本篇帖文主要介绍一下在使用时出现错误如何快速进行故障排查,帮助您快速定位和解决问题。
1. 上传产品包失败排查攻略
可能的原因:
a. 磁盘空间不足
b. 产品包md5不对导致产品包无法解压
c. 上传超时
d. 5000端口占用
a. 磁盘空间不足
默认会使用/var/lib/transwarp-manager/tmp目录来存储解压的产品包,必须保证这个目录所在的磁盘空间足够
PS: 这个目录是在/etc/transwarp-manager/master/application.conf的 tmp-dir参数配置的
b. 产品包md5不对
产品包中有附带了md5文件,但是由于用户环境的不同可能会对拷贝介质等做各种限制,从而损坏了产品包,您可以验证下产品包的的md5值是否变化。
b(1). 产品包无法解压
如果没有变化的话可以尝试手动解压产品包,看看是否会失败。
tar -xvzf <install-pkg>
2. 问题:Metastore不健康、无法启动、自动宕机。如何查看metastore的kucectl log和服务的日志进行问题定位c. 上传超时
上传超时错误在页面上会有提示,仔细观察下就能发现
机器磁盘性能较差时,可以修改manager的 application.conf 文件下的 node.install.timeout把超时时间调长,改完需要重启manager
d. 5000端口占用
上传产品包需要用到5000端口,如果这个端口被registry之外的其他进程占用了,会导致失败
解决思路:
查看metastore日志以及kubctl logs 容器本身的启动日志进行问题定位
如何查看(示例):
然后可以到部署了metastore的节点上,查看/var/log/quark1/下面的quark-metastore.log,日志中的报错原因有明确显示。

3. 8180端口无法访问问题排查流程
问题描述
使用浏览器无法打开Manager的8180页面,显示无法访问或拒绝连接。
故障排查整体思路
Manager服务启停
登录Manager节点,执行以下命令:
ps -ef | grep ManagerMaster
如果进程不存在,执行以下命令启动服务:
systemctl restart transwarp-manager
服务启动后再尝试访问8180页面,如果无法访问可以用下面步骤排查
排查步骤
a. 检查下磁盘空间是否足够
如果日志没刷新,很可能是磁盘满了
b. 网络连接不畅
检查网络、防火墙(网络是否正常)
在浏览器所在机器执行以下命令:
ping <manager节点IP>
如果不通请先检查网络连接,包括防火墙
c. 浏览器不支持
检查浏览器版本
查看安装手册,确认支持的浏览器,如果使用的浏览器不在支持列表中,请更换为支持的浏览器。
d. 浏览器缓存问题
清空浏览器缓存之后再尝试重新访问8180页面。
e. 检查HTTPS是否打开
如果https配置未打开,无法使用https访问8180
/etc/transwarp-manager/master/application.properties里面
server.ssl.enabled=false|true
f. 检查rpm包的完整性
在manager节点上,执行 rpm -qa | grep transwarp-manager命令,查看rpm包是否完整:
rpm包如何获取:https://community.transwarp.cn/question?questionId=73
如果不完整则需要重新安装,使用rpm -i命令安装即可。
g. 检查manager主进程是否存在
/etc/init.d/transwarp-manager status 与 jps命令都可以查询到manager主进程号
主进程不存在时候,可以尝试启动manager ,命令: /etc/init.d/transwarp-manager start
如果启动成功可以重新打开8180页面尝试登录,如果失败检查是否因为DB启动失败导致
h. 检查是否因为DB启动失败导致
manager启动失败,最常见的错误是db启动失败导致的,所以首先排查db的问题,参考第4个排查问题:transwarp-manager-db启动失败排查思路
db正常之后,manager还是启动不了,就需要检查启动日志 /var/log/transwarp-manager/master/transwarp-manager.out 查找原因了
i. 检查端口监听
注意: 开始这个步骤之前,要保证manager主进程已经在运行了manager默认使用8180端口,使用如下命令查看是否更改过:
cat /etc/transwarp-manager/master/application.properties | grep -i server.port
PS: 以下默认使用8180端口登录Manager节点,检查8180端口监听状况,执行以下命令:
netstat -lnp | grep 8180
或者
ss -nap | grep 8180
如果有进程在监听,要确定是manager的进程号;如果没有进程在监听,尝试重启Manager服务;如果有其他进程在监听8180端口,关闭此进程并重启Manager服务,验证是否能成功。
j. 验证Manager是否在提供服务
当确定8180端口被正确监听了之后,可以在Manager节点上执行下curl -v http://managerip:8180/来验证是否在正常服务,以下是正常集群:
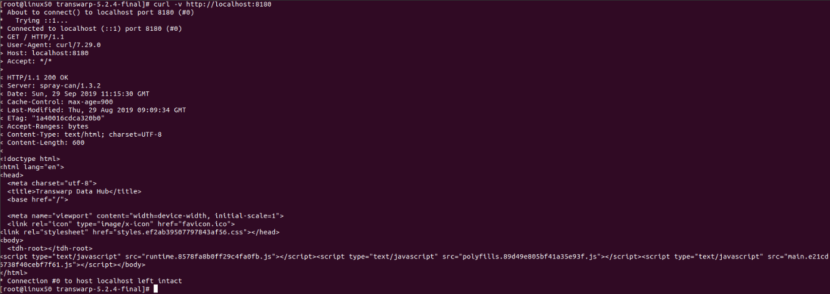
如果得不到上面的结果,此时基本可以确定是manager本身出问题了,启动日志中一定会有报错,根据错误来寻找原因;
如果得到了上面的正确结果,还是无法访问8180页面,那么99%可能性是集群的网络、防火墙等有问题
k. 集群压力导致的manager进程启动失败
k(1). 内存不足
服务器的内存空间被耗尽有可能导致manager进程启动失败,可以用下面这个命令查看机器的内存情况
free -g
如果manager频繁的OOM,可以考虑增大进程的内存,
修改地址:
/usr/lib/systemd/system/transwarp-manager.service
修改代码:
LANG=en_US.UTF-8 nohup $JAVA_HOME/bin/java $AGENT \
-Xms1024m -Xmx1536m \
必须同时更改这Xms和Xmx两个参数,并且Xmx要比Xms大,通常Xms要小于Xmx*70%
k(2). 磁盘IO
可以用iostat命令来检查磁盘的IO情况,比如:
iostat -mx 2
PS: 安装命令是 yum install -y sysstat
结果类似:
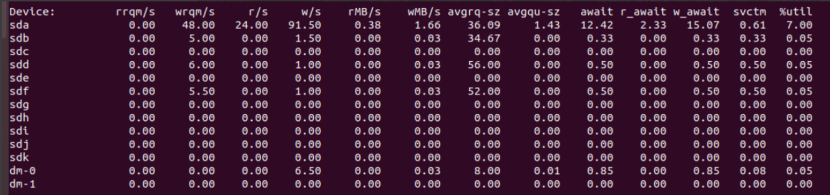
尤其需要关注系统盘的使用率
%util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了
可以用pidstat命令来查看占用IO最高的进程:
pidstat -dl -T ALL 3
PS: 安装命令是 yum install -y sysstat
可以根据结果来确定哪些进程在消耗磁盘的IO
4. transwarp-manager-db启动失败排查思路
a. 检查rpm包是否完整
rpm -qa | grep -i mariadb
b. 查看mysql用户是否存在
manager在安装db的过程中,会在操作系统中建立一个mysql用户,并且修改对应配置文件的所属,mysql用户缺失会导致db启动失败

c. 尝试后台启动db
根据/etc/init.d/transwarp-manager-db脚本中的内容,手动执行命令:
/usr/bin/mysqld_safe --defaults-file=/etc/transwarp-manager/master/my.cnf
或者是
/bin/sh /usr/bin/mysqld_safe --defaults-file=/etc/transwarp-manager/master/my.cnf
如果能执行成功,那么db应该已经可以启动了,可以用/etc/init.d/transwarp-manager-db start去启动db
如果执行失败,那么根据错误提示去查看日志,一般是在 /var/log/transwarp-manager/master/mysql/transwarp-manager-db.log,不排除有提示查看其他日志
如果报错发现日志报错
[ERROR] Fatal error: Can't open and lock privilege tables: Table 'mysql.host' doesn't exist
排查:
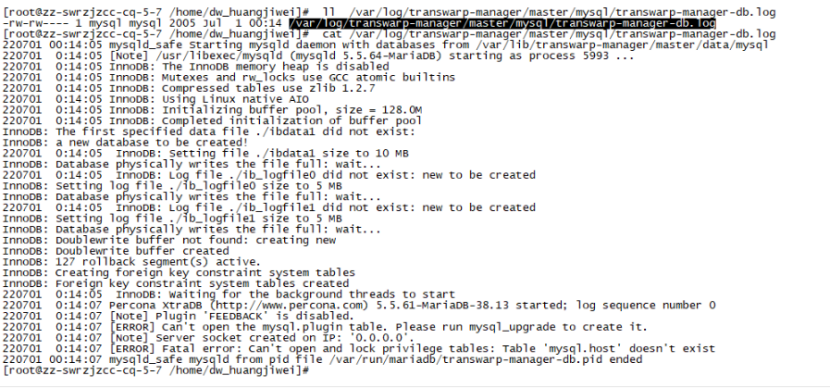
该问题基本是出现在新装 TDH 集群时。
首先确认执行 hostname 命令输出的主机名,和 /etc/hosts 里配置的保持一致
如果服务器配置了 DNS 域名解析,确认 /etc/resolv.conf 里配置的 DNS 服务器能正常解析域名
分别执行 ping localhost 和 ping $(hostname) 看 ip 信息对不对,网络是否正常
解决:
如果以上有信息不正确,请先解决相关的问题,如果以上信息都正确,请执行如下命令来初始化数据库和启动 manager。
$ /usr/bin/mysql_install_db --user=mysql --defaults-file=/etc/transwarp-manager/master/my.cnf --datadir=/var/lib/transwarp-manager/master/data/mysql --force
$ /etc/init.d/transwarp-manager restart
常见问题解决方法(持续更新中)
(1)日志目录权限不对
db启动失败,/usr/bin/mysqld_safe --defaults-file=/etc/transwarp-manager/master/my.cnf
命令报错:can't create/write to file ‘/var/log/transwarp-manager/master/mysql/transwarp-manager-db.log’ (Errcode: 13)
这个错误跟日志的权限有关,日志权限正确就检查整个路径的文件夹权限
或者 su - mysql -s /bin/bash切换到mysql用户,然后验证是否能读写日志
(2)日志中提示表不存在
(3)日志中提示表不存在日志报错:
090517 13:34:15 [ERROR] Can't open the mysql.plugin table. Please run mysql_upgrade to create it.
090517 13:34:15 [ERROR] Fatal error: Can't open and lock privilege tables: Table 'mysql.host' doesn't exist
类似的错误 ,在TDH集群中应该是/usr/bin/mysql_install_db --user=mysql --datadir=“/var/lib/transwarp-manager/master/data/mysql” 执行之后再去启动db
但是上一步中的命令执行不了错误信息:
Neither host ‘host4’ nor ‘localhost’ could be looked up with ‘/usr/libexec/resolveip’
解决方法:
需要建一个软连接从/usr/bin/resolveip到/usr/libexec/resolveip
ln -s /usr/bin/resolveip /usr/libexec/resolveip

(4)缺少mysql用户
Manager安装过程中会创建mysql用户来启动数据库,如果这个用户创建失败,也会导致db启动失败
5.启动故障
(1)Datanode起不来
修复磁盘重新挂载hdfs后,启动时datanode起不来,datanode挂了
报错1:
org.apache.hadoop.util.DiskChecker$DiskErrorException: Too many failed volumes - current valid volumes: 3, volumes configured: 5, volumes failed: 2, volume failures tolerated: 0
报错2:
org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /vdir/mnt/disk5/hadoop/data is in an inconsistent state: Root /vdir/mnt/disk5/hadoop/data: DatanodeUuid=138c130a-c8ea-4eff-8c03-1b4c8fdba1b6, does not match 691f7ac4-a901-46a4-9cac-6fc2904f1585 from other StorageDirectory.
rootcase:真正的问题原因在报错2中,可以看出是因为datanode的uuid发生了改变导致的datanode起不来
解决方法:
举例如上述报错中可将xxx/data/current/VERSION 文件中的DatanodeUuid=138c130a-c8ea-4eff-8c03-1b4c8fdba1b6改为DatanodeUuid=691f7ac4-a901-46a4-9cac-6fc2904f1585 然后配置服务重启hdfs即可
报错3:
org.apache.hadoop.util.DiskChecker$DiskErrorException: Invalid volume failure config value: 3
rootcase:datanode只配置了三个数据目录,并且hdfs-site.xml的dfs.datanode.failed.volumes.tolerated设置成了3
解决方法:
将参数dfs.datanode.failed.volumes.tolerated的值设置成0,配置服务重启hdfs即可
(2)Namenode起不来
基本原理:
一般namenode起不来,大部分原因是因为元数据文件缺失、损坏、权限不对、挂载信息错误等导致nn启动加载的时候识别报错;
① editlog问题,缺失等;
一般在启动的时候,FSEditLogLoader类会去加载nn目录下面的editlog文件;首先editlog这个文件是存在于ann、snn、jn中的;首先查看各个jn中的editlog是不是连续的,中间有没有缺失,有没有不正常的edits_inprogress文件;
首先ann生成editlog文件,并同步上传给jn,snn会去jn上拉取editlog用于合并fsimage,然后将最新的fsimage传输给ann。
ann和snn在启动的时候会去检查editlog是否完整;
② fsimage文件损坏;
使用sh fixfsimage.sh check {fsimage文件}查看文件是否损坏;
6. Inceptor 事务并发加锁时间过长的可能情况
解决思路:
如果inceptor的并发事务执行慢,可以检查一下mysql的master节点挂载的磁盘的压力情况以及网络延时情况。
7.管理界面添加节点失败
现象:
在查找添加节点的界面上,输入节点IP、用户名和密码之后,报错无法连接到对应机器。
具体的报错信息
Could not create directory '/home/transwarp/.ssh'.
解决办法:
(1)将解压出来的/home/transwarp更名,以创建/home/transwarp目录并chown为transwarp:transwarp
(2)将transwarp用户的$HOME默认改为/var/lib/transwarp
8. 如何进行Inceptor server GC日志分析
Inceptor server 没有单独的GC日志文件,GC的信息混在hive-server2.log里面。
GC的信息是通过leviathan输出的,每分钟一次。
1) 如果间隔超过了1分钟,中间肯定发生了比较严重的GC。
2) gcTime计算:gcTime是累积的时间,两个相减就是期间的GC总时间。
9. Inceptor server GC问题分析2018-11-30 14:09:16,255 INFO leviathan.TimedEventTracker: (Logging.scala:logInfo(59)) [Leviathan Monitor Timer()] - [Leviathan][2100931]JVM Process Time: recent {u:200, s:91}; history {u:5772494, s:990672}; Executor thread number: 377; opened fd: 3049; JVM offheap status: used 88677591 byte, capa 88677589 byte, max 32883343360 byte; JVM heap gc status: count 2028, gcTime 3111809 ms; JVM Heap: init = 2147483648(2097152K) used = 13232454000(12922318K) committed = 32883343360(32112640K) max = 32883343360(32112640K), Non-Heap: init = 2555904(2496K) used = 303465696(296353K) committed = 310972416(303684K) max = -1(-1K); Get these information costs: 18.89 ms
...
2018-11-30 14:10:16,256 INFO leviathan.TimedEventTracker: (Logging.scala:logInfo(59)) [Leviathan Monitor Timer()] - [Leviathan][2100933]JVM Process Time: recent {u:126, s:73}; history {u:5772620, s:990745}; Executor thread number: 375; opened fd: 3048; JVM offheap status: used 88685783 byte, capa 88685781 byte, max 32883343360 byte; JVM heap gc status: count 2028, gcTime 3111809 ms; JVM Heap: init = 2147483648(2097152K) used = 13259790112(12949013K) committed = 32883343360(32112640K) max = 32883343360(32112640K), Non-Heap: init = 2555904(2496K) used = 303465696(296353K) committed = 310972416(303684K) max = -1(-1K); Get these information costs: 19.55 m
可能会引起GC的原因:
① CTC 表太大(垃圾太多)
HiveConf中会包含CTC表的信息,如果记录数目太多,占用内存会比较多.
在mysql/txsql里面查询:
SELECT count(*) FROM hive_metastore.COMPLETED_TXN_COMPONENTS
② PL/SQL死循环profile信息积累,jmap如下

解决方法:plsql.runtime.profile设置为false.
③ ORC column统计信息太多
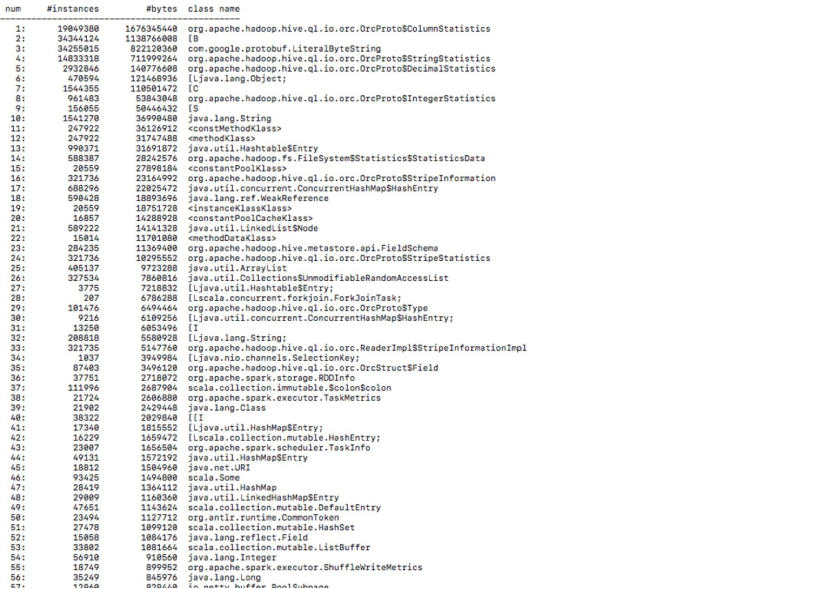
解决方法: 调小hive.orc.cache.stripe.details.size
这个开关会影响orc footer cache的大小。 在inceptor的log里面搜, FooterCacheHitRatio, 如果绝大部分ration是0,可以考虑把hive.orc.cache.stripe.details.size设成0。
④ HiveConf太多
设置 -Dspark.cleaner.ttl.BROADCAST_FAST=1800应该可以缓解 (默认是1800,如果还是积累比较严重,可以把这个值设小)
“该参数影响范围内容:
当Inceptor以Cluster模式“高并发”连续执行批处理作业时(一般是平均1分钟执行20个SQL以上)连续执行数小时,会导致Executor严重FullGC,并且无法自然缓解
该参数无副作用
该参数的工作原理及问题出现原因:
这个参数只是用来清理Executor和Inceptor Server“内存”中的Broadcast的,
并不清理被保存在磁盘上的Broadcast文件,如果后续任务还需要这个Broadcast那么从磁盘中拿到那个Broadcast文件就可以
Broadcast的文件清理间隔还会4个半小时,这个参数设置在15分钟左右是不会有任何副作用的
开发这套新的机制的起因是邮政项目在跑高并发的时候发现HiveConf过大导致Executor/server FullGC"
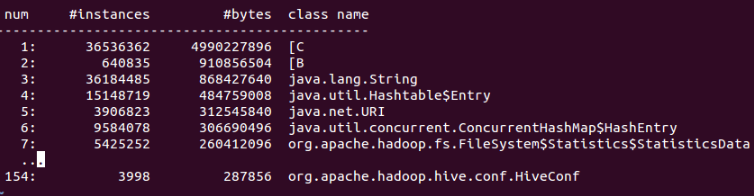
一般出现在并发量比较大的情况,jmap如下所示:
这里占内存最多的 [C, 可能是 第二节 提到的CTC表问题。
并发跑时,HiveConf可能会积累到5/6千个,这个基本正常,跟SQL的复杂度和积压情况相关。 暂时还没有好办法,可以先调大inceptor server内存workaround.
目前正在持续更新中,有问题大家多多留言~
 悬赏:
悬赏: 0
0 分享
分享 举报
举报
 登录后可回答问题
登录后可回答问题



.jpg)



.jpg)


