DBAService中Stage中的Stargate Context内容如何理解?
友情链接:
- 如何通过Aquila Insight快速定位一个查询为什么慢?
- AquilaInsight核心功能及角色概览
- Aquila的核心功能介绍
- DBA Service的核心功能介绍
- 刚部署好Aquila Insight,第一次如何使用
- 如何通过AquilaInsight快速查看每天有哪些异常/慢查询?
- Aquila 添加自定义监控信息和告警的示例
- 当Quark/Inceptor上跑批变慢、不健康,如何借助星环运维工具AquilaInsight进行排查?
- 【产品使用示例】使用Aquila Insight运维示例(含演示视频)
DBAService上Stage的Stargate Context的内容示例
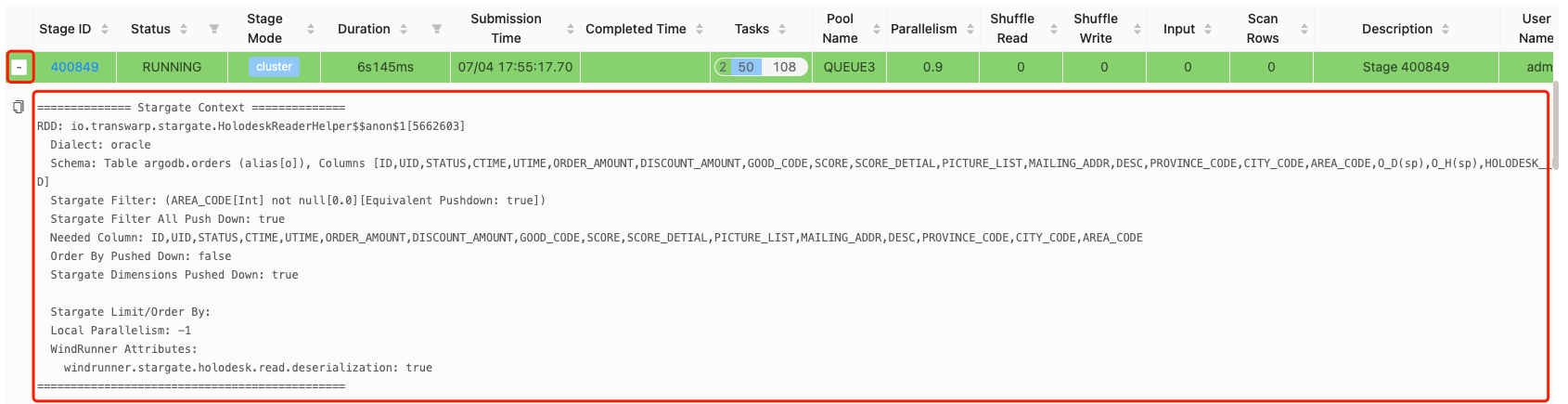
上图的正文如下:
============== Stargate Context ==============
RDD: io.transwarp.stargate.HolodeskReaderHelper$$anon$1[5662603]
Dialect: oracle
Schema: Table argodb.orders (alias[o]), Columns [ID,UID,STATUS,CTIME,UTIME,ORDER_AMOUNT,DISCOUNT_AMOUNT,GOOD_CODE,SCORE,SCORE_DETIAL,PICTURE_LIST,MAILING_ADDR,DESC,PROVINCE_CODE,CITY_CODE,AREA_CODE,O_D(sp),O_H(sp),HOLODESK__BLOCK__ID,HOLODESK__RECORD__ID,HOLODESK__ROW__ID]
Stargate Filter: (AREA_CODE[Int] not null[0.0][Equivalent Pushdown: true])
Stargate Filter All Push Down: true
Needed Column: ID,UID,STATUS,CTIME,UTIME,ORDER_AMOUNT,DISCOUNT_AMOUNT,GOOD_CODE,SCORE,SCORE_DETIAL,PICTURE_LIST,MAILING_ADDR,DESC,PROVINCE_CODE,CITY_CODE,AREA_CODE
Order By Pushed Down: false
Stargate Dimensions Pushed Down: true
Stargate Limit/Order By:
Local Parallelism: -1
WindRunner Attributes:
windrunner.stargate.holodesk.read.deserialization: true
==============================================Stargate Context中各字段说明
| 字段名 | 说明 | 备注 |
|---|---|---|
| RDD | 由TableScanOperator生成,即需要读表的Operator/RDD才会有Stargate Context的内容 | 能看到走的哪条读表的路 |
| Dialect | 方言类型,三种取值:oracle(argodb默认),db2,td。 | 查看社区版官方文档中的交互语言 |
| Schema | Table 库名.表名[(alias[表别名])], Columns [表的所有列名,逗号分隔] | |
| Original Stargate | stargate接收到的过滤条件 | |
| Stargate Filter | 上面表的所有过滤条件,此时的过滤条件时or(a and b and c)这种形式,根节点一定是or。 | 真正下推到存储的过滤条件 |
| Stargate Filter All Push Down | 上面所有的过滤条件是否都可以被下推到存储 | 过滤条件被下推到存储引擎,意味着从存储引擎读到计算引擎的数据都是这些被下推的过滤条件过滤之后的,一般来讲,过滤条件被下推相比表所有数据,会有减少,可以提升性能。 如果是false,可能需要关注 |
| Needed Column | 需要存储引擎返回的改表的列 | 返回的列比表的总列数小的越多,返回的数据大小会越少,可以提升性能。 |
| Not Push Down Columns | 关注的较少 | 关注的较少 |
| Used Index | 关注的较少 | |
| Order By Pushed Down | 关注的较少 | |
| Stargate Dimensions Pushed Down | 关注的较少 | |
| Index Infomation | 关注的较少 | |
| Feedback | 关注的较少 | |
| Stargate Dimensions | 关注的较少 | |
| Stargate Limit/Order By | 关注的较少 | |
| Local Parallelism | 关注的较少 | |
| WindRunner Attributes | 关注的较少 |
友情链接:
- 如何通过Aquila Insight快速定位一个查询为什么慢?
- AquilaInsight核心功能及角色概览
- Aquila的核心功能介绍
- DBA Service的核心功能介绍
- 刚部署好Aquila Insight,第一次如何使用
- 如何通过AquilaInsight快速查看每天有哪些异常/慢查询?
- Aquila 添加自定义监控信息和告警的示例
- 当Quark/Inceptor上跑批变慢、不健康,如何借助星环运维工具AquilaInsight进行排查?
- 【产品使用示例】使用Aquila Insight运维示例(含演示视频)
DBAService上Stage的Stargate Context的内容示例
上图的正文如下:
============== Stargate Context ==============
RDD: io.transwarp.stargate.HolodeskReaderHelper$$anon$1[5662603]
Dialect: oracle
Schema: Table argodb.orders (alias[o]), Columns [ID,UID,STATUS,CTIME,UTIME,ORDER_AMOUNT,DISCOUNT_AMOUNT,GOOD_CODE,SCORE,SCORE_DETIAL,PICTURE_LIST,MAILING_ADDR,DESC,PROVINCE_CODE,CITY_CODE,AREA_CODE,O_D(sp),O_H(sp),HOLODESK__BLOCK__ID,HOLODESK__RECORD__ID,HOLODESK__ROW__ID]
Stargate Filter: (AREA_CODE[Int] not null[0.0][Equivalent Pushdown: true])
Stargate Filter All Push Down: true
Needed Column: ID,UID,STATUS,CTIME,UTIME,ORDER_AMOUNT,DISCOUNT_AMOUNT,GOOD_CODE,SCORE,SCORE_DETIAL,PICTURE_LIST,MAILING_ADDR,DESC,PROVINCE_CODE,CITY_CODE,AREA_CODE
Order By Pushed Down: false
Stargate Dimensions Pushed Down: true
Stargate Limit/Order By:
Local Parallelism: -1
WindRunner Attributes:
windrunner.stargate.holodesk.read.deserialization: true
==============================================Stargate Context中各字段说明
| 字段名 | 说明 | 备注 |
|---|---|---|
| RDD | 由TableScanOperator生成,即需要读表的Operator/RDD才会有Stargate Context的内容 | 能看到走的哪条读表的路 |
| Dialect | 方言类型,三种取值:oracle(argodb默认),db2,td。 | 查看社区版官方文档中的交互语言 |
| Schema | Table 库名.表名[(alias[表别名])], Columns [表的所有列名,逗号分隔] | |
| Original Stargate | stargate接收到的过滤条件 | |
| Stargate Filter | 上面表的所有过滤条件,此时的过滤条件时or(a and b and c)这种形式,根节点一定是or。 | 真正下推到存储的过滤条件 |
| Stargate Filter All Push Down | 上面所有的过滤条件是否都可以被下推到存储 | 过滤条件被下推到存储引擎,意味着从存储引擎读到计算引擎的数据都是这些被下推的过滤条件过滤之后的,一般来讲,过滤条件被下推相比表所有数据,会有减少,可以提升性能。 如果是false,可能需要关注 |
| Needed Column | 需要存储引擎返回的改表的列 | 返回的列比表的总列数小的越多,返回的数据大小会越少,可以提升性能。 |
| Not Push Down Columns | 关注的较少 | 关注的较少 |
| Used Index | 关注的较少 | |
| Order By Pushed Down | 关注的较少 | |
| Stargate Dimensions Pushed Down | 关注的较少 | |
| Index Infomation | 关注的较少 | |
| Feedback | 关注的较少 | |
| Stargate Dimensions | 关注的较少 | |
| Stargate Limit/Order By | 关注的较少 | |
| Local Parallelism | 关注的较少 | |
| WindRunner Attributes | 关注的较少 |
评论
 登录后可评论
登录后可评论








.jpg)



