 454人浏览过
454人浏览过目录
一、基本概念
二、传统强化学习
Dynamic Programming
Monte Carlo Method
Temporal Difference Learnin
三、深度强化学习
DQN
Policy Gradient
Actor Critic
四、强化学习的应用
一、基本概念
强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物,它的本质是解决decision making 问题,即自动进行决策,并且可以做连续决策。它主要包含四个元素,agent,环境状态,行动,奖励,强化学习的目标就是获得最多的累计奖励。
1.什么是强化学习
强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物,它的本质是解决decision making 问题,即自动进行决策,并且可以做连续决策。它主要包含四个元素,agent,环境状态,行动,奖励,强化学习的目标就是获得最多的累计奖励。
2.强化学习的场景
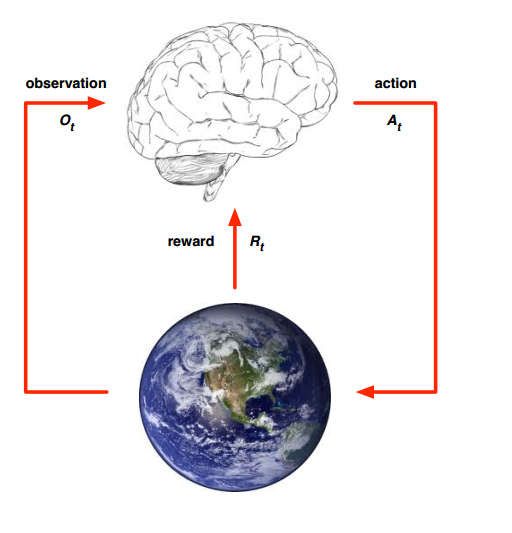
如图所示,个体与环境的交互:环境(environment)中的个体(agent)根据当前所处状态(state)按照某种策略(policy)选择下一步动作(action)并从环境中得到奖励(reward)。
例如:
下棋:根据棋盘的状态下子。
玩游戏:根据目前的游戏状况选择下一步动作。
机械控制:根据装置的和目标选择下一步动作。
3.强化学习的定义
强化学习(reinforcement learning),又称再励学习、评价学习,是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用
4.强化学习的几个要素:
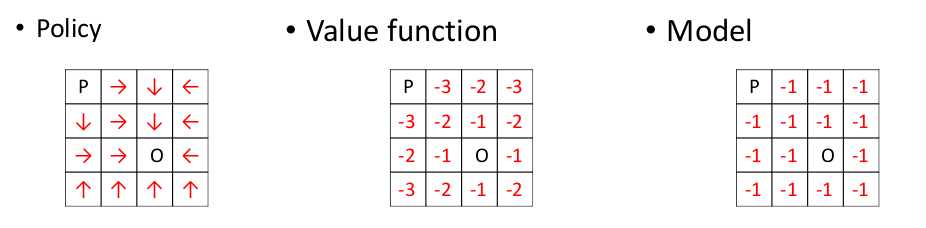
Policy: agent的动作选择函数:
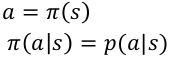
Value function: 对未来的预测,判断当前状态s的好坏 :
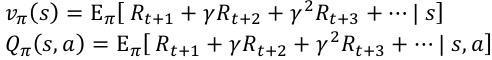
Model: agent对于环境的评估:
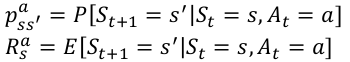
强化学习的目的:寻找一个最优的策略或者值函数。
例子:
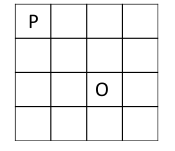
Grid World
Agent:P
•State:p所处的位置
•Reward:每一步是-1
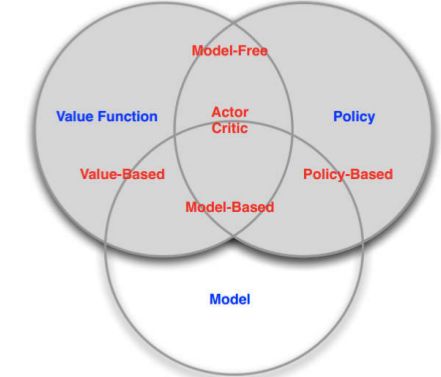
5.强化学习的分类
基于value的
有Value function Policy是隐式的,比如选择value最大的action;
基于Policy的
有显式的Polic;
没有value function;
Actor Critic
有value function;
有policy;
按照有无model来分
(1)Model free
无model;
有policy或者value function;
(2)Model based
有model;
有policy或者value function;
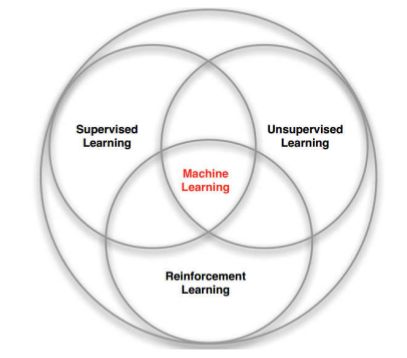
6.与其他机器学习方法的对比
从与环境的交互中学习
没有label,通过reward学习
二、传统强化学习
使用Markov Decision Process来表示建模agent与env的交互过程。下一个状态St+1只跟当前状态St与动作at有关。
四元组<S , A, P, R, γ>表示;S是状态空间的*;A是动作空间的*;P是转移概率矩阵
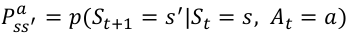
R是奖励函数
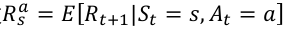
γ是discount factor;
其目的还是:寻找最优策略,最大化期望回报。
动态规划
动态规划(Dynamic Programming)是通过拆分问题,定义问题状态和状态之间的关系,使得问题能够以递推(或者说分治)的方式去解决。求解复杂问题的方法,将原问题分解为一些子问题:
Model based:
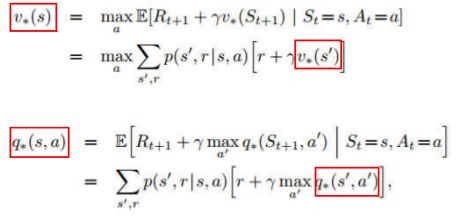
动态规划(DP) – Policy IterationPolicy Evaluate和Policy Improve的循环:

动态规划(DP) – Value Iteration
PolicyIteration每次都需要重新根据当前的策略更新value。
function的评估,Value iteration直接选择greedy的policy。

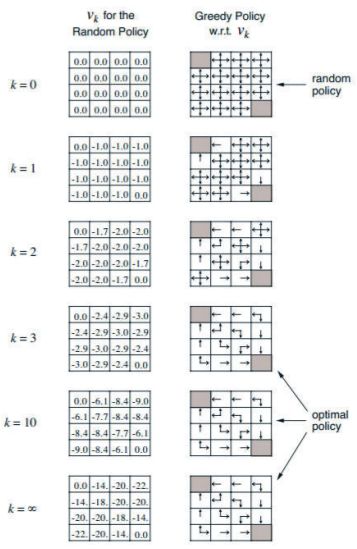
求解最短路径的示例:
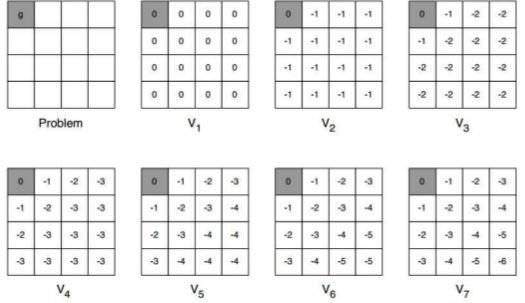
蒙特卡洛方法(Monte Carlo Method)
Model free
大部分情况下完整的环境状态是未知的,不停的与环境交互,获取state,action, reward的序列;V是return的均值。

Temporal Difference Learning
强化学习的核心方法,结合了DP和MC
Model Free

Temporal Difference Learning -- Q-Learning
更新公式
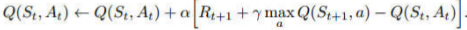
Off policy

Temporal Difference Learning -- Sarsa
更新公式
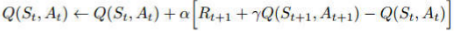
On policy

三、深度强化学习
深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,可以直接根据输入的图像进行控制,是一种更接近人类思维方式的人工智能方法。
深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,可以直接根据输入的图像进行控制,是一种更接近人类思维方式的人工智能方法。
Tabular based method
前面介绍的方法都是基于表格的,记录每个状态的情况。
状态数变大--- not available
棋类游戏:围棋,象棋等。
机械控制:机械臂,机器人等。
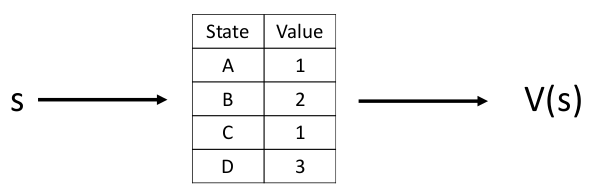
Value Function Approximation
使用一个函数来近似表示当前状态的估计值:
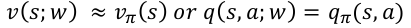
状态feature的构造feature engineering
Polynomials
Fourier Basis
Coarse Coding
...
函数选取
线性: liner regression...
非线性: tree-based, neural network …
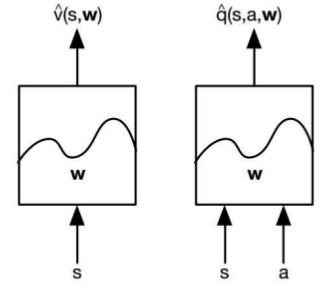
Deep Q Network
使用一个神经网络Q(s;w)来近似表示Q Table输入状态s,输出该状态下每个action的value。
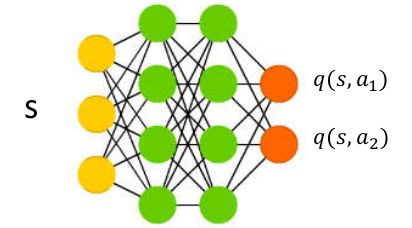
1.训练
训练集
使用一个memory记录前段时间内产生的状态动作序列s,a,r,s,随机采样batch Loss,用Q(s:w)来表示预测值;使用r+maxQ(s:w*)来表示w*为几个step之前的参数值。
Squred Loss
Deep Q Network -- 训练
Q(s:w)-- eval net
Q(s:w)-- target net

2.改进:Double DQN
DQN的目标值
从target net选取一个action
根据target net计算这个action的value
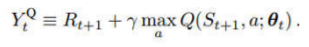
Double DQN的目标值
从target net选取一个action
根据eval net计算这个action的value
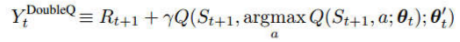
3.改进:Dueling DQN
改变Q值计算的方式
State value与action value之和
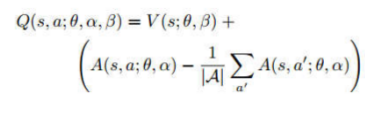
4.改进:PrioritizedDQN,改进batch选择的方式
DQN
Uniform
Prioritized DQN
Weighted with td-error

Policy Gradient
直接优化决策函数π(s; θ)
相比value based方法更直接
能够直接适用于连续action的场景
训练:
没有loss
构造回传的梯度,使reward大的action更有可能出现
REINFORCE-- episodic based

Actor Critic
结合value based method和policy gradient method。
Critic
类似DQN,计算状态的value v(s; w)
Actor
使用Policy Gradient方法更新
使用Critic得到的value衡量当前步骤的好坏
Actor Critic
(1)优势
单步更新
速度快
(2)劣势
难收敛

四、强化学习的应用
机械控制:机器人、机械臂
深度学习与强化学习相结合应用于机械控制领域。深度学习非常适合解决非结构化的真实世界场景,而强化学习能够实现较长期的推理(longer-term reasoning),同时能够在一系列决策时做出更好更鲁棒的决策。将这两个工具结合到一起,就有可能能够让机器人从自身经验中不断学习,使得机器人能够通过数据,而不是人工手动定义的方法来掌握运动感知的技能。
NLP:对话系统
我们正越来越多地使用自然语言对话接口与计算机进行交互。简单的问答(QA)机器人已经在亚马逊的 Alexa、苹果的 Siri、谷歌的 Now 和微软的 Cortana(小娜)中为数百万用户提供服务了。这些 bot 通常执行的是单个交流的对话,但我们渴望开发出更通用的对话智能体,使其对话广度能接近人类对话者所表现出的能力。强化学习成为对话系统的基础技术,应用于传统面向任务的对话系统的不同模块。充分利用大数据,结合端到端的训练和强化学习。
游戏:棋类、对战游戏
近年来,强化学习被越来越多地应用在游戏中,包括多种单人游戏和多人游戏,其优点在于能从大量的训练数据中学习出非线性的表示,从而达到更好的预测效果。棋类博弈和对战游戏都是很典型的应用场景。

自动建模:神经网络的架构搜索
强化学习对于自动建模也有重大贡献,通过环境反馈提供最优模型,搜索神经网络架构,能促进建模任务高效完成。
结语:强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物,它最开始是在机器人上的应用,但随着技术的发展,它在制造业,库存,电商,广告,推荐,金融,医疗等与我们生活息息相关的领域也有很好的应用,值得我们多多关注。
 0
0 举报
举报
 登录后可评论
登录后可评论



.jpg)



.jpg)


