提高数据处理的并发性和效率。
通过这些优化,KunDB的执行器能够更高效地处理大规模数据查询,提升整体系统的性能和响应速度。
扫描下方二维码即可解锁KunDB白皮书
 登录后可评论
登录后可评论








.jpg)



